SparkSql---RDD DataFrame DataSet
文章目录
1.DataFrame
在Spark中,DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中的 二维表格 。DataFrame 与 RDD 的主要区别在于,RDD只关心数据,而DataFrame中也包含数据描述信息(数据的元数据)。如RDD中的一行数据为:16 小王,而这行数据在DataFrame中为age:16,name:小王。
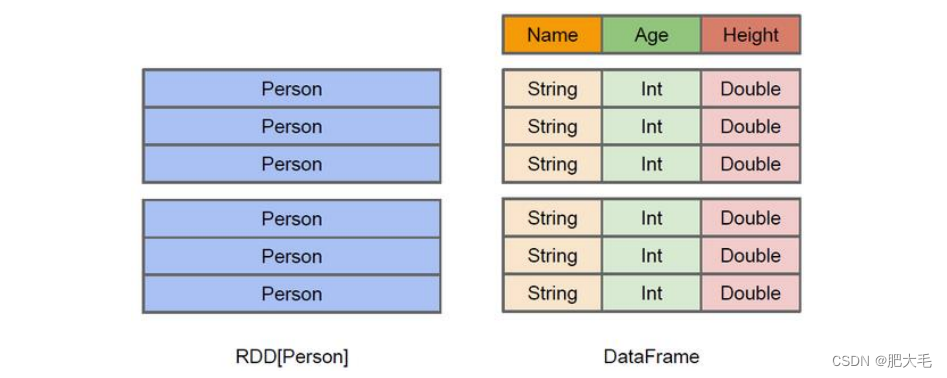
Spark SQL 的 DataFrame API 允许我们使用 DataFrame 而不用必须去注册临时表或者生成 SQL 表达式。 DataFrame API 既有 transformation 操作也有 action 操作。
2.DataSet
DataSet 是分布式数据集合。DataSet 是 Spark 1.6 中添加的一个新抽象,是 DataFrame的一个扩展。它提供了 RDD 的优势(强类型,使用强大的 lambda 函数的能力)以及 SparkSQL 优化执行引擎的优点。DataSet 也可以使用功能性的转换(操作 map,flatMap,filter等等)。
DataSet与DataFrame的区别在于,DataSet在DataFrame的基础上,进一步的指明了每个数据的数据类型。
DataFrame 其实就是 DataSet 的一个特例 ,因为DataFrame中每行的类型都是Row
type DataFrame = Dataset[Row]
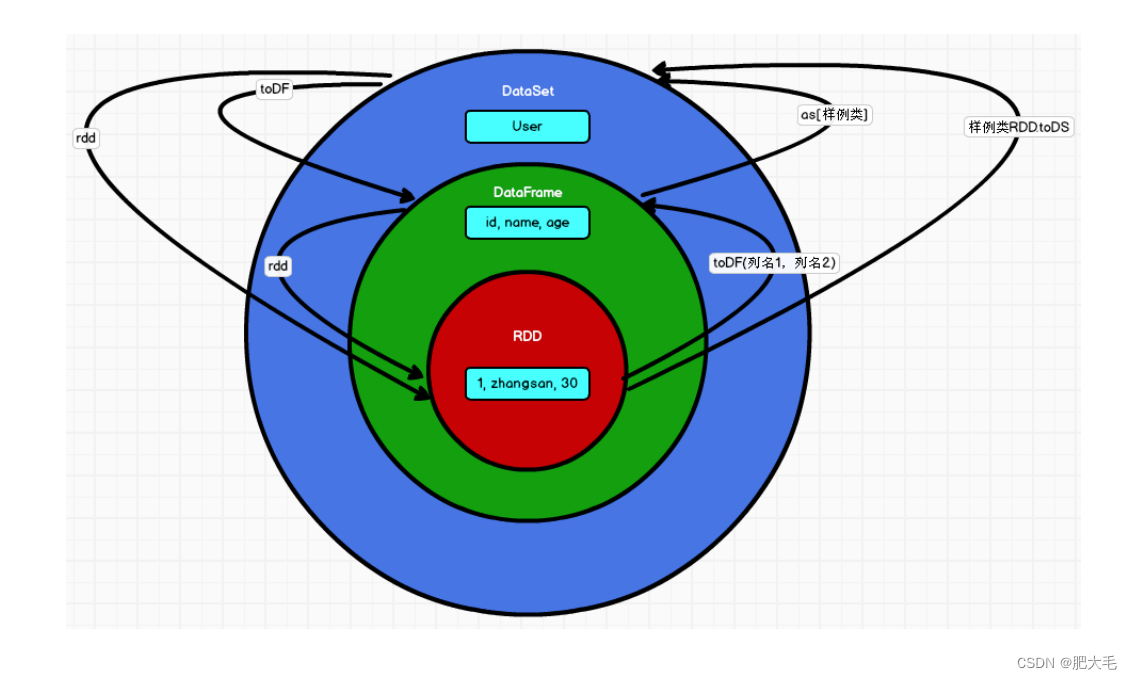
3.RDD、DataFrame、DataSet 三者的关系
1.RDD、DataFrame、DataSet 全都是 spark 平台下的分布式弹性数据集
2.三者都有惰性机制,在进行创建、转换,如 map 方法时,不会立即执行,只有在遇到Action 如 foreach 时,三者才会开始遍历运算
3.三者有许多共同的函数,如 filter,排序等
4.在对 DataFrame 和 Dataset 进行操作许多操作都需要这个包:import spark.implicits._
5.三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
6.三者都有 partition 的概念
7.DataFrame 和 DataSet 均可使用模式匹配获取各个字段的值和类型
RDD、DataFrame、DataSet之间可以相互转化
4. 使用SQL操作DataFrame类型的数据
定义一个名为user的json文件,文件中的数据如下。

创建DataFrame的数据
object SparkSQLDemo01 {
def main(args: Array[String]): Unit = {
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLDemo01")
//创建 SparkSession 对象
val sc: SparkSession = SparkSession.builder().config(conf).getOrCreate()
//RDD,DataFrame,DataSet三者在进行转换的时候需要引入隐式转换规则,否则无法转换
import sc.implicits._
val df = sc.read.json("D:\\learnSoftWare\\IdeaProject\\Spark_Demo\\Spark_Core\\src\\main\\com.mao\\datas\\user.json")
df.show()
sc.stop()
}
}

对 DataFrame 创建一个临时视图
使用SQL来对DataFrame数据进行操作的时候,需要有一个临时视图和全局视图来辅助。
//创建临时视图
df.createOrReplaceTempView("user")
val allSelect = sc.sql("select * from user")
allSelect.show()
对 DataFrame 创建一个全局视图
df.createGlobalTempView("user")
4.1 DSL语法
DataFrame 提供一个特定领域语言(domain-specific language, DSL)去管理结构化的数据。可以在 Scala, Java, Python 和 R 中使用 DSL,使用 DSL 语法风格不必去创建临时视图了
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLDemo02")
//创建 SparkSession 对象
val sc: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import sc.implicits._
//RDD,DataFrame,DataSet三者在进行转换的时候需要引入隐式转换规则,否则无法转换
val df = sc.read.json("D:\\learnSoftWare\\IdeaProject\\Spark_Demo\\Spark_Core\\src\\main\\com.mao\\datas\\user.json")
df.show()
//DSL语法
df.printSchema()
//只查看username列
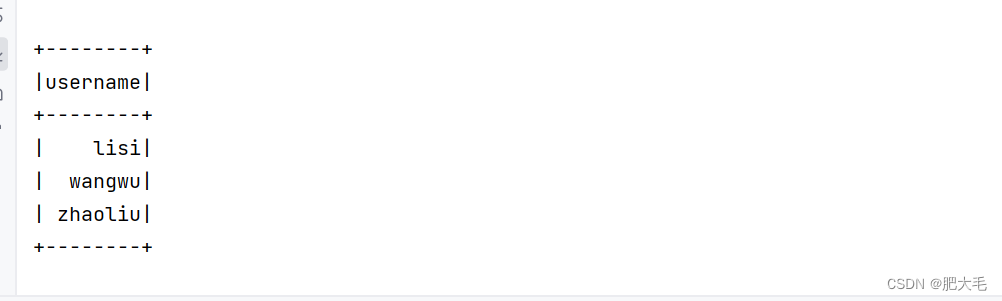
df.select("username").show()
sc.stop()
在DSL语法中,可以使用$和‘来对字段中的值进行操作
//对所有user的年龄执行+1操作
df.select($"username",$"age" + 1).show
df.select('username, 'age + 1).show()
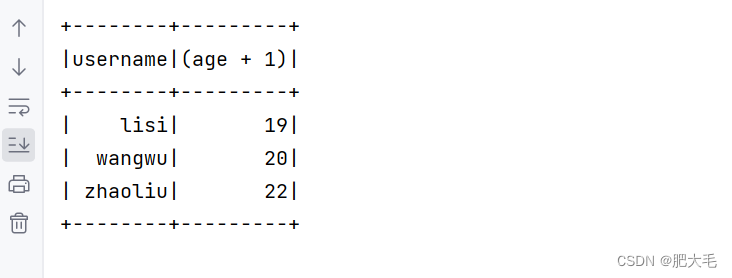
//查看"age"大于"30"的数据
df.filter('age>20).show()

//按照age进行分组,查看数据条数
df.groupBy('age).count().show()

4.2 RDD转换为DataFrame
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLDemo03")
//创建 SparkSession 对象
val sc: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import sc.implicits._
//RDD,DataFrame,DataSet三者在进行转换的时候需要引入隐式转换规则,否则无法转换
val rdd1=sc.sparkContext.makeRDD(List(1,2,3,4))
val rdd2: RDD[(Int, String, Int)] = sc.sparkContext.makeRDD(List((1, "zhangsan", 30), (2, "lisi", 28), (3, "wangwu", 20)))
//将RDD转换为DataFrame
val df1 = rdd1.toDF()
val df2 = rdd2.toDF()
df1.show()
df2.show()
sc.stop()


4.3 DataFrame转换为RDD
DataFrame 其实就是对 RDD 的封装,所以可以直接获取内部的 RDD
//DataFrame转RDD
val newrdd1: RDD[Row] = df1.rdd
val newrdd2: RDD[Row] = df2.rdd
newrdd1.collect().foreach(println)
newrdd2.collect().foreach(println)

5.使用SQL操作DataSet的数据
5.1 使用样例类序列创建 DataSet
SparkSQL 能够自动将包含有 case 类的 RDD 转换成 DataSet,case 类定义了 table 的结构,case 类属性通过反射变成了表的列名。Case 类可以包含诸如 Seq 或者 Array 等复杂的结构。
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLDemo03")
//创建 SparkSession 对象
val sc: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import sc.implicits._
val caseUserRDD: RDD[User] = sc.sparkContext.makeRDD(List(User("zhangsan", 19), User("lisi", 21)))
val DSUser = caseUserRDD.toDS()
DSUser.show()
sc.stop()

5.2 DataSet转换为RDD
DataSet 其实也是对 RDD 的封装,所以可以直接获取内部的 RDD
val dsRdd: RDD[User] = DSUser.rdd
dsRdd.collect().foreach(println)

5.3 DataSet和DataFrame相互转换
DataFrame 其实是 DataSet 的特例,所以它们之间是可以互相转换的。
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLDemo03")
//创建 SparkSession 对象
val sc: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import sc.implicits._
val userRDD: RDD[(String, Int)] = sc.sparkContext.makeRDD(List(("zhangsan", 20), ("lisi", 21), ("wangwu", 22)))
//将RDD转换为DataFrame
val userDF = userRDD.toDF("name,age")
//将DataFrame转换为DataSet,使用as[样例类]
val userDS: Dataset[User] = userDF.as[User]
userDS.show()
//将DataSet转换为DataFrame
val newUserDF: DataFrame = userDS.toDF()
newUserDF.show()
sc.stop()

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- RabbitMQ的基本使用&入门
- 华为机试真题实战应用【赛题代码篇】-文件目录大小(附Java、C++和python代码)
- IM即时通讯聊天社交APP源码+h5群聊+红包转账+朋友圈
- 127基于matlab的卡尔曼滤波在目标跟踪中应用仿真研究
- 【Python爬虫】Python爬虫入门教程&注意事项
- 【大数据面试】YARN常见问题与答案
- 码农维权——案例分析之违法解除劳动合同(三)审查解除的具体依据
- 解决App Store上架提示您必须上传 12.9 英寸 iPad Pro(第 2 代)显示屏的截屏
- 项目整合管理-8.1制定项目章程
- MobaXterm无法上传文件处理