【CVPR2023】人像卡通化(2D图像->3D卡通)
1. 3DAvatarGAN Bridging Domains for Personalized Editable Avatars
Affiliation: KAUST (Peter Wonka), Snap Inc. (Hsin-Ying Lee, Menglei Chai, Aliaksandr Siarohin, Sergey Tulyakov)
Authors: Rameen Abdal, Hsin-Ying Lee, Peihao Zhu, Menglei Chai, Aliaksandr Siarohin, Peter Wonka, Sergey Tulyakov
Keywords: 3D-GAN, personalized avatars, artistic datasets, deformation-based modeling, inversion method
Summary:
(1) This paper addresses the domain of 3D cartoon character modeling, aiming to provide a method for generating and editing personalized 3D cartoon characters from a single 2D image.
(2) Previous methods primarily relied on known 3D models and image pairs to generate 3D characters, requiring extensive 3D models and parameter annotations, which produced low-quality cartoon characters. This paper proposes a method using existing 2D artistic datasets and 3D GAN models, which does not need camera parameter annotations and is capable of generating and editing high-quality personalized cartoon characters.
(3) The paper presents an optimization method based on adjusting camera parameter distributions and texture quality, alongside deformation modeling techniques, which allows the knowledge of 2D GAN generators to be transferred to 3D generators, hence enabling the creation and editing of 3D cartoon characters.
(4) The method has been tested on artistic datasets such as Caricatures, Pixar toons, Cartoons, Comics, etc., achieving high-quality generation results. The paper also introduces a novel 3D-GAN inversion method, achieving a latent space mapping from the target domain to the source domain.
Methods:
(1) The paper proposes a method for generating personalized 3D cartoon characters from 2D images based on a 3D GAN model, which does not require camera parameter annotations and can generate high-quality 3D cartoon characters.
(2) The method achieves this by adapting the knowledge of 2D GAN generators to 3D generators through deformation modeling techniques and an optimization method that adjusts camera parameter distributions and texture quality. A new 3D-GAN inversion method is also provided, which maps the latent space from the target domain to the source domain.
(3) Tested on artistic datasets, the method has yielded high-quality results and offers personalized editing capabilities, supporting local adjustments based on geometry and semantics while maintaining the identity of the target.
Conclusion:
(1) The paper proposes a method for generating personalized 3D cartoon characters from 2D images, as well as a domain adaptation method for 3D GANs, filling a gap in the field of cartoon character generation. The method contributes to improving the quality and efficiency of 3D cartoon character generation.
(2) Innovation: The paper introduces a new method for generating and editing 3D cartoon characters based on deformation modeling techniques without needing camera parameter annotations, and a novel 3D-GAN inversion method, tackling the challenges in cartoon character generation. Performance: The experimental results show that the method can generate high-quality personalized 3D cartoon characters and supports local adjustments while maintaining the identity of the target. Workload: The method requires optimization of factors such as camera parameter distributions and texture quality, and it has been tested on a limited number of datasets, necessitating further validation and expansion.
2. 人像卡通化 (Photo to Cartoon)实现原理

有个公式做这个的:这个项目名叫「人像卡通化 (Photo to Cartoon)」,已经在 GitHub 上开源。但对于不想动手下载各种软件、数据集、训练模型的普通用户,该公司开放了一个名为「AI 卡通秀」的小程序,可以生成各种风格的卡通照片、gif 表情包,完全可以满足社交需求。
此外还有一个开源项目:
2.1 定义
人像卡通风格渲染的目标是,在保持原图像 ID 信息和纹理细节的同时,将真实照片转换为卡通风格的非真实感图像。
2.2 图像卡通化任务面临着一些难题
卡通图像往往有清晰的边缘,平滑的色块和经过简化的纹理,与其他艺术风格有很大区别。使用传统图像处理技术生成的卡通图无法自适应地处理复杂的光照和纹理,效果较差;基于风格迁移的方法无法对细节进行准确地勾勒。
数据获取难度大。绘制风格精美且统一的卡通画耗时较多、成本较高,且转换后的卡通画和原照片的脸型及五官形状有差异,因此不构成像素级的成对数据,难以采用基于成对数据的图像翻译(Paired Image Translation)方法。
照片卡通化后容易丢失身份信息。基于非成对数据的图像翻译(Unpaired Image Translation)方法中的循环一致性损失(Cycle Loss)无法对输入输出的 id 进行有效约束。
那么如何解决这些问题呢?
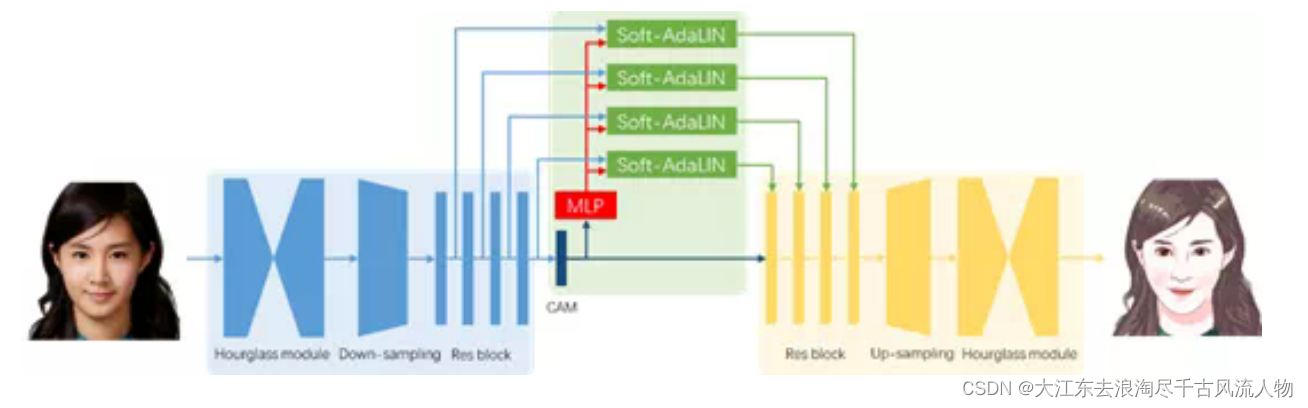
小视科技的研究团队提出了一种基于生成对抗网络的卡通化模型,只需少量非成对训练数据,就能获得漂亮的结果。卡通风格渲染网络是该解决方案的核心,它主要由特征提取、特征融合和特征重建三部分组成。
整体框架由下图所示,该框架基于近期研究 U-GAT-IT(论文《U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation》。
2.3 详细原理与测试见论文与项目
论文《U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation》
项目代码与部署
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!