尚硅谷离线数仓之采集平台
1. 用户行为日志
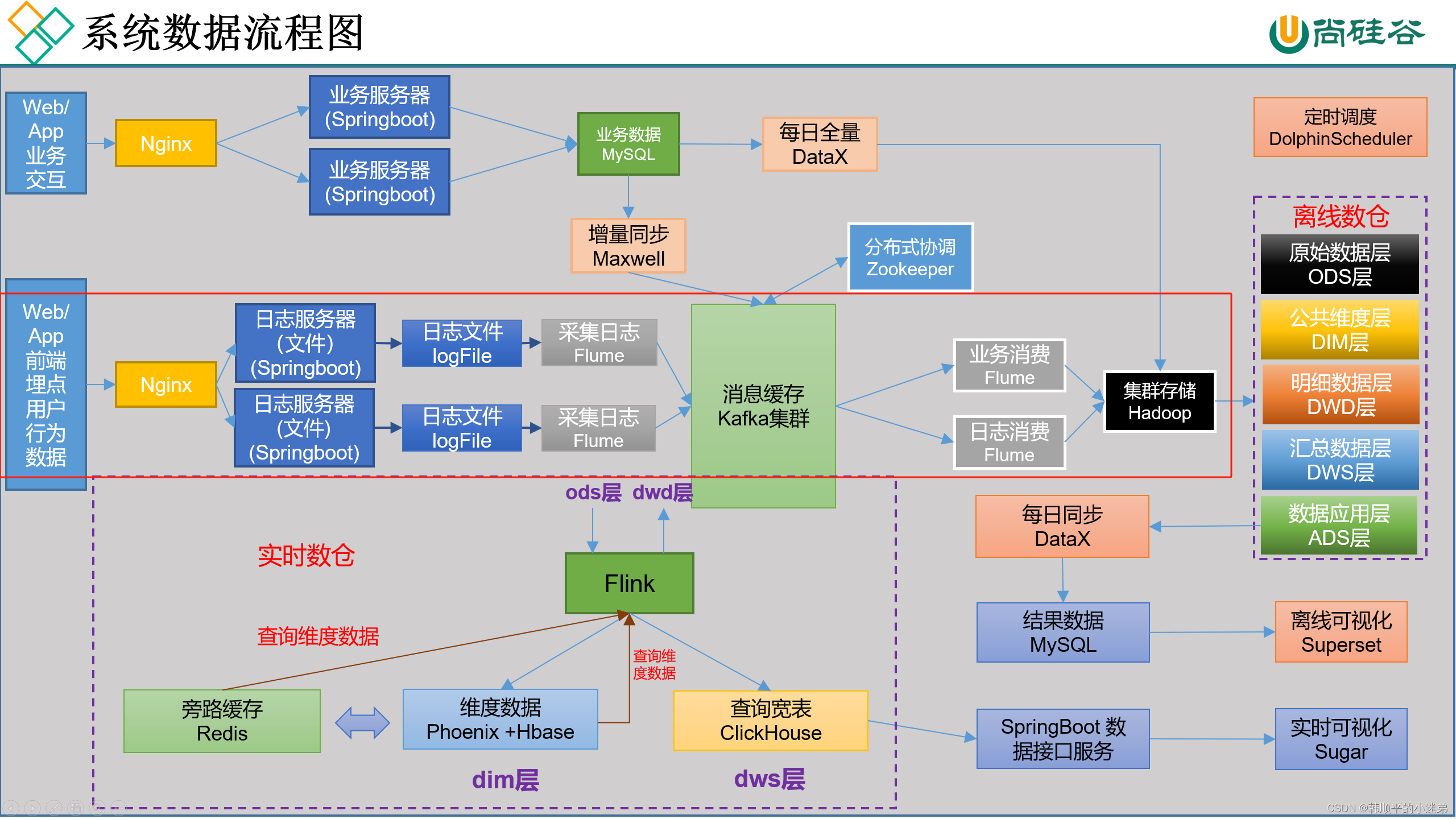
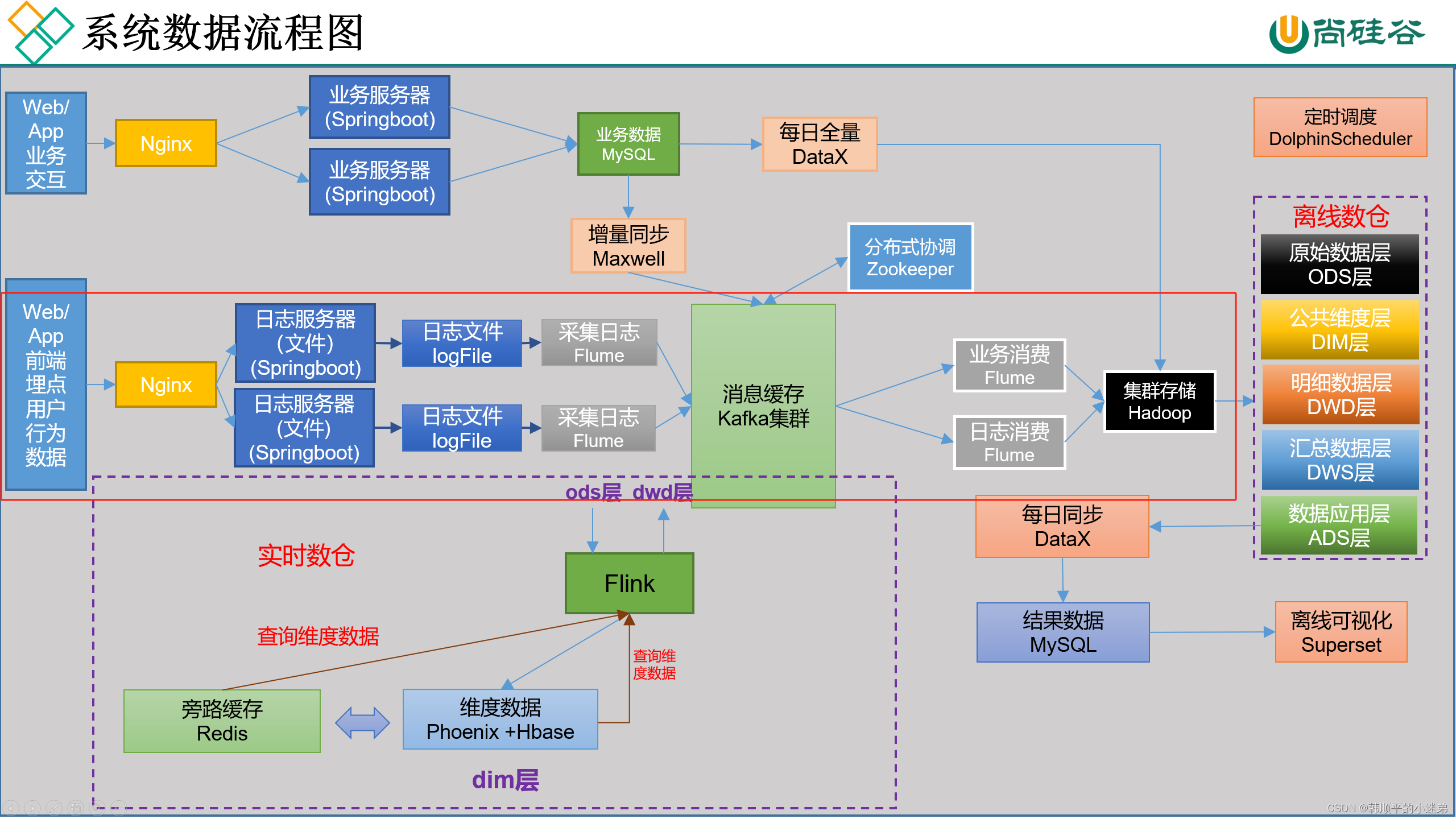
数据流向流程图如下,其中红框表示用户行为日志数据的流向图。
1.1 行为日志内容
行为日志主要包括以下几个内容
- 页面浏览记录
- 动作记录
- 曝光记录
- 启动记录
- 错误记录
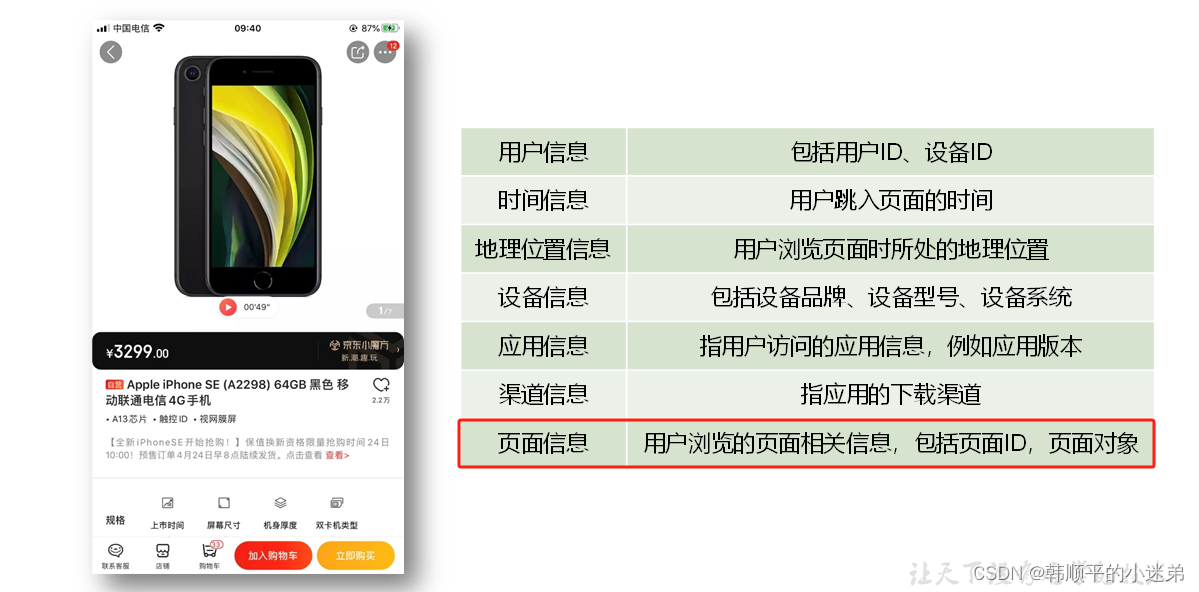
页面浏览记录

动作记录


1.2 用户行为日志格式
- 页面日志
- 启动日志
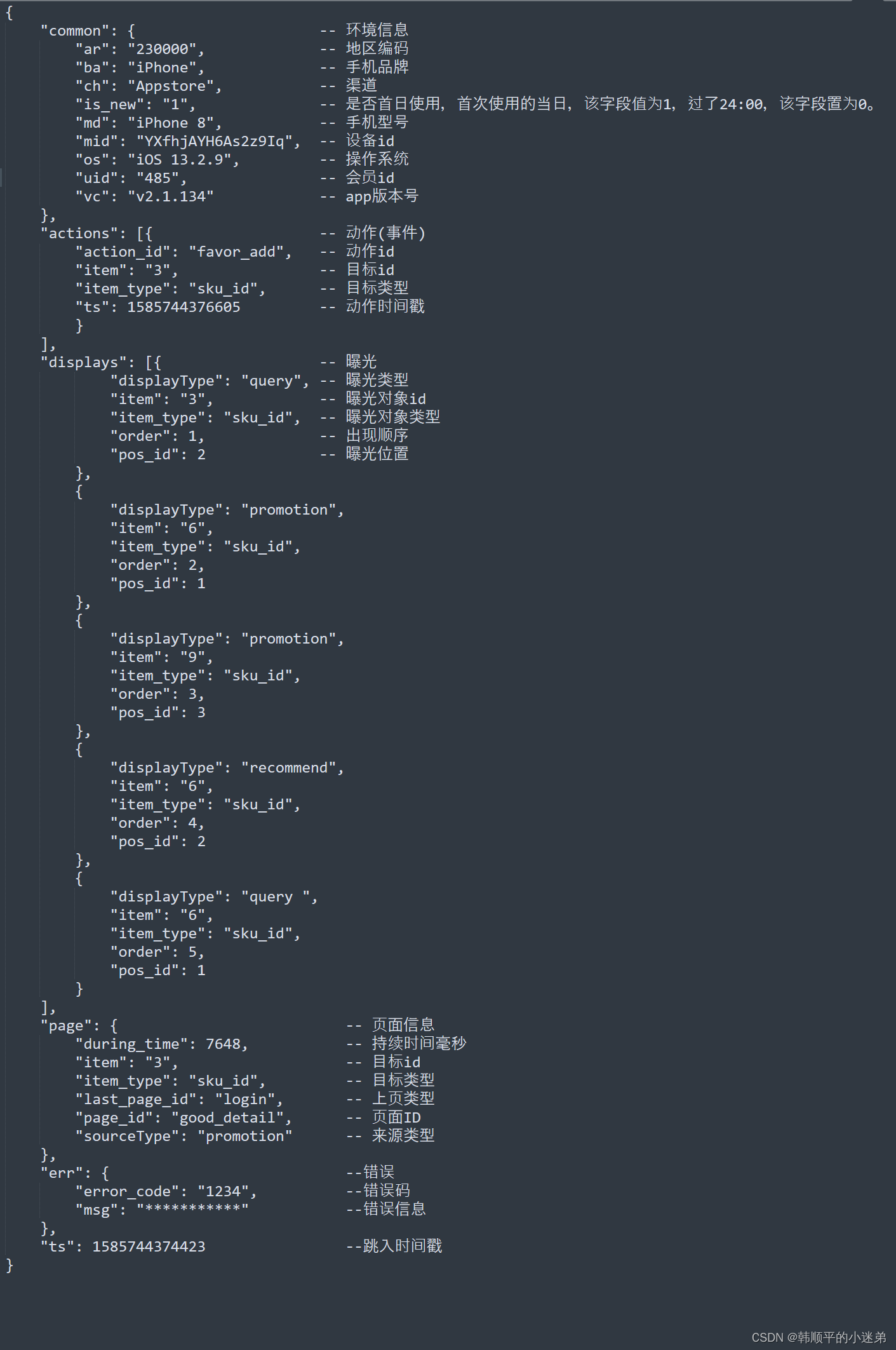
页面日志,以页面浏览为单位,即一个页面浏览记录,生成一条页面埋点日志。一条完整的页面日志包含,一个页面浏览记录,用户在该页面所做的若干个动作记录,若干个该页面的曝光记录,以及一个在该页面发生的报错记录。
除上述行为信息,页面日志还包含了这些行为所处的各种环境信息,包括用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息等。
页面日志内容格式如下:
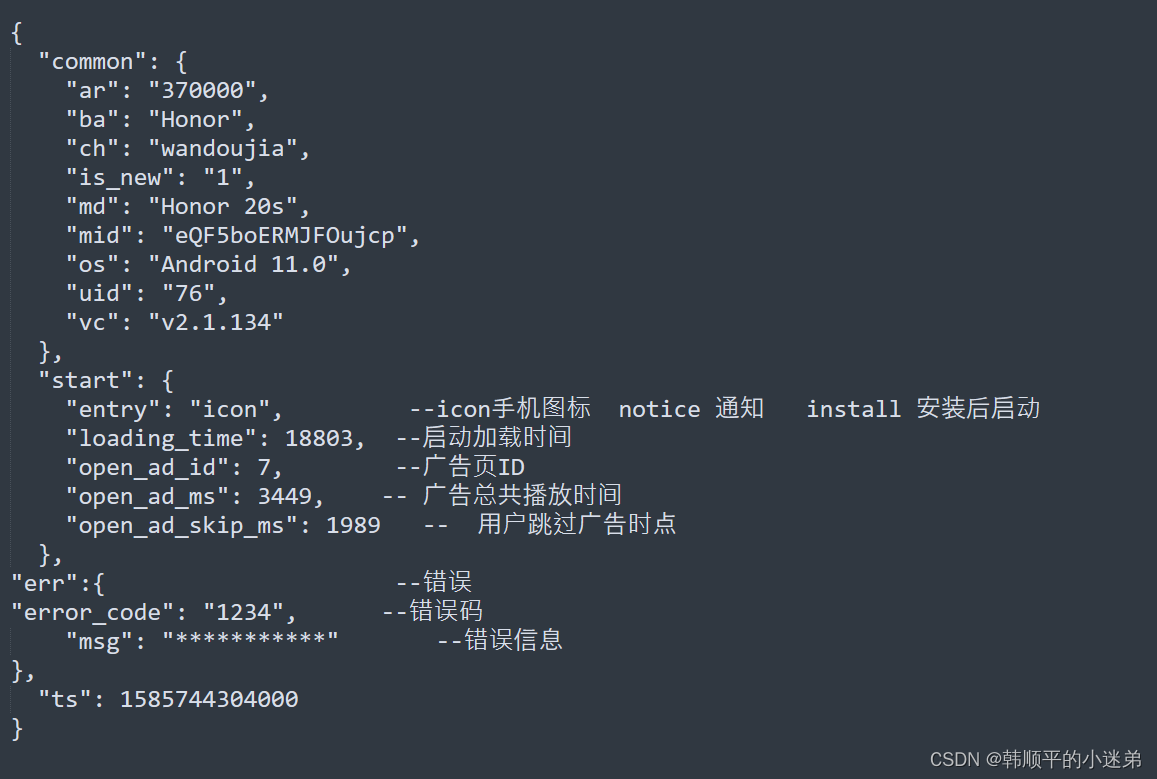
启动内容格式如下:
1.3 模拟生成日志行为数据
java jar包生成模拟数据命令如下:
java -jar gmall2020-mock-log-2021-10-10.jar
生成模拟数据脚本如下:
#!/bin/bash
for i in hadoop102 hadoop103; do
echo "========== $i =========="
ssh $i "cd /opt/module/applog/; java -jar gmall2020-mock-log-2021-10-10.jar >/dev/null 2>&1 &"
done
生成的日志文件如下:
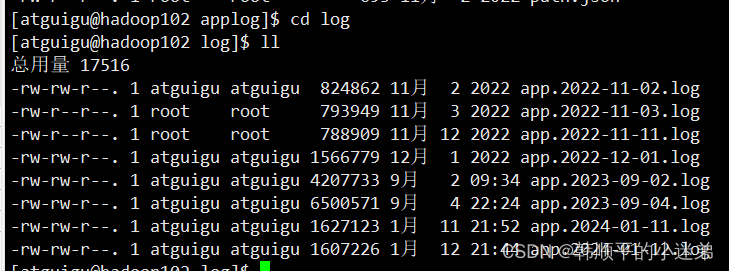
生成用户行为页面日志数据如下:

生成用户行为启动日志数据如下:

集群日志生成脚本lg.sh:
#!/bin/bash
for i in hadoop102 hadoop103; do
echo "========== $i =========="
ssh $i "cd /opt/module/applog/; java -jar gmall2020-mock-log-2021-10-10.jar >/dev/null 2>&1 &"
done
2. 用户行为数据采集模块
用户行为数据采集到hdfs集群的流程图如下图中的红框所示,分为两个阶段
- 阶段一:flume采集用户行为日志数据到kafka集群的topic_log主题
- 阶段二:flume采集kafka集群中的topic_log主题的数据到hdfs集群
2.1 用户行为数据采集到kafka集群
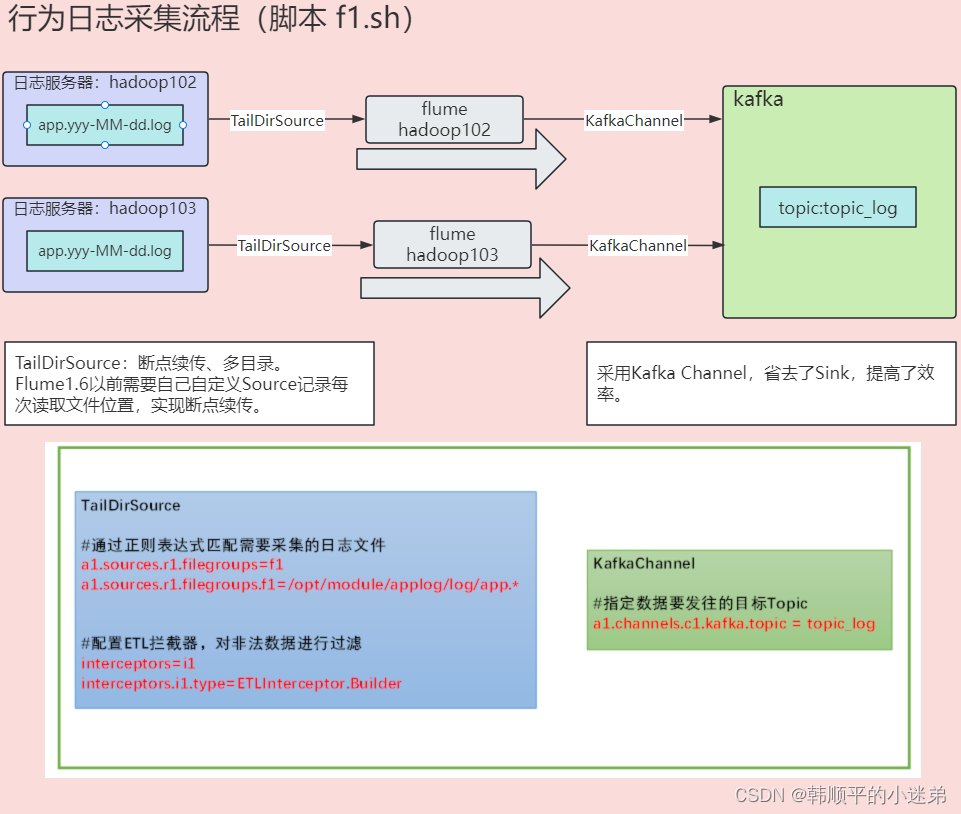
按照规划,需要采集的用户行为日志文件分布在hadoop102,hadoop103两台日志服务器,故需要在hadoop102,hadoop103两台节点配置日志采集Flume。日志采集Flume需要采集日志文件内容,并对日志格式(JSON)进行校验,然后将校验通过的日志发送到Kafka集群。
用户行为日志数据流向图如下图所示,flume采用TailDirSource监控日志文件的产生,并将日志文件数据以json的格式通过kafkaChannel采集到kafka集群topic_log主题。
2.1.1 flume简单介绍
Flume 中的事件(Event)是数据传输的基本单元,它包含了要从源传递到目标的数据。一个 Flume 事件通常包含以下几个主要部分:
-
Header(头部信息):
头部是一个包含元数据(metadata)的键值对集合,描述了事件的属性和信息。头部中的信息通常包括事件的来源、时间戳、数据类型等。头部提供了对事件的基本描述和上下文信息。 -
Body(主体数据):
主体是实际的数据内容,即要传输的信息。主体可以是文本、二进制数据等,具体取决于事件的来源和目标。主体是事件中实际传输的核心数据。 -
Attachment(附件):
附件是一些可选的附加信息,可以包含在事件中。附件通常用于存储一些额外的元数据,提供更多关于事件的信息。附件可以是任意格式的数据,例如序列化后的对象、附加文件等。总体来说,Flume 事件的结构可以用以下的伪代码表示:
Event {
Header {
key1: value1,
key2: value2,
// ...
},
Body: data,
Attachment: additional_metadata
}
2.1.2 kafka channel 三种架构
在 Kafka Channel 中,数据保存在kakfa集群。在 Kafka Channel 中,事件是以 Kafka 消息的形式存储的,而不是传统的 Flume 事件。 Kafka 本身提供了一些消息的元数据,例如 topic、partition、offset 等。由于 Kafka Channel 使用 Kafka 的机制来存储和传递消息,因此传统的 Flume 拦截器可能无法直接应用于 Kafka Channel 中。如果想要用Flume拦截器就必须把
设parseAsFlumeEvent: true.
parseAsFlumeEvent: true:表示接收到的数据将被解析为 Flume 事件,而不是普通的文本数据
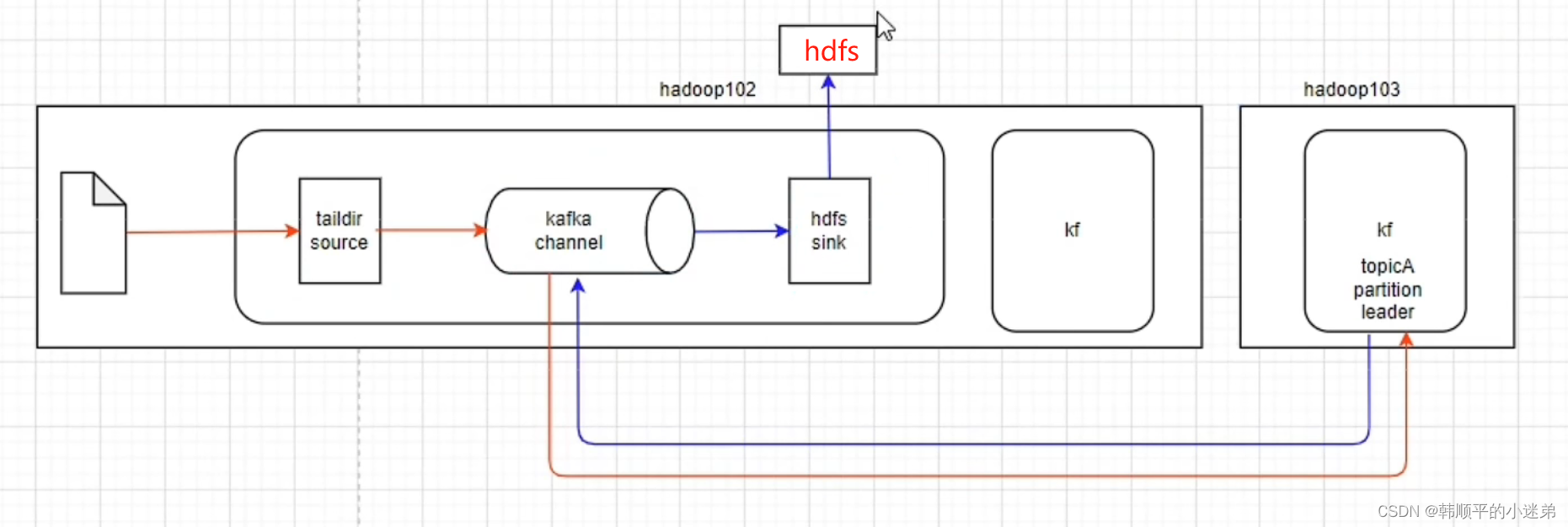
上图flume结构:
- source
- kafka channel
- sink
上图中同一个颜色的箭头表示数据的流向。
上图中需要对日志数据进行json校验,所以必须使用flume拦截器,故 parseAsFlumeEvent: true。kafka channel数据以flumeEven格式保存在kafka集群中,在离线数仓中,可以解析出Even数据中的Body源数据存入hdfs,但是在实时数仓中,flumeEven数据不利于实时处理。故不采用
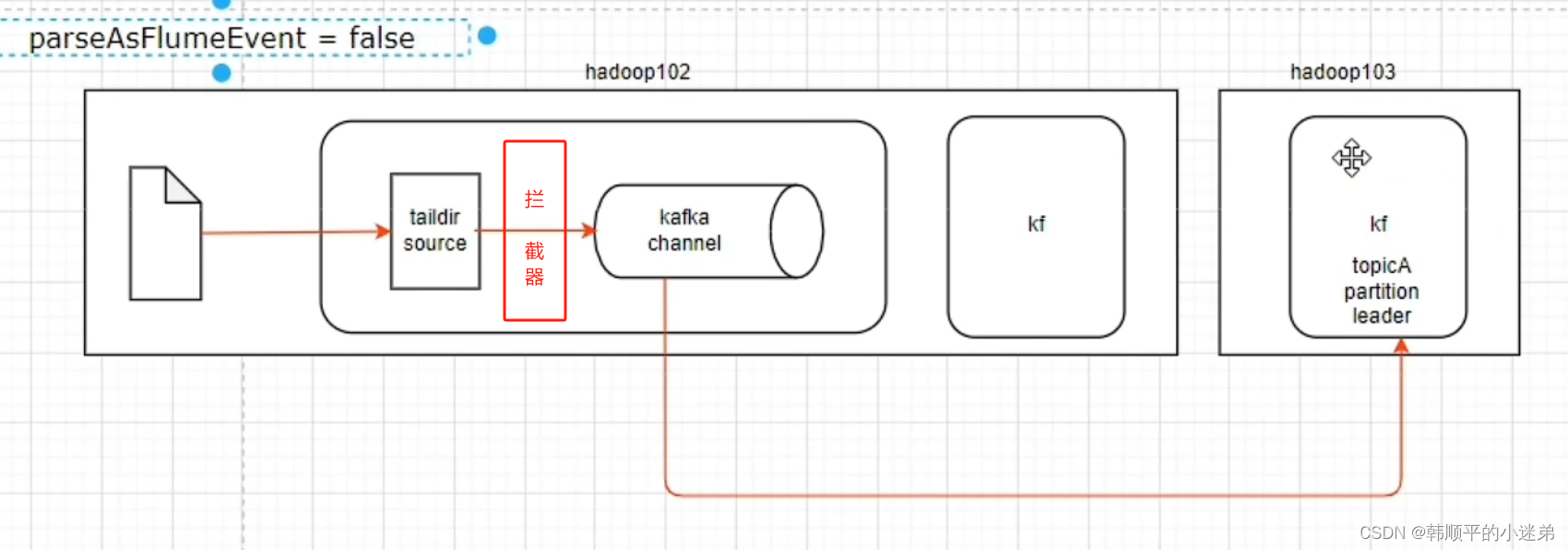
上图flume结构:
- source
- 拦截器(interceptor)
- kafka channel
上图中同一个颜色的箭头表示数据的流向。把参数设为parseAsFlumeEvent: false,让事件是以 Kafka 消息的形式存储,拦截器对日志数据进行json格式校验。日志数据保存在kafka集群中,下游使用flume采集到hdfs集群上用于做离线数仓。在kafka集群上的日志数据也可以用于实时处理。本项目采用此架构采集日志数据到kafka集群。
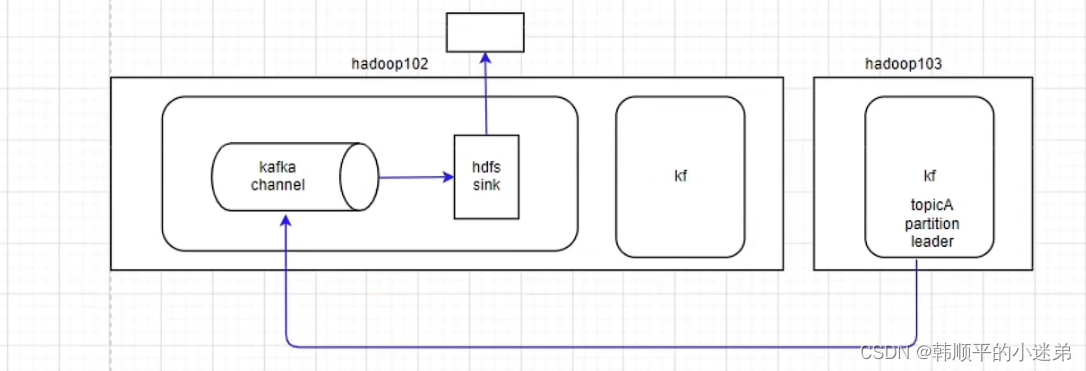
上图flume结构:
- kafka channel
- sink
hdfs 作为kakfa集群的消费者,不符合我们需求。
2.1.3 日志采集Flume配置实操
定义组件
a1.sources = r1
a1.channels = c1
在这里,a1 是 Flume Agent 的名称,r1 是 source 的名称,c1 是 channel 的名称。这定义了一个 Flume Agent 包含一个 source 和一个 channel。
配置 source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.ETLInterceptor$Builder
type: 指定 source 的类型为 TAILDIR,表示使用 Taildir Source,用于监控文件尾部。filegroups: 定义文件组 f1,指定监控的文件路径模式为 /opt/module/applog/log/app.*。positionFile: 指定保存文件读取位置信息的文件路径为 /opt/module/flume/taildir_position.json,用于记录读取的位置,以便恢复读取状态。interceptors: 配置拦截器,这里使用了名为 ETLInterceptor 的拦截器。
配置 channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
type: 指定 channel 的类型为 KafkaChannel。kafka.bootstrap.servers: 指定 Kafka 服务器的地址为 hadoop102:9092,hadoop103:9092。kafka.topic: 指定 Kafka 的 Topic 名称为 topic_log。parseAsFlumeEvent: 设置为 false,表示不将 Flume 事件解析为 Kafka 事件。
组装
a1.sources.r1.channels = c1
这一行表示将 source r1 和 channel c1 进行组装,即数据从 source 流向 channel。
在hadoop102,hadoop103节点的Flume的job目录下创建file_to_kafka.conf,内容如下:
#定义组件
a1.sources = r1
a1.channels = c1
#配置source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.ETLInterceptor$Builder
#配置channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
#组装
a1.sources.r1.channels = c1
这个配置文件的作用是使用 Taildir Source 监控指定文件夹中的日志文件,通过 Kafka Channel 将获取到的日志数据传输到 Kafka Topic。拦截器 ETLInterceptor 用于对json格式的数据进行校验。
2.1.4 Flume拦截器
1. 创建Maven工程flume-interceptor
2. 创建包:com.atguigu.gmall.flume.interceptor
3. 在pom.xml文件中添加配置
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
4. 在com.atguigu.gmall.flume.utils包下创建JSONUtil类
package com.atguigu.gmall.flume.utils;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.JSONException;
public class JSONUtil {
/*
* 通过异常判断是否是json字符串
* 是:返回true 不是:返回false
* */
public static boolean isJSONValidate(String log){
try {
JSONObject.parseObject(log);
return true;
}catch (JSONException e){
return false;
}
}
}
5. 在com.atguigu.gmall.flume.interceptor包下创建ETLInterceptor类
package com.atguigu.gmall.flume.interceptor;
import com.atguigu.gmall.flume.utils.JSONUtil;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
public class ETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
//1、获取body当中的数据并转成字符串
byte[] body = event.getBody();
String log = new String(body, StandardCharsets.UTF_8);
//2、判断字符串是否是一个合法的json,是:返回当前event;不是:返回null
if (JSONUtil.isJSONValidate(log)) {
return event;
} else {
return null;
}
}
@Override
public List<Event> intercept(List<Event> list) {
Iterator<Event> iterator = list.iterator();
while (iterator.hasNext()){
Event next = iterator.next();
if(intercept(next)==null){
iterator.remove();
}
}
return list;
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new ETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
@Override
public void close() {
}
}
6. 打包

7. 需要先将打好的包放入到hadoop102的/opt/module/flume/lib文件夹下面。
2.1.5 日志采集Flume测试
- 启动Zookeeper、Kafka集群
- 启动hadoop102的日志采集Flume
[atguigu@hadoop102 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf -Dflume.root.logger=info,console
- 启动一个Kafka的Console-Consumer
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic topic_log
- 生成模拟数据
[atguigu@hadoop102 ~]$ lg.sh
- 观察Kafka消费者是否能消费到数据
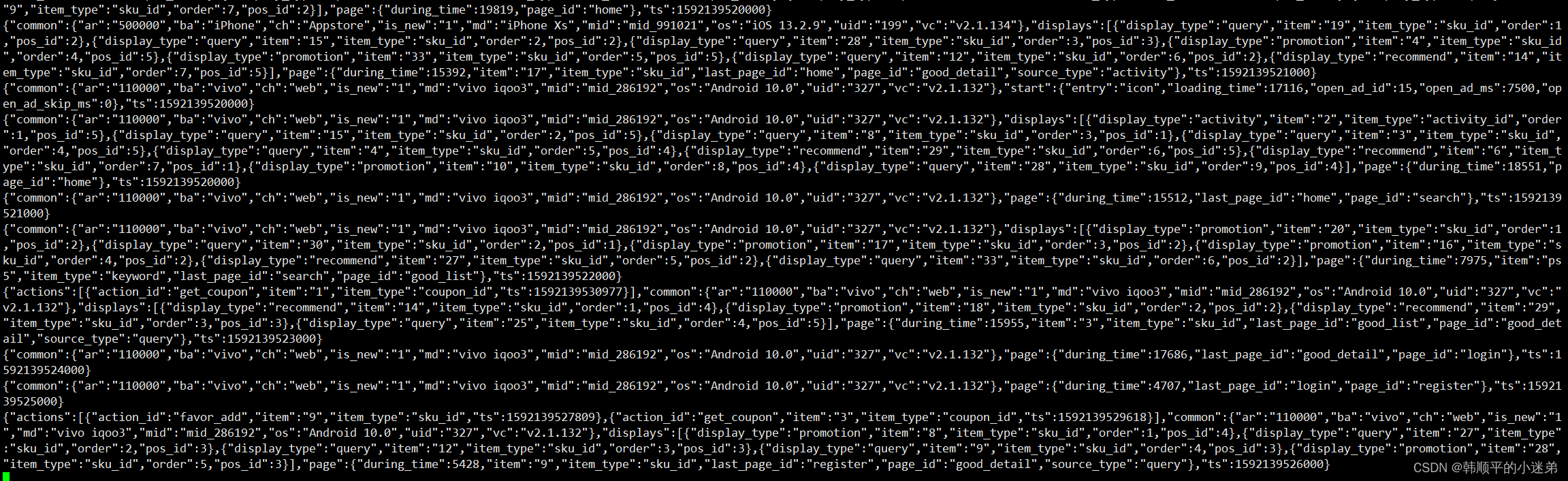
追加数据到日志:

kafka消费者消费数据:
2.1.6 日志采集Flume进程的启停脚本f1.sh
f1.sh
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103
do
echo " --------启动 $i 采集flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf/ -f /opt/module/flume/job/file_to_kafka.conf >/dev/null 2>&1 &"
done
};;
"stop"){
for i in hadoop102 hadoop103
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep file_to_kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "
done
};;
esac
- 增加脚本执行权限: chmod 777 f1.sh
- f1启动: f1.sh start
- f1停止: f1.sh stop
2.2 用户行为数据由Flume从Kafka集群采集到HDFS
由于离线数仓采用Hive的分区表按天统计,所以目标路径要包含一层日期。具体数据流向如下图所示。
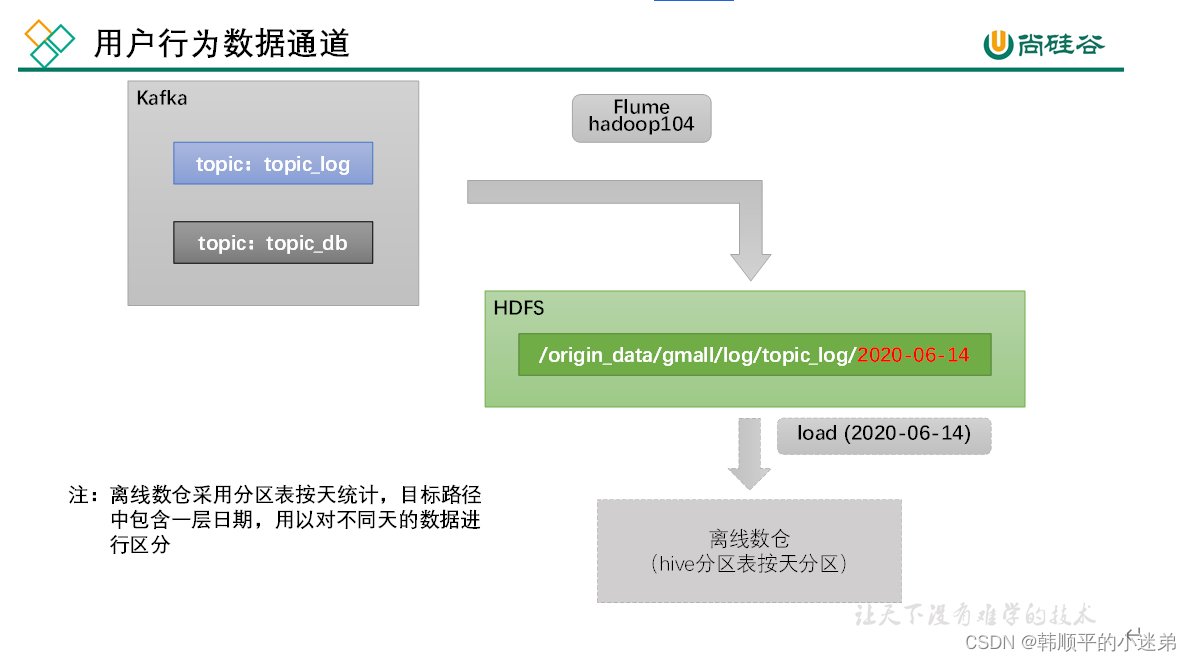
2.2.1 日志消费Flume配置概述
按照规划,该Flume需将Kafka中topic_log的数据发往HDFS。并且对每天产生的用户行为日志进行区分,将不同天的数据发往HDFS不同天的路径。
此处选择KafkaSource、FileChannel、HDFSSink。
关键配置如下:
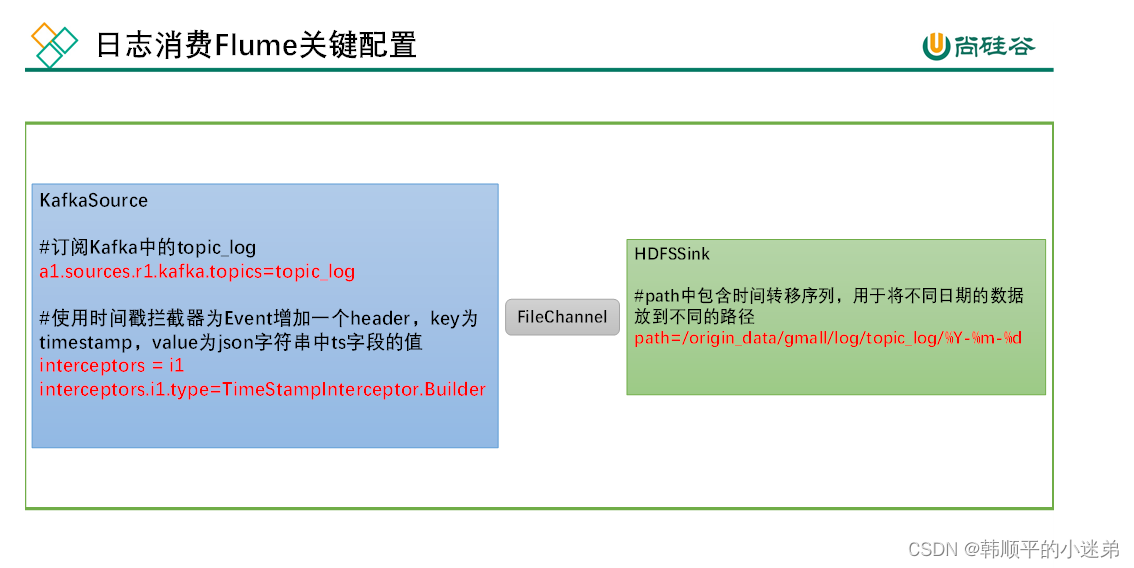
2.2.2 日志消费Flume配置实操
- 在hadoop104节点的Flume的job目录下创建kafka_to_hdfs_log.conf
[atguigu@hadoop104 flume]$ vim job/kafka_to_hdfs_log.conf
- flume配置文件内容如下
#定义组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.TimestampInterceptor$Builder
#配置channel
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
#配置sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
#控制输出文件类型
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
#组装
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.2.3 编写Flume拦截器
kafka通过flume把日志数据采集到hdfs集群存在数据漂移问题,所以把kafka中的时间戳作为flume Event header中的时间戳。具体细节如下图所示。
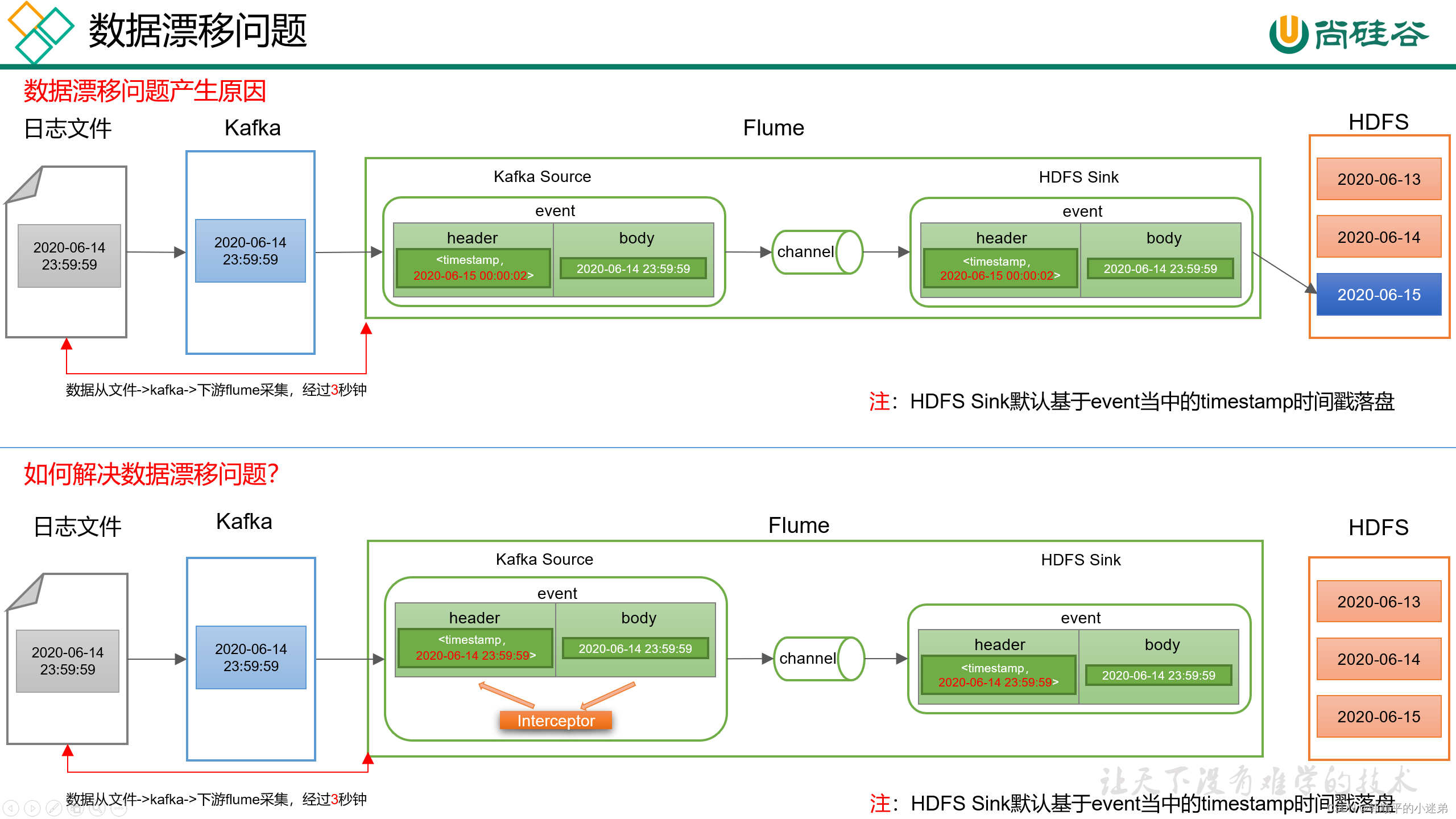
2.2.4 日志消费flume测试
- 启动Zookeeper、Kafka集群
- 启动日志采集Flume
[atguigu@hadoop102 ~]$ f1.sh start
- 启动hadoop104的日志消费Flume
[atguigu@hadoop104 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/kafka_to_hdfs_log.conf -Dflume.root.logger=info,console
- 生成模拟数据
[atguigu@hadoop102 ~]$ lg.sh
- 观察HDFS上数据
2.2.5 日志消费Flume启停脚本
1)在hadoop102节点的/home/atguigu/bin目录下创建脚本f2.sh
[atguigu@hadoop102 bin]$ vim f2.sh
#!/bin/bash
case $1 in
"start")
echo " --------启动 hadoop104 日志数据flume-------"
ssh hadoop104 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs_log.conf >/dev/null 2>&1 &"
;;
"stop")
echo " --------停止 hadoop104 日志数据flume-------"
ssh hadoop104 "ps -ef | grep kafka_to_hdfs_log | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esac
2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 f2.sh
3)f2启动
[atguigu@hadoop102 module]$ f2.sh start
4)f2停止
[atguigu@hadoop102 module]$ f2.sh stop
3. 业务数据
3.1 业务数据介绍
电商数仓系统涉及到34个业务数据表如下:

3.2 业务数据模拟
[atguigu@hadoop102 db_log]$ java -jar gmall2020-mock-db-2021-11-14.jar

3.3 业务数据的同步策略
数据的同步策略有全量同步和增量同步。
- 全量同步,就是每天都将业务数据库中的全部数据同步一份到数据仓库,这是保证两侧数据同步的最简单的方式。本项目中全量同步用DataX。
- 增量同步,就是每天只将业务数据中的新增及变化数据同步到数据仓库。采用每日增量同步的表,通常需要在首日先进行一次全量同步。本项目中增量同步用Maxwell。
3.4 DataX简单介绍
DataX基于Select查询的离线、批量同步工具。细节见另一篇文章DataX:https://blog.csdn.net/qq_41246557/article/details/135584013
3.5 Maxwell 简单介绍
Maxwell基于数据库数据变更日志(例如MySQL的binlog,其会实时记录所有的insert、update以及delete操作)的实时流式同步工具。细节见另一篇文章Maxwell :https://blog.csdn.net/qq_41246557/article/details/135599215
4. 业务数据采集通道
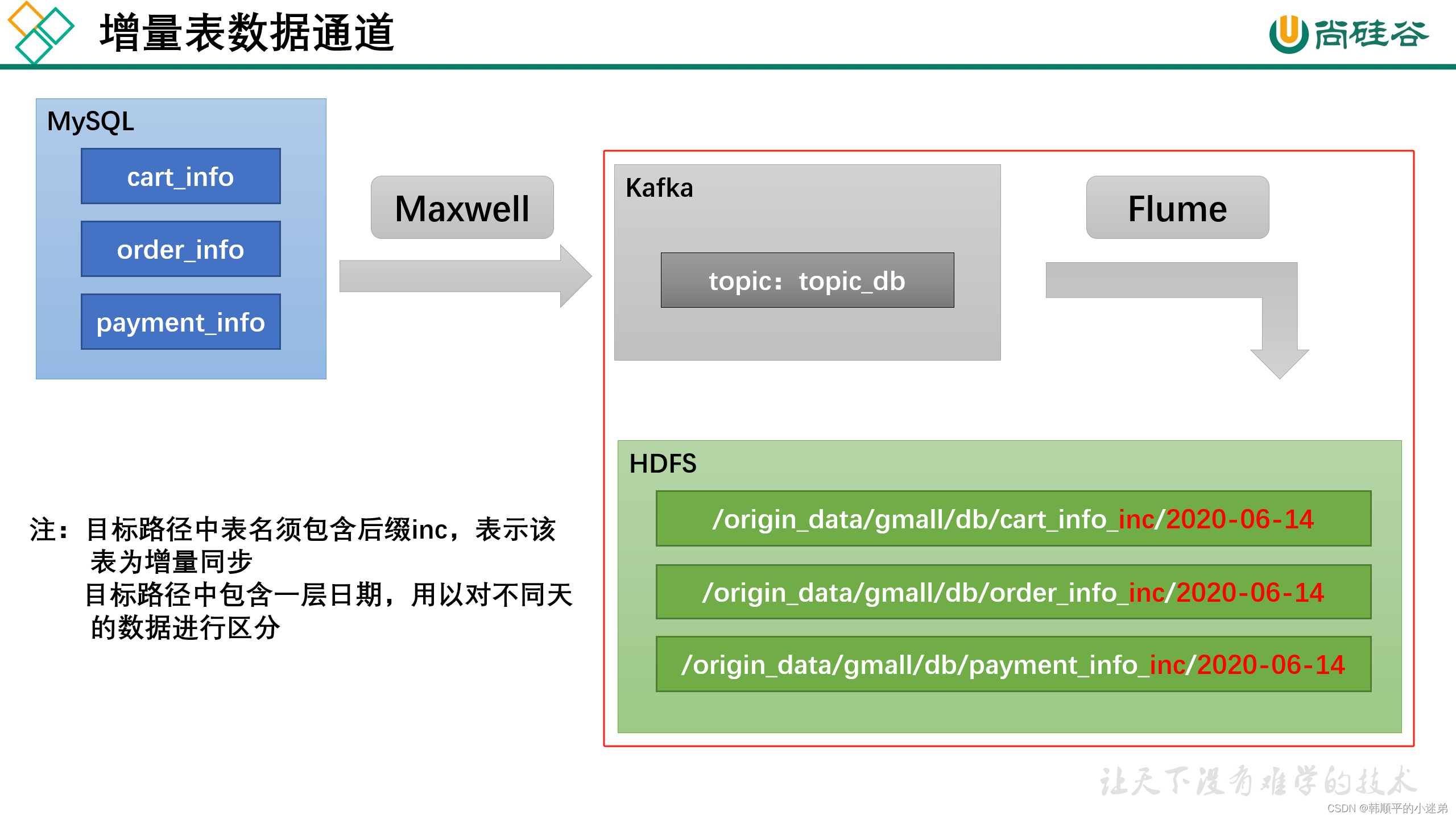
业务数据采集通道分为全量同步和增量同步。
- 全量表数据由DataX从MySQL业务数据库直接同步到HDFS。
- 增量表数据由Maxwell从Mysql业务数据库同步到kafka集群的topic_db主题,topic_db主题数据再由flume采集到hdfs集群。
4.1 全量数据同步
全量表数据由DataX从MySQL业务数据库直接同步到HDFS。所有的全量表如下所示:
- activity_info
- activity_rule
- base_category1
- base_category2
- base_category3
- base_dic
- base_province
- base_region
- base_trademark
- cart_info
- coupon_info
- sku_attr_value
- sku_info
- sku_sale_attr_value
- spu_info
4.1.1 数据通道
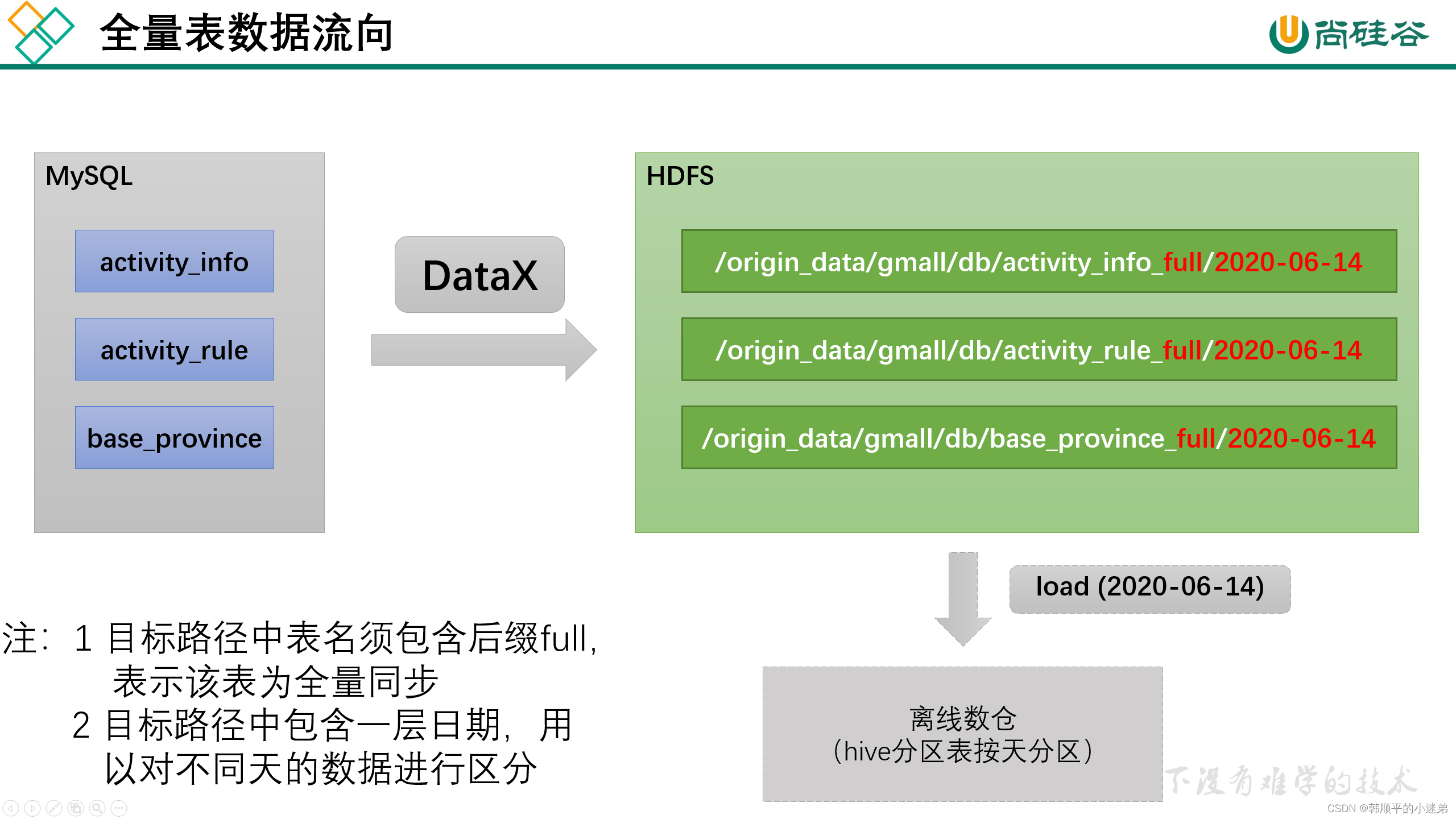
数据流向如下图所示:
4.1.2 DataX配置文件
我们需要为每张全量表编写一个DataX的json配置文件,此处以activity_info为例,配置文件内容如下:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"activity_name",
"activity_type",
"activity_desc",
"start_time",
"end_time",
"create_time"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://hadoop102:3306/gmall"
],
"table": [
"activity_info"
]
}
],
"password": "000000",
"splitPk": "",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "bigint"
},
{
"name": "activity_name",
"type": "string"
},
{
"name": "activity_type",
"type": "string"
},
{
"name": "activity_desc",
"type": "string"
},
{
"name": "start_time",
"type": "string"
},
{
"name": "end_time",
"type": "string"
},
{
"name": "create_time",
"type": "string"
}
],
"compress": "gzip",
"defaultFS": "hdfs://hadoop102:8020",
"fieldDelimiter": "\t",
"fileName": "activity_info",
"fileType": "text",
"path": "${targetdir}",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}
注:由于目标路径包含一层日期,用于对不同天的数据加以区分,故path参数并未写死,需在提交任务时通过参数动态传入,参数名称为targetdir
4.1.3 DataX配置文件生成脚本
由于每个全量表都需要编写一个DataX的json配置文件,大量的全量表让我们很难为每一个表手动编写DataX的json配置文件。故写一个脚本gen_import_config.py来生成我们所需要的DataX的json配置文件。脚本需要两个参数 -d 数据库 -t 表名。生成的DataX的json配置会保存在/opt/module/datax/job/import目录下,文件名为数据库.表名.json。脚本编写步骤如下:
1) 在~/bin目录下创建gen_import_config.py脚本
[atguigu@hadoop102 bin]$ vim ~/bin/gen_import_config.py
2)脚本内容
# ecoding=utf-8
import json
import getopt
import os
import sys
import MySQLdb
#MySQL相关配置,需根据实际情况作出修改
mysql_host = "hadoop102"
mysql_port = "3306"
mysql_user = "root"
mysql_passwd = "000000"
#HDFS NameNode相关配置,需根据实际情况作出修改
hdfs_nn_host = "hadoop102"
hdfs_nn_port = "8020"
#生成配置文件的目标路径,可根据实际情况作出修改
output_path = "/opt/module/datax/job/import"
def get_connection():
return MySQLdb.connect(host=mysql_host, port=int(mysql_port), user=mysql_user, passwd=mysql_passwd)
def get_mysql_meta(database, table):
connection = get_connection()
cursor = connection.cursor()
sql = "SELECT COLUMN_NAME,DATA_TYPE from information_schema.COLUMNS WHERE TABLE_SCHEMA=%s AND TABLE_NAME=%s ORDER BY ORDINAL_POSITION"
cursor.execute(sql, [database, table])
fetchall = cursor.fetchall()
cursor.close()
connection.close()
return fetchall
def get_mysql_columns(database, table):
return map(lambda x: x[0], get_mysql_meta(database, table))
def get_hive_columns(database, table):
def type_mapping(mysql_type):
mappings = {
"bigint": "bigint",
"int": "bigint",
"smallint": "bigint",
"tinyint": "bigint",
"decimal": "string",
"double": "double",
"float": "float",
"binary": "string",
"char": "string",
"varchar": "string",
"datetime": "string",
"time": "string",
"timestamp": "string",
"date": "string",
"text": "string"
}
return mappings[mysql_type]
meta = get_mysql_meta(database, table)
return map(lambda x: {"name": x[0], "type": type_mapping(x[1].lower())}, meta)
def generate_json(source_database, source_table):
job = {
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": mysql_user,
"password": mysql_passwd,
"column": get_mysql_columns(source_database, source_table),
"splitPk": "",
"connection": [{
"table": [source_table],
"jdbcUrl": ["jdbc:mysql://" + mysql_host + ":" + mysql_port + "/" + source_database]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://" + hdfs_nn_host + ":" + hdfs_nn_port,
"fileType": "text",
"path": "${targetdir}",
"fileName": source_table,
"column": get_hive_columns(source_database, source_table),
"writeMode": "append",
"fieldDelimiter": "\t",
"compress": "gzip"
}
}
}]
}
}
if not os.path.exists(output_path):
os.makedirs(output_path)
with open(os.path.join(output_path, ".".join([source_database, source_table, "json"])), "w") as f:
json.dump(job, f)
def main(args):
source_database = ""
source_table = ""
options, arguments = getopt.getopt(args, '-d:-t:', ['sourcedb=', 'sourcetbl='])
for opt_name, opt_value in options:
if opt_name in ('-d', '--sourcedb'):
source_database = opt_value
if opt_name in ('-t', '--sourcetbl'):
source_table = opt_value
generate_json(source_database, source_table)
if __name__ == '__main__':
main(sys.argv[1:])
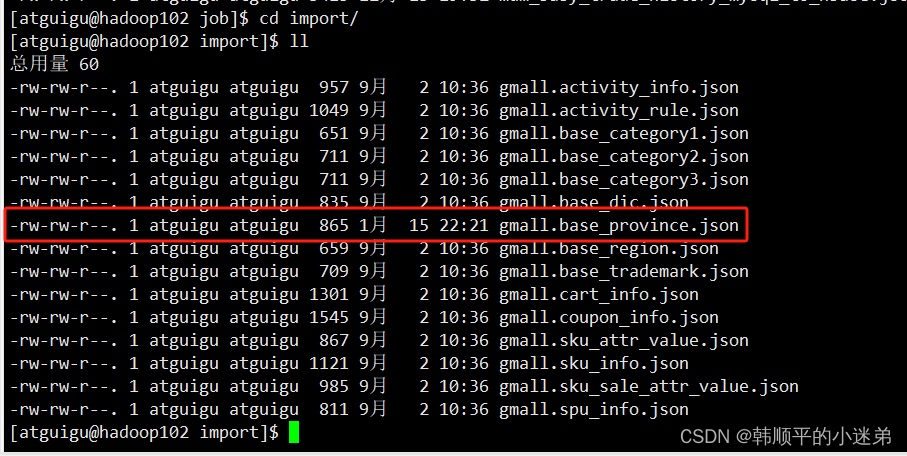
3)测试脚本生成效果,以gmall数据库中的base_province为例:
- 执行脚本
python ~/bin/gen_import_config.py -d gmall -t base_province - 生成效果如下:


4)在~/bin目录下创建gen_import_config.sh脚本
这个脚本用于生成所有全量表对应的DataX的配置JSON文件。
[atguigu@hadoop102 bin]$ vim ~/bin/gen_import_config.sh
脚本内容如下:
#!/bin/bash
python ~/bin/gen_import_config.py -d gmall -t activity_info
python ~/bin/gen_import_config.py -d gmall -t activity_rule
python ~/bin/gen_import_config.py -d gmall -t base_category1
python ~/bin/gen_import_config.py -d gmall -t base_category2
python ~/bin/gen_import_config.py -d gmall -t base_category3
python ~/bin/gen_import_config.py -d gmall -t base_dic
python ~/bin/gen_import_config.py -d gmall -t base_province
python ~/bin/gen_import_config.py -d gmall -t base_region
python ~/bin/gen_import_config.py -d gmall -t base_trademark
python ~/bin/gen_import_config.py -d gmall -t cart_info
python ~/bin/gen_import_config.py -d gmall -t coupon_info
python ~/bin/gen_import_config.py -d gmall -t sku_attr_value
python ~/bin/gen_import_config.py -d gmall -t sku_info
python ~/bin/gen_import_config.py -d gmall -t sku_sale_attr_value
python ~/bin/gen_import_config.py -d gmall -t spu_info
为gen_import_config.sh脚本增加执行权限
[atguigu@hadoop102 bin]$ chmod 777 ~/bin/gen_import_config.sh
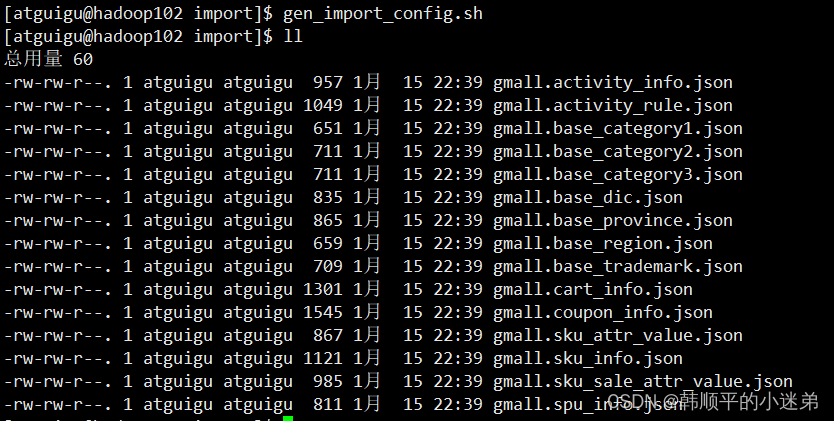
5)执行gen_import_config.sh脚本,生成配置文件,观察效果
[atguigu@hadoop102 bin]$ gen_import_config.sh
4.1.4 测试生成的DataX配置文件
以base_province为例,测试用脚本生成的配置文件是否可用。
1)创建目标路径
由于DataX同步任务要求目标路径提前存在,故需手动创建路径,当前base_province表的目标路径应为/origin_data/gmall/db/base_province_full/2020-06-14。
[atguigu@hadoop102 bin]$ hadoop fs -mkdir /origin_data/gmall/db/base_province_full/2020-06-14
2)执行DataX同步命令
[atguigu@hadoop102 bin]$ python /opt/module/datax/bin/datax.py -p"-Dtargetdir=/origin_data/gmall/db/base_province_full/2020-06-14" /opt/module/datax/job/import/gmall.base_province.json
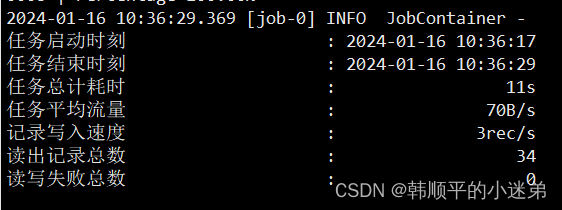
3)观察同步结果
(1)datax的打印日志如下:
(2)hdfs的目标数据如下:
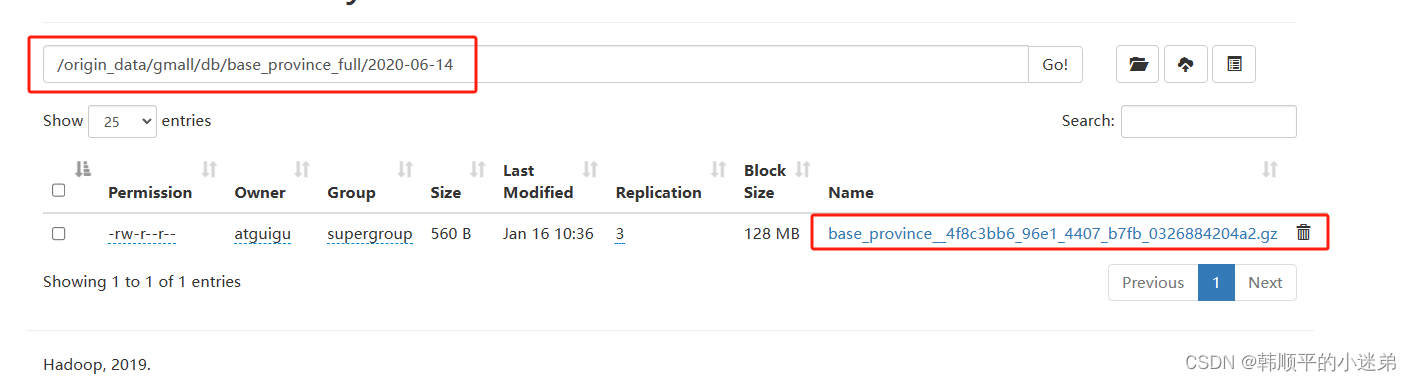
(3)hadoop查看解压内容
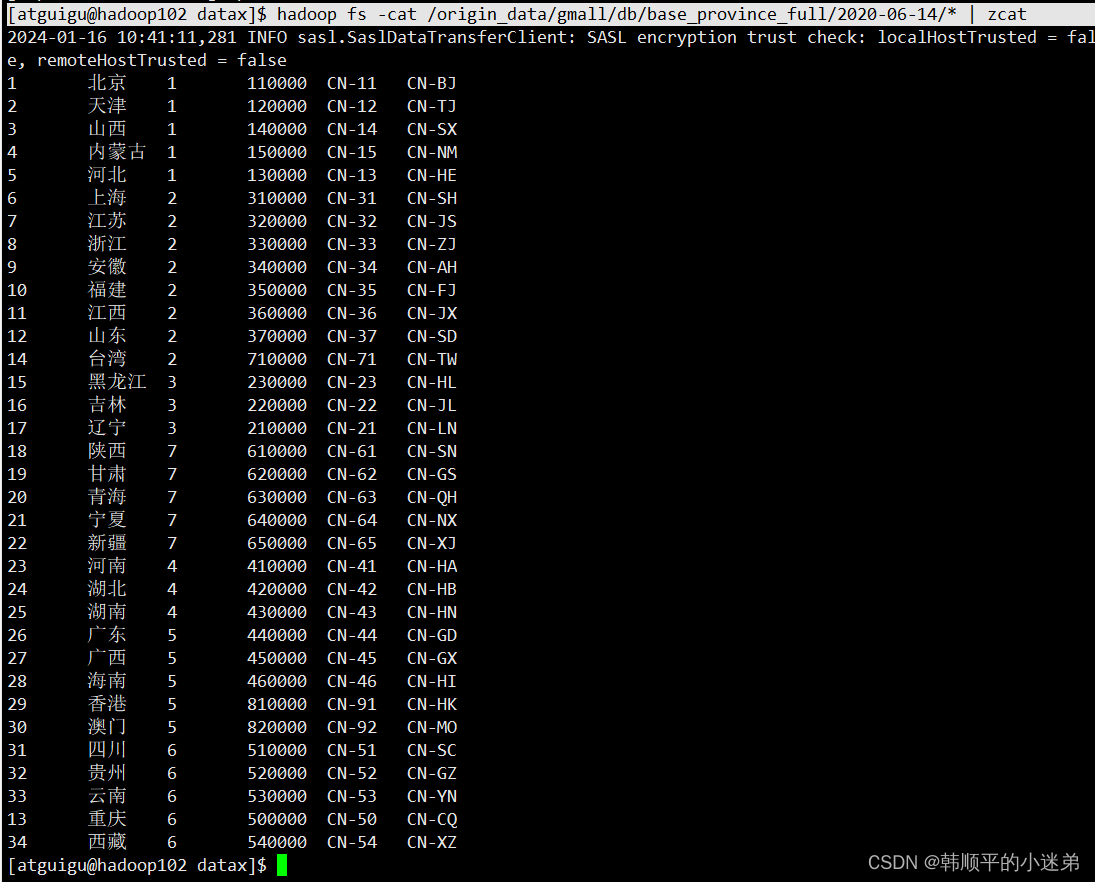
执行命令如下:
[atguigu@hadoop102 datax]$ hadoop fs -cat /origin_data/gmall/db/base_province_full/2020-06-14/* | zcat
结果如下:
4.1.5 全量表数据同步脚本
1)在~/bin目录创建mysql_to_hdfs_full.sh
[atguigu@hadoop102 bin]$ vim ~/bin/mysql_to_hdfs_full.sh
脚本内容如下:
#!/bin/bash
DATAX_HOME=/opt/module/datax
# 如果传入日期则do_date等于传入的日期,否则等于前一天日期
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d "-1 day" +%F`
fi
#处理目标路径,此处的处理逻辑是,如果目标路径不存在,则创建;若存在,则清空,目的是保证同步任务可重复执行
handle_targetdir() {
hadoop fs -test -e $1
if [[ $? -eq 1 ]]; then
echo "路径$1不存在,正在创建......"
hadoop fs -mkdir -p $1
else
echo "路径$1已经存在"
fs_count=$(hadoop fs -count $1)
content_size=$(echo $fs_count | awk '{print $3}')
if [[ $content_size -eq 0 ]]; then
echo "路径$1为空"
else
echo "路径$1不为空,正在清空......"
hadoop fs -rm -r -f $1/*
fi
fi
}
#数据同步
import_data() {
datax_config=$1
target_dir=$2
handle_targetdir $target_dir
python $DATAX_HOME/bin/datax.py -p"-Dtargetdir=$target_dir" $datax_config
}
case $1 in
"activity_info")
import_data /opt/module/datax/job/import/gmall.activity_info.json /origin_data/gmall/db/activity_info_full/$do_date
;;
"activity_rule")
import_data /opt/module/datax/job/import/gmall.activity_rule.json /origin_data/gmall/db/activity_rule_full/$do_date
;;
"base_category1")
import_data /opt/module/datax/job/import/gmall.base_category1.json /origin_data/gmall/db/base_category1_full/$do_date
;;
"base_category2")
import_data /opt/module/datax/job/import/gmall.base_category2.json /origin_data/gmall/db/base_category2_full/$do_date
;;
"base_category3")
import_data /opt/module/datax/job/import/gmall.base_category3.json /origin_data/gmall/db/base_category3_full/$do_date
;;
"base_dic")
import_data /opt/module/datax/job/import/gmall.base_dic.json /origin_data/gmall/db/base_dic_full/$do_date
;;
"base_province")
import_data /opt/module/datax/job/import/gmall.base_province.json /origin_data/gmall/db/base_province_full/$do_date
;;
"base_region")
import_data /opt/module/datax/job/import/gmall.base_region.json /origin_data/gmall/db/base_region_full/$do_date
;;
"base_trademark")
import_data /opt/module/datax/job/import/gmall.base_trademark.json /origin_data/gmall/db/base_trademark_full/$do_date
;;
"cart_info")
import_data /opt/module/datax/job/import/gmall.cart_info.json /origin_data/gmall/db/cart_info_full/$do_date
;;
"coupon_info")
import_data /opt/module/datax/job/import/gmall.coupon_info.json /origin_data/gmall/db/coupon_info_full/$do_date
;;
"sku_attr_value")
import_data /opt/module/datax/job/import/gmall.sku_attr_value.json /origin_data/gmall/db/sku_attr_value_full/$do_date
;;
"sku_info")
import_data /opt/module/datax/job/import/gmall.sku_info.json /origin_data/gmall/db/sku_info_full/$do_date
;;
"sku_sale_attr_value")
import_data /opt/module/datax/job/import/gmall.sku_sale_attr_value.json /origin_data/gmall/db/sku_sale_attr_value_full/$do_date
;;
"spu_info")
import_data /opt/module/datax/job/import/gmall.spu_info.json /origin_data/gmall/db/spu_info_full/$do_date
;;
"all")
import_data /opt/module/datax/job/import/gmall.activity_info.json /origin_data/gmall/db/activity_info_full/$do_date
import_data /opt/module/datax/job/import/gmall.activity_rule.json /origin_data/gmall/db/activity_rule_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_category1.json
import_data /opt/module/datax/job/import/gmall.base_category1.json /origin_data/gmall/db/base_category1_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_category2.json /origin_data/gmall/db/base_category2_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_category3.json /origin_data/gmall/db/base_category3_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_dic.json /origin_data/gmall/db/base_dic_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_province.json /origin_data/gmall/db/base_province_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_region.json /origin_data/gmall/db/base_region_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_trademark.json /origin_data/gmall/db/base_trademark_full/$do_date
import_data /opt/module/datax/job/import/gmall.cart_info.json /origin_data/gmall/db/cart_info_full/$do_date
import_data /opt/module/datax/job/import/gmall.coupon_info.json /origin_data/gmall/db/coupon_info_full/$do_date
import_data /opt/module/datax/job/import/gmall.sku_attr_value.json /origin_data/gmall/db/sku_attr_value_full/$do_date
import_data /opt/module/datax/job/import/gmall.sku_info.json /origin_data/gmall/db/sku_info_full/$do_date
import_data /opt/module/datax/job/import/gmall.sku_sale_attr_value.json /origin_data/gmall/db/sku_sale_attr_value_full/$do_date
import_data /opt/module/datax/job/import/gmall.spu_info.json /origin_data/gmall/db/spu_info_full/$do_date
;;
esac
2)为mysql_to_hdfs_full.sh增加执行权限
[atguigu@hadoop102 bin]$ chmod 777 ~/bin/mysql_to_hdfs_full.sh
3)测试同步脚本
[atguigu@hadoop102 bin]$ mysql_to_hdfs_full.sh all 2020-06-14
4)检查同步结果
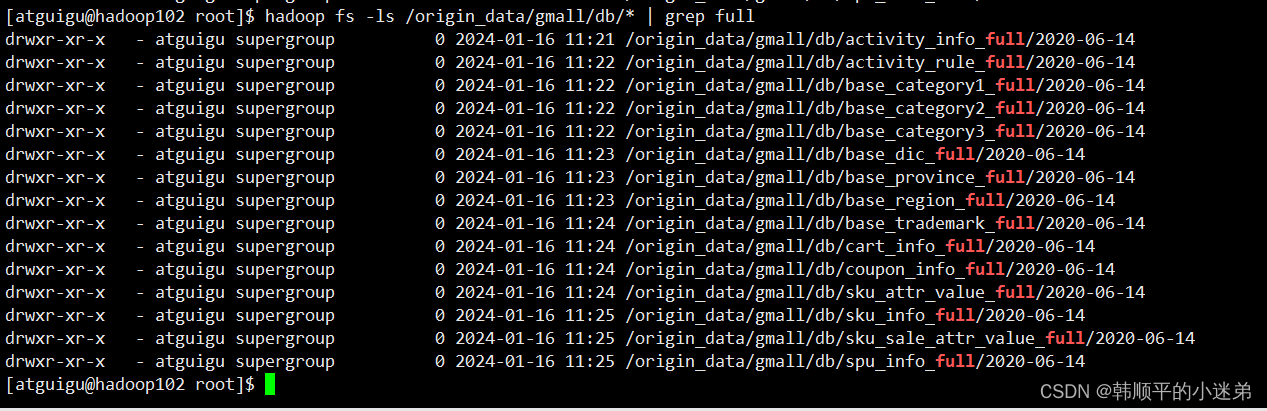
查看HDFS目表路径是否出现全量表数据,全量表共15张。
执行命令:hadoop fs -ls /origin_data/gmall/db/* | grep full
4.2 增量数据同步
4.2.1 业务数据采集通道Mysql->Kafka
1)业务数据通道
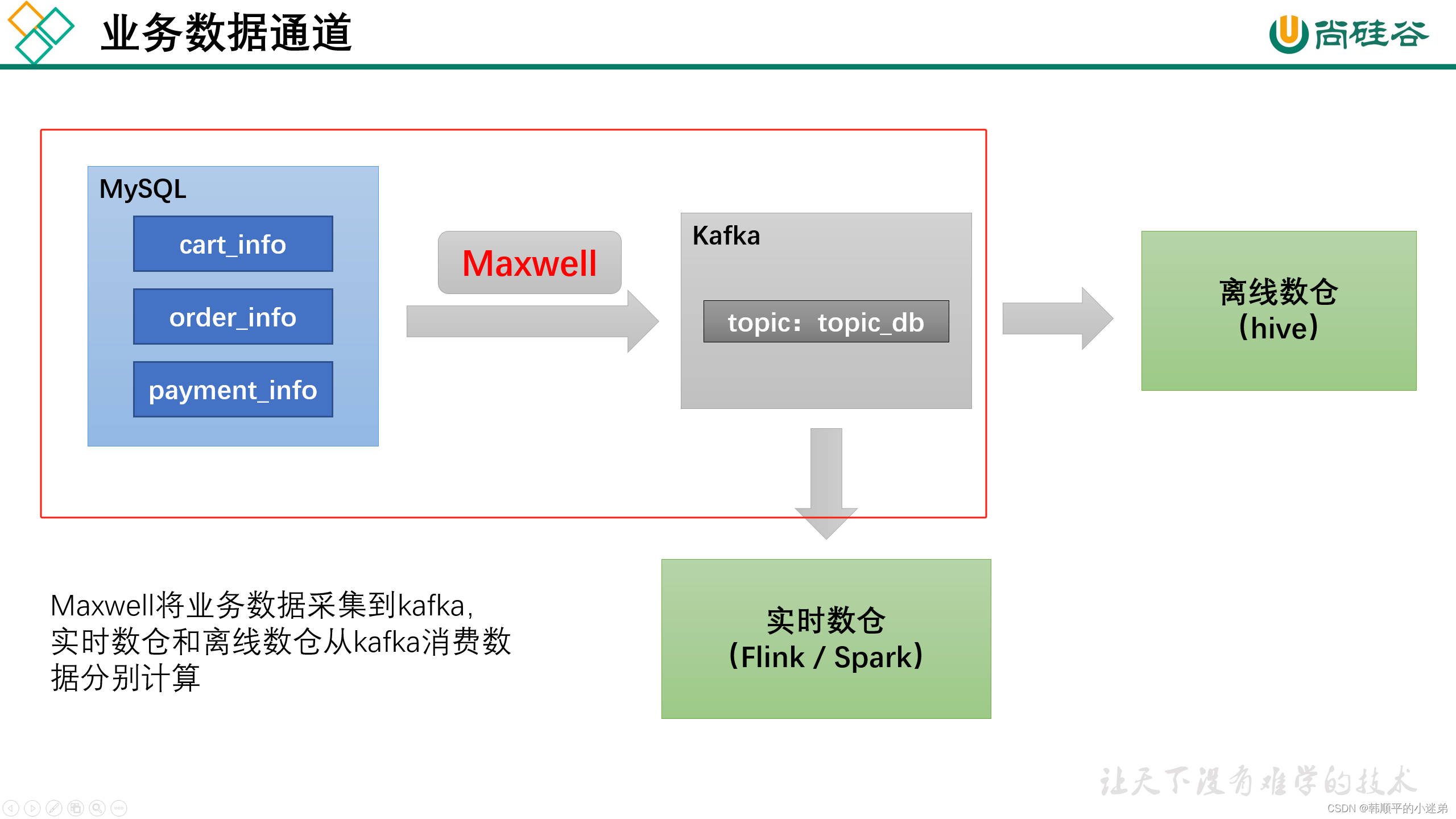
使用Maxwell把mysql数据增量同步到kafka的topic_db主题。
2)采集通道Maxwell配置
(0)Maxwell学习见:https://blog.csdn.net/qq_41246557/article/details/135599215
(1)Maxwell时间戳问题
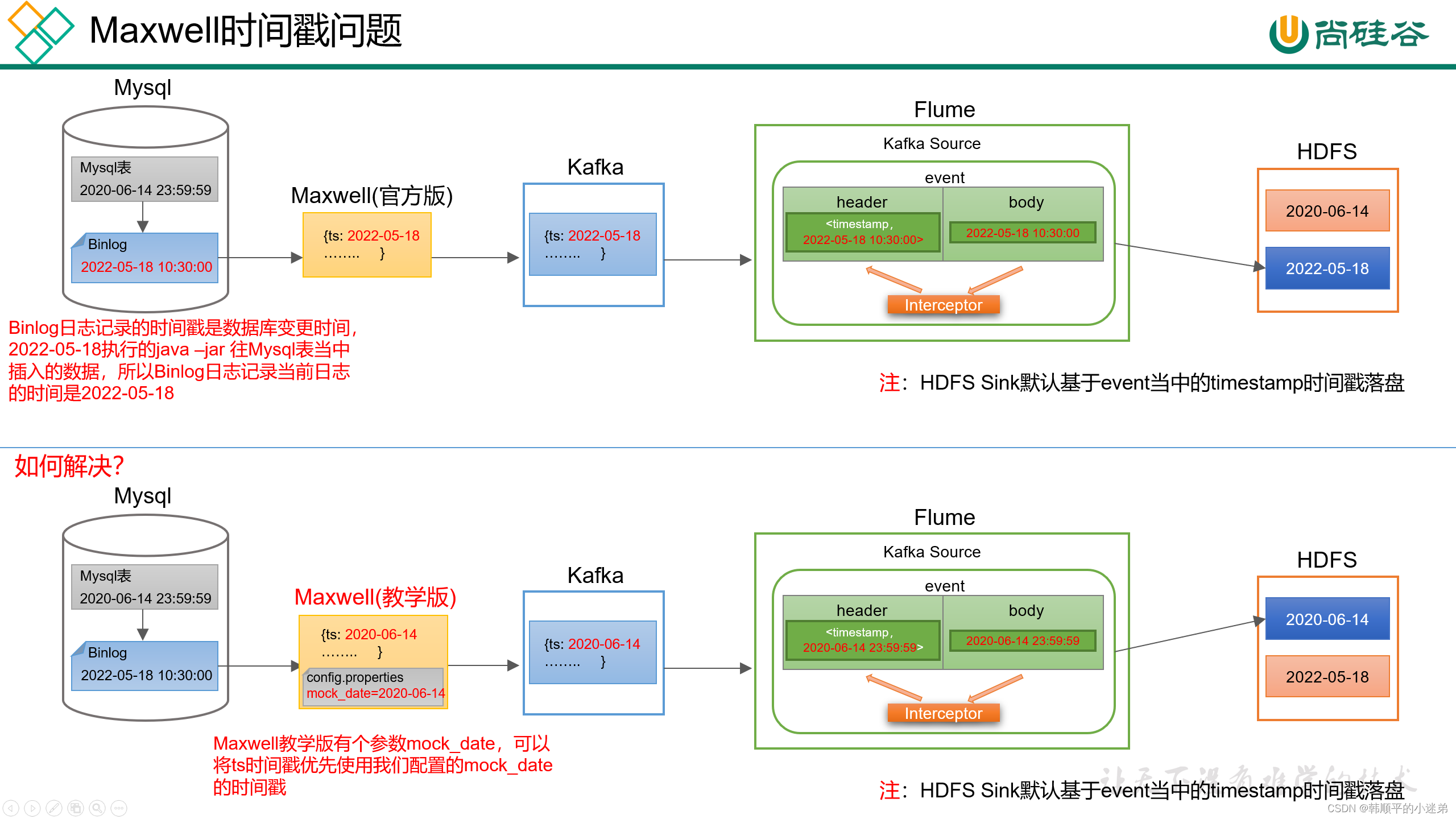
??此处为了模拟真实环境,对Maxwell源码进行了改动,增加了一个参数mock_date,该参数的作用就是指定Maxwell输出JSON字符串的ts时间戳的日期,接下来进行测试。
(2)修改Maxwell配置文件config.properties,增加mock_data参数,如下:
log_level=info
producer=kafka
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092
#kafka topic配置
kafka_topic=topic_db
#注:该参数仅在maxwell教学版中存在,修改该参数后重启Maxwell才可生效
mock_date=2020-06-14
# mysql login info
host=hadoop102
user=maxwell
password=maxwell
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai
注:该参数仅供学习使用,修改该参数后重启Maxwell才可生效。
(3)重启Maxwell(mxw.sh脚本见Maxwell文章)
[atguigu@hadoop102 bin]$ mxw.sh restart
3)测试通道
(0)启动zookeeper、kafka集群
(1)启动kafka消费者
/opt/module/kafka/bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic topic_db
(2)重新生成模拟数据
[atguigu@hadoop102 bin]$ cd /opt/module/db_log/
[atguigu@hadoop102 db_log]$ java -jar gmall2020-mock-db-2021-11-14.jar
(3)观察kafka输出
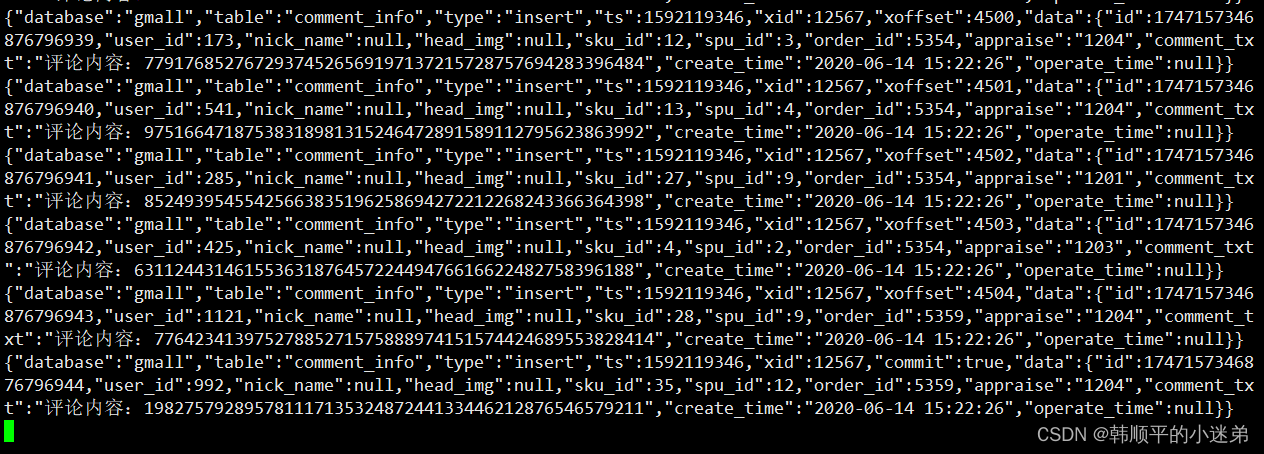
4.2.2 业务数据采集通道Kafka->hdfs
1)Flume配置
1)Flume配置概述
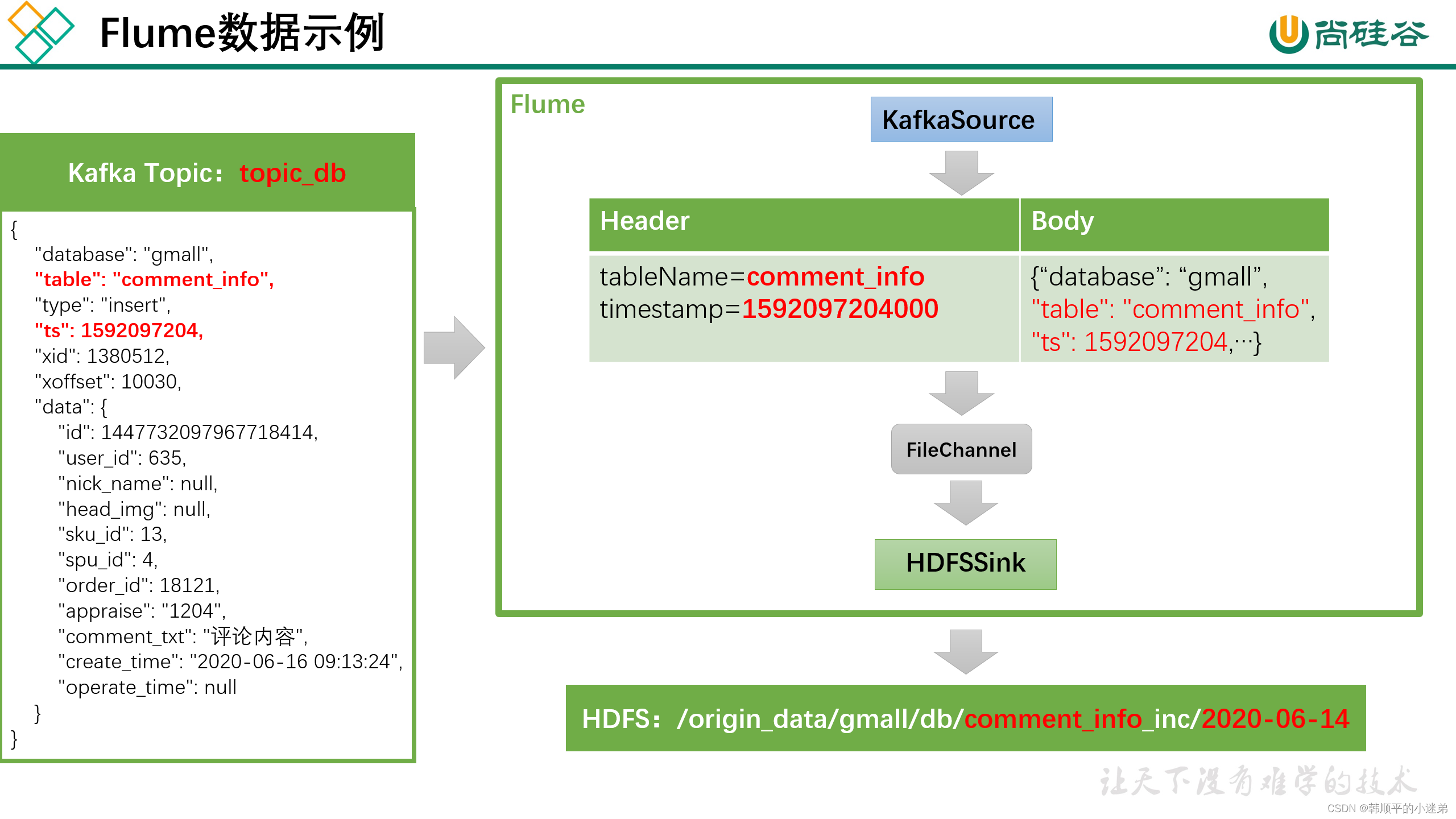
??Flume需要将Kafka中topic_db主题的数据传输到HDFS,故其需选用KafkaSource以及HDFSSink,Channel选用FileChannel。
??需要注意的是, HDFSSink需要将不同mysql业务表的数据写到不同的路径,并且路径中应当包含一层日期,用于区分每天的数据。关键配置如下:

具体数据示例如下:
2)配置Flume
(1)创建Flume配置文件
??在hadoop104节点的Flume的job目录下创建kafka_to_hdfs_db.conf
[atguigu@hadoop104 flume]$ mkdir job
[atguigu@hadoop104 flume]$ vim job/kafka_to_hdfs_db.conf
(2)配置文件内容如下:
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.sources.r1.kafka.topics = topic_db
a1.sources.r1.kafka.consumer.group.id = flume
a1.sources.r1.setTopicHeader = true
a1.sources.r1.topicHeader = topic
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.TimestampAndTableNameInterceptor$Builder
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior2
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior2/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/db/%{tableName}_inc/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = db
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
(3)编写Flume拦截器,见文档
flume拦截器获取Maxwell中的表名和ts日期,作为参数传给flume中的HDFSsink,目的是为了生成基于表名和时间的动态hdfs目录。
3)编写Flume启动脚本
(1)在hadoop102节点的/home/atguigu/bin目录下创建脚本f3.sh
[atguigu@hadoop102 bin]$ vim f3.sh
在脚本中填写如下内容:
#!/bin/bash
case $1 in
"start")
echo " --------启动 hadoop104 业务数据flume-------"
ssh hadoop104 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs_db.conf >/dev/null 2>&1 &"
;;
"stop")
echo " --------停止 hadoop104 业务数据flume-------"
ssh hadoop104 "ps -ef | grep kafka_to_hdfs_db | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esac
(2)添加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 f3.sh
(3)f3启动
[atguigu@hadoop102 module]$ f3.sh start
(4)f3停止
[atguigu@hadoop102 module]$ f3.sh stop
2)maxwell和flume双通道测试
(1)启动Zookeeper、Kafka集群
(2)启动Maxwell采集通道,把数据从mysql采集到Kafka
mxw.sh start
(3)开启flume采集通道,把kafka数据采集到hdfs
f3.sh start
(4)生成模拟数据
[atguigu@hadoop102 bin]$ cd /opt/module/db_log/
[atguigu@hadoop102 db_log]$ java -jar gmall2020-mock-db-2021-11-14.jar
(5)HDFS上观察数据
执行命令:hadoop fs -ls /origin_data/gmall/db/* | grep _inc/
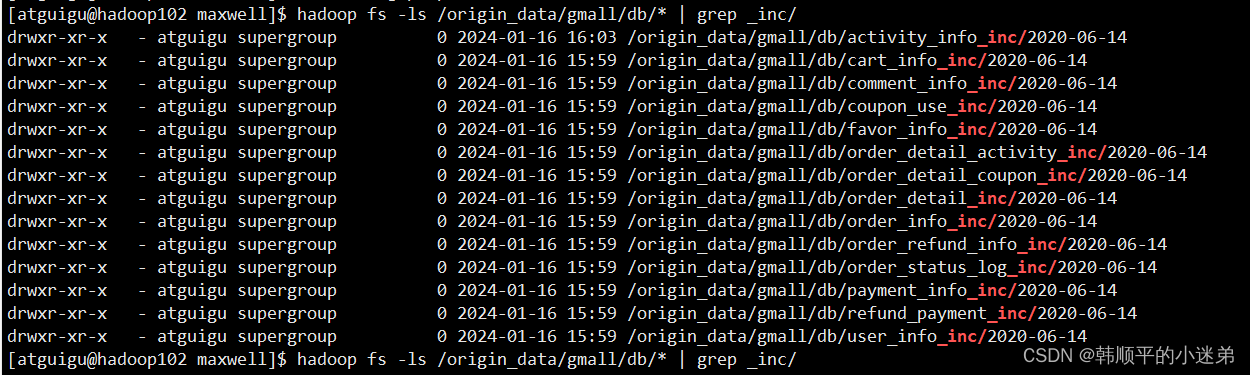
4.2.3 增量表首日全量同步
??通常情况下,增量表需要在首日进行一次全量同步,后续每日再进行增量同步,首日全量同步可以使用Maxwell的bootstrap功能,方便起见,下面编写一个增量表首日全量同步脚本。
1)在~/bin目录创建mysql_to_kafka_inc_init.sh
[atguigu@hadoop102 bin]$ vim mysql_to_kafka_inc_init.sh
脚本内容如下:
#!/bin/bash
# 该脚本的作用是初始化所有的增量表,只需执行一次
MAXWELL_HOME=/opt/module/maxwell
import_data() {
$MAXWELL_HOME/bin/maxwell-bootstrap --database gmall --table $1 --config $MAXWELL_HOME/config.properties
}
case $1 in
"cart_info")
import_data cart_info
;;
"comment_info")
import_data comment_info
;;
"coupon_use")
import_data coupon_use
;;
"favor_info")
import_data favor_info
;;
"order_detail")
import_data order_detail
;;
"order_detail_activity")
import_data order_detail_activity
;;
"order_detail_coupon")
import_data order_detail_coupon
;;
"order_info")
import_data order_info
;;
"order_refund_info")
import_data order_refund_info
;;
"order_status_log")
import_data order_status_log
;;
"payment_info")
import_data payment_info
;;
"refund_payment")
import_data refund_payment
;;
"user_info")
import_data user_info
;;
"all")
import_data cart_info
import_data comment_info
import_data coupon_use
import_data favor_info
import_data order_detail
import_data order_detail_activity
import_data order_detail_coupon
import_data order_info
import_data order_refund_info
import_data order_status_log
import_data payment_info
import_data refund_payment
import_data user_info
;;
esac
2)为mysql_to_kafka_inc_init.sh增加执行权限
[atguigu@hadoop102 bin]$ chmod 777 ~/bin/mysql_to_kafka_inc_init.sh
3)测试同步脚本
(1)清理历史数据
为方便查看结果,现将HDFS上之前同步的增量表数据删除
[atguigu@hadoop102 ~]$ hadoop fs -ls /origin_data/gmall/db | grep _inc | awk '{print $8}' | xargs hadoop fs -rm -r -f
(2)执行同步脚本
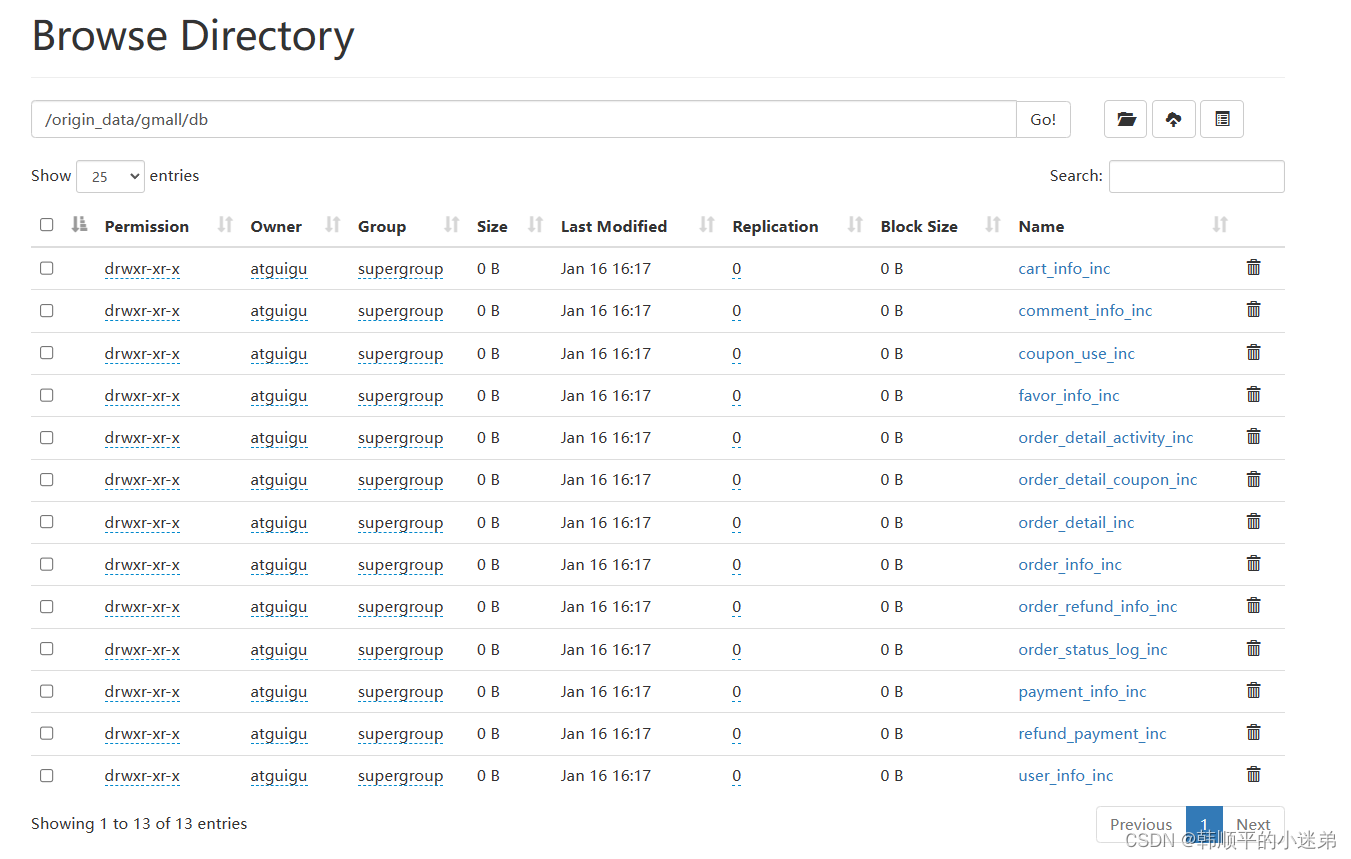
[atguigu@hadoop102 bin]$ mysql_to_kafka_inc_init.sh all
4)检查同步结果
5 数据仓库采集部分完结
数据仓库采集部分完成:后续更新数据建模,数据指标计算。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 电商“仅退款”全面开打,淘宝、京东、拼多多2024开战
- Intel Processor Trace(一)
- 基础数论二:分解质因数、筛质数
- This request has been blocked; the content must be served over HTTPS.
- markdown公式编写备忘录
- JavaScript 中常用事件
- TransRPPG
- TypeScript入门笔记1
- 思腾云计算
- VB.NET创建AOT无依懒的winform 独立EXE,动态库如何调用?