多层感知机
为什么要有多层感知机?
因为单层感知机无法解决XOR问题,单层感知机只能做线性平面
什么是多层感知机
我们可以通过在网络中加入一个或多个隐藏层来克服线性模型的限制, 使其能处理更普遍的函数关系类型。 要做到这一点,最简单的方法是将许多全连接层堆叠在一起。 每一层都输出到上面的层,直到生成最后的输出。 我们可以把前L?1层看作表示,把最后一层看作线性预测器。 这种架构通常称为多层感知机(multilayer perceptron),通常缩写为MLP
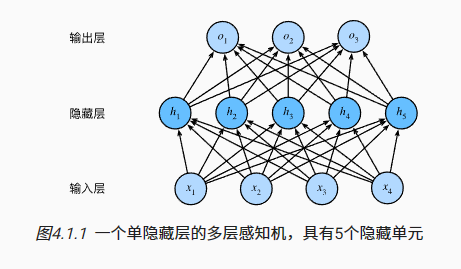
这个多层感知机有4个输入,3个输出,其隐藏层包含5个隐藏单元。
从线性到非线性
为了发挥多层架构的潜力, 我们还需要一个额外的关键要素: 在仿射变换之后对每个隐藏单元应用非线性的激活函数(activation function)σ。 激活函数的输出(例如,σ(?))被称为活性值(activations)。 一般来说,有了激活函数,就不可能再将我们的多层感知机退化成线性模型
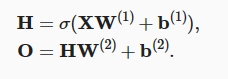
单隐藏层如何计算

什么是激活函数?
激活函数(activation function)通过计算加权和并加上偏置来确定神经元是否应该被激活, 它们将输入信号转换为输出的可微运算。 大多数激活函数都是非线性的
常见激活函数
ReLU函数
最受欢迎的激活函数是修正线性单元(Rectified linear unit,ReLU), 因为它实现简单,同时在各种预测任务中表现良好。 ReLU提供了一种非常简单的非线性变换。 给定元素x,ReLU函数被定义为该元素与0的最大值
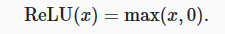
使用ReLU的原因是,它求导表现得特别好:要么让参数消失,要么让参数通过。
sigmoid函数
对于一个定义域在R中的输入, sigmoid函数将输入变换为区间(0, 1)上的输出。 因此,sigmoid通常称为挤压函数(squashing function): 它将范围(-inf, inf)中的任意输入压缩到区间(0, 1)中的某个值:
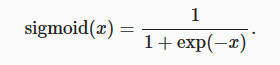
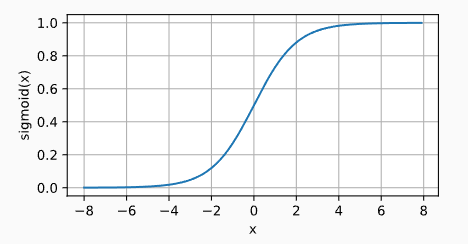
当人们逐渐关注到到基于梯度的学习时, sigmoid函数是一个自然的选择,因为它是一个平滑的、可微的阈值单元近似。 当我们想要将输出视作二元分类问题的概率时, sigmoid仍然被广泛用作输出单元上的激活函数 (sigmoid可以视为softmax的特例)。 然而,sigmoid在隐藏层中已经较少使用, 它在大部分时候被更简单、更容易训练的ReLU所取代。
小结
-
多层感知机在输出层和输入层之间增加一个或多个全连接隐藏层,并通过激活函数转换隐藏层的输出。
-
多层感知机在输出层和输入层之间增加一个或多个全连接隐藏层,并通过激活函数转换隐藏层的输出。
-
常用的激活函数包括ReLU函数、sigmoid函数和tanh函数。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ssm基于Java Web的在线电影票购买系统的设计与实现论文
- vue3+vite+ts实现qiankun微前端子应用
- pythonList列表
- 【控制器view的生命周期-控制器的销毁-掌握 Objective-C语言】
- 代码混淆:保护您的应用程序
- 基于Java (spring-boot)的在线考试管理系统
- 某联webpack解析(js逆向)
- SaaS在阿里云弹性伸缩策略方案
- Java使用Steam流对数据进行分组并排序
- 干洗店洗鞋店小程序开发系统功能特色