python时间序列分析
发布时间:2024年01月24日
环境配置
python推荐直接装Anaconda,它集成了许多科学计算包,有一些包自己手动去装还是挺费劲的。statsmodels需要自己去安装,这里我推荐使用0.6的稳定版,0.7及其以上的版本能在github上找到,该版本在安装时会用C编译好,所以修改底层的一些代码将不会起作用。
时间序列分析
1.基本模型
自回归移动平均模型(ARMA(p,q))是时间序列中最为重要的模型之一,它主要由两部分组成: AR代表p阶自回归过程,MA代表q阶移动平均过程,其公式如下:
 在时间序列中,ARIMA模型是在ARMA模型的基础上多了差分的操作。
在时间序列中,ARIMA模型是在ARMA模型的基础上多了差分的操作。
2.pandas时间序列操作
大熊猫真的很可爱,这里简单介绍一下它在时间序列上的可爱之处。和许多时间序列分析一样,本文同样使用航空乘客数据(AirPassengers.csv)作为样例。
数据读取:
# -*- coding:utf-8 -*-
import numpy as np
import pandas as pdfrom datetime import datetimeimport matplotlib.pylab as plt
# 读取数据,pd.read_csv默认生成DataFrame对象,需将其转换成Series对象df = pd.read_csv('AirPassengers.csv', encoding='utf-8', index_col='date')df.index = pd.to_datetime(df.index) # 将字符串索引转换成时间索引ts = df['x'] # 生成pd.Series对象# 查看数据格式ts.head()ts.head().index
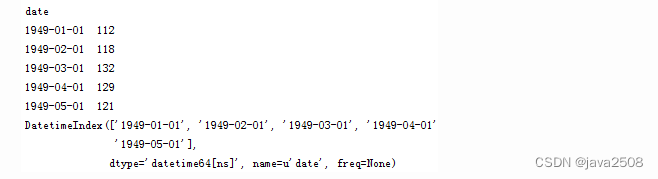
查看某日的值既可以使用字符串作为索引,又可以直接使用时间对象作为索引
ts['1949-01-01']
ts[datetime(1949,1,1)]
两者的返回值都是第一个序列值:112
如果要查看某一年的数据,pandas也能非常方便的实现
ts['1949']
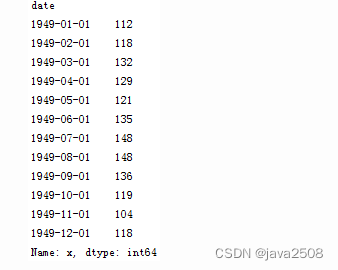
切片操作:
ts['1949-1' : '1949-6']

注意时间索引的切片操作起点和尾部都是包含的,这点与数值索引有所不同
pandas还有很多方便的时间序列函数,在后面的实际应用中在进行说明。
文章来源:https://blog.csdn.net/java2508/article/details/135817643
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 数据割据:当代社会数据治理的挑战
- Feature Prediction Diffusion Model for Video Anomaly Detection 论文阅读
- chatGPT的Function calling示例
- SpringBoot的热部署
- PDF转换工具箱小助手流量主小程序开发
- 手机上的python怎么运行,python在手机上怎么运行
- 为什么v-if和v-for不建议放一起?v-if和v-for的优先级是什么?
- vmware虚拟机内存异常占用问题一例
- 精选暖心的早安问候语图片,送一份温馨问候、送一串真诚祝福!
- Swift 周报 第四十期