(2023|NIPS,时空专家混合去噪,边缘检测及监督)RAPHAEL:通过大量混合的扩散路径生成文本到图像
RAPHAEL: Text-to-Image Generation via Large Mixture of Diffusion Paths
公和众和号:EDPJ(添加 V:CV_EDPJ 或直接进 Q 交流君羊:922230617 获取资料)
目录
0. 摘要
文本 - 图像生成最近取得了显著的成就。我们引入了一种文本条件的图像扩散模型,称为RAPHAEL(distinct image regions align with different text phases in attention learning),用于生成高度艺术化的图像,准确地描绘文本提示,包括多个名词、形容词和动词。这是通过堆叠数十个混合专家(mixture-of-experts,MoEs)层实现的,即 空间-MoE 和 时间-MoE 层,从而实现了从网络输入到输出的数十亿扩散路径(route)。每条路径直观地充当 “画家”,在扩散步中将特定的文本概念描绘到指定的图像区域。全面的实验证明,RAPHAEL 在图像质量和审美吸引力方面优于最近的尖端模型,如稳定扩散、ERNIE-ViLG 2.0、DeepFloyd 和DALL-E 2。首先,RAPHAEL 在切换不同风格的图像方面表现出色,如日本漫画、写实主义、赛博朋克和墨水插画。其次,一个单一模型,具有 30 亿参数,经过两个月在 1,000 个 A100 GPU 上的训练,在 COCO 数据集上实现了 6.61 的最新零样本 FID 分数。此外,RAPHAEL 在 ViLG-300 基准上在人工评估方面显著超越了其竞争对手。我们相信 RAPHAEL 在学术界和工业界都具有推动图像生成研究前沿的潜力,为这个迅速发展的领域的未来突破铺平道路。
更多详细信息可以在网页上找到:https://raphael-painter.github.io
现有模型通常未能充分保留生成的图像中的文本概念。这主要是因为依赖交叉注意力机制将文本描述集成到视觉表示中,导致对扩散过程的相对粗糙的控制,从而导致了妥协的结果。
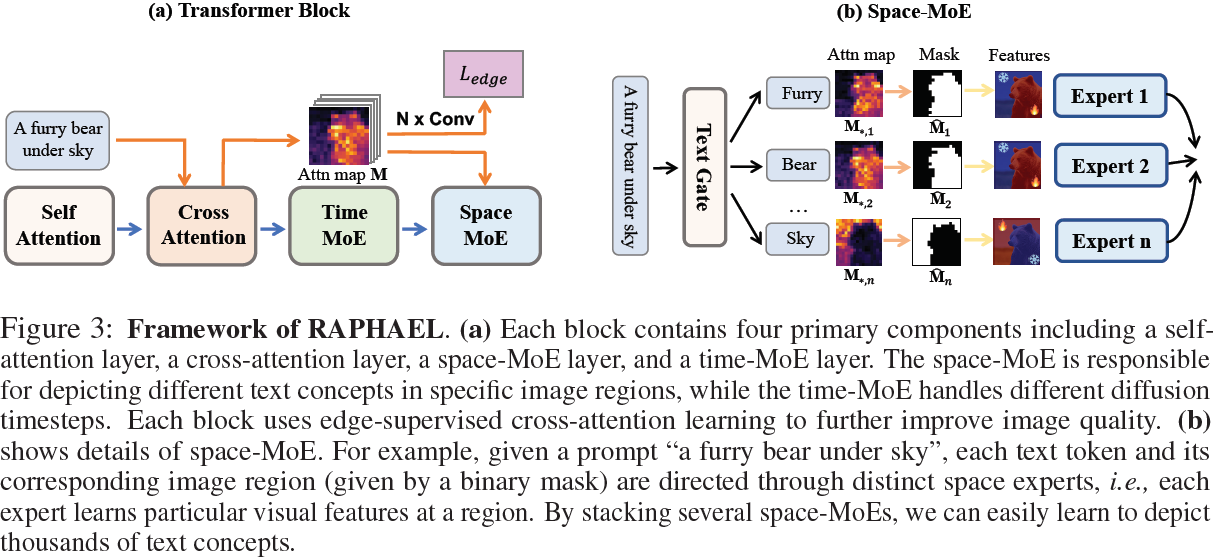
3. 方法
RAPHAEL 的总体框架如图 3 所示,网络配置的详细信息在附录 7.1 中提供。采用 U-Net 架构,该框架包含 16 个 transformer 块,每个块包含四个组件:自注意层、交叉注意层、空间-MoE 层和时间-MoE 层。空间-MoE 负责在给定尺度上在特定图像区域描绘不同的文本概念,而时间-MoE 处理不同的扩散时间步。
3.1 空间-MoE 和时间-MoE
空间-MoE。关于空间-MoE 层,如前所述,不同的文本标记对应于图像中的各种区域。例如,当提供提示 “天空下的毛茸茸的熊” 时,每个文本标记及其相应的图像区域(用二进制掩码表示)被馈送到单独的专家,如图 3b 所示。空间-MoE 层的输出是所有专家的均值,使用以下公式计算:
![]()
在这个方程中,y_i?是输入文本提示,^M_i 是一个二维二进制矩阵,指示第 i 个文本标记应对应的图像区域,如图 3b 所示。这里,? 表示哈达玛积,h′(x_t) 是来自时间-MoE 的特征。门控(路由)函数 route(y_i) 返回空间-MoE 中专家的索引,其中 {e1, e2, . . . , ek} 是一组 k 个专家。
文本门控网络。文本门控网络用于将图像区域分配给特定的专家,如图 3b 所示。使用函数
![]()
其中,G:R^(d_y) → R^k 是一个前馈网络,使用文本标记表示 E_θ(y_i) 作为输入,并分配一个空间专家。为防止模式崩溃,引入了随机噪声 ?。argmax 函数确保每个文本标记对应的图像区域由一个专家独占处理,而不增加计算复杂性。
从文本到图像区域。回想一下,M 是文本和图像之间的交叉注意力图,其中每个元素 M_(j,i) 表示第 j 个图像标记和第 i 个文本标记之间的对应值。在空间-MoE 中,如果 M_(j,i) ≥ η_i,二进制掩码 ^M_i 中的每个条目都等于 “1”,否则等于“0”,如图 3b 所示。引入了一个阈值机制来确定掩码中的值。阈值 η_i = α·max(M_(?,i)) 被定义,其中 max(M_(?,i)) 表示文本标记 i 与所有图像区域之间的最大对应。超参数 α 将通过消融研究进行评估。
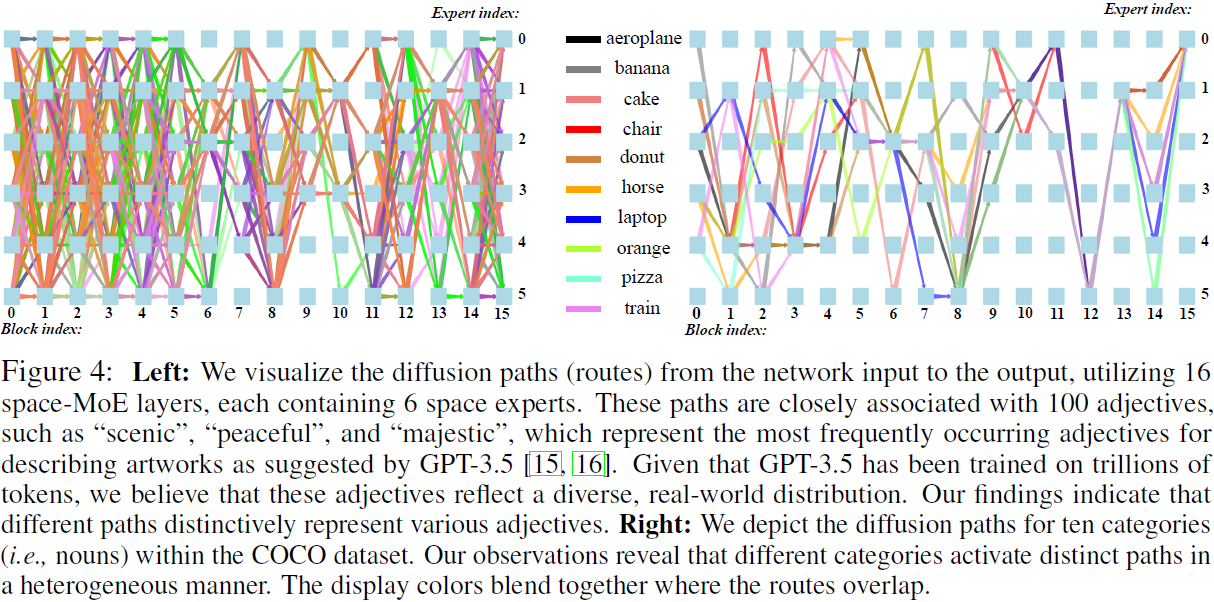
讨论。空间-MoE 背后的见解是有效地建模文本标记与图像中它们相应区域之间的复杂关系,准确反映生成图像中的概念。如图 4 所示,采用 16 个空间-MoE 层,每个层包含 6 个专家,导致数十亿个空间扩散路径(即 6^16 个可能路径)。显然,每个扩散路径与特定的文本概念密切相关。
为了进一步调查这一点,我们生成了 100 个最常用的形容词,这些形容词是 GPT-3.5 建议用来描述艺术作品的最频繁出现的形容词 [15, 16]。考虑到 GPT-3.5 已经在数万亿标记上进行了训练,我们认为这些形容词反映了多样化的真实世界分布。我们将每个形容词输入 RAPHAEL 模型,并使用 GPT-3.5 给出的提示模板生成 100 个不同的图像,并收集它们对应的扩散路径。因此,我们获得了这 100 个词的一万条路径。通过将这些路径视为特征(即每个路径是一个包含 16 个条目的向量),我们训练一个简单的分类器(例如,XGBoost [17])来对这些词进行分类。在 5 折交叉验证后,该分类器对于开放世界形容词达到了超过 93% 的准确率,证明了不同的扩散路径明显代表不同的文本概念。我们在 COCO 数据集的 80 个对象类别中观察到类似的现象。有关动词和可视化的更多细节,请参见附录 7.5。?
时间-MoE。通过采用时间混合专家(time-MoE)方法,我们可以进一步提高图像质量,这受到以前作品的启发,例如 [4, 5]。鉴于扩散过程通过一系列时间步骤 t = 1, . . . , T 不断用高斯噪声破坏图像,图像生成器被训练成按照 t = T 到 t = 1 的反向顺序去去噪图像。所有的时间步骤都旨在去噪一个嘈杂的图像,逐渐将随机噪声转化为艺术图像。直观来说,这些去噪步骤的难度取决于图像中呈现的噪声比例。例如,当 t = T 时,去噪网络的输入图像 x_t 非常嘈杂。当 t = 1 时,图像 x_t 更接近原始图像。
为了解决这个问题,我们在每个 transformer 块的每个空间-MoE 之前都使用一个时间-MoE。与 [4, 5] 相反,这需要手工制定时间专家分配,我们实现了一个额外的门网络,以自动学习将不同的时间步骤分配给各种时间专家。更多细节可以在附录 7.3 中找到。
3.2 边缘监督学习
为了进一步提高图像质量,我们提议将边缘监督学习(edge-supervised learning)策略融入到 transformer 块的训练中。通过实现一个边缘检测模块,我们旨在从图像中提取丰富的边界信息。这些复杂的边界可以作为监督,引导模型在各种风格中保留详细的图像特征。

考虑一个神经网络模块,P_θ(M),具有 N 个卷积层的参数(例如,N = 5)。该模块被设计成在给定注意力图 M(参见图 7a)的情况下预测一个边缘图。我们利用输入图像的边缘图(图 7b),表示为 I_edge,来监督网络 P_θ。I_edge 可以通过全面嵌套的边缘检测算法 [18] 获得。直观地说,网络 P_θ 可以通过最小化损失函数 L_edge = Focal(P_θ(M), I_edge) 进行训练,其中 Focal(·, ·) 表示聚焦损失(focal loss)[19],用于测量预测边缘图与 “地面实况” 边缘图之间的差异。此外,如 [5, 6] 中所讨论的,当时间步 t 较大时,注意力图 M 容易变得模糊。因此,在 t 较大时停用(暂停)边缘监督学习是必要的。这个时间步阈值值(T_c)是一个超参数,将通过消融研究进行评估。
总体而言,RAPHAEL 模型通过结合两个损失函数进行训练,L = L_denoise + L_edge。如图 7d 所示,边缘监督学习显著改善了生成图像的质量和审美吸引力。?
4. 实验
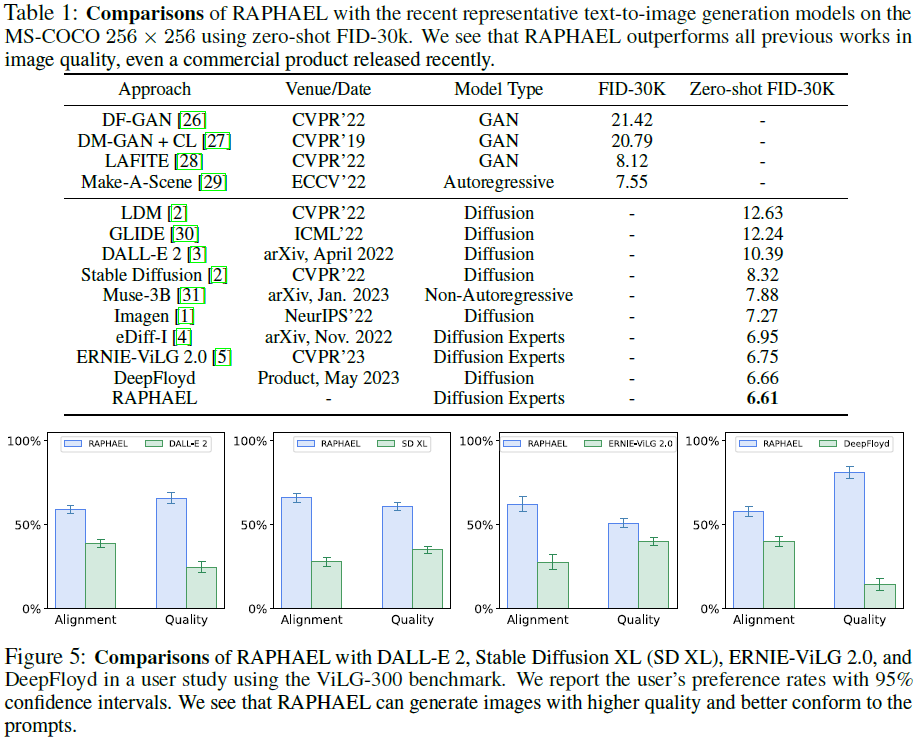
定量对比显示(表 1),?RAPHAEL 性能优越。
人类评估显示(表 2),RAPHAEL 在图文对齐和质量方面,更受人类偏爱。
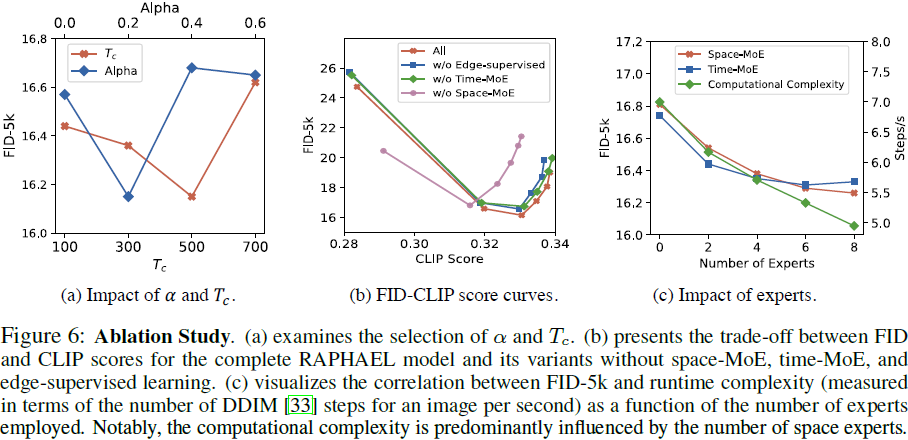
掩蔽门限参数 α = 0.2 提供最佳性能,在保留足够特征和避免使用整个潜在特征之间取得了平衡。?
一个适当的阈值 T_c 值可以在扩散时间步骤较大时终止边缘监督学习,T_c = 500?提供最佳性能。

7. 附录
7.3? 时间-MoE 的细节
RAPHAEL 的总体架构如图 8 所示。时间-MoE 由一个时间门控网络组成,根据时间步将特征分配给特定的专家,可以表示为
![]()
在这个方程中,h_c(x_t) 是来自交叉注意模块的特征。门控函数 t_router 返回 Time-MoE 中一个专家的索引,其中 {te_1,te_2,...,te_nt} 是一组 n_t 个专家。具体而言,时间门网络是通过一个在时间步 t_i 的函数实现的
![]()
为了防止模式崩溃,引入了随机噪声 ?。类似于文本门控
![]()
这是一个前馈网络,其中 d_t 是时间嵌入 E′_θ(t_i) 的维度。

分析。在我们的探索中,我们发现所有 transformer 块中时间专家的路由存在一些统计规律,与时间步长维度有明显的相关性。值得注意的是,我们观察到这些专家之间存在明显的分工,专门处理具有不同噪声水平的时间步骤。例如,如图 9 所示,在第一个 transformer 块中,第一个专家主要专注于处理嘈杂图像(代表 DDIM 采样器步骤的初始 59%),而其余专家处理相对噪声水平较低的图像(代表 DDIM 采样器步骤的最后 41%)。基于噪声特征的这种系统分配专业知识强调了该模型有效地调整计算资源的能力。
S. 总结
S.1 主要贡献
现有模型通常未能充分保留生成的图像中的文本概念。这主要是因为依赖交叉注意力机制将文本描述集成到视觉表示中,导致对扩散过程的相对粗糙的控制,从而导致了妥协的结果。
为此,本文提出?RAPHAEL(distinct image regions align with different text phases in attention learning),用于准确地描绘文本提示,生成高度艺术化的图像。它通过堆叠数十个(时间和空间)混合专家(mixture-of-experts,MoEs)层,实现了从网络输入到输出的数十亿扩散路径。每条路径直观地充当 “画家”,在扩散步中将特定的文本概念描绘到指定的图像区域。
使用边缘监督学习(edge-supervised learning)进一步提高图像质量。
S.2 方法
RAPHAEL?架构如图 8 所示。它采用 U-Net 架构,含 16 个 transformer 块,每个块包含四个组件:自注意层、交叉注意层、空间-MoE 层和时间-MoE 层。空间-MoE 负责在给定尺度上在特定图像区域描绘不同的文本概念,而时间-MoE 处理不同的扩散时间步。
空间-MoE。
- 给定提示,每个文本标记及其相应的图像区域(给定阈值,基于文本和图像的交叉注意力图,用二进制掩码表示)被馈送到单独的专家,如图 8c 所示。
- 空间-MoE 层的输出是所有专家的均值。
- 使用文本门控网络将图像区域分配给特定的专家。
时间-MoE。
- 在扩散过程的不同的去噪阶段,图像的噪声级别不同。?
- 为进一步提高图像质量,在每个 transformer 块的每个空间-MoE 之前都使用一个时间-MoE,如图 8d 所示。
- 不同的时间-MoE 用于不同阶段的去噪过程。
- 时间-MoE 由一个时间门控网络组成,根据时间步将特征分配给特定的专家。
边缘监督学习(edge-supervised learning)。
- 把边缘监督学习融入 transformer 块的训练中,可进一步提高图像质量。
- 它使用边缘检测算法,基于预测边缘图与 “地面实况” 边缘图之间的差异的聚焦损失(focal loss),训练一个边缘检测模块。
- 该模块从图像中提取丰富的边界信息,作为监督引导模型在各种风格中保留详细的图像特征。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Rust 最新版1.75.0升级记
- 如何编写好的测试用例?
- 本地git服务器的使用
- 总结项目中oauth2模块的配置流程及实际业务oauth2认证记录(Spring Security)
- Python实现多元线性回归模型信用卡客户价值预测项目源码+数据+项目设计报告
- 智能分析网关V4在工业园区周界防范场景中的应用
- Docker0网络设置
- 【冷备优缺点?】
- Java设计模式之命令模式详解
- Spring 使用 MongoDB 时的数据类型转换器