关于论文《Deep Convolutional Pooling Transformer forDeepfake Detection》阅读笔记
一.关于卷积的一些基础知识
1.卷积操作:
卷积操作通过使用滤波器(也称为卷积核或过滤器)在输入数据上滑动,学习输入数据的局部特征。每个滤波器生成一个特征图,其中包含检测到的特定特征。
滤波器的数量决定了输出的特征图的深度。这样,卷积层能够学习多个不同特征的表示。在图像处理中,这些特征可以是边缘、纹理等。
卷积层的输出通常被送入非线性激活函数,如ReLU,以引入非线性性(非线性函数表达能力更强)
2.多层感知器(MLP):
卷积操作后得到的特征图可以被展平成一维向量,然后输入到MLP中进行进一步的处理。
MLP是一种全连接的神经网络结构,其目的是通过学习从卷积层提取的高级特征来执行分类、回归等任务。
MLP的每个神经元与前一层的所有神经元相连接,因此MLP能够学习输入数据中的更复杂的模式和表示。
所以,整个过程可以概括为:
1.卷积层通过滤波器学习局部特征,生成多个特征图。
2.这些特征图被展平成一维向量。
3.一维向量输入到MLP中,MLP学习将这些高级特征映射到最终的输出,如分类标签。
多层前馈神经网络:
多层:多个隐含层
前馈:前向传播,无环路
神经网络:NN,由神经元组成
--------------------------------------------------------------------------------------------
当我们谈论Vision Transformer(ViT),我们实际上在讨论一种用于图像处理任务的深度学习模型,它与传统的卷积神经网络(CNN)不同,采用了全新的结构。ViT是一种基于自注意力机制的模型,它是由Google在2020年提出的。让我们来详细了解Vision Transformer的一些关键概念和组成部分。
1.自注意力机制(Self-Attention): Vision Transformer的核心是自注意力机制,也称为注意力机制。这使得模型能够在处理图像时关注图像的不同部分,而不仅仅是局限于局部区域。这种机制允许模型在全局范围内理解图像的语境和关联。
2.图像划分为小块(Patches): 为了将图像输入到Transformer中,ViT首先将图像划分为一系列小块,这些小块被称为“patches”。每个patch会被拉平成一个向量,作为输入传递给Transformer。
3.位置嵌入(Positional Embeddings): 由于Transformer没有卷积神经网络中的位置感知性,ViT引入了位置嵌入以提供关于每个patch在图像中位置的信息。
4.Transformer编码器: 将图像的patch表示输入到Transformer编码器中,这个编码器由多个自注意力层组成。这些层允许模型在学习中捕获图像的全局和局部信息。
5.分类头部: 最后,ViT使用一个全连接层来输出最终的分类结果,这是通过对所有patch的表示进行平均或采用其他池化操作来实现的。
对于图像分类任务,模型通过前面的层学习提取图像中的特征,然后将这些特征传递给一个全连接层,这个全连接层即是分类头部。全连接层的输出节点数量通常等于数据集中的类别数量,每个节点对应一个类别。分类头部的输出可以经过softmax函数,将模型的原始输出转换为概率分布,使得每个类别的概率值在0到1之间且和为1。在推理阶段,模型输出的概率最高的类别即为模型对输入图像的分类结果。
-----------------------------------------------------------------------------------------
这篇论文先用CNN进行特征提取,随后输入到vision transformer中,但对vision transformer进行了改动,将vision transformer划分为3个阶段,每个阶段之后跟着一个最大池化操作,目的是为了降低特征图 的尺寸,随后就是多头自注意模块,为了防止多头学习到相同的内容(退化成单注意力头)添加了一个可学习的参数
ViT的输入是图像的块,因此输入的维度和通道数取决于块的大小和图像的通道数。如果整个图像的大小是(H,W),每个块的大小是(h,w),且图像有C个通道,那么ViT的输入维度将是(h * w,C)。
对于vit,我的理解就是对图像分配权重的过程,其输入和输出的维度和通道数是一致的。
--------------------------------------------------------------------------------------------------------------------
二.对论文的讲解部分
1.论文的整体架构
[卷积(特征抽取)]--->[将特征图划分为patch块,输入到vit中(进行深度可分离的卷积映射获得Q、K、V)]----->[计算特征相似度----->进行最大池化操作----->再次计算特征相似度--->最大池化操作---->再词计算特征相似度----->]输入到MLP中进行分类任务

2.介绍了图像的压缩原理,一般只要保留I帧就可以对图像进行压缩,而本文是直接从视频中截取图像,故降低了图像因压缩带来的信息损失。
原文描述:“在Deepfake检测中,图像帧提取过程在视频解码的图像帧重建过程中会损失p帧和b帧的信息。考虑到超现实的Deepfake视频中几乎没有可以轻易发现的假线索,在检测假脸时,从视频中收集尽可能多的关键帧是很重要的。”

3.CNN提取图像特征

共17个卷积层,分为5组,除了第一组将特征图的通道数从3增加到32,其余都是将特征图的通道数增加1倍。输入的图像尺度3*224*224卷积之后输出的尺寸512*7*7,然后将提取的局部特征输入到Transformer部分进行全局特征学习和关系分析。
4.vit(深度可分离卷积与重注意力机制)

深度可分离卷积投影和深度重新关注来增强其学习能力
自注意力计算公式:

传统的方法使用与特征图尺寸相同,通道数为1的投影映射操作,这种操作将特征映射降至1的维度,这将显著地丢弃决定特征,从而降低了模型的性能。
故作者在论文提出使用池化transformer
对于多头self-attention的内容此处简略描述
将输入图像展平添加位置编码,输入到SA中进行计算


池化的作用是调节感受野,池化操作后,随着特征补丁数量的减少,特征补丁之间的相互作用也随之增加。详细地说,Transformer块被分为三个阶段,每两个连续阶段之间有一个卷积池。
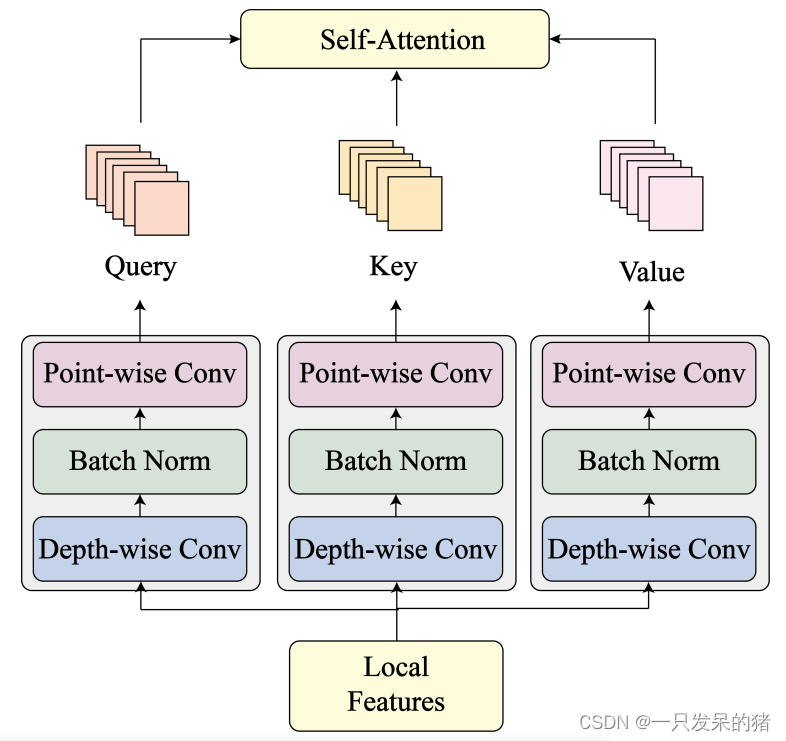
考虑到cnn在图像分析方面相对于线性投影的优势,我们进一步将深度可分离卷积引入到Q、K和V矩阵的生成过程中,以丰富多头自关注计算的图像特征学习。详细地说,我们替换了三个完全连接的层来生成Q、K和V,每个层都有一个深度可分离的卷积,然后在投影每个Transformer块中的输入特征时进行批处理归一化。为了保持稳定的模型架构,可分离卷积被设置为只执行投影,同时保持从局部特征提取模块提取的特征维度。深度可分卷积是为了避免标准CNN中由于参数过多而可能出现的过拟合和耗时问题。
深度可分离卷积将标准CNN分为深度卷积和点卷积。
前者是一种空间卷积,仅在通道不变的情况下修改特征映射维数,后者仅改变通道数。
通过对矩阵投影采用深度可分离卷积,该模型可以分析更丰富的图像特征。
2)深度重注意:对于复杂的图像任务,具有大量Transformer块的深度模型是必要的。
深度ViT模型中注意图往往过于相似,并且随着模型的深入,可以观察到明显的性能下降。论文中分三个阶段构建了一个共24个Transformer块的深池Transformer,并采用了具有可学习变换矩阵Θ的重注意技术来保持注意图的多样性。重注意技术采用交叉头沟通
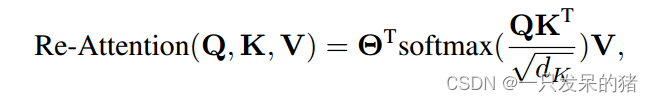 使用唯一的可学习变换矩阵Θ提高了注意图的多样性。因此,可以学习更丰富的特征和关系,并提高Deepfake的检测性能。
使用唯一的可学习变换矩阵Θ提高了注意图的多样性。因此,可以学习更丰富的特征和关系,并提高Deepfake的检测性能。
--------------------------------------------------------暂时写到这里
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【WPF.NET开发】如何创建自定义路由事件
- vscode运行python项目
- DiffMatch:扩散模型 + 图像配对 + 密集匹配,如何在一对图像之间建立像素级的对应关系?
- 软件测试|Python字典的访问方式你了解吗?
- Miniconda 3 | 出发,探索Python
- 手摸手系列之SpringBoot+Vue2项目整合高德地图实现车辆实时定位功能
- QT文件介绍
- LINUX基础培训六之磁盘和文件系统管理
- uniapp 微信小程序请求拦截器 接口封装
- 真的干不过,00后整顿职场已经给我卷麻了,想离职了...