《数据结构》第六章:二叉树
6.1 二叉树的概念和性质
二叉树是一种递归数据的数据结构。
6.1.1 二叉树的定义
二叉树(BT)是含有n(n≥0)个结点的有限结合。当n=0时称为空二叉树。在非空二叉树中:
- 有且仅有一个称为根的结点:
- 其余结点划分为两个互不相交的子集L和R也是一棵二叉树,分别称为左二叉树和右二叉树。
二叉树有五种基本形态:
- 空二叉树(无结点)
- 只有一个根结点的二叉树。
- 右子树为空的二叉树
- 左子树为空的二叉树
- 左右子树均为非空的二叉树。

二叉树的结点包括一个数据元素及指向其左右子树的两个分支,分别称为左分支和右分支。结点的左、右子树的根称为该结点的左、右孩子,相应的,该结点称为孩子的双亲。同一个双亲的孩子之间可成为兄弟。结点的孩子个数称为结点的度。度为0的结点称为叶子结点。非叶子的结点称为内部结点或分支结点。
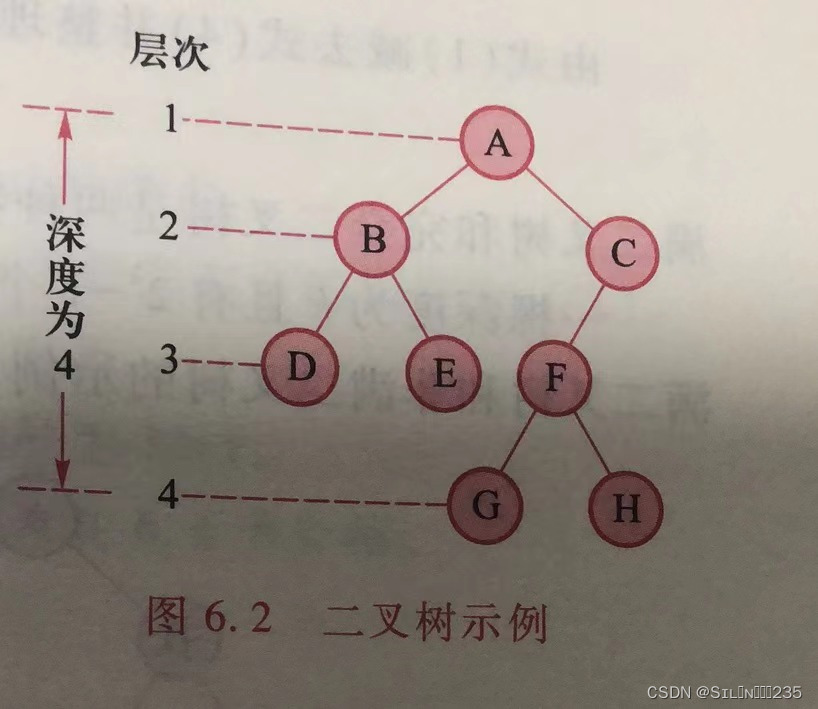
结点的层次从根结点开始定义,根为第1层,根的孩子为第2层,如此计数,直到该结点为止。二叉树中结点的最大层次称为二叉树的深度或高度。D的层次为3,二叉树的深度为4。
6.1.2 二叉树的性质
二叉树具有以下重要。
性质1:在非空二叉树的第i层上最多有2i-1个结点(i≥1)
证明:归纳法证明
当i=1时,二叉树中只有一个根结点,即2i-1=21-1=20=1。
假设对所有的j(1≤j<i)成立,即第j层上最多有2j-1个结点。也就是说,当j=i-1时,第i-1层上最多有2i-2个结点。
由于二叉树中每个结点的度最大为2,可推出第i层的结点个结点个数最多是第i-1层的结点个数的2倍,即2i-1×2=2i-1。
性质2:深度为k的二叉树上最多有2k-1个结点(k≥1)。
证明:基于性质1,深度为k的二叉树上的结点数至多为
20+21+…+2k-1=2k-1(等比数列求和) ??????????????????
性质3:对于任意一棵二叉树,如果度为0的结点个数为n0,度为2的结点个数为n2,则n0=n2+1
证明:假设度为1的结点个数为n1,结点总数为n,二叉树中的分支数为b。因为二叉树中结点的度均小于或等于2,所以结点总数为
??????????????????????????? ????????n=n0+n1+n2???????????????????? ??????(1)
在二叉树中,除根结点之外,每个结点都有一个分支指向它,所以n与b之间的关系为
??????????????????????????????? ????b=n-1??? ???????????????????????????(2)
因为度为1的结点对应一个分支,度为2的结点对应两个分支,所以n1、n2与b之间的关系为
?????????????????????????????????? b=n1+2n2??????????????????????????? ???(3)
由(2)和(3)可得
???n=n1+2n2+1???????????????????????? ?????(4)
由(1)减去(4)整理得
n0=n2+1
满二叉树和完全二叉树是两种特殊的二叉树。
一棵深度为k且由2k-1个结点的二叉树称为满二叉树。
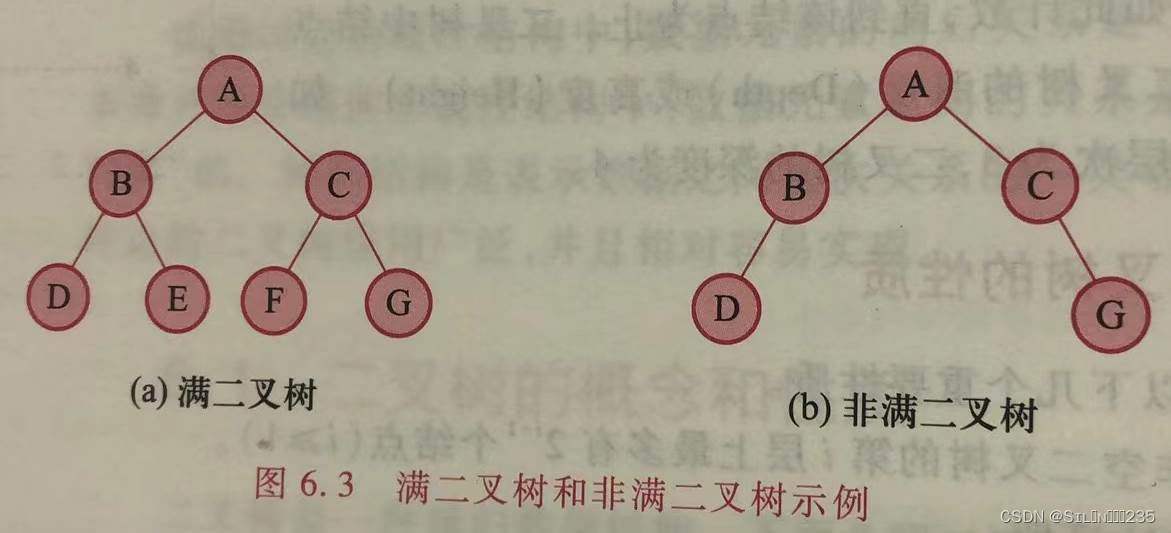
约定从根起,自上而下,自左而右,给满二叉树中的每个结点从1到n连续编号,编号为i的结点可称为i结点。
深度为k且含有k个结点的二叉树,如果其每个结点都与深度为k的满二叉树中编号从1至n的结点一一对应,则称为完全二叉树。

性质4:具有n个结点的完全二叉数的深度为k=?log2n?+1
证明:根据完全二叉树的定义和性质2可知,完全二叉树的结点总数为n,满足
2k-1-1<n≤2k-1
即n大于深度为k-1的满二叉树的结点数2k-1-1,且小于等于深度为k的满二叉树结点数2k-1。
由于不等式各项为整数,对两端各加1,可得2k-1≤n+1<2k。对于不等式取对数,有k-1≤log2n<k。
由于k是整数,所以有k=?log2n?+1.
性质5:对于含n个结点的完全二叉树中编号为i(i≤i≤n)的结点:
- 如果i=1,则i结点是这棵完全二叉树的根,没有双亲;否则其双亲的编号为?i/2?
- 如果2i>n,则i结点没有左孩子;否则其左孩子的编号为2i。
- 如果2i+1>n,则i结点没有右孩子,否则其右孩子的编号为2i+1.
性质5是完全二叉树的顺序存储表示和堆的重要基础。
6.2 二叉树的存储结构
在存储二叉树时,除了存储它的每个结点数据外,还要表示结点之间的一对多逻辑关系(父子关系)。
6.2.1 顺序存储结构
根据二叉树的性质5,可用一维数组存储完全二叉树:结点的编号对应该结点在数组中的下标。
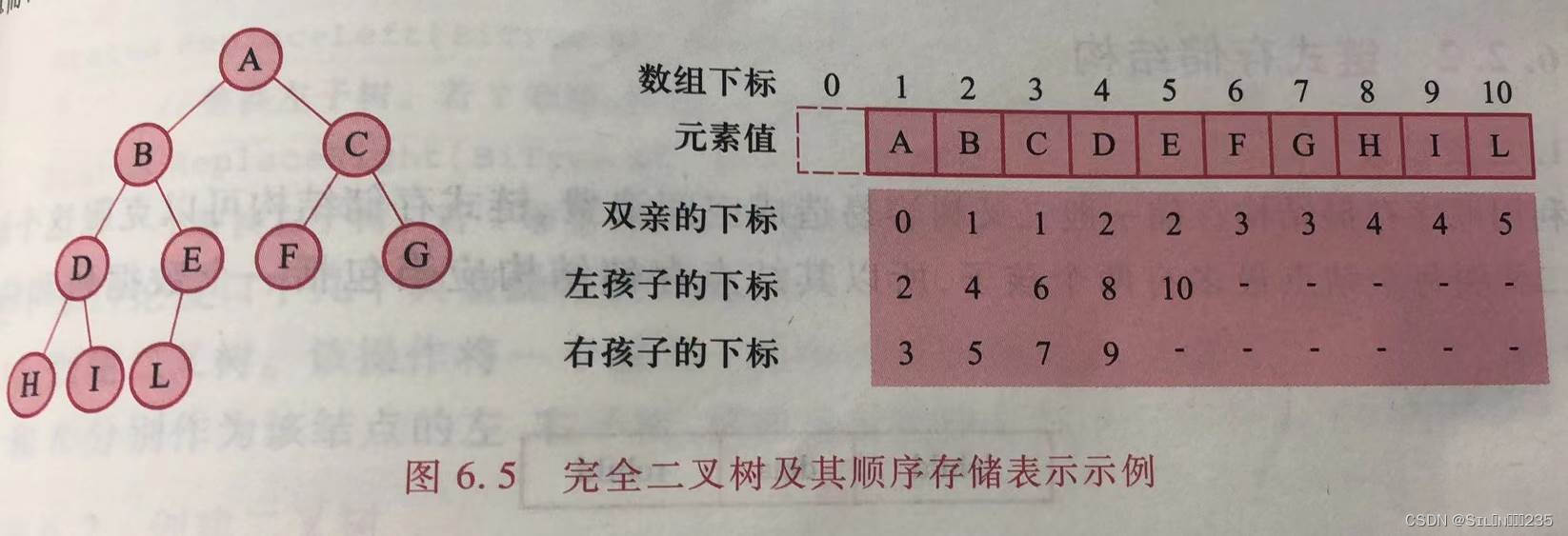
二叉树的顺序存储结构的类型定义如下:
typedef char TElemType;//假设二叉树结点的元素类型为字符
typedef struct{
??? TElemType *elem;//0号单元闲置
??? int lastIndex;//二叉树最后一个结点的编号
}SqBiTree;//顺序存储的二叉树例:判别v结点是否为u结点的子孙
根据v结点的编号,利用性质5(1),可以依次去找v结点的祖先结点的编号。若祖先编号为u,则v结点是u结点的子孙,返回TRUE。若祖先结点的编号均不为u,则返回FALSE。
算法:判别v结点是否为u结点的子孙
Status is_Desendant(SqBiTree T,int u,int v)
{
??? //判别v结点是否为u结点的子孙
??? if(u<1||n>T.lastIndex||v<1||v>T.lastIndex||v<=u)
??? {
??????? return FALSE;//u和v的范围不合理
??? }
??? while(v>u)//根据性质5找v的祖先
??? {
??????? v=v/2;
??????? if(v==u)//v是u的子孙
??????? {
?????????? return TRUE;
??????? }
??? }
??? return FALSE;
}6.2.2 链式存储结构
1.二叉链表
利用顺序存储结构一般存储容易造成空间浪费,链式存储结构可以克服这个缺点。由于二叉树每个结点最多有两个孩子,所以其结点存储结构应当包括一个数据域和两个指针域:

其中,lchild和rchild是分别指向该结点左孩子和右孩子的指针域,data是数据域。利用这种结点构建二叉树链式存储结构称为二叉链表,其类型定义如下:
typedef struct BiTNode{
??? TElemType data;//数据域
??? struct BiTNode *lchild,*rchild;//左右孩子指针
}BiTNode,*BiTree;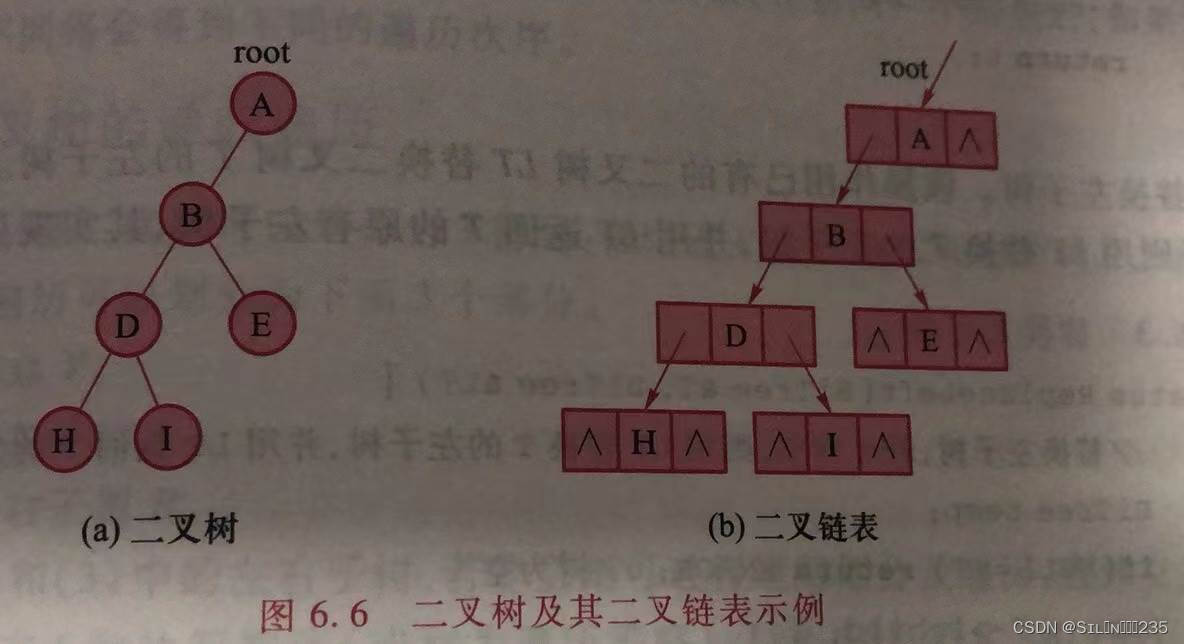
基于二叉链表的接口定义如下:
void InitBiTree(BiTree &T);//构建一棵空二叉树
BiTree MakeBiTree(TElemType e,BiTree L,BiTree R);//创建一棵二叉树,其中根结点的值为e,L和R分别作为左子树和右子树
void DestroyBiTree(BiTree &T);//销毁二叉树
Status BiTreeEmpty(BiTree T);//对二叉树判空。若空返回TRUE,否则返回FALSE
Status BreakBiTree(BiTree &T,BiTree &L,BiTree &R);//将一棵二叉树分解为根、左子树和右子树三部分
Status ReplaceLeft(BiTree &T,BiTree <);//替换左子树。若T非空,则用LT替换T的左子树,并用LT返回T的原有左子树
Status ReplaceRight(BiTree &T,BiTree &RT);//替换右子树。若T非空,则用LR替换T的右子树,并用RT返回T的原有右子树算法:构建二叉树
BiTree MakeBiTree(TElemType e,BiTree L,BiTree R)//创建一棵二叉树,其中根结点的值为e,L和R分别作为左子树和右子树
{
??? BiTree t;
??? t=(BiTree)malloc(sizeof(BiTNode));
??? if(t==NULL)
??? {
??????? return NULL;
??? }
??? t->data=e;//根结点的值为e
??? t->lchild=L;//L作为t的左子树
??? t->rchild=R;//R作为t的右子树
??? return t;
}算法:替换左子树
Status ReplaceLeft(BiTree &T,BiTree <)//替换左子树。若T非空,则用LT替换T的左子树,并用LT返回T的原有左子树
{
??? BiTree temp;
??? if(T==NULL)
??? {
??????? return ERROR;//树为空
??? }
??? temp=T->lchild;
??? T->lchild=LT;
??? LT=temp;
??? return OK;
}2.三叉链表
二叉链表便于处理当前结点的孩子结点,但不能直接访问其双亲结点。在指针域增加一个双亲结点的指针域parent,以此构建三叉链表,结点形式如下:

三叉链表的类型定义如下:
typedef struct TriTNode{
??? TElemType data;//数据域
??? TriTNode*parent,*lchild,*rchild;//双亲、左右孩子结点
}TriTNode,*TriTree;6.3 遍历二叉树
遍历二叉树是指从根结点出发,按照某种次序访问二叉树中所有结点,使得每个结点被且仅访问一次。这里的访问可以是输出、比较、更新、查看结点信息等各种操作,由实际应用确定。遍历是二叉树的一类重要操作,也是二叉树的其他一些操作和各类应用算法的基本框架。遍历对于线性结构来说是一种容易解决的问题,而对二叉树则不然。由于二叉树是一种层次结构,结点与其孩子结点对应的关系是一对多的关系,在访问一个结点后,如果对其孩子结点访问次序不同将会得到不同的遍历次序。
6.3.1 二叉树的递归遍历
由定义可知,一棵二叉树可以划分为三部分:根结点V,左子树L,和右子树R。根据分治法的思维,二叉树的遍历可以划分为下面三部分:
- 访问根结点V。
- 访问左子树L。
- 访问右子树R。
其中,对于(2)和(3)中的左右子树,若非空则可进行递归划分及遍历,直到空为止。
以上划分可以有6种执行顺序(或称为遍历策略):LVR、LRV、VLR、VRL、RVL和RLV。如果限定遍历左子树先于右子树,则只有3种策略:VLR、LVR、LRV,分别称为先序遍历、中序遍历和后序遍历。
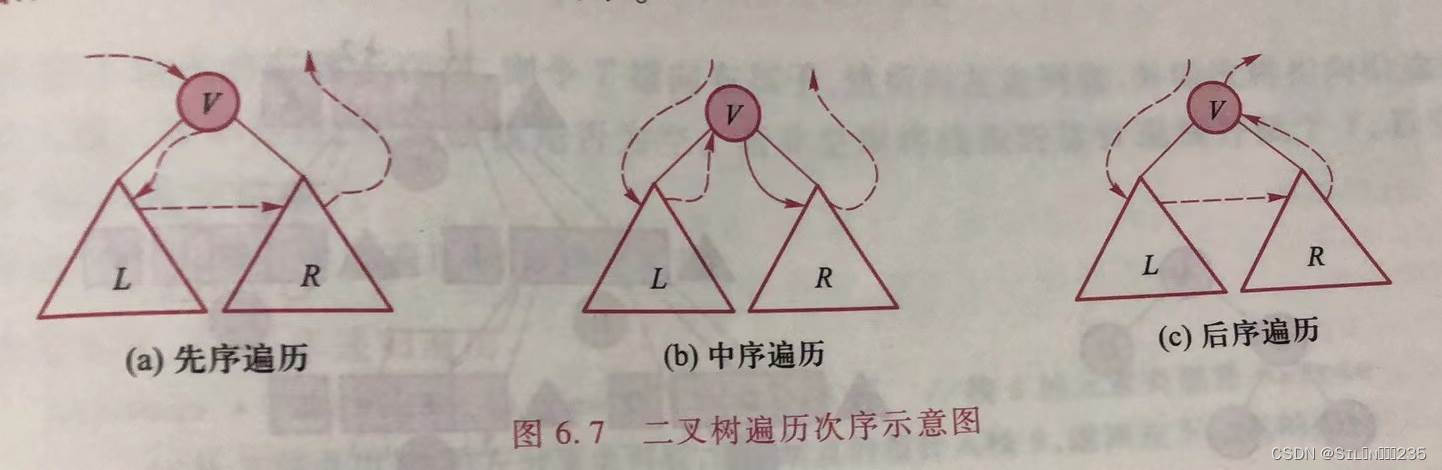
先序、中序、后序三种遍历都可递归实现,其区别是访问的根结点的时机不同。中序遍历的算法步骤为,若二叉树不为空,则可依次进行以下操作。
- 遍历根结点的左子树。
- 访问根结点
- 遍历根结点的右子树。
算法:中序遍历二叉树
Status InOrderTraverse(BiTree T,Status(*visit)(TElemType e))
{
??? //中序遍历二叉树T,visit是对数据元素操作的应用函数
??? if(NULL==T)
??? {
??????? return OK;
??? }
??? if(ERROR==InOrderTraverse(T->lchild,visit))
??? {
??????? return ERROR;//递归遍历T的左子树
??? }
??? if(ERROR==visit(T->data))//访问结点的数据域
??? {
??????? return ERROR;
??? }
??? return InOrderTraverse(T->rchild,visit);//递归遍历T的右子树
}从三种遍历算法的递归定义可以看出,它们的不同之处仅在于访问根结点、遍历左子树、遍历右子树这3个部分的先后顺序。如果去掉与递归无关的visit语句,则这三种遍历算法完全相同。由此,从递归执行过程的角度来看,如果忽略对结点的访问操作,则先序、中序和后序遍历的过程也是完全相同的。
6.3.2 二叉树的非递归遍历
为提高二叉树遍历算法的执行效率,可对其非递归实现
1.使用栈的中序非递归遍历
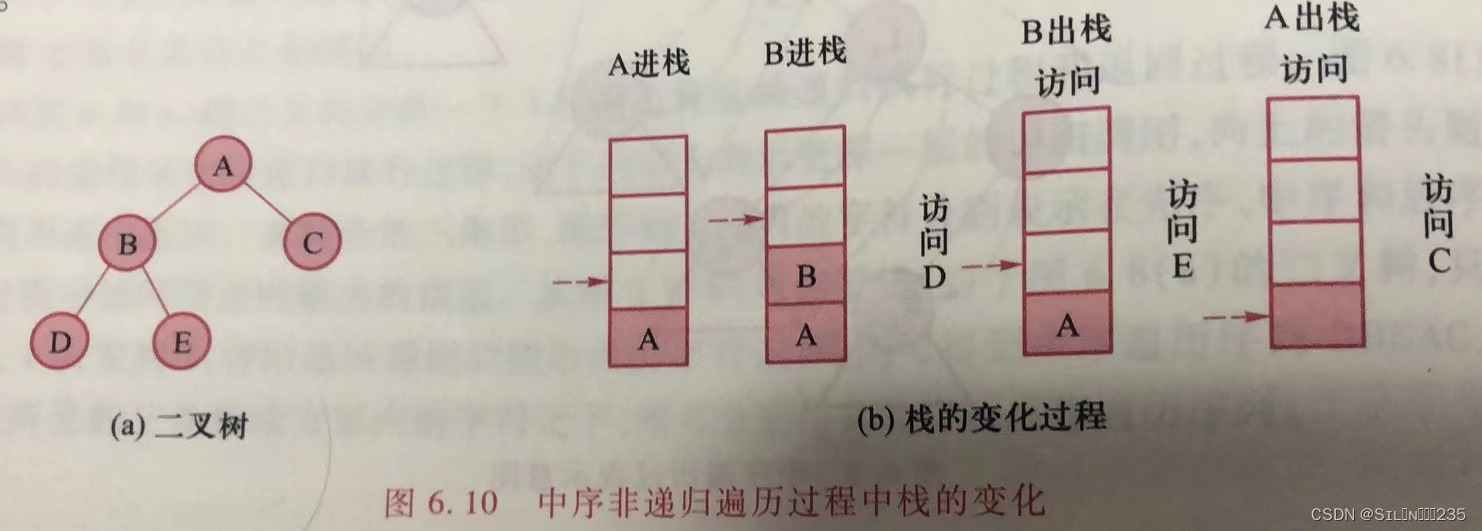
根据上述二叉树的遍历的递归执行过程,可以将二叉树的中序遍历理解为:
- 指针T从根结点出发,向左走到底,并依次将指向沿途结点的左孩子指针入栈
- 重复下面步骤,直到T为空
- 访问T结点。
- 若T结点的右孩子存在,则令T指向右孩子,然后向左走到底,并依次将指向沿途结点的指针入栈。若不存在,则判断栈是否为空。若非空则将栈顶的指针退栈并赋予T;若空,则强制T为空(遍历结束)
算法:中序非递归遍历
BiTNode * GoFarLeft(BiTree T,LStack &S)//栈S的元素类型是BiTree
{
??? //从T结点出发,沿左分支走到底,沿途结点指针入栈S,返回左下结点的指针
??? if(NULL==T)
??? {
?????? return NULL;
??? }
??? while(T->lchild!=NULL)
??? {
?????? Push_LS(S,T);
?????? T=T->lchild;
??? }
??? return T;
}
void InorderTraverse_I(BiTree T,Status(*visit)(TElemType e))
{
??? //中序非递归遍历二叉树T,visit是对数据元素操作的应用函数
??? LStack S;
??? InitStack_LS(S);
??? BiTree p;
??? p=GoFarLeft(T,S);//找到最左下的结点,并将沿途的结点的指针入栈S
??? while(p!=NULL)
??? {
?????? visit(p->data);//访问结点数据域
?????? if(p->rchild!=NULL)
?????? {
?????????? p=GoFarLeft(p->rchild,S);//令p指向其右孩子为根的子树的最左下结点
?????? }
?????? else if(StackEmpty_LS(S)!=TRUE)
?????? {
?????????? Pop_LS(S,p);//栈不空时退栈
?????? }
?????? else
?????? {
?????????? p=NULL;//栈空表明遍历结束
?????? }
??? }
}
2.不使用栈的先序非递归遍历
采用三叉链表存储结构,二叉树的非遍历可不使用栈。
算法:三叉链表的先序非递归遍历
Status PreOrderTraverse(TriTree T,Status(*visit)(TElemType e)){
??? //先序非递归遍历二叉树,visit的实参是对数据元素操作的应用函数
??? TriTree p,pr;
??? if(T!=NULL)
??? {
??????? p=T;
??????? while(p!=NULL)
??????? {
?????????? visit(p->data);//输出当前的结点
?????????? if(p->lchild!=NULL)
?????????? {
?????????????? p=p->lchild;//若有左孩子,继续访问
?????????? }
?????????? else if(p->rchild!=NULL)
?????????? {
?????????????? p=p->rchild;//若有右孩子,继续访问
?????????? }
?????????? else
?????????? {//沿双亲指针链查找,找到第一个右孩子的p结点,找不到则结束
?????????????? do
?????????????? {
??? ?????????????? pr=p;
?????????????????? p=p->parent;
????????????? }while(p!=NULL&&(p->rchild==pr||NULL==p->rchild));
?????????????? if(p!=NULL)
?????????????? {
?????????????????? p=p->rchild;//找到后,p指向右孩子结点
?????????????? }
?????????? }
??????? }
??? }
??? return OK;
}3.层次遍历——使用队列的非递归遍历
层次遍历是按二叉树的层次从小到大且每层从左到右的顺序依次访问结点。
对采用顺序存储结构的二叉树,其结点在数组中的顺序下标序列与层次遍历的访问顺序一致,因此可直接根据数组得到层次遍历的结果。然而,对采用链式存储结构的二叉树,难以获得结点的同一层的下一结点,从层末结点也难以得到下一层的层首结点。
在层次遍历中,当前层先访问的结点,在下一层访问时其左右孩子也先被访问,这符合队列的操作原则。因此,在进行层次遍历时,可使用一个辅助队列存储当前层被访问过的结点。那么二叉树采用二叉链表存储结构表示时,层次遍历算法的执行步骤如下:
- 访问根结点,并将根结点入队。
- 当队列不空时,重复下列操作:
- 队头结点出队;
- 若其有左孩子,则访问左孩子并入队。
- 若其有右孩子,则访问右孩子并入队
算法:二叉树的层次遍历
void LevelOrderTraverse(BiTree T,Status (*visit)(TElemType e))
{
??? //层次遍历二叉树T,visit实参是对数据元素操作的应用函数
??? if(T!=NULL)
??? {
??????? LQueue Q;
??????? InitQueue_LQ(Q);
??????? BiTree p=T;//初始化
??????? visit(p->data);
??????? EnQueue_LQ(Q,p);//访问根结点,并将其入队
??? }
??? while(OK==DeQueue_LQ(Q,p))//当队非空是重复执行操作,出队
??? {
??????? if(p->lchild!=NULL)//访问左孩子入队
??????? {
?????????? visit(p->lchild->data);
?????????? EnQueue_LQ(Q,p->lchild);
??????? }
??????? if(p->lchild!=NULL)//访问右孩子入队
??????? {
?????????? visit(p->rchild->data);
?????????? EnQueue_LQ(Q,p->rchild);
??????? }
??? }
}6.3.3 遍历的应用
遍历是二叉树的其他一些操作和各种应用算法的基本框架,如销毁二叉树,二叉树的叶子结点计数,求二叉树的深度等。
例:销毁二叉树
二叉树的销毁必须逐个释放所有节点,可采用遍历的算法框架。合理的结点释放顺序是采用后序遍历,先销毁左子树、右子树,在释放根结点。
算法:销毁二叉树
void DestroyBiTree(BiTree &T)
{
??? //销毁二叉树
??? if(T!=NULL)
??? {
??????? DestroyBiTree(T->lchild);//递归销毁左子树
??????? DestroyBiTree(T->rchild);//递归销毁右子树
??? ??? free(T);//释放根结点
??? }
}例:求二叉树的深度
二叉树由根结点和左子树、右子树构成,而根结点独占一层,所以二叉树深度为其左子树、右子树深度的最大值加1。那么利用后序遍历框架,先递归求得左、右子树深度,然后取两者较大值加1作为深度值返回。
算法:求二叉树深度
int BiTreeDepth(BiTree T)
{
??? //返回二叉树深度,T为树根的指针
??? int depthLeft,depthRight;
??? if(NULL==T)
??? {
??????? return 0;//空二叉树深度为0
??? }
??? else
??? {
??????? depthLeft=BiTree(T->lchild);//递归求左子树的深度
??????? depthRight=BiTree(T->rchild);//递归求右子树的深度
??????? return 1+(dedepthLeft>depthRight?dedepthLeft:depthRight);//左子树、右子树深度的较大值+1
??? ?}
}例:二叉树的叶子结点计数
利用遍历框架实现对叶子结点的计数,可增添一个初值为0的计数器引用形参,“访问结点“的操作为,若是叶子,则计数器增1.
算法:二叉树的叶子结点计数
void CountLeaf(BiTree T,int &count){
??? //用count对二叉树T的叶子计数
??? if(T!=NULL)
??? {
??????? //二叉树非空
??????? if(NULL==T->lchild&&NULL==T->rchild)
??????? {
?????????? count++;//对叶子结点计数
??????? }
??????? CountLeaf(T->lchild,count);
??????? CountLeaf(T->rchild,count);
??? }
}
例:构造二叉树
可以利用遍历框架,依次生成结点,建立二叉树树的存储结构。在先序遍历序列中,插入表示空子树的符号,以构成二叉树的树形描述序列。

可由下列序号表示:
A B D # # E # # C # #
算法:先序构造二叉树
BiTree CreateBiTree(char* defBT,int &i)
{
??? //基于先序遍历框架构造二叉树,defBT为树形描述序列,i为defBT的当前位标,初值为0
??? BiTree T;
??? TElemType ch;
??? ch=defBT[i++];
??? if('#'==ch)
??? {
??????? InitBiTree(T);//空树
??? }
??? else{
??????? T=MakeBiTree(ch,NULL,NULL)//构造结点ch
??????? T->lchild=CreateBiTree(defBT,i);.//构造左子树
??????? T->rchild=CreateBiTree(defBT,i);//构造右子树
??? }
??? return T;
}6.4堆
堆是一类完全二叉树,常用于实现排序,选择最大(最小)值和优先队列等。
6.4.1堆的定义
堆是具有以下特性的完全二叉树,其所有的非子叶结点均不大于(或不小于)其左右孩子结点,即按完全二叉树的结点编号排列,n个结点的关键字序列(k1-,k-2,…,kn)称为堆,当且仅当满足以下关系:
小顶堆:{?? ? ki≤k2i
ki≤k2i+1??????? ??}(i=1,2,…,?n/2?)
大顶堆:{?? ? ki≥k2i
ki≥k2i+1??????? ??}(i=1,2,…,?n/2?)
其中 ,若堆中所有非子叶结点均不大于其左右孩子,则称为小顶堆(小根堆);若堆中的所有非子叶结点均小于其左右孩子结点,则称为大顶堆(大根堆)。堆中的子树称为子堆。
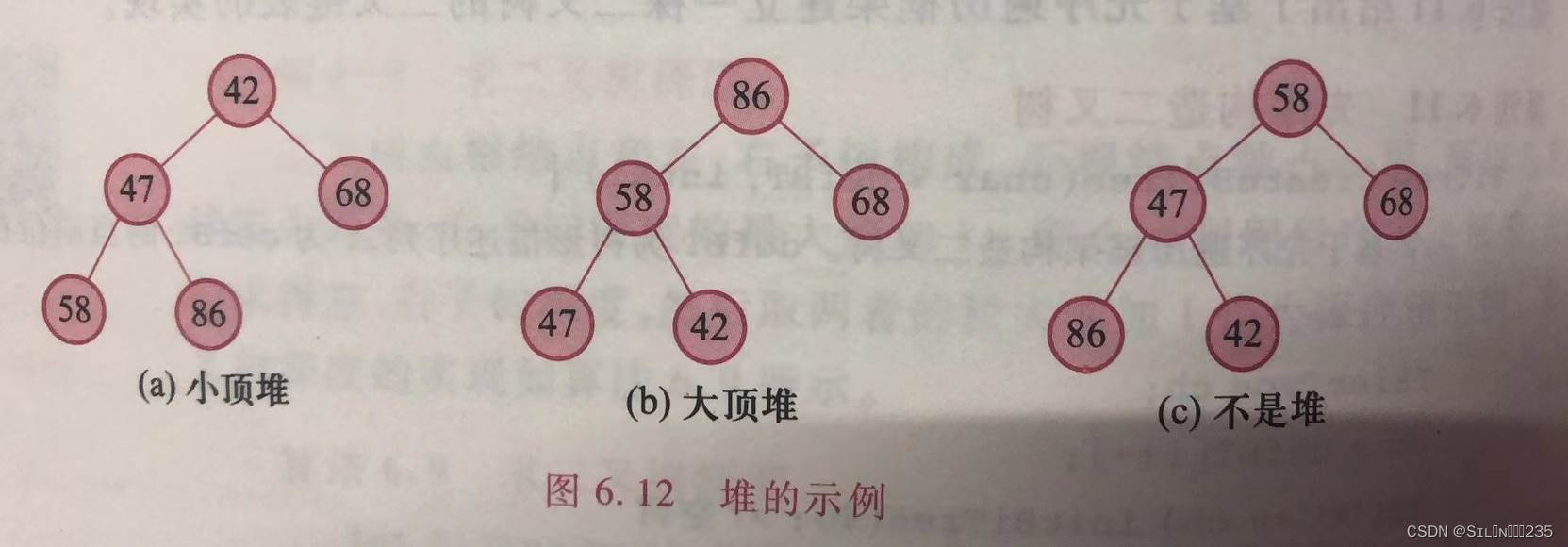
堆中根结点的位置称为堆顶,最后结点的位置称为堆尾,结点个数称为堆长度。由定义可知,小顶堆的堆顶结点必定为n个结点的最小值,而大顶堆的堆顶结点必定为n个结点的最大值。
由于堆需要考虑插入和删除操作,因此堆的存储结构应在完全二叉树的顺序结构中增加堆的长度域,其类型定义如下:
typedef struct{
??? RcdTyoe *rcd;//堆基址,0号单元闲置
??? int n;//堆长度
??? int size;//堆容量
??? int tag;//小顶堆与大顶堆的标志;tag=0为小顶堆,tag=1为大顶堆
??? int (*prior)(KeyType,KeyType);//函数变量,用于关键字优先级比较
}Heap;//类型对于大顶堆,假设关键字类型为整数,则大顶堆和小顶堆的优先函数可分别定义如下:
int greatPrior(int x,int y)
{
??? return x>=y;//大顶堆优先函数
}
int lessPrior(int x,int y)
{
??? return x<=y;//小顶堆优先函数
}堆的常用操作定义成如下的一组接口:
Status InitHeap(Heap &H,int size,int tag,int(*prior)(KeyType,KeyType));//prior为相应的优先函数
//初建最大容量为size的空堆H,当tag=0或1时分别表示小顶堆和大顶堆
void MakeHeap(Heap &H,RcdType *E,int n,int size,int tag,int (*prior)(KeyType,KeyType));
//用E建长度为n的堆H,容量为size,当tag为0或1时分别表示小顶堆和大顶堆
Status DestroyHeap(Heap&H);//销毁堆H
void ShiftDown(Heap &H,int pos);//对堆H中位置为pos的结点做筛选,将以pos为根的子树调整为子堆
Status InsertHeap(Heap&H,RcdType e);//将e插入堆
Status RemoveFirstHeap(Heap&H,RcdType&e);//删除堆H的堆顶结点,并用e将其返回
Status RemoveHeap(Heap &H,int pos,RcdType &e);//删除位置pos的结点,并用e返回其值6.4.2基本操作的实现
1.堆的筛选操作
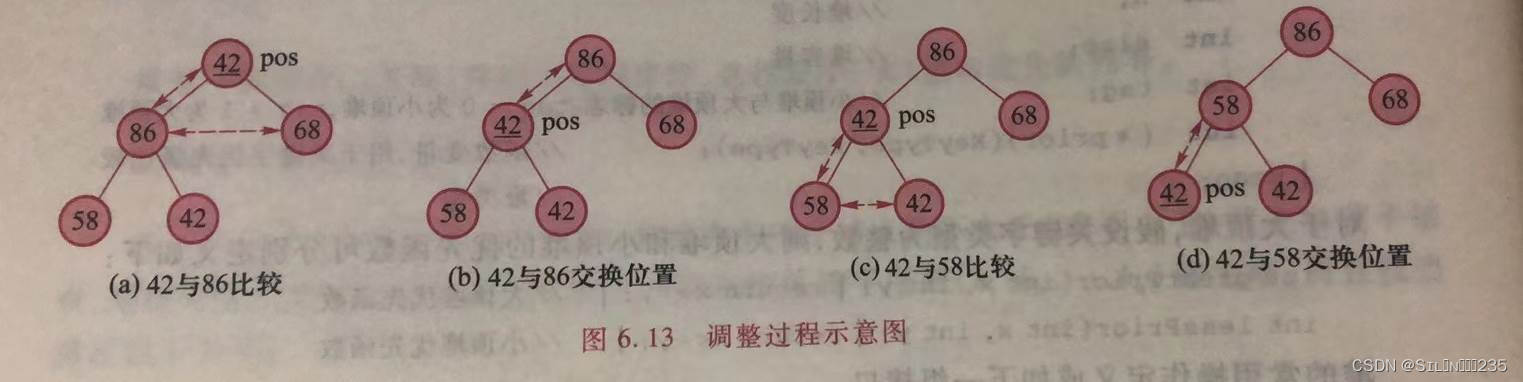
堆的筛选操作是将堆中指定的pos结点为根的子树调整为子堆。筛选操作的过程为,将pos结点的左右子树较优先者比较,若pos结点较优先则结束,否则pos结点与左右孩子中较优先者交换位置,pos位标下移。重复上述步骤,直到pos指示叶子结点为止。
例如,把pos结点为根的子树(42,86,68,58,42)筛选为大顶堆,其中结点42有两个,第一个带下划线。86较大,与42交换位置,pos下移;再次将pos结点的42和左右孩子的较大者58比较,58较大,因此58和42交换位置,pos下移,此时pos位置已达到叶子结点,调整结束。
算法:筛选操作
Status swapHeapElem(Heap &H,int i,int j)
{
??? //交换堆H中的第i个结点和第j个结点
??? RcdType t;
??? if(i<=0||i>H.n||j<=0||j>=H.n)
??? {
??????? return ERROR;
??? }
??? t=H.rcd[i];
??? H.rcd[i]=H.rcd[j];
??? H.rcd[j]=t;
??? return OK;
}
void ShiftDown(Heap &H,int pos)
{
??? //对堆H中位置为pos的结点做筛选,将以pos为根的子树调整为子堆
??? int c,rc;
??? while(pos<=H.n/2)//若pos结点为叶子结点,循环结束
??? {
??????? c=pos*2;//c为pos结点的左孩子位置
??????? rc=pos*2+1;//rc为pos结点的右孩子位置
??????? if(rc<=H.n&&H.prior(H.rcd[rc].key,H.rcd[c].key))
??????? {
?????????? c=rc;//c为pos结点的左右孩子中较为优先者的位置
??????? }
??????? if(H.prior(H.rcd[pos].key,H.rcd[c].key))
??????? {
?????????? return ;//若pos结点较优先,则筛选结束
??????? }
??????? swapHeapElem(H,pos,c);//否则pos和较优先者c交换位置
??????? pos=c;//继续向下调整
??? }
}对深度为k的完全二叉树,做一次筛选最多需要进行2(k-1)次比较。n个结点的完全二叉树的深度为?log2n?+1,因此筛选算法的时间复杂度为O(logn)。
2.堆的插入操作
堆的插入操作是将元素加到堆尾,此时须判别堆尾和其双亲结点是否满足堆特性,若不满足,则需要进行向上调整,将插入元素与双亲交换;交换后,插入元素若存在双亲且此双亲结点不满足堆特性,则需要重复上述操作,因此插入堆的操作步骤如下:
- 将插入元素加到堆尾,并用curr指示堆尾。
- 若curr指示堆顶,插入操作结束,否则,将curr结点与其双亲结点比较,若curr结点较优先则交换,curr上移,重复(2);否则插入操作结束。
例如,在堆(86,58,68,42,42)中插入98.首先将98插入到堆尾,并令curr指示堆尾;然后将98与双亲结点68比较,98较优先,与68交换位置;curr上移,继续与其双亲结点86比较,98较优先,与86交换位置;curr上移后已到堆顶,插入操作结束。
算法:堆的插入
Status InsertHeap(heap &H,RcdType e)
{
??? //将结点e插入到堆H中
??? int curr;
??? if(H.n>=H.size-1)
??? {
??????? return ERROR;//堆已满,插入失败
??? }
??? curr=++H.n;
??? H.rcd[curr]=e;//将插入元素加到堆尾
??? while(1!=curr&&H.prior(H.rcd[curr].key,H.rcd[curr/2],key))
??? {
??????? swapHeapElem(H,curr,curr/2);//交换curr和curr/2结点,即向上调整
??????? curr/=2;
??? }
??? return OK;
}插入操作是从叶子结点向上调整的过程,和筛选操作相反,最坏的情况下,比较次数为堆的高度减1,因此堆插入操作的算法时间复杂度为O(logn)。
3.删除堆顶结点的操作
删除顶堆结点时,用堆尾结点代替堆顶结点,不影响其左右子堆的特性,但需要对新的堆顶结点进行筛选,以维护整个堆的特性。删除堆顶结点的操作步骤如下:
- 取出堆顶结点。
- 将堆顶结点与堆尾结点交换位置,并将堆长度减1
- 对堆顶结点进行筛选。
算法:删除堆顶结点
Status RemoveFirstHeap(heap &H,RcdType &e)
{
??? //删除堆H的堆顶结点,并用e将其返回
??? if(H.n<=0)
??? {
??????? return ERROR;
??? }
??? e=H.rcd[1];//取出堆顶结点
??? swapHeapElem(H,1,H.n);//交换堆顶与堆尾结点,堆长度减1
??? H.n--;
??? if(H.n>1)
??? {
??????? ShiftDown(H,1);//从堆顶位置向下筛选
??? }
??? return OK;
}删除堆顶结点操作的主要工作是筛选,其时间复杂度为O(logn)。
4.建堆的操作
由于单个结点的完全二叉树满足堆特性,所以叶子结点都是堆,对n个结点的完全二叉树建堆的过程是,依次将以编号为n/2,n/2-1,…,1的结点为根的子树筛选为子堆。
例如,对初始序列(42,58,68,98,86,42)建堆,由于堆长度为6,所以只需依次对编号为3,2,1的结点筛选。
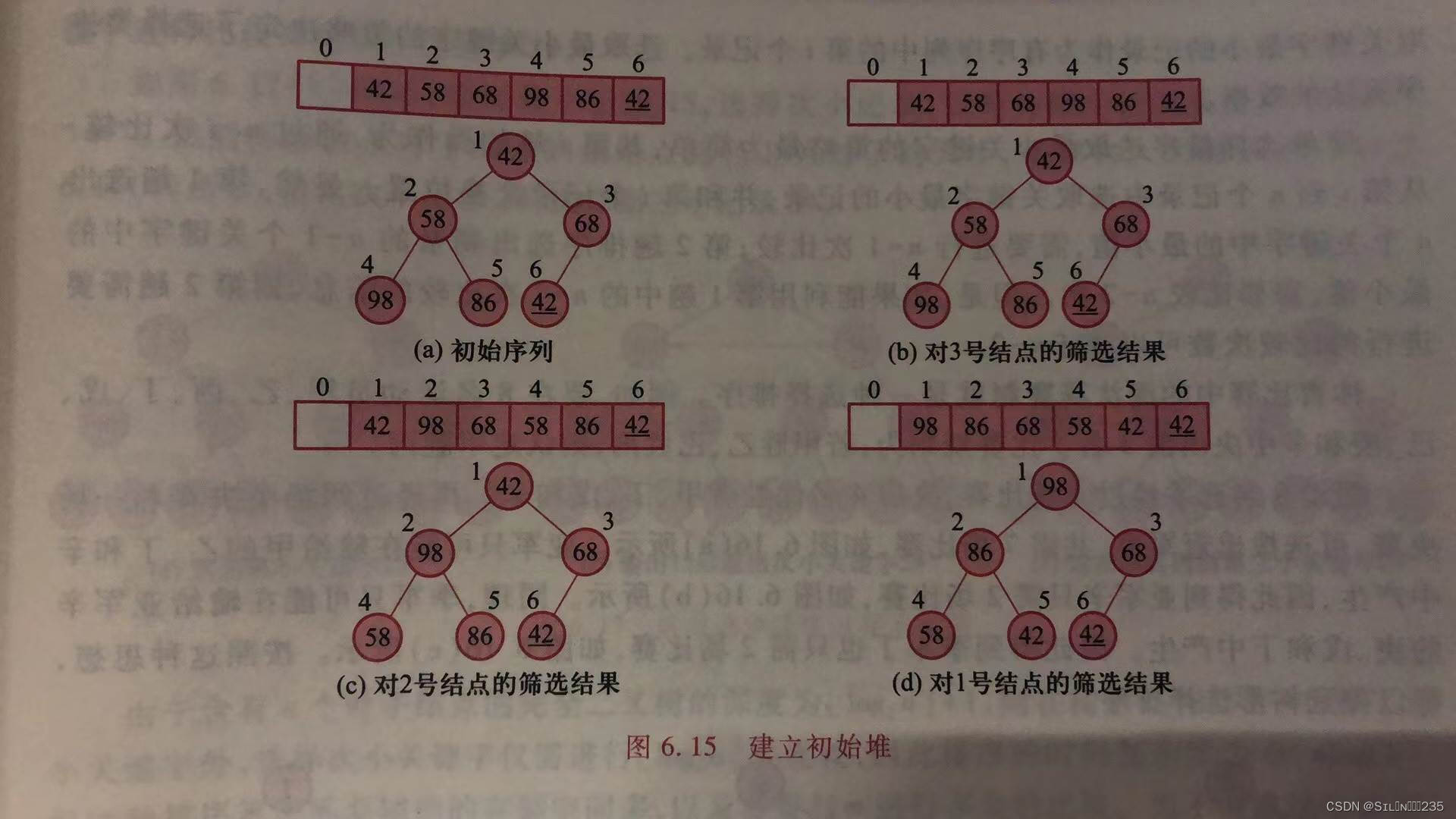
算法:建堆操作
void MakeHeap(Heap &H,RcdType *E,int n,int size,int tag,int (*prior)(KeyType,KeyType))
{
??? //用E建长度为n的堆H,容量为size,当tag=0或1w时分别表示为小顶堆或大顶堆
??? //prior为优先函数
??? int i;
??? H.rcd=E;//E[1..n]是堆的n个结点,0号单元闲置
??? H.n=n;
??? H.size=size;
??? H.prior=prior;
??? for(i=n/2;i>0;i--)
??? {
??????? ShiftDown(H,i);//对以i结点为根的子树进行筛选
??? }
}深度为h的堆中第i层上的结点数最多为2i-1,以它们为根的二叉树的深度为h-i+1,筛选算法中进行的关键字比较次数为2(h-i),则建堆总共进行比较的次数为
![]() ×2(h-i)=
×2(h-i)=![]() ×2(h-i)=
×2(h-i)=![]() ×j≤2n
×j≤2n![]() ≤4n
≤4n
因此,建立初始堆总共进行比较次数不会超过4n,其时间复杂度为O(n)。
6.4.3 堆排序
选择类排序的基本思路是,在n个记录中,第i趟(i=1,2,3,…,n-1)在第i到n个记录中选取关键字最小的记录作为有序序列中的第i个记录。选取最小关键字的策略决定了选择类排序算法的效率。
简单选择排序选取最屌关键字的策略最为简单,其中第i趟的操作为,通过n-i次比较,从第i到n个记录中选取关键字最小的记录,并和第i个记录交换位置。显然,第1趟选出n个关键字中的最小值,需要进行n-1次比较;第二趟排序选出剩余的n-1个关键字中的最小值,需要比较n-2次。但是,如果能利用第一趟中的n-1次比较的信息,则第二趟需要进行的比较次数可以少于n-2。
体育比赛中的淘汰赛赛制就是一种选择排序。例如,在8名运动员甲、乙、丙、丁、戊、己、庚、辛中决出前3名。比赛规则为,若甲胜乙,乙胜丙,则认定甲胜丙。
假设八名选手经过四场比赛,决出4名优胜者甲、丁、戊、辛。再经过两场半决赛和一场决赛,可选拔出冠军甲,共需7场比赛。亚军只可能在输给甲的乙、丁、辛中产生,因此得到亚军辛只需两场比赛。同理,季军只可能在输给亚军辛的庚、戊、丁中产生,因此得到季军丁也只需2长比赛。按这种思路,可以得到树形选择排序。
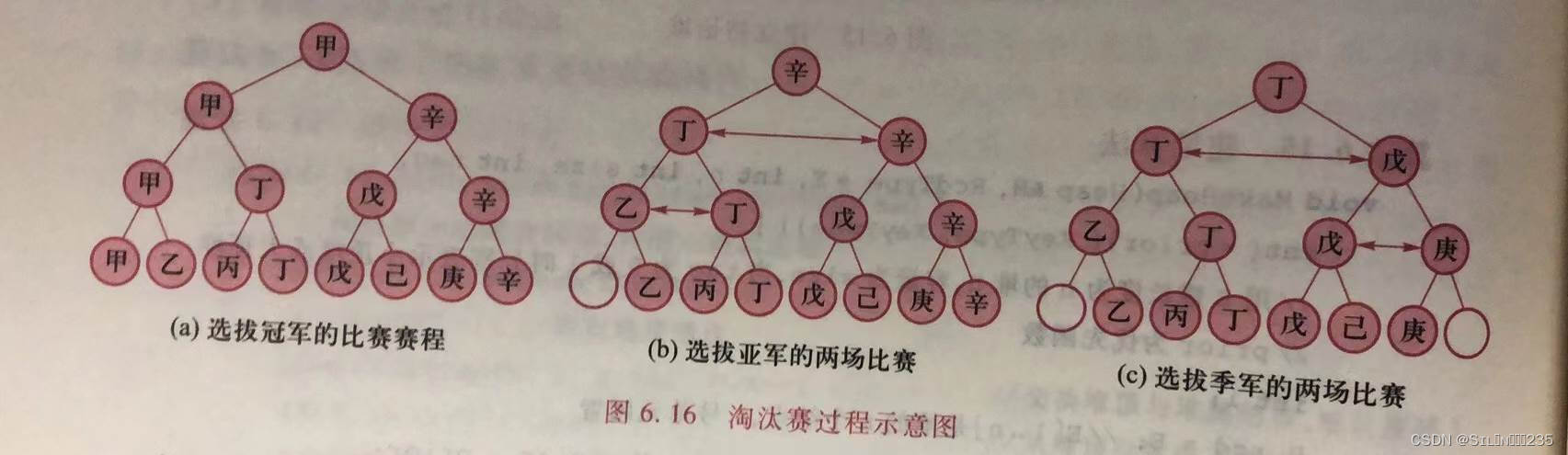
树形选择排序是按照淘汰赛思想进行的排序。该排序过程可用一颗有n个子叶结点的完全二叉树来表示,树形选择排序步骤如下:
- 首先对n个记录的关键字两两进行比较,然后再对?n/2?个较小者进行两两比较,如次重复,直至选出关键字最小的记录为止。
- 输出当前最小的记录,并将其对应的叶子结点的关键字改为“∞”。
- 沿着该叶子结点到根结点的路径,将沿途结点与其左或右兄弟结点比较,较小者填入双亲结点,最后根结点的关键字就是当前最小关键字。
- 重复(2)和(3),即可完成树形选择排序。
设待排关键字序列为78,46,15,28,56,87,34,92.将待排关键字序列存入完全二叉树的8个叶子结点,将左右兄弟的结点两两比较,得到四个较小的关键字46、15、56、34,再对这4个较小的关键字两两比较,得到2个较小的关键字15和34,最后对这两个关键字进行比较得到最小关键字15.
输出最下记录15,选择次小记录,仅需将最小记录的关键字15改为“∞”,然后再修改从子叶结点到根结点路径上关键字的大小,得到次小关键字28,输出次小记录28,选择第三小记录34。

由于含有n个子叶结点的完全二叉树的深度为?log2n?+1,则在树形结构排序中,除了最小关键字外,选择次小关键字仅需进行?log2n?次比较,因此排序的时间复杂度为O(nlog2n)。但这种排序算法需要辅助的存储空间多,以及与∞进行多余的比较,为了消除这个缺陷,有一种新的排序方法为——堆排序
堆排序利用堆的特性进行排序。采用大顶堆可以进行升序排序。首先将待排序列建成一个大顶堆,使得堆顶结点最大;将堆顶结点与堆尾结点交换位置,堆长度减1(即最大记录排序到位);然后调整剩余结点为堆,得到次大值结点;重复这一过程,即可得到一个升序序列。同理可采用小顶堆进行降序排序。
例如,对初始序列(42,58,68,98,86,42)进行升序堆排序的过程如下:
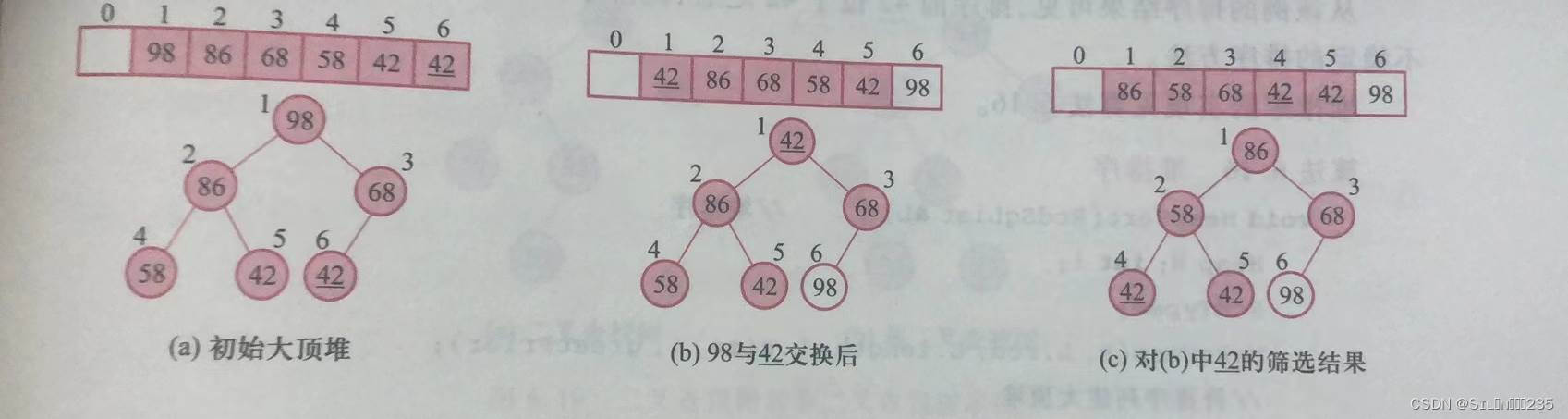
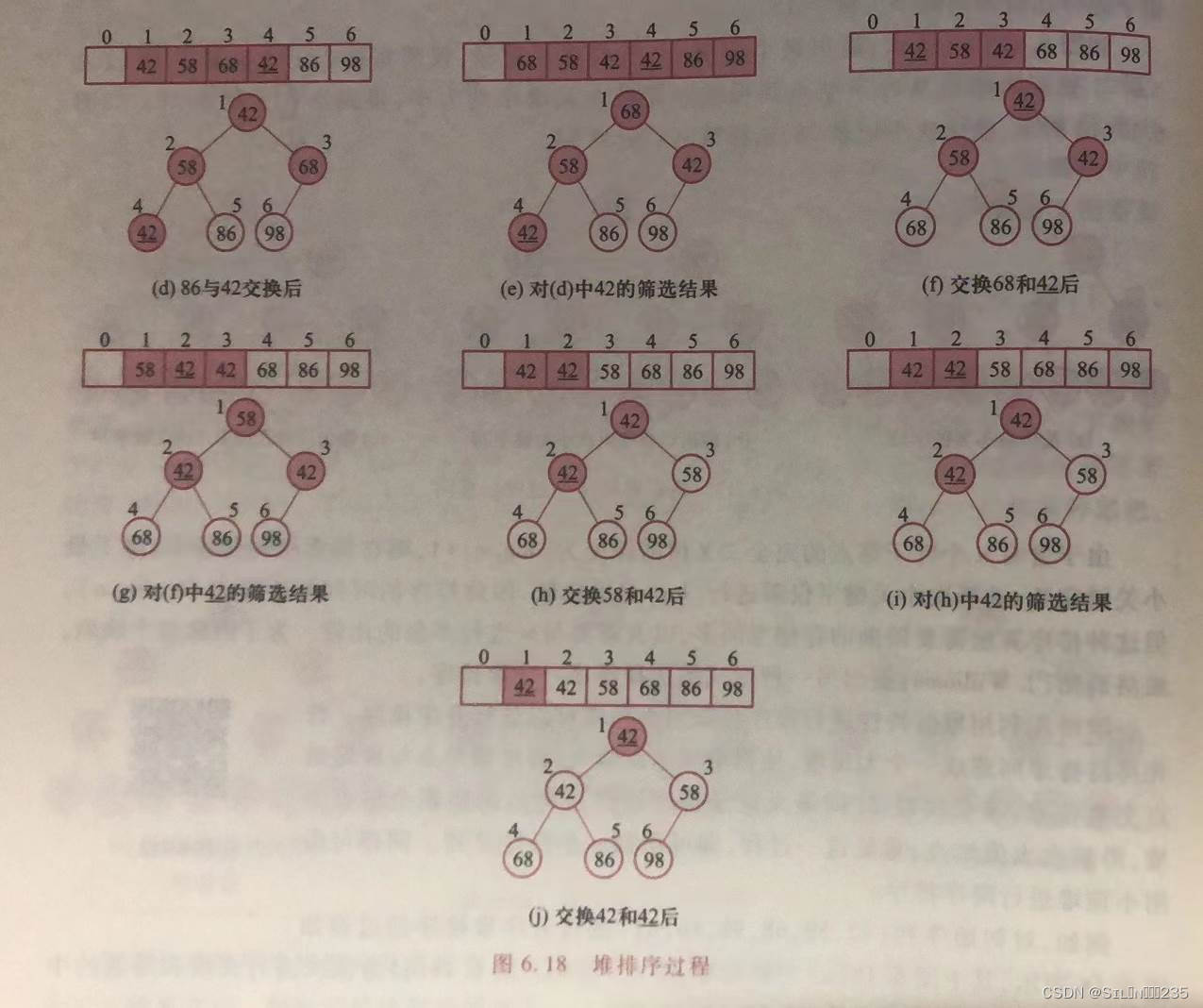
排序前42在42之后,但排序后却位于42之前,因此堆排序是不稳定的排序方法。
算法:堆排序
void HeapSort(RcdType &L)//堆排序
{
??? Heap H;
??? int i;
??? RcdType e;
??? MakeHeap(H,L.rcd,L.length,L.size,1,greatPrior);
??? //待排序列建大顶堆
??? for(i=H.n;i>0;i--)
??? {
??????? RemoveFirstHeap(H,e);//堆顶与堆尾结点交换,堆长度减1,筛选新的堆顶结点
??? }
}分析堆排序算法,其运行时间主要集中在建立初始堆和交换数据元素后的反复筛选上,它们均通过调用筛选算法实现的,建堆的时间复杂度为O(n)。
对长度为n的顺序表排序共需调用算法n-1次,n个结点的完全二叉树的深度为?log2n?+1,因此总共比较次数为
2(?log2(n-1)?+?log2(n-2)?+…+?log22?)≤2n?log2(n-1)?
堆排序的最坏时间复杂度为O(nlogn)
堆排序仅需要一个记录供交换系欸但使用,空间复杂度为O(1)。
6.5二叉查找树
二叉树的查找一般是通过遍历来实现,效率较低。二叉查找树是一种专门为查找而设计的二叉树,可提高查找效率。
6.5.1二叉查找树的定义
二叉查找树又称二叉排序树,或者是一棵空二叉树,或者是具有如下特性的二叉树:
- 若左子树不空,则左子树上的所有结点均小于根结点的值。
- 若右子树不空,则右子树上的所有结点均大于根结点的值。
- 左右子树也分别为二叉查找树。
由定义可知,二叉查找树中结点的值不允许重复,其中遍历序列是有序的。二叉查找树的二叉链表存储结构的类型定义如下:
typedef struct BSTNode{
??? RcdType data;//数据元素
??? struct BSTNode *lchild,*rchild;//左右孩子指针
}BSTNode,*BSTree;//二叉查找树
二叉查找树的基本操作接口定义:
Status InitBST(BSTree &T);//构造一棵空的二叉查找树T
Status DestroyBST(BSTre &T);//二叉查找树T存在,销毁树T
BSTree SearchBST(BSTree T,KeyType key);//若二叉查找树T中存在值为key的结点,则返回该结点指针,否则返回NULL
Status InsertBST(BSTree &T,RcdType e);//若二叉查找树中不存在值为key的结点,则插入到T
Status DeleteBST(BSTree &T,KeyType key);//若二叉查找树T中存在值为key的结点,则删除6.5.2二叉查找树的查找
二叉查找树的查找过程为,若二叉查找树为空,则查找不成功;若给定值等于根结点的值,则查找成功;若给定值小于根结点的值,则继续在左子树上递归查找;若给定值大于根结点的值,则继续在右子树上递归查找。
算法:二叉查找树查找的递归实现
BSTree SearchBST(BSTree T,KeyType key)
{
??? //二叉查找树递归查找
??? if(NULL==T)
??? {
??????? return NULL;//查找失败
??? }
??? if(T->data.key==key)
??? {
??????? return T;//查找值等于根结点的值
??? }
??? if(T->data.key>key)
??? {
??????? return SearchBST(T->lchild,key);//查找值小于根结点的值,递归在左子树里面查找
??? }
??? return SearchBST(T->rchild,key);//查找值大于根结点的值,递归在右子树里面查找
}二叉查找树查找过程中是沿着某条路径进行的,从执行效率考虑,应设计成迭代算法。假设要在二叉树T中查找值为key的结点,算法的基本过程可以表示为:
- 从树的根结点T出发查找。
- 若T不为空,则比较key和根结点的值,若
- key等于根结点的值,查找成功,返回指向该结点的指针
- key小于根结点的值,T指向左子树,重复过程(2)。
- key大于根结点的值,T指向右子树,重复过程(2)。
- 若T为空,则查找失败。
算法:二叉查找树查找的非递归实现
BSTree SearchBST_T(BSTree &T,KeyType key)
{
??? //二叉查找树非递归查找
??? while(T!=NULL)
??? {
??????? if(T->data.key==key)
??????? {
?????????? return T;//根结点的值等于查找值
??????? }
??????? else if(T->data.key>key)
??????? {
?????????? T=T->lchild;//根结点的值大于查找值,查找左子树
??????? }
??????? else
??????? {
?????????? T=T->rchild;//根结点的值小于查找值,查找右子树
??????? }
??? }
??? return NULL;//二叉查找树已被全部查找,没有找到,查找失败
}6.5.3二叉查找树的插入
为确保二叉查找树中结点的值不重复,需在插入前进行检查查找,若不存在才插入。二叉查找树插入算法的基本过程可描述为:
- 若二叉查找树为空树,则创建新插入的结点并作为根结点,算法结束。
- 若插入的结点的值小于根结点的值,在左子树递归插入。
- 若插入的结点的值大于根结点的值,在右子树递归插入。
算法:二叉查找树插入操作
Status InsertBST(BSTree &T,RcdType e)
{
??? //二叉查找树插入
??? if(NULL==T)//若二叉树为空树,则创建新插入的结点并作为根结点
??? {
??????? BSTree *s;
??????? s=(BSTNode *)malloc(sizeof(BSTNode));//开辟空间
??????? if(NULL==s)
??????? {
?????????? return OVERFLOW;//开辟空间失败
??????? }
??????? s->data=e;
??????? s->lchild=NULL;
??????? s->rchild=NULL;
??????? T=s;
??????? return TRUE;
??? }
??? if(e.key<T->data.key)
??? {
??????? return InsertBST(T->lchild,e);//插入结点的值小于根结点的值,在左子树递归插入
??? }
??? if(e.key>T->data.key)
??? {
??????? return InsertBST(T->rchild,e);//插入结点的值大于根结点的值,在右子树递归插入
??? }
??? return FALSE;//e,key==T->data.key,结点已经存在
?}可利用插入操作构造二叉查找树。从空树开始,逐个插入结点。
6.5.4 二叉查找树的删除
在二叉查找树种删除一个结点,必须维持二叉查找树的特性。可分为以下三种情况讨论:
- 被删除结点为叶子。删除叶子后仍为二叉查找树。
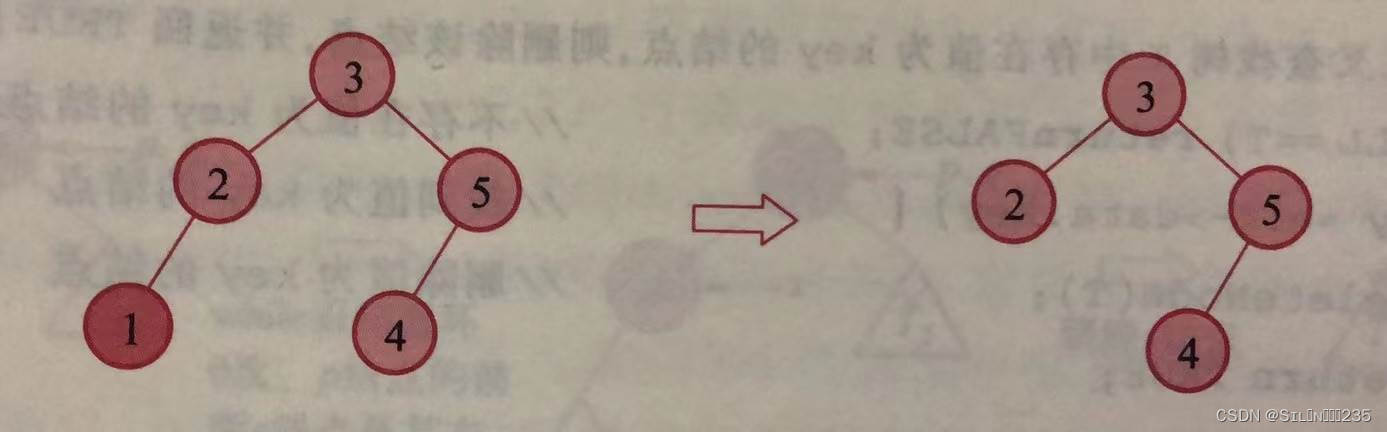
2.被删除结点只有左右子树之一为空,只需将被删除结点的结点非空子树直接置为其双亲结点的相应子树。
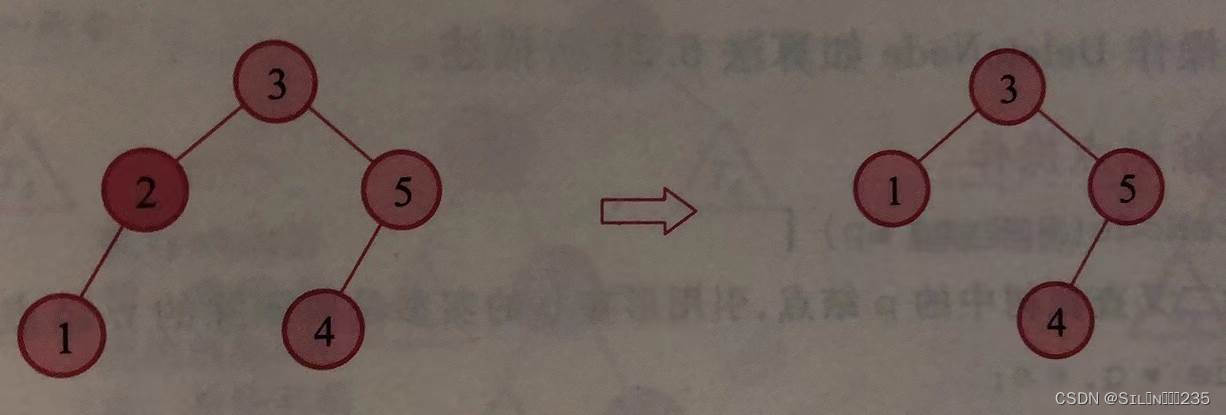
3.被删结点的左右子树均不为空。二叉查找树的中序序列是有序序列。如果先在二叉查找树中找到被删结点的直接前驱,并将其值赋值给被删结点,然后删去前驱结点,可不影响其余结点之间的有序关系,亦即不改变二叉查找树的特性。在二叉查找树中,被删结点的直接前驱位于其左子树的左下角(它的右子树为空),这就将删除转化为第(2)甚至第(1)种情形。

算法:二叉查找树删除操作
Status DeleteBST(BSTree &T,KeyType key)
{
??? //若二叉查找树种存在值为key的结点,则删除该结点,并返回TRUE;否则返回FALSE
??? if(NULL==T)//二叉查找树为空或者找不到值为key的结点
??? {
??????? return FALSE;
??? }
??? if(key==T->data.key)//找到值为key的结点
??? {
??????? DeleteNode(T);//删除值为key的结点
??????? return TRUE;//删除成功
??? }
??? else if(key<T.data.key)//查找值小于根结点的值
??? {
??????? return DeleteBST(T->lchild,key);//对左子树递归并返回结果
??? }
??? else//根结点的值小于查找值
??? {
??????? return DeleteBST(T->rchild,key);//对右子树递归并返回结果
??? }
}算法:删除结点操作
void DeleteNode(BSTree &p)
{
??? //删除二叉查找树中的p结点,引用形参p的实参是要删除的p结点的双亲指向其指针域
??? BSTNode *q,*s;
??? q=p;//令q指向要删除的p结点
??? if(NULL==p->rchild)//被删除的p结点的右子树为空
??? {
??????? p=p->lchild;//置p结点的左子树为p结点的双亲结点的相应子树
??????? free(q);//释放p结点的空间
??? }
??? else if(NULL==p->lchild)//被删除的p结点的左子树为空
??? {
??????? p=p->rchild;//置p结点的右子树为p结点的双亲结点的相应子树
??????? free(q);//释放p结点的空间
??? }
??? else//左右子树均不空
??? {
??????? s=p->lchild;//置s为p结点的左孩子
??????? while(s->rchild!=NULL)//向右走到尽头,令s指向被删结点的直接前驱
??????? {
?????????? q=s;
?????????? s=s->rchild;
??????? }
??????? p->data=s->data;//将直接前驱s结点的值赋予被删结点
??????? if(q==p)//s结点是被删结点的左孩子
??????? {
?????????? q->lchild=s->lchild;//删除s结点只需将其左子树置为q结点的左子树
??????? }
??????? else
??????? {
?????????? p->qchild=s->lchild;//删除s结点只需将其左子树置为q的右子树
??????? }
??????? free(s);
??? }
}在算法中,当被删结点的左右子树均不为空时,执行while语句后,根据s结点是否为被删的p结点的左孩子,分两种情形处理

6.5.5二叉查找树的性能
二叉查找树的查找过程与折半查找相似,也是一个逐步缩小查找范围的过程。若查找成功,则走过的是一条从根结点到待查结点的路径;若失败,则是一条根结点到某一个叶子结点的路径。因而,查找过程中关键字比较次数不超过树的高度。最好的情况为二叉查找树的高度最小,时间复杂度为O(logn);最坏的情况时二叉查找树为单支树,这时平均查找长度与顺序查找时相同,时间复杂度为O(n)。就平均性能而言,二叉查找树上的查找与折半查找相差不大,但二叉查找树上插入和删除结点十分方便,无需大量移动结点。
6.6平衡二叉树
二叉查找树要达到查找性能最优,其高度应为最小。满二叉树和完全二叉树的高度是最小的。但要在插入和删除结点之后维持其高度最小的代价较大。平衡二叉树是一种可以兼顾查找和维护性能的折中方案。
6.6.1平衡二叉树的定义
平衡二叉查找树简称平衡二叉树。平衡二叉树有很多种,其中最著名的是由前苏联数学家在1962年提出的高度平衡的二叉树,根据提出者的名字的英文名字首字母简写为AVL树。
平衡二叉树或者是棵空树,或者具有以下性质的二叉查找树:它的左子树和右子树都是平衡二叉树,且左子树和右子树的高度之差的绝对值不超过1.若将二叉树结点的平衡因子定义为该结点的左子树的高度减去它的右子树的高度,则所有结点的平衡因子只可能为-1、0、1.只要有一个结点的平衡因子的绝对值大于1,那么这棵树就失去了平衡。

在二叉查找树定义的基础上,平衡二叉树的结点增加了平衡因子bf,其存储结构的类型定义如下:
typedef struct BBSTNode {
??? RcdType data;
??? int df;//结点平衡因子
??? struct BBSTNode* lchild, * rchild;
}*BBSTree;//平衡二叉树平衡二叉树的查找过程和二叉查找树的查找过程相同。可以证明,在平衡二叉树上进行查找时,所进行的值比较次数是和logn同数量级的。而平衡二叉树的插入和删除都有可能破坏平衡二叉树的特性,若失衡则需调整,令其重新满足平衡二叉树的定义。
6.6.2平衡二叉树的失衡及调整
在平衡二叉树种插入一个新的结点之后,从该结点起向上寻找第一个不平衡的结点(平衡因子bf变成-2或者2),以确定该树是否失衡。若找到,则该结点为根的子树称为最小失衡子树。
当插入结点导致失衡时,如果将最小失衡子树调整为平衡子树而且其高度与插入前的高度相同,则整棵树可恢复平衡且无须调整其他结点。对最小失衡子树的调整操作可归纳为以下四种情况:
- LL型。LL型指的是在最小失衡子树的左孩子的左孩子上插入新的结点。先找到最小失衡子树的根A,以其左孩子结点B为轴,对不平衡结点进行顺时针旋转(也称为右旋)。右旋是让B顶替A的位置,并置A为B的右孩子,如果B存在右子树BR,则置BR为A的左子树。

算法:右旋调整
void R_Rotate(BBSTree &p)
{
??? //对失衡子树p做右旋调整
??? BBSTree lc=p->lchild;//lc指向p结点的左孩子
??? p->lchild=lc->rchild;//lc结点的右孩子置为p结点的左子树
??? lc->rchild=p;//置p结点(原来的根结点)为lc结点的右孩子
??? p=lc;//p指向新的根结点
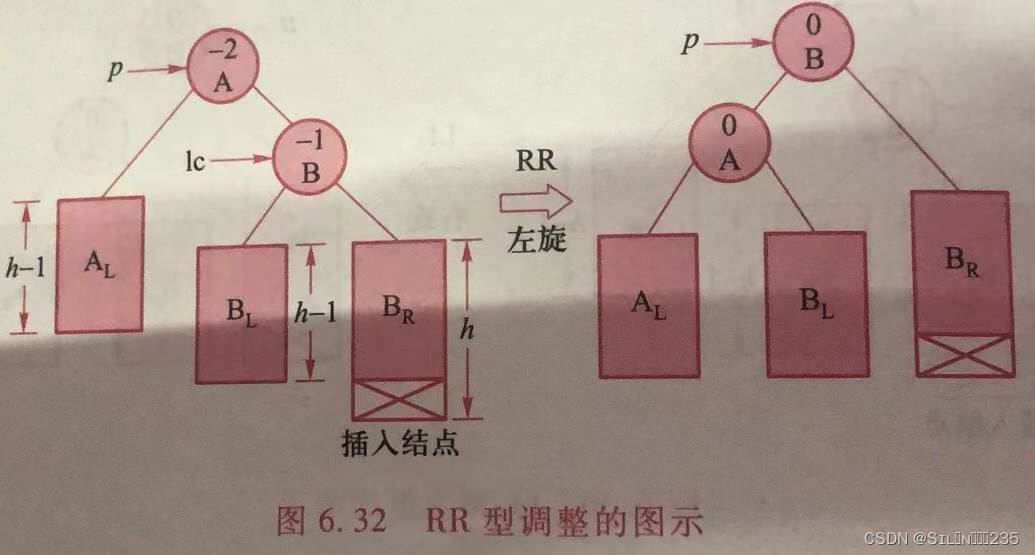
}2.RR型。对于RR型,正好与LL型对称,对以A为根的最小失衡子树进行逆时针旋转(也称为左旋)。
算法:左旋调整
void L_Rotate(BBSTree &p)
{
??? //对最小失衡子树p作左旋调整
??? BBSTree rc=p->rchild;//rc指向p的左孩子
??? p->rchild=rc->lchild;//rc结点的左子树置为p结点的右子树
??? rc->lchild=p;//置p结点(原根结点)为rc结点的左孩子
??? p=rc;//p指向新的根结点
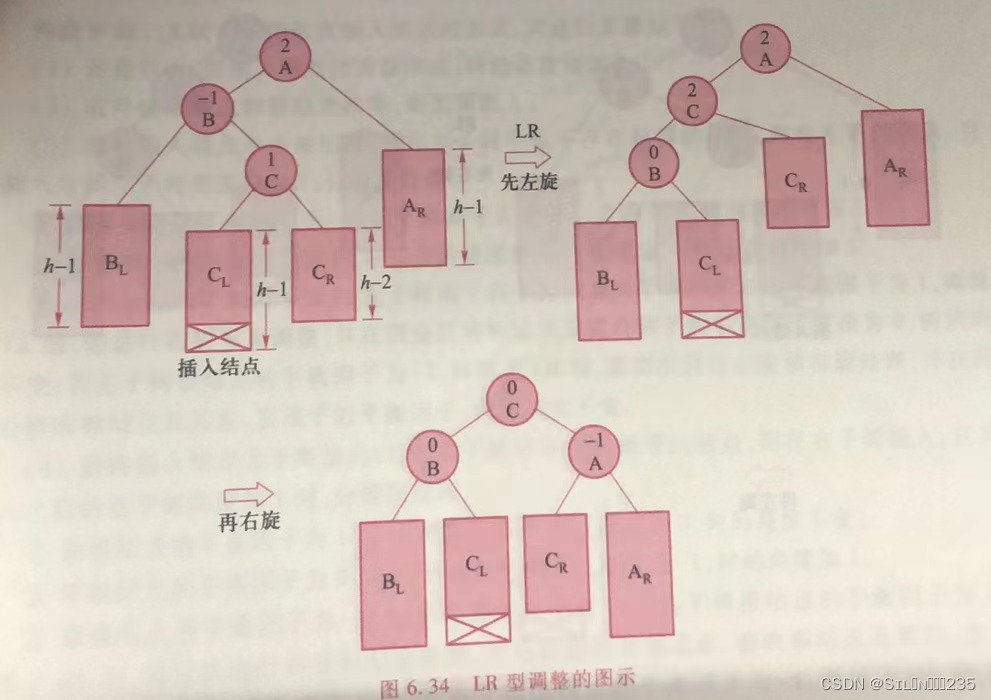
}3.LR型。LR型指的是最小平衡子树的左孩子的右子树插入了新的结点。处理办法:首先找到以A为根的最小失衡子树,以该子树的左孩子子树B为轴,对右子树结点C进行左旋调整,使之变为LL型。再以C为轴,对不平衡结点A进行右旋调整。
4.RL型。RL型和LR型对称,需进行右旋处理和左旋处理。
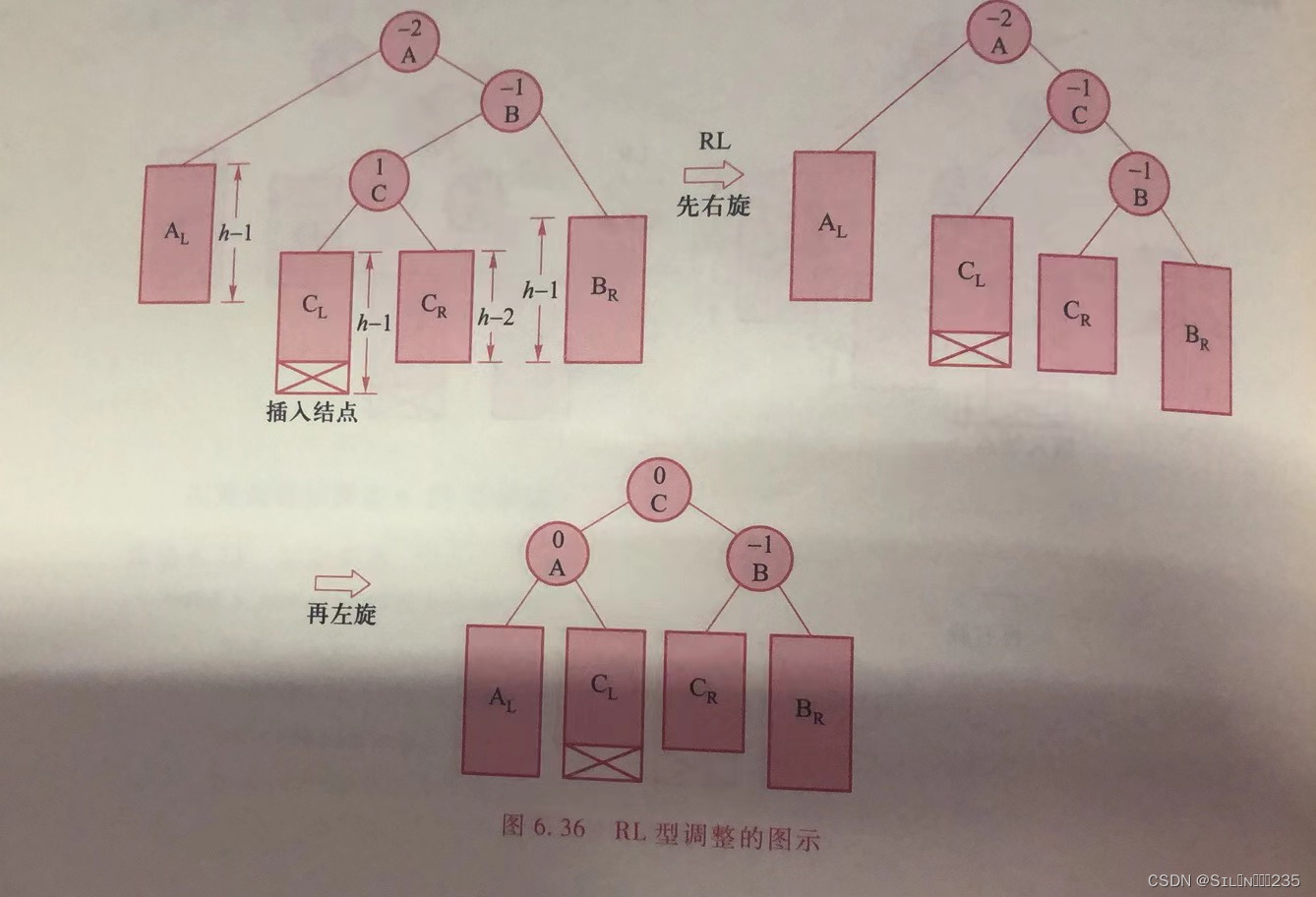
6.6.3平衡二叉树的插入
构造平衡二叉树可采用依次插入结点的方式,其递归步骤如下:
- 若是空树,则插入的结点作为根结点,树的高度增加1.
- 若待插入结点和根结点相等,则无需插入。
- 若待插入结点小于根结点,且在左子树中也不存在相等的结点,则在左子树插入,且插入后的左子树高度增加1,分情况讨论:
- 原根结点的平衡因子为-1(右子树高于左子树),更改为0,树的高度不变。
- 原根结点的平衡因子为0(左右子树高度相等),更改为1,树的高度加1.
- 原根结点的平衡因子为1(左子树高于右子树);若左子树根结点的平衡因子为1,则属于LL型,需进行右旋平衡调整,并在调整后将根结点及其右孩子的平衡因子改为0,树的高度不变;若左子树根结点的平衡因子为-1,则属于LR型,需进行左旋和右旋处理,并在调整后修改根结点及其左右孩子的平衡因子,树的高度不变。
- 若待插入结点大于根结点,且在右子树中不存在相等的结点,则在右子树插入,且当插入之后的右子树高度加1时,分情况讨论:
- 原根结点的平衡因子为1(左子树高于右子树),更改为0,树的高度不变。
- 原根结点的平衡因子为0(左右子树相等),更改为-1,树的高度加1.
- 原根结点的平衡结点为-1(右子树高于左子树);若右子树根结点的平衡因子为1,属于RL型,需要进行右旋和左旋处理,并在旋转处理之后,修改根结点及其左右子树根结点的平衡因子,树的高度不变;若右子树的根结点的平衡因子为-1,则属于RR型,需进行一次左处理,并在左旋之后,更新根结点和其左右子树根结点的平衡因子,树的高度不变。
算法:左平衡处理操作‘
#define LH +1//左子树比右子树高,简称左高
#define EH 0//左右子树相等高度,简称等高
#define RH -1//右子树高于左子树,简称右高
void LeftBalance(BBSTree &T)
{
??? //实现对数T的左平衡处理
??? BBSTree lc,rd;
??? lc=T->lchild;//lc指向T的左孩子
??? switch(lc->bf)//检查T的左子树的平衡因子,并作对应处理
??? {
?????? case LH://LL型,需要右旋调整
?????? {
?????????? T->bf=lc->bf=EH;
?????????? R_Rotat(T);
?????????? break;
?????? }
?????? case RH://新结点插入在T的左子树的右子树上属于LR型,做双旋处理
?????? {
?????????? rd=lc->rchild;
?????????? swicth(rd->bf)//修改T及其左孩子的平衡因子
?????????? {
?????????????? case LH:
?????????????? {
?????????????????? T->bf=RH;
?????????????????? lc->bf=EH;
?????????????????? break;
?????????????? }
?????????????? case EH:
?????????????? {
?????????????????? T->bf=lc->bf=EH;
?????????????????? break;
?????????????? }
?????????????? case RH:
?????????????? {
?????????????????? T->bf=EH;
?????????????????? lc->bf=LH;
?????????????????? break;
?????? ??????? }
?????????????? rd->bf=EH;
?????????????? L_Rotate(T->lchild);//对T的左子树作左旋调整
?????????????? R_Rotate(T);//对T进行右旋调整
?????????????? break;
?????????? }
?????? }
??? }
}算法:平衡二叉树的插入操作
Status InsertAVL(BBSTree &T,RcdType e,Status &taller){
??? //实现对e插入到二叉树的操作
??? if(NULL==T)//T为空树
??? {
?????? T=(BSTree)malloc(sizeof(BSTNode));//开辟空间
?????? T->bf=EH;
?????? T->lchild=NULL;
?????? T->rchild=NULL;
?????? taller=TRUE;
??? }
??? else if(e.key==T->data.key)//树的根结点的值等于插入值
??? {
?????? taller=FALSE;
?????? return FALSE;//插入失败
??? }
??? else if(e.key<T->data.key)//插入到左子树
??? {
?????? if(FALSE==INsertAVL(T->lchild,e,taller))
?????? {
?????????? return FALSE;//递归左子树检查是否能插入
?????? }
?????? if(TRUE==taller)
?????? {
?????????? switch(T->bf)//检查T的平衡因子
?????????? {
?????????????? case LH:
?????????????? {
?????????????????? LeftBalance(T);
?????????????????? taller=TRUE;
?????????????????? break;//原左高,左平衡处理
?????????????? }
?????????????? case EH:
?????????????? {
?????????????????? T->bf=LH;
?????????????????? taller=TRUE;//原等高,左边高
?????????????????? break;?
?????????????? }
?????? ??????? case RH:
?????????????? {
?????????????????? T->bf=EH;
?????????????????? taller=FALSE;
?????????????????? break;//原右高,变等高?
?????????????? }
?????????? }
?????? }
??? }
??? else//插入到右子树
??? {
?????? if(FALSE==INsertAVL(T->rchild,e,taller))
?????? {
?????????? return FALSE;//递归右子树检查是否能插入
?????? }
?????? if(TRUE==taller)
?????? {
?????????? switch(T->bf)//检查T的平衡因子
?????????? {
?????????????? case LH:
?????????????? {
?????????????????? T->bf=EH;
?????????????????? taller=TRUE;
?????????????????? break;//原左高,变等高
?????????????? }
?????????????? case EH:
?????????????? {
?????????????????? T->bf=RH;
?????????????????? taller=TRUE;//原等高,变右高
?????????????????? break;?
?????????????? }
?????????????? case RH:
?????????????? {
?????????????????? RightBalance(T);
?????????????????? taller=FALSE;
?????????????????? break;//原右高,右平衡处理?
?????????????? }
?????????? }
?????? }
??? }
??? return TRUE;
}本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!