【Python】【深度学习】使用argparse模块和JSON管理深度学习模型的超参数
在深度学习中,超参数(如batch_size、learning_rate等)是重要的因素。我们通过调整超参数,可以得到不同的实验结果。因此,我们通常需要尝试大量不同的超参数设置,来获得较好的数据。这就带来了一个问题:我们的超参数散布在网络的各个角落,每次修改它们时,要从上到下翻阅大量代码块,甚至还有可能遗漏一些超参数。此外,如果我们想自动训练不同的超参数组合,这也是很难做到的。
好在,这里有一个解决办法:使用argparse模块和json进行超参数的管理。
一、argparse模块
1.1 argparse是什么?
argparse 模块是 Python 中用于解析命令行参数的标准库工具。它允许你定义你的脚本应该接受哪些命令行参数,以及这些参数的类型和默认值。通过使用 argparse,你可以轻松地从命令行获取用户输入,并在脚本中使用这些输入。
argparse 帮助你创建一个用户友好的命令行界面,使得你的脚本能够更加灵活地与用户交互。例如,你可以定义脚本接受的选项,设置默认值,提供帮助信息,等等。
但其实这些不是很重要,可以继续看下面的例子!
1.2 用agrparse管理超参数,并用命令行启动py项目
1.2.1超参数的设置
假设我们有几个超参数:
| 参数 | 类型 | 默认值 |
|---|---|---|
| batch_size | int | 64 |
| epoch | int | 200 |
| learning_rate | float | 0.001 |
看下面的代码片:
文件名称:parser.py
import argparse
# 创建 ArgumentParser 实例
parser = argparse.ArgumentParser(description="用来介绍parser!!")
# 添加命令行参数
#help用于在命令行中打印“--batch_size”的用法,可以提醒自己和其他使用此程序的人
parser.add_argument('--batch_size', type=int, default=64, help="定义batch")
parser.add_argument('--epoch', type=int, default=200, help="定义训练轮数")
parser.add_argument('--learning_rate', type=float, default=0.001, help="定义学习率")
# 解析命令行参数
args = parser.parse_args()
# 访问命令行参数的值
model_batch_size = args.batch_size
model_epoch = args.epoch
model_learning_rate = args.learning_rate
# 输出batch_size参数的值
print(model_batch_size)
print(model_epoch)
print(model_learning_rate)
运行结果:
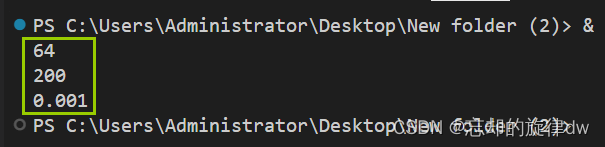
在上述案例中,我们给parser添加了batch_size超参数,最后通过parser.parse_args()把超参数解析到args实例,这样,我们就能通过args访问到所有超参数(比如batch_size)的值。
1.2.2自动调整超参数
我们还可以通过命令行运行这个py文件,选择性给超参数赋值,如果没有赋值,则使用默认值。以上面的代码片为例(名称是“parser.py”)
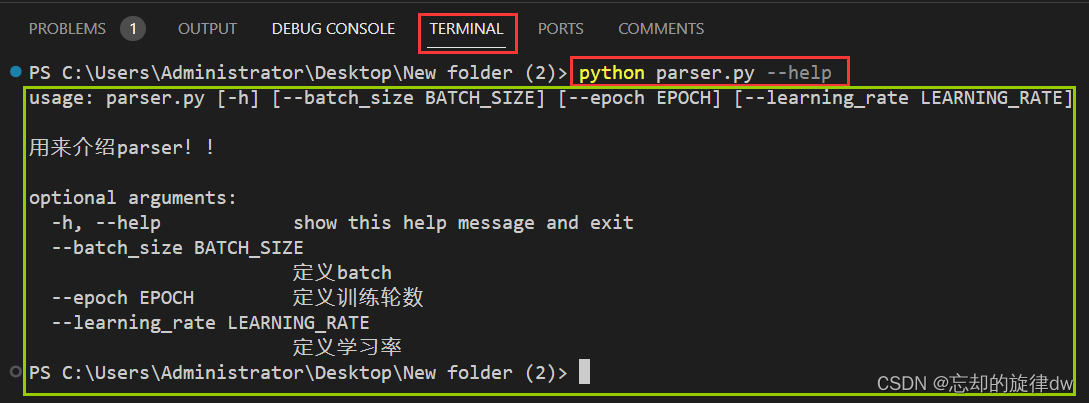
(1)在命令行打印help用法:
python parser.py --help
可以看到结果如下:
(2)使用携带超参数的命令行
在batch_size、epoch和learning_rate三个超参数中,我们手动设置batch_size为128,epoch为100。learning_rate则使用默认的0.001。在命令行中运行如下命令:
python parser.py --batch_size 128 --epoch 100
运行结果:

这说明程序的batch_size和epoch使用了我们手动设置的值,而learning_rate默认。
二、使用JSON管理超参数
2.1 JSON是什么?
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它以易于阅读和编写的文本形式表示数据,同时具有良好的数据结构支持。JSON现在被广泛用于各种编程语言和应用程序之间的数据交换。
JSON数据采用键值对的形式,类似于Python中的字典。一个JSON对象由花括号 {} 包裹,键值对之间用逗号 , 分隔。每个键值对的键是一个字符串,值可以是字符串、数字、布尔值、数组、对象、null等基本数据类型。
例如,下面是一个简单的JSON对象:
{
"batch_size": 64,
"epoch": 200,
"learning_rate": 0.001
}
2.2读取JSON中的超参数
在上面的例子中,我们定义了三个超参数,我们该如何读取它?看下面的例子:
首先是项目结构:

其中arg.json存放超参数,内容如下:
{
"batch_size": 32,
"epoch": 200,
"learning_rate": 0.001
}
utils.py读取json:
import argparse
import os
import json
class Params():
def __init__(self,json_path):
with open(json_path) as f:
params = json.load(f)
self.__dict__.update(params)
#testParam接收arg.json中的超参数
testParam = Params("arg.json")
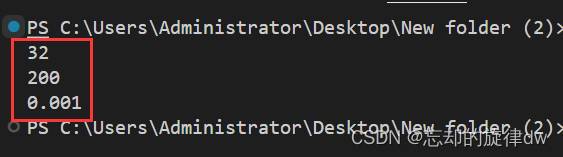
print(testParam.batch_size)
print(testParam.epoch)
print(testParam.learning_rate)
这里主要注意self.__dict__.update(params)用法,这行代码的作用是将 params 字典中的键值对更新到实例的属性中。这样,实例的属性就会直接映射到 JSON 文件中的键值对。在这个过程中,实例的属性名将与 JSON 文件中的键相匹配,而属性的值将是相应键的值。
执行代码,输出结果如下:
2.3argparse配合json自定义超参数所在路径
其实思路就是利用argparse模块,给parse增加一个dir参数,这个参数用来存放超参数json文件夹所在路径。这样,我们训练模型时,只需要给好超参数文件所在位置即可,而具体的超参数可以直接在json文件中修改即可。
下面是最终结果:
(1)项目结构:
par.py
utils.py
hyper→ arg.json

(2)par.py
import argparse
import os
import utils
# 创建 ArgumentParser 实例
parser = argparse.ArgumentParser(description="用来介绍parser!!")
# 添加命令行参数
parser.add_argument('--dir', default="hyper/", help="超参数文件arg.json所在文件夹路径")
# 解析命令行参数
args = parser.parse_args()
# 访问命令行参数的值
model_arg_path = args.dir
#找到超参数json文件的所在位置(model_arg_path/arg.json)
json_path = os.path.join(model_arg_path, 'arg.json')
#映射超参数值到testParam上
testParam = utils.Params(json_path)
# 输出超参数的值
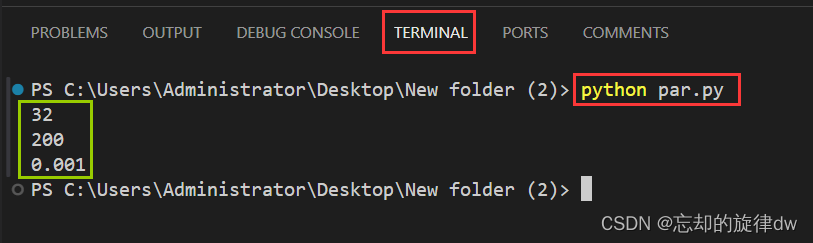
print(testParam.batch_size)
print(testParam.epoch)
print(testParam.learning_rate)
(3)utils.py
import argparse
import os
import json
class Params():
def __init__(self,json_path):
with open(json_path) as f:
params = json.load(f)
self.__dict__.update(params)
使用命令行运行par.py,结果如下:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 快速构造商业思维:明确商业目标的关键
- 2024年深圳市专精特新企业申报条件-专精特新企业认定、申请时间、流程及奖励补贴
- VR云看房:打造房源全方位闭环,助力房企数字化转型
- python列表删除元素的三种方法(含例子)
- 学习笔记-李沐动手学深度学习(一)(01-07)
- 华为OD机试真题-最长的指定瑕疵度的元音子串-2023年OD统一考试(C卷)
- facebook广告的内容应该怎么写
- PAT 乙级 1043 输出PATest
- Deep Learning for Precipitation Nowcasting:A Benchmark and A New Model
- flex布局(3)