工具系列:PyCaret介绍_编写和训练自定义机器学习模型
文章目录

PyCaret
PyCaret是一个开源的、低代码的机器学习库和端到端模型管理工具,使用Python构建,用于自动化机器学习工作流程。它因其易用性、简单性和快速高效地构建和部署端到端ML原型的能力而广受欢迎。
PyCaret是一个可替代数百行代码的低代码库,只需几行代码即可。这使得实验周期指数级地快速和高效。
PyCaret简单易用。在PyCaret中执行的所有操作都顺序存储在一个管道中,该管道完全自动化用于部署。无论是填充缺失值、独热编码、转换分类数据、特征工程,还是超参数调整,PyCaret都可以自动化完成。
安装PyCaret
安装PyCaret非常容易,只需几分钟即可完成。我们强烈建议使用虚拟环境,以避免与其他库可能发生的冲突。
PyCaret的默认安装是一个精简版的pycaret,只安装硬依赖项在此处列出。
# 安装slim版本(默认)
pip install pycaret
# 安装完整版本
pip install pycaret[full]
当您安装完整版的pycaret时,所有可选依赖项都会被安装,如此处所列。
👉 让我们开始吧
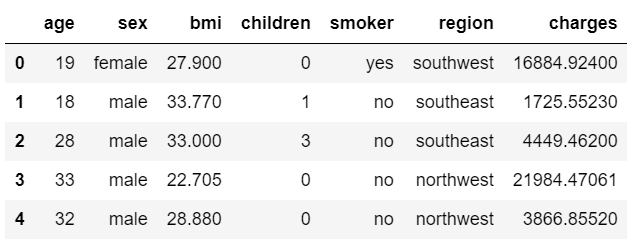
在我们开始讨论自定义模型训练之前,让我们先看一下PyCaret如何使用开箱即用的模型进行快速演示。我将使用PyCaret存储库上可用的“保险”数据集。该数据集的目标是基于某些属性预测患者的费用。
👉 数据集
# 从pycaret仓库中读取数据
from pycaret.datasets import get_data
# 使用get_data函数从pycaret仓库中获取insurance数据集
data = get_data('insurance')
👉 数据准备
在PyCaret中,对于所有模块来说,设置(setup)是在PyCaret中执行任何机器学习实验的第一个且唯一必需的步骤。这个函数负责在训练模型之前进行所有必要的数据准备工作。除了执行一些基本的默认处理任务外,PyCaret还提供了广泛的预处理功能。要了解PyCaret中的所有预处理功能,请参阅此链接。
# 导入pycaret.regression模块中的所有函数
from pycaret.regression import *
# 初始化设置
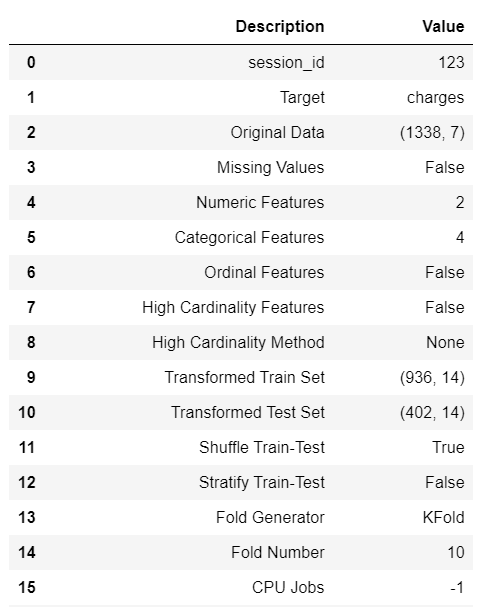
# data为数据集,target为目标变量
# s为初始化后的设置,包含了数据预处理、特征工程、模型选择等步骤
s = setup(data, target='charges')
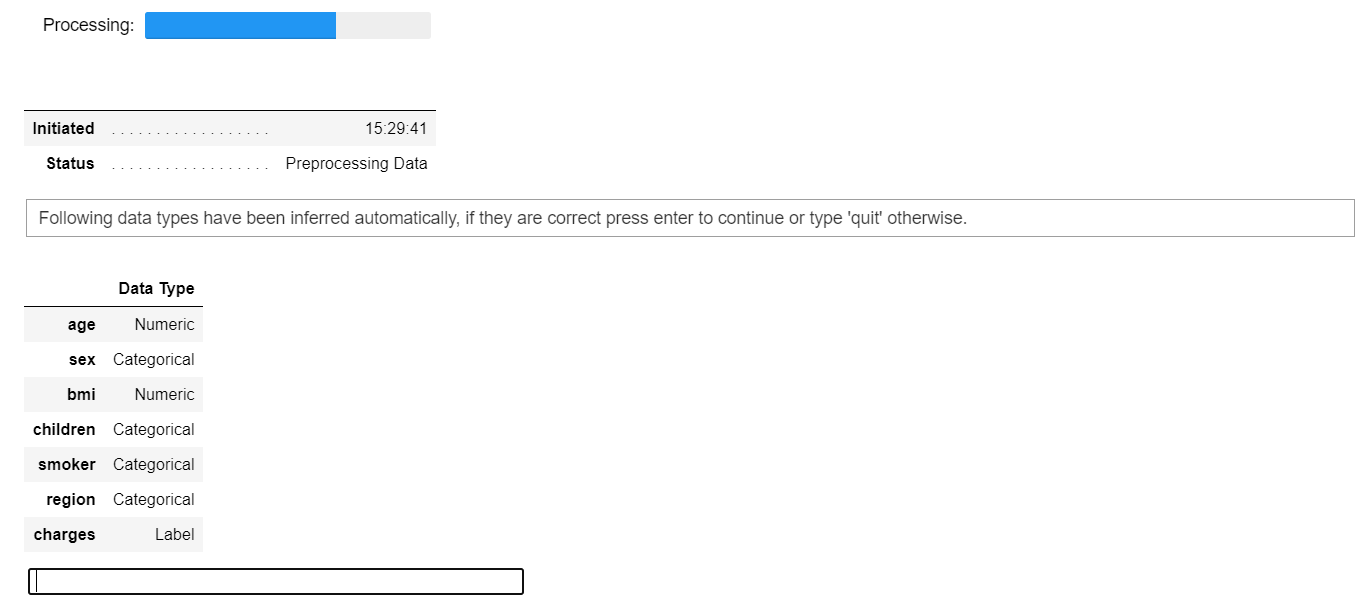
PyCaret中的设置函数
每当您在PyCaret中初始化设置函数时,它会对数据集进行分析,并推断所有输入特征的数据类型。如果所有数据类型都被正确推断,则可以按Enter键继续。
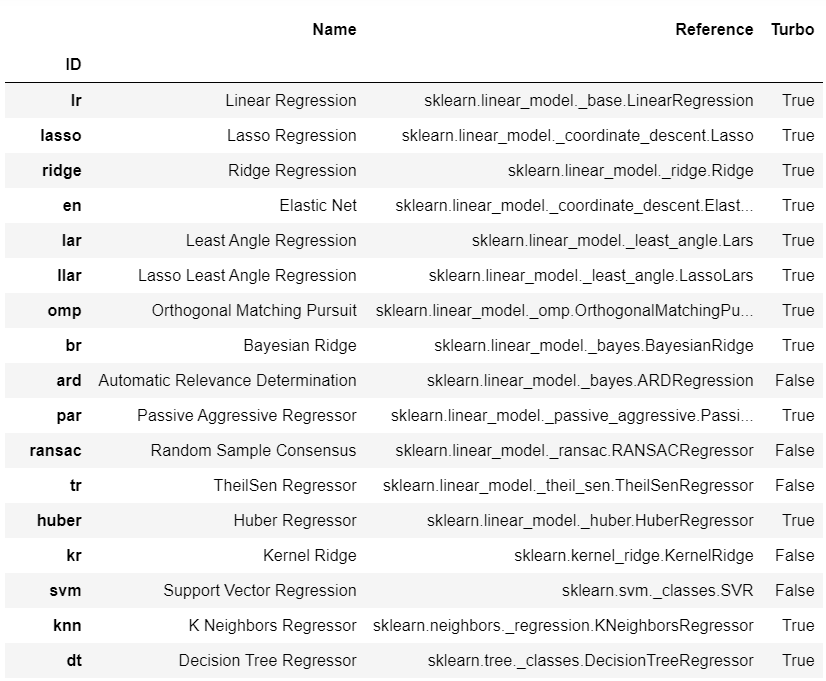
👉 可用模型
要查看所有可用于训练的模型列表,您可以使用名为 models 的函数。它会显示一个包含模型ID、名称和实际估计器引用的表格。
# 导入必要的库
import torch
from transformers import AutoModel, AutoTokenizer
# 定义一个函数,用于打印所有可用的模型
def models():
# 获取所有可用的预训练模型的名称
model_names = AutoModel.from_pretrained.__self__.CONFIG_PRETRAINED_MODEL_ARCHIVE_LIST
# 打印所有可用的模型名称
for name in model_names:
print(name)
# 调用函数,打印所有可用的模型
models()
👉 模型训练与选择
在PyCaret中,用于训练任何模型的最常用函数是create_model。它接受一个你想要训练的估计器的ID。
# 创建决策树模型
dt = create_model('dt')
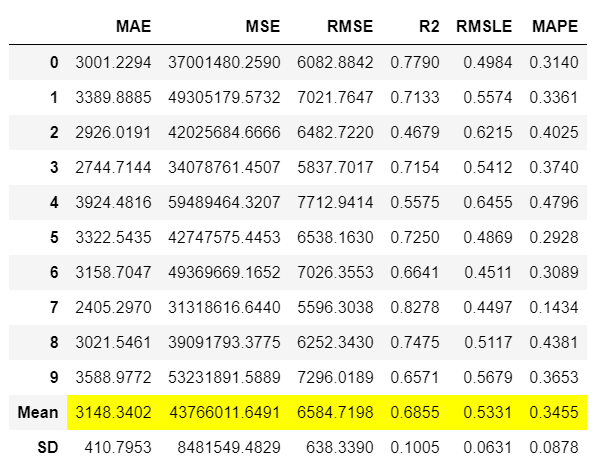
输出显示了10折交叉验证的指标,包括均值和标准差。这个函数的输出是一个训练好的模型对象,本质上是一个scikit-learn对象。
# 打印当前日期和时间
print(dt)

要在循环中训练多个模型,您可以编写一个简单的列表推导式:
# 创建多个模型
# 创建一个包含多个模型的列表,模型类型分别为'dt'、'lr'和'xgboost'
multiple_models = [create_model(i) for i in ['dt', 'lr', 'xgboost']]
# 检查 multiple_models 的类型和长度
type(multiple_models), len(multiple_models)
>>> (list, 3)
# 打印 multiple_models
print(multiple_models)

如果你想训练库中所有可用的模型而不是只选择几个,你可以使用PyCaret的compare_models函数,而不是编写自己的循环(尽管结果将是相同的)。
# compare_models()函数是一个用于比较所有模型的函数,它会返回最佳模型。
best_model = compare_models() # 调用compare_models()函数,并将返回的最佳模型赋值给best_model变量。
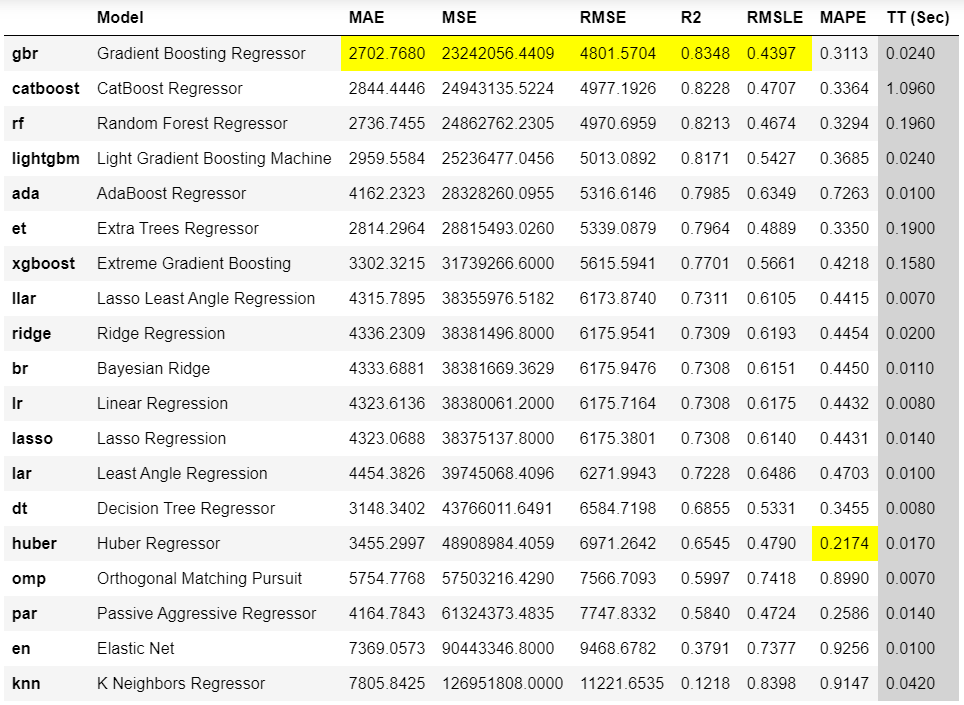
compare_models 函数返回的输出显示了所有模型的交叉验证指标。根据这个输出,Gradient Boosting Regressor 是最佳模型,使用 10 折交叉验证在训练集上的平均绝对误差(MAE)为 2,702。
# 打印最佳模型
print(best_model)

上面网格中显示的指标是交叉验证分数,用于检查最佳模型在留出集上的分数:
# 预测保留集上的结果
pred_holdout = predict_model(best_model)

为了在未见过的数据集上生成预测,您可以使用相同的predict_model函数,只需传递一个额外的参数data:
# 创建数据的副本并删除目标列
data2 = data.copy() # 创建data的副本,命名为data2
data2.drop('charges', axis=1, inplace=True) # 在data2中删除'charges'列,axis=1表示按列删除
# 生成预测
predictions = predict_model(best_model, data=data2) # 使用best_model对data2进行预测,将结果保存在predictions中
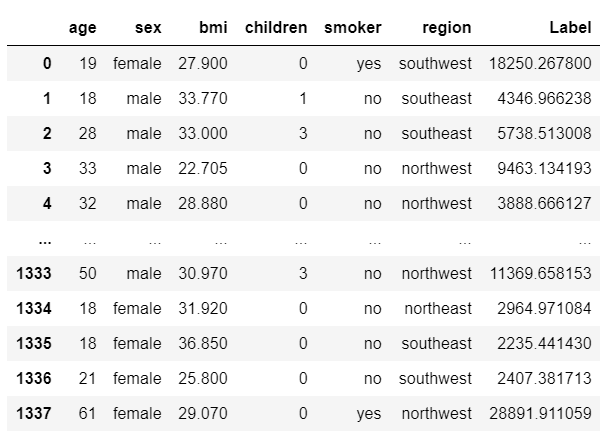
👉 编写和训练自定义模型
到目前为止,我们已经看到了如何对PyCaret中所有可用的模型进行训练和模型选择。然而,PyCaret对于自定义模型的工作方式完全相同。只要你的估计器与sklearn API风格兼容,它就会以相同的方式工作。让我们看几个例子。
在我展示如何编写自己的自定义类之前,我将首先演示如何使用自定义的非sklearn模型(即不在sklearn或pycaret的基本库中的模型)。
👉 GPLearn模型
虽然遗传编程(GP)可以用于执行非常广泛的任务,但gplearn被有意地限制为解决符号回归问题。
符号回归是一种机器学习技术,旨在识别最能描述关系的基础数学表达式。它首先通过构建一组天真的随机公式来表示已知独立变量和它们的依赖变量目标之间的关系,以预测新数据。然后,每一代程序都是从前一代中选择适应度最高的个体经过遗传操作进化而来的。
要使用gplearn中的模型,您首先需要安装它:
# 导入所需的库
import numpy as np
from gplearn.genetic import SymbolicRegressor
# 创建一个简单的数据集
X_train = np.arange(0, 10, 0.1).reshape(-1, 1)
y_train = np.sin(X_train).ravel()
# 创建一个符号回归器对象
est_gp = SymbolicRegressor(population_size=500, generations=20, stopping_criteria=0.01,
p_crossover=0.7, p_subtree_mutation=0.1, p_hoist_mutation=0.05,
p_point_mutation=0.1, max_samples=0.9, verbose=1,
parsimony_coefficient=0.01, random_state=0)
# 使用训练数据拟合符号回归器
est_gp.fit(X_train, y_train)
# 打印符号回归器的最佳表达式
print(est_gp._program)
现在你可以简单地导入未训练的模型并将其传递给create_model函数:
# 入未经训练的估计器
from gplearn.genetic import SymbolicRegressor
# 创建一个SymbolicRegressor对象,作为未经训练的估计器
sc = SymbolicRegressor()
# 使用create_model函数对sc进行训练
sc_trained = create_model(sc)
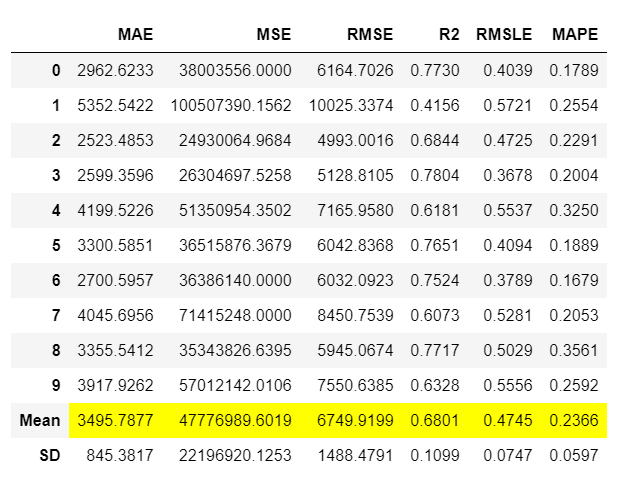
## 打印已经训练好的sc_trained变量的值

您还可以检查此模型的保留分数:
## 检查留存数据的得分
pred_holdout_sc = predict_model(sc_trained)

👉 NGBoost 模型
ngboost 是一个实现了自然梯度提升的 Python 库,如 “NGBoost: Natural Gradient Boosting for Probabilistic Prediction” 中所述。它构建在 Scikit-Learn 之上,旨在在选择适当的评分规则、分布和基学习器方面具有可扩展性和模块化性。关于 NGBoost 方法学的教学介绍可在此 幻灯片 中找到。
要使用 ngboost 中的模型,您首先需要安装 ngboost:
# 导入所需的库
import numpy as np
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from ngboost import NGBRegressor
from ngboost.distns import Normal
# 生成回归数据集
X, y = make_regression(n_samples=100, n_features=1, noise=0.1, random_state=0)
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 创建NGBRegressor模型
ngb = NGBRegressor(Dist=Normal)
# 训练模型
ngb.fit(X_train, y_train)
# 使用训练好的模型进行预测
y_pred = ngb.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
# 打印均方误差
print("均方误差:", mse)
代码解释:
- 导入所需的库:导入numpy库用于数值计算,导入make_regression函数用于生成回归数据集,导入train_test_split函数用于划分数据集,导入mean_squared_error函数用于计算均方误差,导入NGBRegressor类和Normal类用于创建和训练NGBRegressor模型。
- 生成回归数据集:使用make_regression函数生成包含100个样本和1个特征的回归数据集,噪声为0.1,随机种子为0。
- 将数据集划分为训练集和测试集:使用train_test_split函数将生成的数据集划分为训练集和测试集,测试集占总样本的20%,随机种子为0。
- 创建NGBRegressor模型:使用NGBRegressor类创建一个NGBRegressor模型,指定分布类型为Normal。
- 训练模型:使用fit方法训练NGBRegressor模型,传入训练集的特征和标签。
- 使用训练好的模型进行预测:使用predict方法对测试集的特征进行预测,得到预测结果。
- 计算均方误差:使用mean_squared_error函数计算预测结果与测试集标签之间的均方误差。
- 打印均方误差:将计算得到的均方误差打印出来。
一旦安装完成,您可以从ngboost库中导入未经训练的估计器,并使用create_model来训练和评估模型:
# 导入未经训练的估计器
from ngboost import NGBRegressor
ng = NGBRegressor()
# 使用create_model进行训练
ng_trained = create_model(ng)
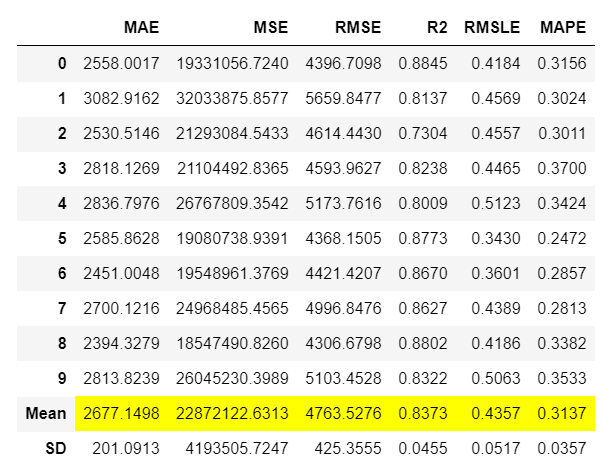
# 打印ng_trained
print(ng_trained)
👉 编写自定义类
上述的两个例子gplearn和ngboost是pycaret的自定义模型,因为它们在默认库中不可用,但您可以像使用其他开箱即用的模型一样使用它们。然而,可能会有一种情况需要编写自己的算法(即算法背后的数学),在这种情况下,您可以继承sklearn的基类并编写自己的数学。
让我们创建一个天真的估计器,在拟合阶段学习目标变量的平均值,并对所有新数据点预测相同的平均值,而不考虑X输入(在现实生活中可能没有用,但只是为了演示功能)。
# 创建自定义的估计器
import numpy as np
from sklearn.base import BaseEstimator
class MyOwnModel(BaseEstimator):
def __init__(self):
self.mean = 0 # 初始化均值为0
def fit(self, X, y):
self.mean = y.mean() # 计算目标变量y的均值
return self
def predict(self, X):
return np.array(X.shape[0]*[self.mean]) # 返回一个长度为X的样本数量的数组,每个元素都是均值
现在让我们使用这个估计器进行训练:
# 创建一个名为mom的MyOwnModel类的实例对象
mom = MyOwnModel()
# 使用create_model函数对mom进行训练,并将训练后的模型保存在mom_trained中
mom_trained = create_model(mom)
# 生成数据的预测结果
# 使用训练好的mom_trained模型对数据进行预测
# predict_model函数用于生成数据的预测结果,接受两个参数:模型mom_trained和数据data
predictions = predict_model(mom_trained, data=data)
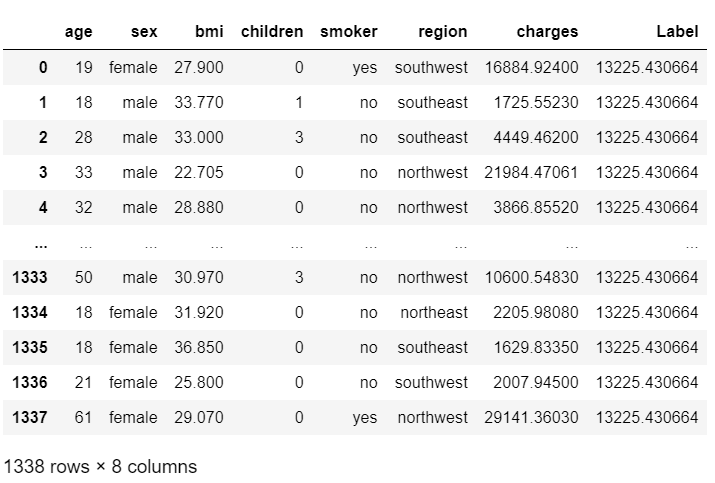
请注意,标签列(即预测结果)对于所有行来说都是相同的数字$13,225,这是因为我们以这样的方式创建了这个算法,它从训练集的均值中学习并预测相同的值(只是为了保持简单)。
我希望您能欣赏PyCaret的易用性和简单性。只需几行代码,您就可以进行端到端的机器学习实验,并编写自己的算法,而无需调整任何原生代码。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 63.接口安全设计(活动管理系统:三)
- 算法练习Day20 (Leetcode/Python-回溯算法)
- 计算图与动态图机制
- 低代码开发平台支持复杂的业务逻辑和API对接吗
- vue2 KeepAlive实操
- LED流水灯
- 哪种SSL证书申请签发最快?
- 如何配置Zabbix告警邮件通知并基于GPT提供解决方案?
- 150个矩阵账号,小魔推助力美业商家带来4.1w订单
- 【RTOS】快速体验FreeRTOS所有常用API(11)打印空闲栈、CPU占用比