深度学习课程实验三训练和测试卷积神经网络
一、 实验目的
1、学会搭建、训练和测试卷积神经网络,并掌握其应用。
2、掌握使用numpy实现卷积(CONV)和池化(POOL)层,包括正向春传播和反向传播。
二、 实验步骤
Convolutional Neural Networks: Step by Step
1、导入所需要的安装包
2、构建卷积神经网络
3、零填充、
4、卷积的单个步骤、
5、卷积神经网络的正向传播
6、池化层的正向传播
Convolutional Neural Networks: Application
1、TensorFlow模型
2、创建占位符
3、初始化参数
4、正向传播
5、计算损失
6、构建模型
Residual Networks
1、导入所需要的安装包
2、深层神经网络带来的问题
3、建立残差网络(前向传播残差块、反向传播残差块)
4、建立第一个ResNet模型
5、测试我们自己的图片(可选练习)
Autonomous driving - Car detection
1、导入所需要的安装包
2、问题描述
3、YOLO
⑴模型的详细信息
⑵对类别分数进行过滤
⑶非极大值抑制
⑷将两者组合以筛选边界框
4、输入图像测试YOLO预训练模型
⑴定义类,瞄点和图像维度
⑵加载预训练模型
⑶将模型的输出转换为可用的边界框张量
⑷筛选框
三、 实验代码分析
1、import numpy as np:将numpy库导入为np。numpy是一个用于进行数组和矩阵运算的常用库。
2、import h5py:导入h5py库。h5py是一个用于读写HDF5格式数据的库。HDF5是一种灵活、可扩展和高效的数据存储格式。
3、import matplotlib.pyplot as plt:导入matplotlib.pyplot库,并将其简称为plt。matplotlib.pyplot是一个用于绘制图形的库。它提供了一系列用于创建图形、设置图形属性和显示图形的函数。
4、X_pad = np.pad(X, ((0,0), (pad,pad), (pad,pad), (0,0)), “constant”):定义了一个函数zero_pad,用于在数据X的四个维度上应用零填充。
函数接受两个参数:X为输入的数据,pad为填充的大小。代码中通过调用 np.pad函数实现了零填充操作。np.pad函数可以在多维数组的各个维度上进行填充操作,第一个参数为输入数组,第二个参数为填充的形状。在这里,通过传入((0,0), (pad,pad), (pad,pad), (0,0))作为填充形状,实现了对X在第二、第三个维度上进行pad大小的零填充。最后,将填充后的结果存储在变量X_pad中,并返回该变量作为函数的输出。
5、s = np.multiply(a_slice_prev, W):a_slice_prev是输入的切片,W是卷积核参数,b是偏置参数。代码中,首先通过使用np.multiply函数实现了输入切片a_slice_prev与卷积核参数W的逐元素相乘
6、Z = np.sum(s):然后,通过使用np.sum函数计算了相乘结果的和,并将结果存储在变量Z中。
7、Z = Z + float(b):将偏置参数b转换为浮点型,并与变量Z相加,将结果存储回Z中。
8、(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape:获取上一层输出数据 A_prev的形状,其中m表示样本数,n_H_prev表示上一层输出的高度,n_W_prev表示上一层输出的宽度,n_C_prev表示上一层输出的通道数。
9、(f, f, n_C_prev, n_C) = W.shape:获取卷积核参数 W的形状,其中 f表示卷积核的大小,n_C_prev表示上一层输出的通道数,n_C表示卷积核的个数。
10、stride = hparameters[“stride”]:从超参数中获取卷积的步长(stride)
11、pad = hparameters[“pad”]:从超参数中获取卷积的填充大小。
12、n_H = (n_H_prev - f + 2 * pad) / stride + 1:计算卷积输出的高度
13、n_W = (n_W_prev - f + 2 * pad) /stride + 1:计算卷积输出的宽度
14、Z = np.zeros((m, n_H, n_W, n_C)):创建一个全零的数组作为卷积层的输出结果。
15、A_prev_pad = zero_pad(A_prev, pad):对输入数据A_prev进行零填充,得到填充后的矩阵A_prev_pad。
16、a_slice_prev = a_prev_pad[vert_start : vert_end, horiz_start : horiz_end, : ]:从填充后的数据中切取与卷积核大小一致的切片。
17、Z[i, h, w, c] = conv_single_step(a_slice_prev, W[:, :, :, c], b[:, :, :, c]):使用函数 conv_single_step计算卷积操作的输出值:,并将结果存储在输出结果 Z中
18、cache = (A_prev, W, b, hparameters):将输入数据、卷积核参数、偏置参数和超参数存储为缓存,用于反向传播。
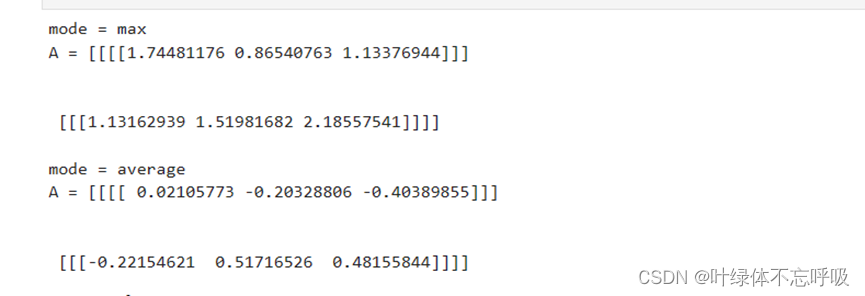
19、if mode == “max”: A[i, h, w, c] = np.max(a_prev_slice) :如果mode等于"max",那么会计算a_prev_slice中的最大值,并把结果赋值给A[i, h, w, c]。即将a_prev_slice中的元素取最大值后赋值给指定位置。
20、elif mode == “average”: A[i, h, w, c] = np.mean(a_prev_slice):如果mode等于"average",那么会计算a_prev_slice的平均值,并把结果赋值给A[i, h, w, c]。即将a_prev_slice中的元素取平均值后赋值给指定位置。
21、X = tf.placeholder(tf.float32, shape=[None, n_H0, n_W0, n_C0]):X是一个四维的浮点数张量,用来存储输入数据的特征。它的形状是[None, n_H0, n_W0, n_C0],其中None表示可以传入任意数量的样本,n_H0、n_W0和n_C0分别表示特征的高度、宽度和通道数。
22、Y = tf.placeholder(tf.float32, shape=[None, n_y]):Y是一个二维的浮点数张量,用来存储输入数据的标签或目标输出。它的形状是[None, n_y],其中None表示可以传入任意数量的样本,n_y表示目标输出的数量。
23、W1=tf.get_variable(“W1”,[4,4,3,8], initializer=tf.contrib.layers.xavier_initializer(seed=0)):使用TensorFlow的 get_variable()函数创建了一个名为"W1"的变量(即权重矩阵),它的形状为[4, 4, 3, 8]。其中,4代表滤波器的高度,4代表滤波器的宽度,3代表输入通道的数量,8代表输出通道(即滤波器数量)的数量。该变量的初始化器是 tf.contrib.layers.xavier_initializer(seed=0),它使用Xavier初始化方法进行权重矩阵的初始化,其中seed=0表示设置随机种子为0,以保证结果的可复现性。
24、W2=tf.get_variable(“W2”,[2,2,8,16], initializer=tf.contrib.layers.xavier_initializer(seed=0) :使用TensorFlow的 get_variable()函数创建了一个名为"W2"的变量(即权重矩阵),它的形状为[2, 2, 8, 16]。其中,2代表滤波器的高度,2代表滤波器的宽度,8代表输入通道的数量,16代表输出通道(即滤波器数量)的数量。该变量的初始化器是 tf.contrib.layers.xavier_initializer(seed=0),同样使用Xavier初始化方法并且设置了随机种子为0。
25、cost=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=Z3, labels=Y)):使用reduce_mean函数和nn.softmax_cross_entropy_with_logits()函数计算了神经网络模型的成本。Z3是最后一层经过全连接层计算得到的未激活的输出。Y是真实的标签值。tf.nn.softmax_cross_entropy_with_logits()函数首先对Z3进行softmax处理以获取模型的预测结果。然后,它计算了预测结果与真实标签值之间的交叉熵损失。该函数会自动将预测结果和真实标签进行归一化,以确保计算结果的数值稳定性。reduce_mean()函数将整个batch中的交叉熵损失取均值,得到一个标量值作为最终的成本。该值表示整个模型在给定的训练样本集上的平均损失。
26、X, Y = create_placeholders(64, 64, 3, 6):调用名为create_placeholders()的函数,创建了两个placeholder变量X和Y,用来存储训练样本和标签。
27、parameters = initialize_parameters():调用名为initialize_parameters()的函数,初始化神经网络的参数,并将结果存储在变量parameters中。
28、Z3 = forward_propagation(X, parameters):调用名为forward_propagation()的函数,进行神经网络的前向传播计算,得到最后一层的输出Z3。
29、cost = compute_cost(Z3, Y):调用名为compute_cost()的函数,计算成本函数,即神经网络预测结果与真实标签之间的损失。
30、optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost):创建了一个Adam优化器,并指定学习率为learning_rate。然后,使用优化器的 minimize()方法来最小化成本函数cost。
31、X = Conv2D(filters = F2, kernel_size = (f, f), strides = (1,1), padding = ‘same’, name = conv_name_base + ‘2b’, kernel_initializer = glorot_uniform(seed=0))(X)
32、X = BatchNormalization(axis=3, name = bn_name_base + ‘2b’)(X)
33、X = Activation(‘relu’)(X):这三行代码实现了残差块的第二个卷积层。它使用fxf大小的卷积核进行卷积,激活函数使用ReLU,同时进行批归一化操作。
34、X = Conv2D(filters = F3, kernel_size = (1, 1), strides = (1,1), padding = ‘valid’, name = conv_name_base + ‘2c’, kernel_initializer = glorot_uniform(seed=0))(X)
35、X = BatchNormalization(axis=3, name = bn_name_base + ‘2c’)(X):两行代码实现了残差块的第三个卷积层。它使用1x1的卷积核进行卷积,不设置偏移量,同时进行批归一化操作。
36、box_scores = box_confidence * box_class_probs:计算每个候选框的分数,即将盒子置信度box_confidence与盒子类别概率box_class_probs进行相乘。
37、box_classes = K.argmax(box_scores, axis=-1):找到每个候选框拥有最高分数的类别,即沿着最后一个维度(axis=-1)找到最大值的索引。
38、box_class_scores = K.max(box_scores, axis=-1, keepdims=False):计算每个候选框的最高分数,即沿着最后一个维度(axis=-1)找到最大值。
39、filtering_mask = box_class_scores > threshold:创建了一个布尔掩码,用来标记分数高于阈值的候选框。
40、scores = tf.boolean_mask(box_class_scores, filtering_mask):
41、boxes = tf.boolean_mask(boxes, filtering_mask):
42、classes = tf.boolean_mask(box_classes, filtering_mask):三行代码使用tf.boolean_mask函数根据布尔掩码来过滤出分数高于阈值的候选框的分数、位置和类别。
43、xi1 = max(box1[0], box2[0])
44、yi1 = max(box1[1], box2[1])
45、xi2 = min(box1[2], box2[2])
46、yi2 = min(box1[3], box2[3]):这四行代码计算两个矩形框的相交矩形框的左上角坐标(xi1, yi1)和右下角坐标(xi2, yi2)。使用max和min函数将两个矩形框的坐标投影到水平和垂直方向上。
47、inter_area = (xi2 - xi1) * (yi2 - yi1):计算相交矩形框的面积,通过相交矩形框的宽度(xi2 - xi1)和高度(yi2 - yi1)的乘积计算得到。
48、box1_area = (box1[2] - box1[0]) * (box1[3] - box1[1])
49、box2_area = (box2[2] - box2[0]) * (box2[3] - box2[1]):两行代码分别计算两个矩形框的面积,通过矩形框的宽度和高度的乘积计算得到。
50、union_area = box1_area + box2_area - inter_area:计算两个矩形框的并集面积,通过两个矩形框的面积之和减去相交矩形框的面积(inter_area)计算得到。
51、iou = inter_area / union_area:计算交并比,即相交矩形框的面积(inter_area)除以并集矩形框的面积(union_area)。
52、nms_indices=tf.image.non_max_suppression(boxes, scores, max_boxes, iou_threshold, name=None):使用tf.image.non_max_suppression函数进行非极大值抑制操作,根据所给的分数、位置、最大保留框数和交并比阈值,返回选择后的候选框的索引。
53、scores = K.gather(scores, nms_indices)
54、boxes = K.gather(boxes, nms_indices)
55、classes = K.gather(classes, nms_indices):这三行代码使用K.gather函数根据非极大值抑制的索引从scores、boxes和classes中选择对应的候选框的分数、位置和类别。
56、box_confidence, box_xy, box_wh, box_class_probs = yolo_outputs:从yolo_outputs中获取YOLO模型的输出,包括盒子置信度、盒子中心坐标、盒子宽高和盒子类别概率等。
57、boxes = yolo_boxes_to_corners(box_xy, box_wh):调用yolo_boxes_to_corners函数,将盒子的中心坐标和宽高转换为左上角和右下角坐标表示的形式。
58、scores,boxes,classes=yolo_filter_boxes(box_confidence, boxes, box_class_probs, score_threshold):调用yolo_filter_boxes函数,对候选框进行过滤操作,根据分数阈值将低得分的候选框过滤掉,只保留高分数的候选框,并得到经过过滤后的分数、位置和类别。
59、boxes = scale_boxes(boxes, image_shape):调用scale_boxes函数,将候选框的位置坐标缩放到与原始图像匹配的尺寸。
60、scores, boxes, classes=yolo_non_max_suppression(scores, boxes, classes, max_boxes, iou_threshold):调用yolo_non_max_suppression函数,进行非极大值抑制操作,根据交并比阈值和最大保留框数来选择最终的候选框,并返回分数、位置和类别。
四、 运行结果
Convolutional Neural Networks: Step by Step
1、zero-pad
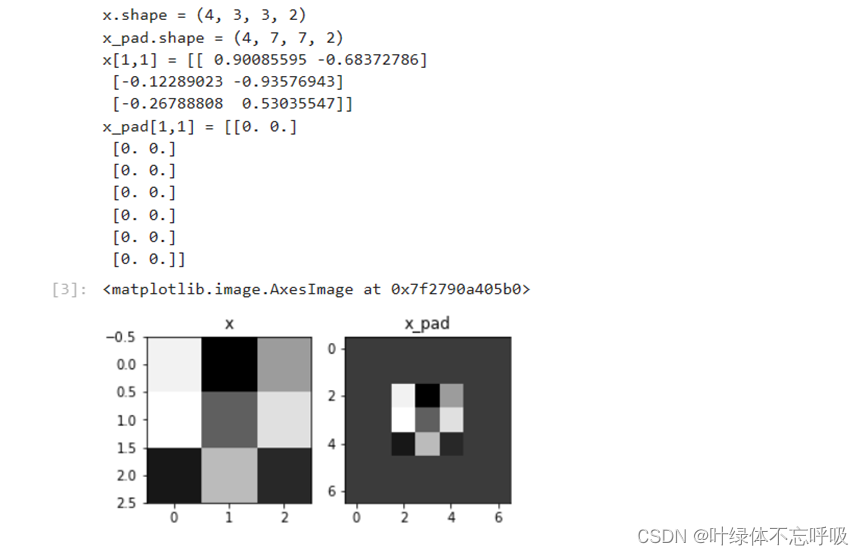
2、切片

3、卷积前向传播

4、池化前向传播
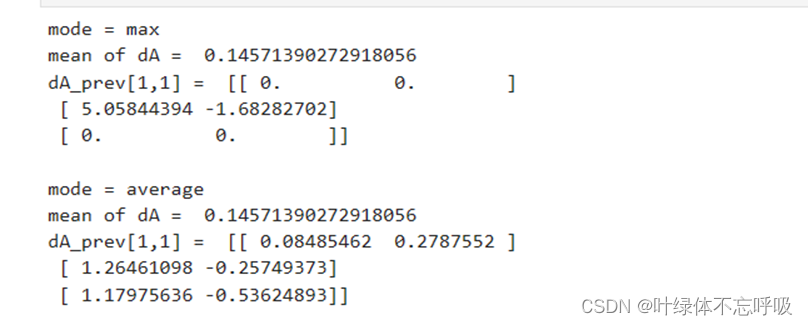
5、卷积反向传播

6、create_mask_from_window

7、 distribute_value

8、池化层反向传播
Convolutional Neural Networks: Application
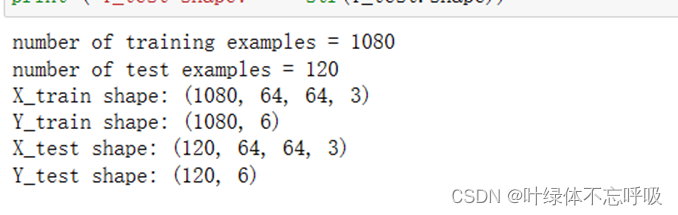
1、加载索引为2的数据集

2、检查数据的维度
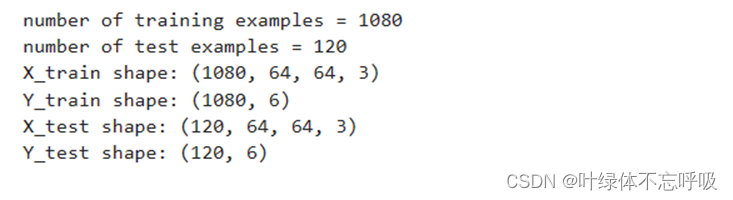
3、创建占位符

4、初始化参数

5、正向传播

6、计算损失

7、构建模型
Residual Networks
1、残差块输出

2、卷积块输出

3、加载数据集
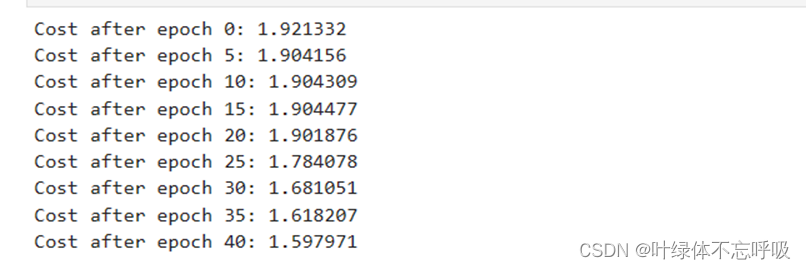
4、训练了两个epoch在测试集上的表现

Autonomous driving - Car detection
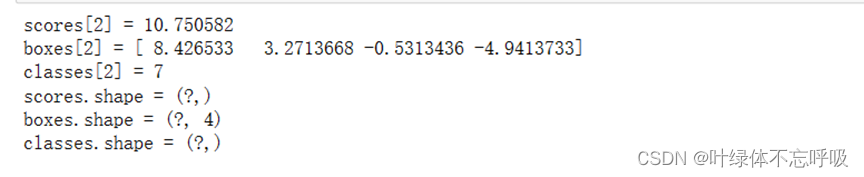
1、对类别分数进行过滤
2、非极大值的iou值

3、非极大值抑制后的结果
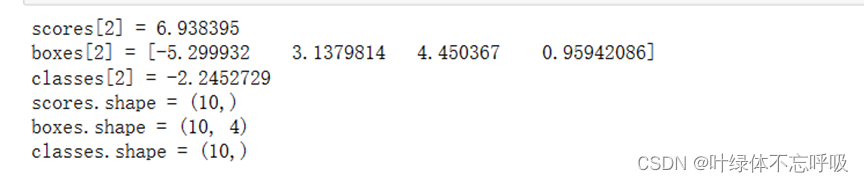
4、将两者结合以筛选边界框
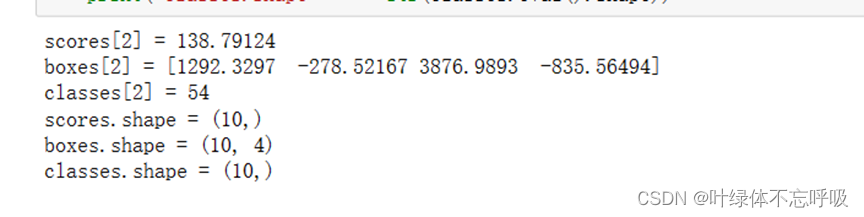
5、运行计算图结果
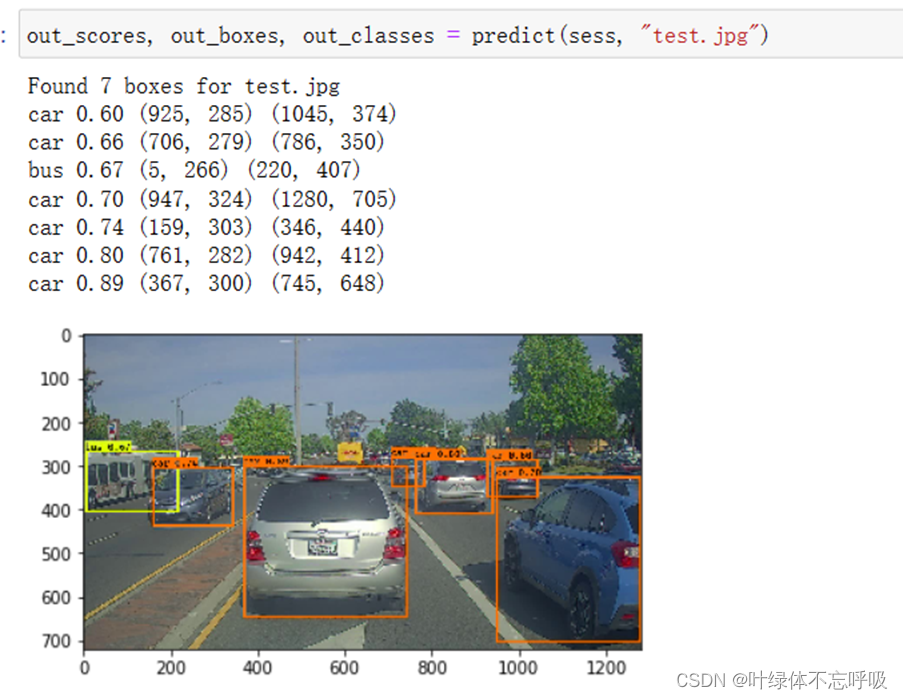
五、 实验结果分析、体会
在逐步实现卷积神经网络实验的过程中,我得出了以下实验结果分析与体会:
卷积神经网络的特征提取能力:卷积神经网络具有强大的特征提取能力,能够从图像中学习出高级的特征表示。在我的实验中,随着卷积层和池化层的叠加,模型逐渐学习到了更加抽象和复杂的特征。这使得模型在对图像进行分类和识别时表现出较好的准确率。
模型的深度与性能关系:在实验中,我尝试了不同的神经网络深度,即调整了卷积层和全连接层的数量和大小。通过对比实验结果,我发现较深的网络结构在处理复杂图像任务时往往能够达到更好的效果。但需要注意的是,过深的网络可能导致模型训练困难、计算资源需求增加等问题,因此需要进行权衡和平衡。在卷积神经网络的应用中,可以用TensorFlow实现功能全面的ConNet。
在残差网络的实验中,我了解到残差连接的作用:在实验中,我使用了残差连接来构建深度残差网络。通过比较带有和不带有残差连接的网络模型,在相同层数下进行训练和测试。实验结果显示,带有残差连接的网络模型相比于普通的深度模型,具有更好的性能。这是因为残差连接允许信息在网络中更有效地传递,减轻了梯度消失问题,从而使网络更容易训练和优化。
模型收敛速度的改善:在实验中,我观察到使用残差连接的深度模型相对于传统深度模型,在训练过程中显示出更快的收敛速度。这意味着残差网络能够更快地学习有效的特征表示,从而提高了整体的训练效率。这对于处理大规模数据集或训练复杂深度模型是非常有价值的。
模型复杂性与泛化能力的权衡:在实验过程中,我改变了残差连接网络的深度和宽度来评估模型的性能。通过实验对比,我发现增加网络的深度可以进一步提升性能,但也容易导致过拟合的问题。因此,在设计残差网络时,需要权衡模型的复杂性和泛化能力,避免深度过大导致的训练困难和计算资源消耗。
在自动驾驶-车辆识别的实验中,我了解到模型的准确率和鲁棒性:在实验中,我使用了深度学习模型对车辆进行识别。通过对大量的车辆图像进行训练和测试,模型在识别车辆方面表现出了较高的准确率。然而,我也发现在处理复杂场景、光照条件变化或车辆姿态变化等较为复杂的情况下,模型的性能受到了一定的影响。因此,提升模型的鲁棒性是未来研究的一个重要方向。
数据集的重要性:实验中,我使用了大规模的车辆图像数据集进行训练和评估。一个充分且多样化的数据集是保证模型性能的关键因素。通过使用多个数据源和增加数据增强操作,我能够获得更具代表性和广泛分布的车辆样本,进而改善模型的表现。模型的效率与实时性:在自动驾驶场景中,及时有效的车辆识别十分重要。在实验过程中,我优化了模型的结构和参数,以提高模型的计算效率和响应速度。通过模型压缩和硬件优化等技术手段,我能够获得更高的实时性和较低的计算资源消耗。真实场景的应用挑战:实验结果也揭示出在真实场景中的一些挑战。例如,复杂的背景干扰、部分遮挡、多尺度车辆等因素可能导致模型的识别表现下降。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- html/css实现简易圣诞贺卡
- 面试简历建议
- nodejs ‘cnpm‘ 不是内部或外部命令,也不是可运行的程序 或批处理文件。
- 代码随想录算法训练营第十一天|● 20. 有效的括号 ● 1047. 删除字符串中的所有相邻重复项 ● 150. 逆波兰表达式求值
- 【JavaEE】线程安全的集合类
- 【代码解析】代码解析之登录(2)
- 变量和函数提升(js的问题)
- pycharm社区版配置flask开发环境
- 蓝牙5.0智能停车引导系统解决方案
- 谷歌Linux内核自动测试平台架构介绍-用自动测试测试难以测试的问题