结构体类型
变量名的要求(额外要说的点)
?
变量名只能是字母,数字,下划线这三种类型组成,且不能由数字开头。???????
内存中数据的存放(额外要说的点)
?
对于大小端存储模式只适用于单个数据(超过单个字节的数据)里的各个字节的排列顺序,其会使该数据的各个字节都安排在对应的地址上 (如在vs中最高位字节安排在最高地址处,最低位字节安排在最低地址处,vs为小端存储模式),它不影响多个数据中的排列。之前就很细致的讲过了在这篇文章中写文章-CSDN创作中心
现在再补充一点,其大小端不影响单个字节内部的比特位排序,其单个字节内部比特位排序是固定的,如1为00000000 00000000 00000000? 00000001,则放到栈中因为为小端存储的关系低字节放到低地址处,而其并不改变单个字节内部的比特位排序,所以一个字节内部的比特位并没改变,则存放之后为 00000001? 00000000 00000000? 00000000? 地址由低到高,所以十六进制表现为01 00? 00? 00 ,跟vs调试中的一样。
所以得出结论,数据在内存存放时:无论如何对于一个字节内部的两个十六进制数字第一个都是高进制位比特,第二个才是低进制位比特(如01中0为高进制比特位,1为低进制比特位),不要搞反了。我们上面那段说的就是产生这种现象的原因。
了解了以后方便以后我们在调试看内存条时能看懂为什么这么放置。?并且我们在看一个变量在内存条的存放放置时:我们能直接依据其内存存放放置将变量转化为十进制数字。(像别人不清楚怎么存放的话,他们就算不出来这个变量到底为多少,极有可能算错)
结构体的基本使用
结构体的声明及基本使用?
?在之前我们就已经学习过结构体了。在操作符的详解中讲过。
https://blog.csdn.net/Easonmax/article/details/134298830?spm=1001.2014.3001.5501
现在简单的看一下就行?
?
结构体里面可以包含很多数据类型,如数组,结构体(除自己本身结构体),结构体指针等。?
在声明完后,可以直接在后面创建变量,可以是普普通通的一个结构体变量,也可以是一个结构体指针变量,还可以是一个结构体数组。
还可以在声明完后就直接将其声明完后的结构体用typedef替换为其他名字,如

对于其相关的两个操作符,一个如果前面是结构体名字就用?. (直接访问操作符)
一个如果前面是结构体地址(指针)就用->(间接访问操作符)?
它们两后面为内部数据名就都能访问到其对应的结构体里面的数据。
之前我已经在操作符详解那篇文章中讲到这两个的具体操作,这里不详细阐述。
?结构体的特殊声明(特殊使用)

对于结构体可以匿名,但是我们只能使用匿名的它创建变量一次,意味着用该匿名结构体类型创建变量时只能在声明的同时在后面创建变量,除此之外它不能再创建变量。


虽然对于匿名之后的结构体创建变量我们只能声明的同时创建,但是我们对结构体匿名的次数并不是有限的,能一直匿名。(匿名结构体的次数不会对系统有什么影响,而是匿名结构体创建变量的地方对系统会有影响)
?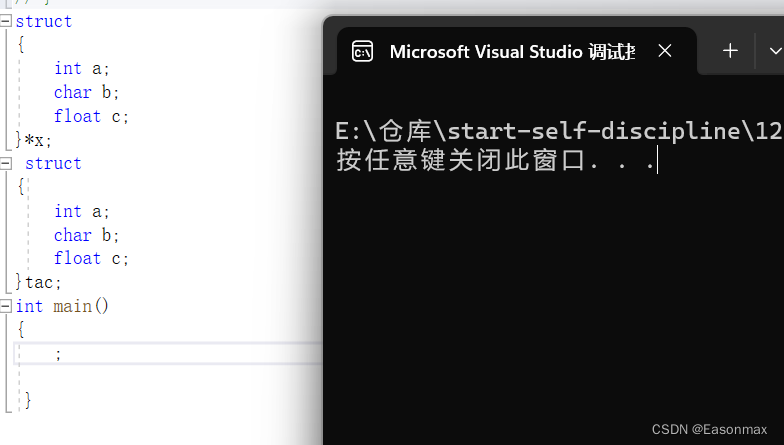
这里还要说一点,对于普通结构体,如果我们这里声明了了两个完全相同的结构体,编译器会认为这是两个类型完全不同的类型,所以导致出现下面这种状况。?

这里可以执行?
 ?
?
?这里因为是两个完全不同的类型,所以不能存入。
对于两个完全相同的匿名的struct,同样它们的类型完全不同。?

所以只要是有两个完全相同的结构体,我们就知道它们的类型是完全不同的 ,从而就能避免很多操作所带来的问题。
对于匿名struct的这个创建变量只能声明时创建变量的这个局限,我们就可以用typedef这个关键词解决这个问题。我们将匿名的struct命名为其他名字,此时用其他名字去创建变量,就可以被编译器所允许。
?
该图中用typedef作用于匿名struct后,其就能在其他地方创建变量了。?
对于struct的特殊声明我们只需要了解知道有这个东西就行,到时候别人代码出现了我们能看懂就行,对于我们自己写时几乎用不到这个特殊声明(不排除有些人拿来炫技用到这个)?
结构体的自引用 (特殊使用)

?对于结构体的自引用,不能出现结构体里面包含自己结构体,否则会因为无限循环,从而无限大。
真正的自引用应该是
struct Node{
int data;
struct Node* next;
};
这个自引用并没有循环,没有无限大,这个才为真正的自引用。里面包含着指向自己的指针。
typedef struct
{
int data;
Node* next;
}Node;因为替换的名字node是在struct声明完后才有的,而struct里面有node,而在struct还没声明好前node是不为结构体,所以struct由于存在一个不知道为什么类型的node从而声明错误,自然也就替换不了,编译错误。
?正常做法就是不要对匿名结构体重命名,而是对普通结构体重命名。如下
typedef struct Node
{
int data;
struct Node* next;
}Node;?结构体内存对齐
对齐规则
?
?offsetof函数
对于该函数适用于求结构体内部各个数据中相对于结构体起始位置的偏移量。?
返回值为size_t类型,返回其对应的偏移量,其offsetof(结构体类型名,结构体内部成员名)这是其所需内部参数
下面有段代码就是对上述的应用?(对于讲的上述知识点都用到了)
#define _CRT_SECURE_NO_WARNINGS
#include<stddef.h>
#include<stdio.h>
struct sat
{
int a;
int b;
char c;
};
int main() {
printf("%d ", sizeof(struct sat));
printf("%d ", offsetof(struct sat, a));
}?
为什么存在内存对齐
?
?修改默认对齐数
?#pragma 这个预处理指令,可以改变编译器的默认对?数。
#define _CRT_SECURE_NO_WARNINGS
#pragma pack(1)//将默认对齐数修改为1
#include<stddef.h>
#include<stdio.h>
struct sat
{
int a;
int b;
char c;
};
#pragma pack()//将默认对齐数还原为初始
struct st
{
int a;
int b;
char c;
};
int main() {
printf("%d ", sizeof(struct sat));
printf("%d ", sizeof(struct st));
}?这里用了#pragma pack(1)将默认对齐数修改为1
而#pragma pack()是将默认对齐数还原为初始状态
?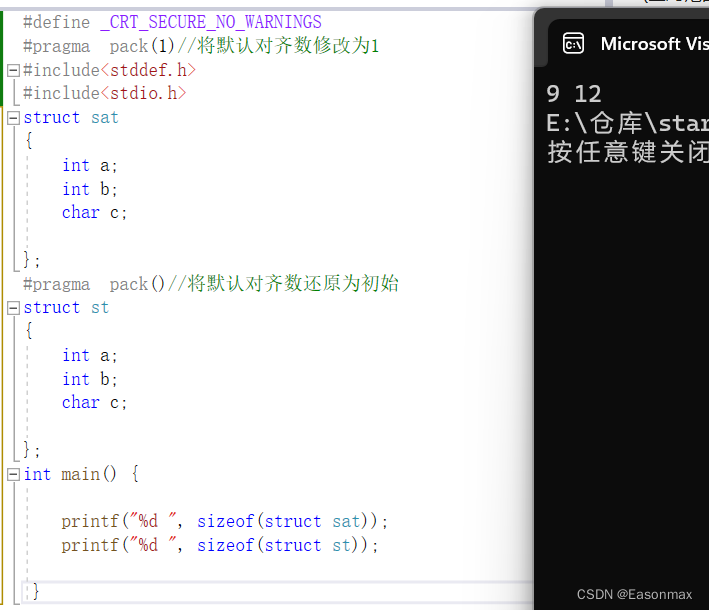
struct sat是在默认对齐数为1时创建的,而struct st 是默认对齐数为8时创建的。所以其字节大小不同 。
对于linux中gcc其不存在默认对齐数时我们用pragma作用它,无需现在考虑它的作用,到时候如果真不存在默认对齐数我们再去探讨其到底怎样作用。现在我们只需考虑当存在默认对齐数时pragma其作用为上所述。(绝大部分情况编译器都存在默认对齐数,极少情况不存在)
?结构体传参
struct S
{
int data[1000];
int num;
};
struct S s = { {1,2,3,4}, 1000 };
void print1(struct S s)
{
printf("%d\n", s.num);
}//结构体传参
void print2(struct S* ps)
{
printf("%d\n", ps->num);
}//结构体地址传参
int main()
{
print1(s); //传结构体
print2(&s); //传地址
return 0;
}目前我们所学的数据名为地址类型的只有函数名,数组名,字符串(整个如“asddasds”),其他都是代表其整个数据。像结构体也是代表整个数据,其结构体变量名代表着整个结构体,而不是其结构体地址?。
结构体实现位段?
这是结构体的一个很细致的知识点(知道就行,其实很少用到)
?什么是位段
struct A
{
int a:2;
int b:5;
int c:10;
int d:30;
}
?其struct A(位段)内存大小为多少,答案为8个字节。那么为什么呢?接下来就要讲到其位段的内存分配
?位段的内存分配
?其跟结构体内存分配不一样,结构体分配符合对齐规则。以空间换取时间所以空间浪费会较多。?
而对于位段来说,其特点就是很能节省空间(不代表不会浪费空间,但相较于结构体浪费的肯定少)
现在说下其内存分配的细节:
我们的这个数字2或者5其实指的是其创建的变量所占的比特位大小,如a空间大小为两个比特位。
之所以设计位段是因为假设我们让a存入一个2,那么如果是int类型的a,就只会给最后两个比特位变化,其他30个比特位不变,白白浪费掉了30个比特位,而我们这时候设计一个为2个比特位的a,刚好不会浪费,相比于普通的int类型大大的节省了空间。?
这里还有个限制,我们的数字不能超过其数据类型的比特位大小,如前面是int,则数字不能超过32,否则系统会错误。
struct A
{
int a:2;
int b:5;
int c:10;
int d:30;
}
?当我们类型为int类型时,我们是以int类型的内存大小为单位来开辟的。
当我们类型为char类型时,我们是以char类型的字节大小为单位来开辟的。
上述就是c语言对于位段的明确规定。但是c语言还是有一些并没有明确规定,如把其数据以怎么的形式存入到其开辟的空间上去等等,c语言没有明确规定的东西就都是编译器所决定的,而不同的编译器有不同的规定,所以位段涉及很多不确定因素。位段是不跨平台的,注重可移植的程序应该避免使?位段(否则在vs能实现该功能换了个编译器就实现不了,此时要实现相同功能必须换代码)
?现在我们就说下在vs中其数据是以怎样的形式存入到其开辟的空间上去。
vs具体是将其数据依次从开辟的空间从右往左放(下一个开辟的空间是往右边创建,因为左边是低地址右边为高地址,注意这是数据内部,跟数组一样内部数据依次从低往高创建,多个数据才是高地址到低地址创建)
当开辟的空间所剩余的空间?法容纳下一个数据时,直接舍弃再创造另一个开辟的空间去容纳。(vs是直接舍弃,有的编译器还要利用)
从而我们解析下,
首先将a的内存放入第一个开辟的空间(一个字节内存),放入其空间的最右边(从右往左放入数据),然后b的内存从右往左放入第一个开辟的空间,由于只剩一个比特位了,c肯定不够,所以直接舍弃,。而后开辟第二个空间,其c依然从最右边放,而后剩余3个,不够放直接舍弃,从而创建第三个开辟的空间,依然从右边往左边放。这时就ok了,其位段内存为三个字节大小
图上的开辟的空间是以char类型字节的大小为单位去开辟的,以int类型字节的大小为单位去开辟同理也是从右往左,直接舍弃
?位段的跨平台问题
?内存分配中就提过跨平台问题,但那只是其中一部分,还有其他问题。
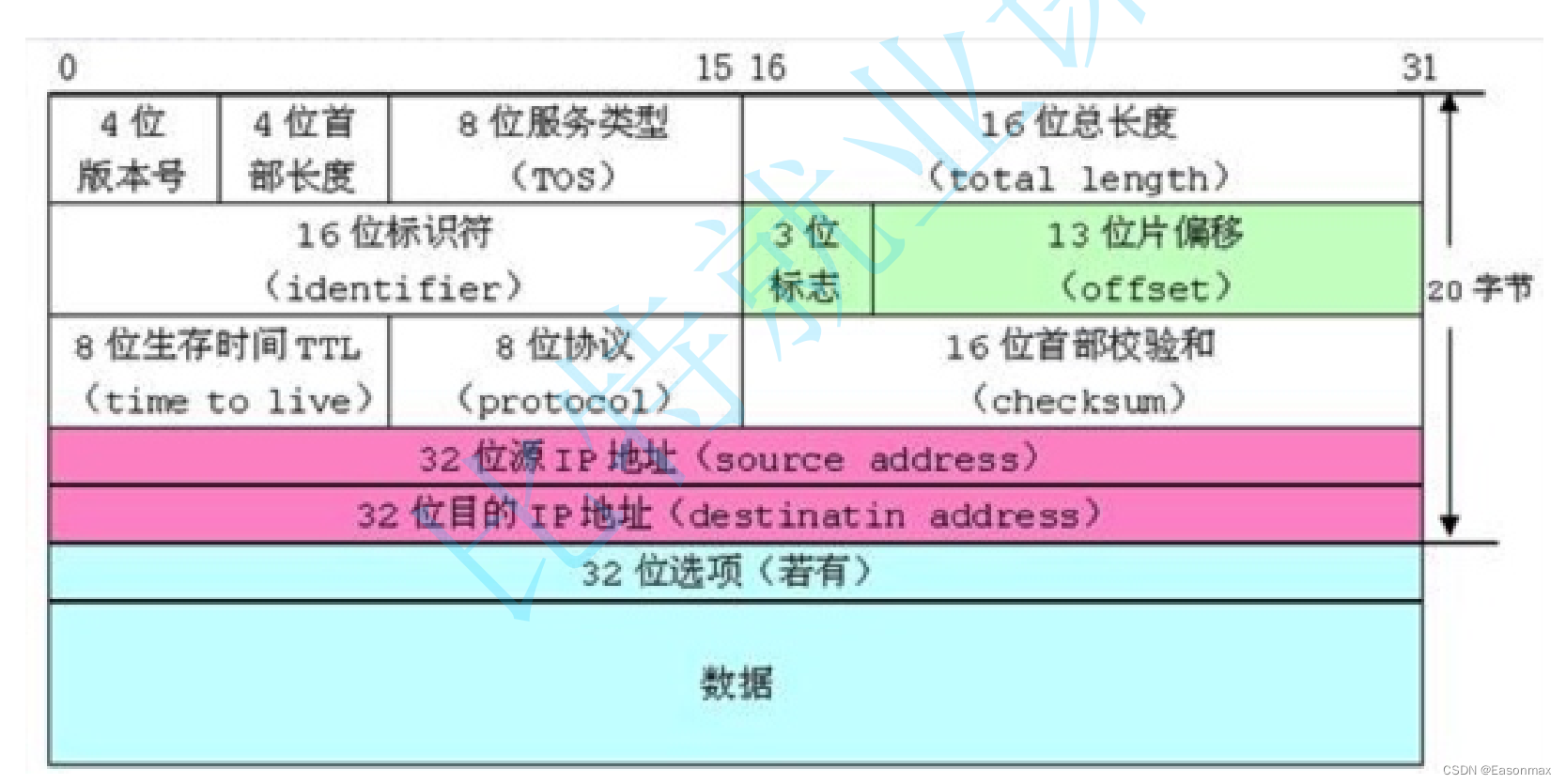
?位段的应用
?
?位段使?的注意事项
int main()
{
struct A sa = {0};
scanf("%d", &sa._b);//这是错误的
//正确的?范
int b = 0;
scanf("%d", &b);
sa._b = b;
return 0;
}?总结
那么在这里,我们的结构体类型就讲清楚了,之后将会给大家介绍联合体类型和枚举类型!
谢谢大家!!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 图神经网络并在 TensorFlow 中实现
- L1-076 降价提醒机器人(Java)
- [AutoSar]基础部分 RTE 介绍
- 沉浸式翻译【中英文翻译软件 Google 插件推荐】
- 剩余银饰的重量 - 华为OD统一考试
- Java中的串流链
- 了解特权身份管理(PIM)的基础知识
- 奇安信天擎 rptsvr 任意文件上传漏洞复现
- C语言--有一个3*4的矩阵,求出其中最大值的那个元素的值,以及其所在的行号和列号
- redis优化系列(五)