【Pandas案例1】 根据某些相同属性列合并同类数据
发布时间:2023年12月18日
根据相同属性合并pandas行
代码
提供的代码可直接运行
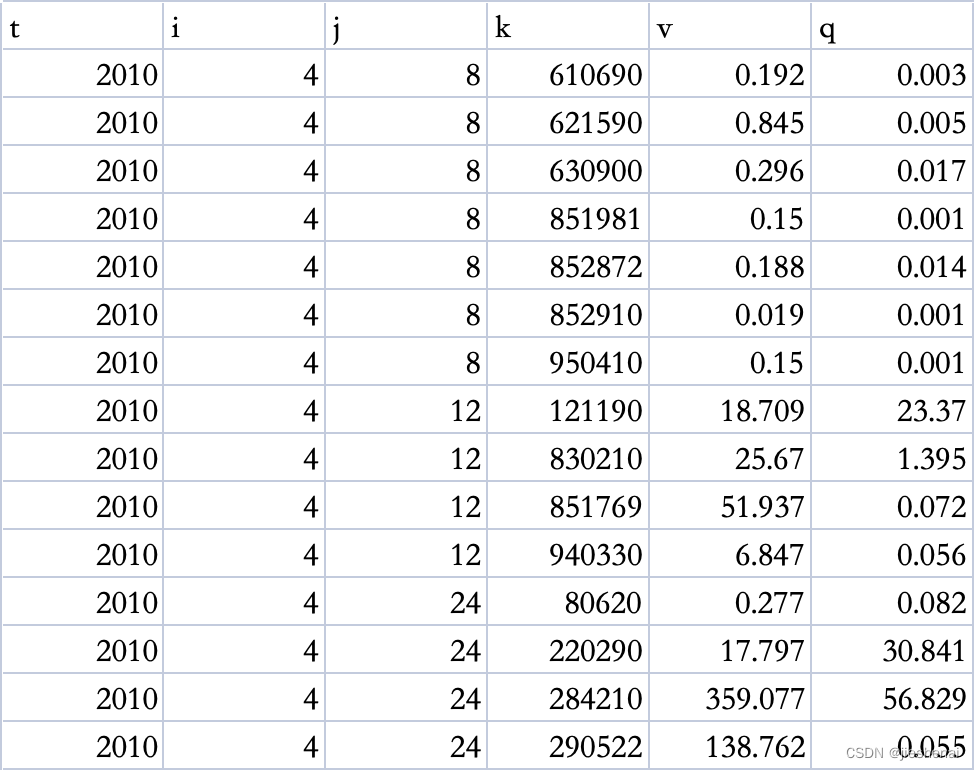
以如下表格数据为例,针对t, i, j相同的行,对其后的v属性数据实现相加。
data.csv的数据如下:
import os
import pandas as pd
from pandas import DataFrame, read_csv
filename = "文件路径/data.csv"
数据加载
若数据量大,可只加载几行数据
head = read_csv(filename, nrows=10)
init_df方法的作用:读取文件数据,创建一个新的容器存放最终的数据
根据keys = ['t', 'i', 'j'],对key相同的属性行将其attrs=['v']的属性值进行相加。
只留下keys,attrs属性列,使用data.drop删除掉其他属性列。
keys = ['t', 'i', 'j']
attrs = ['v']
def init_df(filename):
data = read_csv(filename)
delete_col = set(data.columns.values) - set(keys) - set(attrs)
data = data.drop(list(delete_col), axis=1)
# 创建一个空容器,用于存放最终新的pandas数据
d = {key: [] for key in keys + attrs}
return data, pd.DataFrame.from_dict(d)
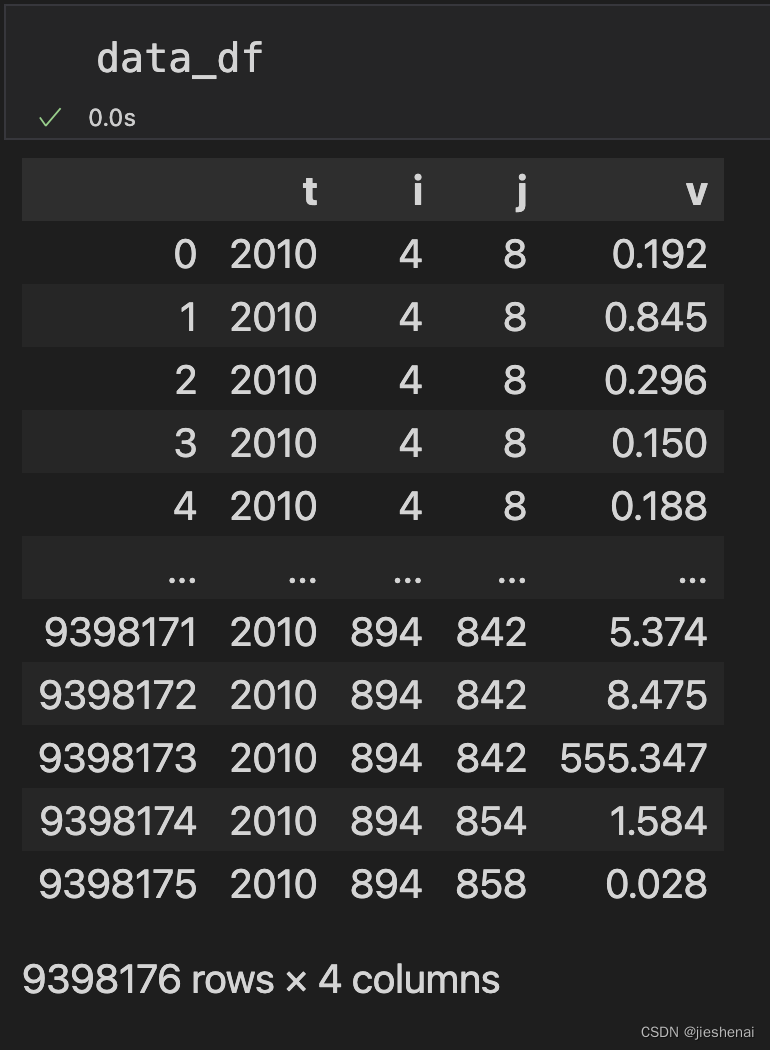
data_df: 读取的文件数据
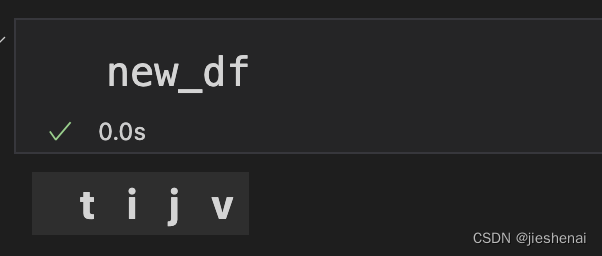
new_df: 空的 pandas.DataFrame 容器
csv的数据是按照keys = ['t', 'i', 'j']的顺序排序好的。
故遍历data_df的每一行数据,将其与new_df最后一行数据的keys进行比较,若其相等则把v对应的属性值相加。
故需要实现如下几个函数
- 判断两行数据的
keys是否相等,is_equal() - 插入一行新数据到
new_df,insert()
自定义方法
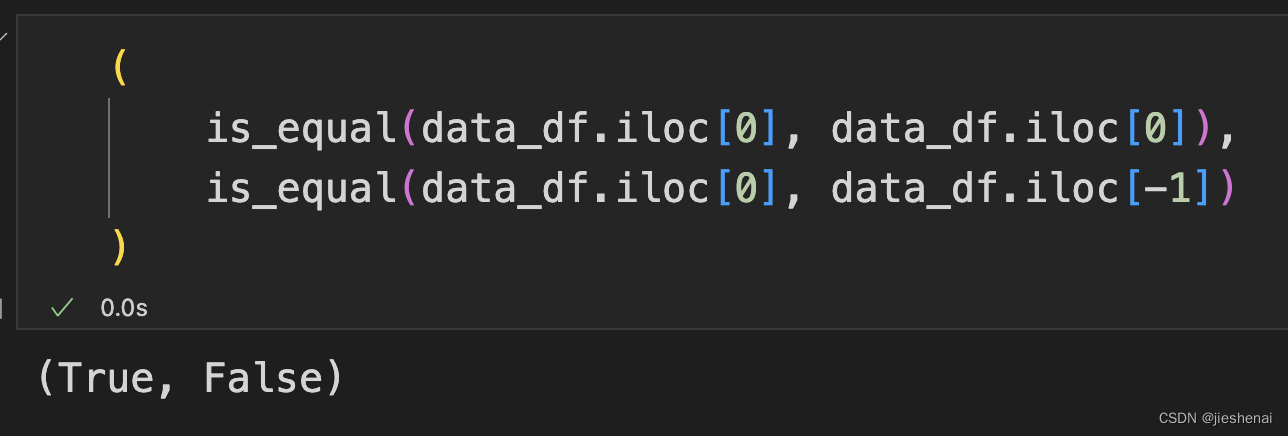
def is_equal(a: DataFrame, b: DataFrame) -> bool:
for key in keys:
if a[key] != b[key]:
return False
return True
# 属性值相加函数
def add(a: DataFrame, b: DataFrame):
assert is_equal(a, b)
for attr in attrs:
a[attr] += b[attr]
# 插入一行数据到容器最后一行
def insert(df: DataFrame, other: DataFrame):
df.loc[len(df)] = other
主函数
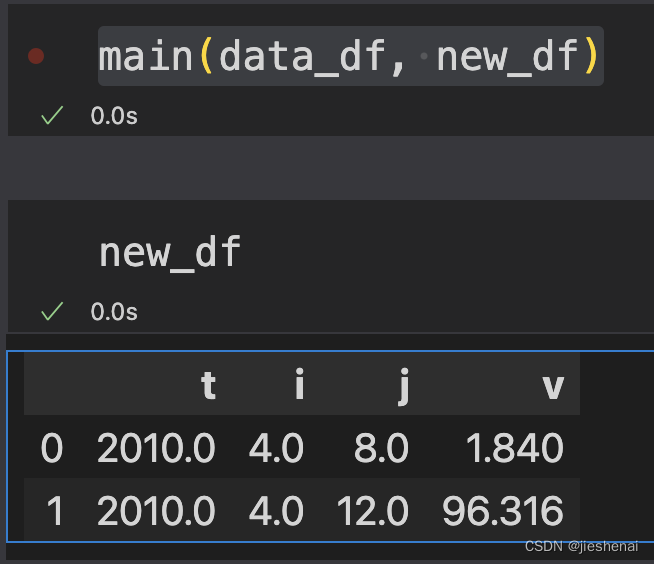
def main(df, res):
insert(res, df.iloc[0])
for idx in range(1, len(df)):
item = df.iloc[idx]
if is_equal(item, res.iloc[-1]):
add(res.iloc[-1], item)
else:
insert(res, item)
main(data_df, new_df)
点击查看此 ipynb 格式代码
完整代码如下
下图是一个完整的封装完成的py代码
处理source_folder文件夹下的所有表格数据,将其处理结果保存到output文件下。
import os
import pandas as pd
from pandas import DataFrame, read_csv
keys = ['t', 'i', 'j']
attrs = ['k']
def init_df(filename):
data = read_csv(filename)
delete_col = set(data.columns.values) - set(keys) - set(attrs)
data = data.drop(list(delete_col), axis=1)
d = {key: [] for key in keys + attrs}
return data, pd.DataFrame.from_dict(d)
def is_equal(a: DataFrame, b: DataFrame):
for key in keys:
if a[key] != b[key]:
return False
return True
def add(a: DataFrame, b: DataFrame):
assert is_equal(a, b)
for attr in attrs:
a[attr] += b[attr]
def insert(df: DataFrame, other: DataFrame):
df.loc[len(df)] = other
def main(df, res):
insert(res, df.iloc[0])
for idx in range(1, len(df)):
item = df.iloc[idx]
if is_equal(item, res.iloc[-1]):
add(res.iloc[-1], item)
else:
insert(res, item)
if __name__ == '__main__':
source_folder = '/Users/jshen/Desktop/jie/data'
output_folder = 'output'
if not os.path.exists(output_folder):
os.makedirs(output_folder)
for root, dirs, files in os.walk(source_folder):
for file in files:
filename = os.path.join(root, file)
print(filename, "处理中...")
data, res_df = init_df(filename)
main(data, res_df)
res_df.to_csv(
f := os.path.join(
output_folder,
os.path.basename(filename)),
)
print("转换完成---> ", f)
文章来源:https://blog.csdn.net/sjxgghg/article/details/134992655
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于人工智能技术的《量化投资AI系统》集群架构设计与实现
- Vue3父子组件生命周期执行顺序
- springboot/java/php/node/python蛋糕甜品在线销售系统【计算机毕设】
- 网络安全之2023 年 10 起最大的安全事件
- windows安装conda小环境 windows安装anaconda python jupyter anaconda
- NIO通信代码示例
- 电话号码信息收集工具:PhoneInfoga | 开源日报 No.137
- 01.neuvector防护平台功能实现设计
- 实现scan-to-map匹配,使用NDT的C++代码实现(2)
- 用uniapp写一个点击左侧可以滑动的menu