STL第一讲
发布时间:2024年01月23日
一、认识headers、版本、重要资源
1. C++ Standard Library和Standard Template Library
前者:c++标准库;后者直译为“标准模板库”
区别:
- C++标准库:是c++编译器提供的自带的头文件(不带
.h后缀)- 新版兼容C的头文件的形式
cxxxx;旧版的xxxx.h也可用但不建议- 新版c++标准库的头文件都存在于命名空间
std- STL:《源码剖析》所说的六大部件
查看自己的g++编译器:
wkm@ai303-virtual-machine:~/code/shell$ gcc -v -x c++ -E -
....
#include "..." search starts here:
#include <...> search starts here:
/usr/include/c++/9
/usr/include/x86_64-linux-gnu/c++/9
/usr/include/c++/9/backward
/usr/lib/gcc/x86_64-linux-gnu/9/include
/usr/local/include
/usr/include/x86_64-linux-gnu
/usr/include
End of search list.
....
2. 一些重要网站
- cplusplus
- cppreference
- gcc.gnu.org
二、STL介绍
六大部件:
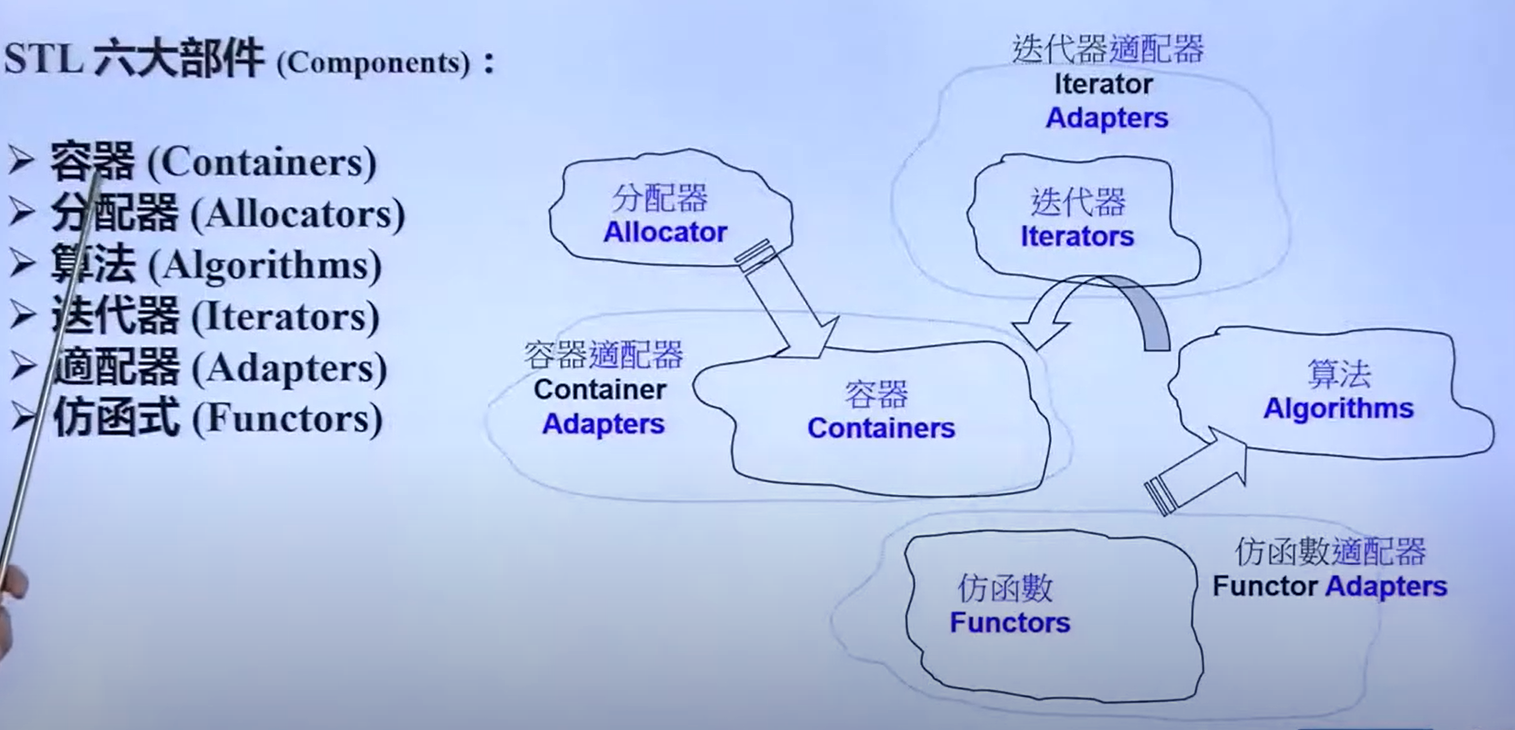
前闭后开区间:
每个容器表示范围的成员:
- begin:指向首元素
- end:指向末尾元素的下一位
三、容器
容器分类与各种测试(一)
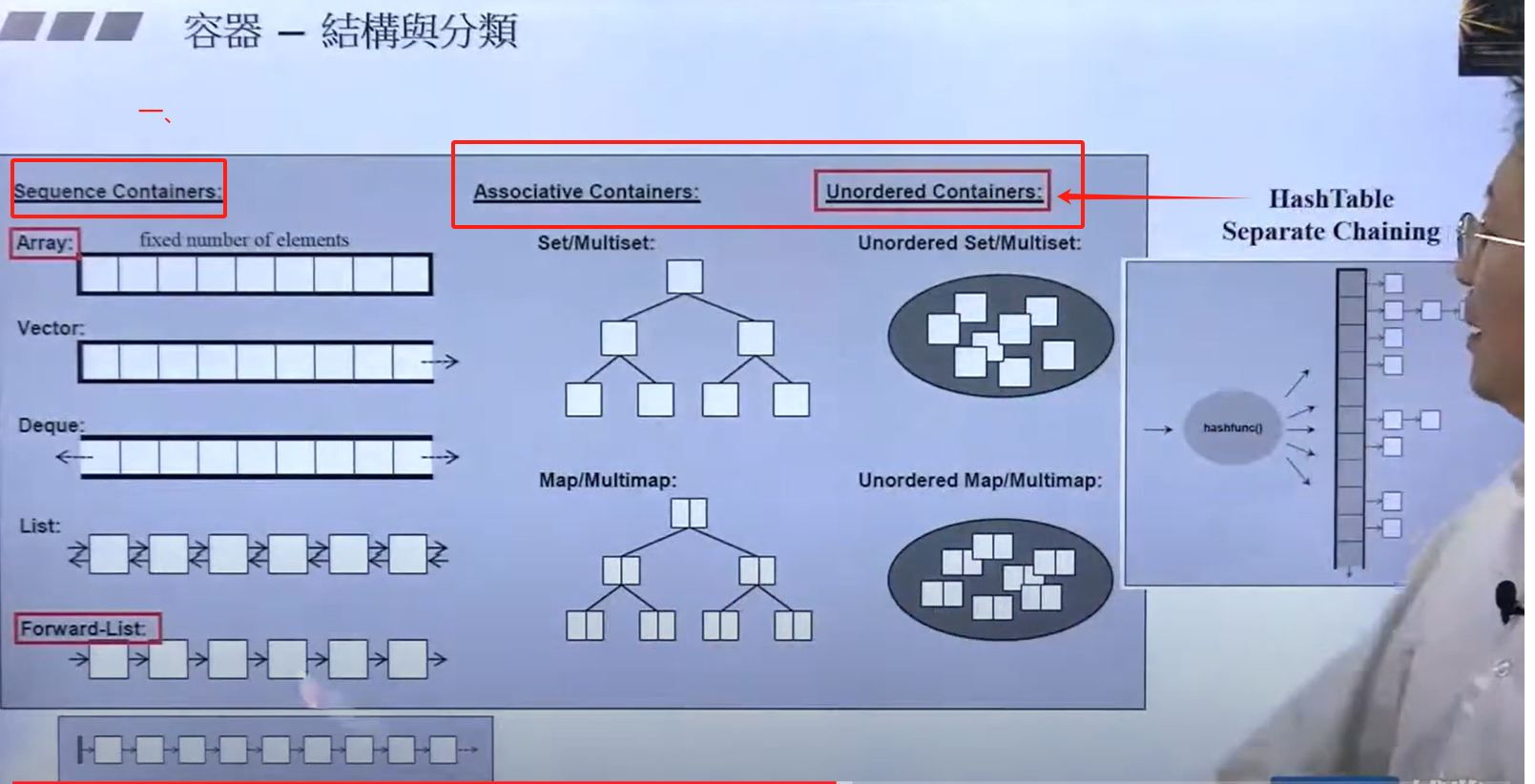
图解:
- 无须容器属于关联容器,所以推荐将container依然分为两大类:顺序容器、关联容器
- 顺序容器中的箭头:表示可扩充的地方;如vector只能在尾部扩充;
- 关联容器底层实现:红黑树;无序容器:hashtable
- 原图中的红标是c++11标准引入的
容器分类与各种测试(二)
测试代码风格:namespace、变量定义定格
在数据量很大的时候,先sort后查找,sort步骤就很耗时。
容器分类与各种测试(三)
stl全局有sort(用法是::sort,即添加作用域运算符),容器也可能有自己的sort。建议使用某种容器时,调用自身的sort。
gnu中有非c++标准库的容器:slist,头文件:ext\slist,其他的成员使用方法与forward_list相同
- deque:
- “分段连续”,由一段段的buffer组成,每个buffer能存储若干个元素;
- push_front和push_back用完一个buffer后,会再向前/后扩充一个buffer(一个buffer具体大小取决于stl具体实现)
- deque没有自己的sort;
stack和queue是容器适配器;不提供iterator,否则会破坏其“先进后出”/“先进先出”的基本原则。
容器分类与各种测试(四)
对于无序容器:当元素个数大于bucket_count(),会扩充bucket;
旧代码中关于hash_set/hash_map/hash_multiset/hash_multimap,需要找到对应的头文件位置
分配器
每个容器的都有默认分配器:std::allocator
建议:尽量使用容器,因为自己直接使用分配器,手动分配和释放内存会加大工作量。
文章来源:https://blog.csdn.net/weixin_43869409/article/details/135793509
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 第二十三章 反射(reflection)
- 基于SSM的停车管理系统设计与实现
- sql优化,内外连接有什么区别
- 代码随想录算法训练营29期Day13|LeetCode 239,347
- 【实战】如何在Docker Image中轻松运行MySQL
- DRF从入门到精通九(权限控制)
- android:clickable=“false“无效,依然能被点击
- FreeRTOS——消息队列
- 明明随机数
- Java毕业设计-基于微信小程序的志愿者活动管理系统-第83期