NLP论文阅读记录 - wos | 01 使用深度学习对资源匮乏的语言进行抽象文本摘要
文章目录
前言

Abstractive text summarization of lowresourced languages using deep learning(2211)
0、论文摘要
人类必须能够应对信息技术革命产生的大量信息。因此,自动文本摘要被广泛应用于各个行业,以帮助个人识别最重要的信息。对于文本摘要,主要考虑两种方法:提取方法和抽象方法的文本摘要。提取摘要方法选择像源文档这样的句子块,而抽象方法可以根据挖掘的关键字生成摘要。对于资源匮乏的语言,例如乌尔都语,提取摘要使用各种模型和算法。然而,乌尔都语抽象概括的研究仍然是一项具有挑战性的任务。由于乌尔都语文学作品如此之多,生成抽象摘要需要进行广泛的研究。
方法。
本文利用乌尔都语百万条新闻数据集提出了乌尔都语深度学习模型,并将其性能与支持向量机(SVM)和逻辑回归(LR)等两种广泛使用的基于机器学习的方法进行了比较。结果表明,建议的深度学习模型比其他两种方法表现更好。使用编码器-解码器范式处理提取摘要生成的摘要以创建抽象摘要。
一、Introduction
1.1目标问题
在自然语言处理(NLP)中,文本摘要是一项艰巨的工作。它的目的是通过创建更小的版本而不失去意义,从许多论文中进行更易于管理的阅读和搜索信息。由于互联网在过去二十年的快速扩张,数据可用性新闻、文章和书评都可以在互联网上找到(Burney, Sami & Mahmood, 2012),并将迅速增加。文本数据显着增加,并且由于巨大的数据量。用户使用搜索查询在互联网上查找信息。即便如此,用户仍然必须访问大量网页,这不仅需要时间,而且要找到他们需要的信息也很头疼。因此,为了避免这个令人头疼的问题,处理如此大量的数据,并以最短的方式从整篇文章中获取信息(Kumar & Rani,2021),引入了一种方法,称为文本摘要。根据生成摘要的类型,文本摘要可以分为两类:抽象文本摘要和提取文本摘要。为了逐字摘录源文本的主要部分,提取摘要主要依赖于统计或语言因素(Suleiman & Awajan,2020)。而抽象摘要则重述了获得的文本,以产生源文本中未确定包含的单词,而不是复制源文本的某些部分(Liang、Du & Li,2020)。使用自然语言处理和先进的机器学习算法生成摘要使得抽象文本摘要比提取文本摘要更加困难。必须对材料进行解释和语义评估,以提供抽象摘要(Azmi & Altmami,2018)。
某些系统还采用卷积神经网络来检查语义特征(Wang 等人,2020)。然而,由于抽象生成的摘要与人类生成的摘要非常相似,因此抽象摘要优于提取摘要。因此,总结更具洞察力(Sunitha、Jaya 和 Ganesh,2016)。无论采用哪种总结方法,两种类型的总结都要求它们具有一定的特征。以下是这些领域的主要特征:即使材料很长,生成的摘要与原文的句子结构和含义也必须一致(Muhammad et al., 2018)。可以使用序列到序列范例中发现的两级编码器和解码器来产生压缩文本摘要。此外,生成的摘要应传达原文的整体含义。在保持相同含义的同时,摘要的长度必须比原文短(Burney, Sami & Mahmood, 2012;Liang, Du & Li, 2020)。最后,减少创建的摘要中的重复量也很重要。
根据研究,该模型基于深度神经网络。这可以提取与主题相关联的关键词,然后将其用作输入。最近,深度学习在 NLP 应用中取得了现代突破。由于特征空间稀疏且维度高,因此采用支持向量机和逻辑回归等机器学习算法来狭隘地处理 NLP 复杂问题(Young et al., 2018)。由于其有希望的结果,深度学习方法最近在抽象文本摘要中被广泛抛弃。
1.2相关的尝试
1.3本文贡献
本研究中提出的方法主要基于 seq2seq 递归神经网络 (RNN) 架构。 Seq2seq 映射用于 NLP 投标,例如文本摘要和机器转换,以绘制神经网络中字体、单词(Fischer,2004)和表达式的两种排列。为了执行此实验,需要考虑由超过 100 万条新闻报道及其摘要组成的数据集。它是可用于以乌尔都语语言执行 NLP 实验的最大数据集。文本是文本摘要中的初始序列,摘要是第二序列。深度学习技术用于解决高维数和字符的稀疏性。另一方面,RNN 由一系列隐藏状态组成,每个隐藏状态的输出都会馈送到下一阶段(Widyassari 等人,2022 年)。 RNN 的顺序方面使得顺序分析数据变得更加容易,例如根据前面或后面的单词来识别句子中术语的含义。所有先前秘密状态的生产力都累积在 RNN 的最后一个隐藏状态中,以形成上下文向量(Bhaduri,1990)。手稿中每个表达式的矢量描述与编码器每个隐藏阶段之前的隐藏状态的生产力混合在一起。 “SOS”符号的单词植入就是单词植入,生成的摘要的第一个单词就是输出。框架向量是解码器中初始未知状态的输入。最近使用了许多词嵌入模型,例如 word2Vec 和 GloVe。提取摘要模型不理解句子含义(Dwi Sanyoto,2017)。摘要是通过连接关键字、短语和句子创建的。
我们提出的抽象文本摘要方法分为三个阶段:在第一阶段,收集数据集并完成预处理。第二阶段,进行文本抽取摘要;第三阶段,进行抽象文本摘要。对于抽象概括,考虑编码器-解码器模型。编码器的三层和解码器的单层构成了建议的模型。编码器-解码器利用长短期记忆(LSTM)。以下是编码器层词嵌入的输入:初始层的输入文本、下一层输入文本的关键字以及最终层输入文本的名称实体。另一方面,使用词嵌入生成的词向量用作解码器层的输入。摘要是由解码器使用全局注意力方法创建的。
其余文章的结构如下。相关工作在“相关工作”部分中进行了描述。在“问题陈述和动机”部分,提供了问题陈述和动机。下一节将讨论研究贡献。 “建议模型”部分介绍了建议模型。接下来描述实验的评估和结果。 “结论”部分给出了结论。
总之,我们的贡献如下:
2015年,首次提出使用深度学习方法来抽象英语文本摘要(Dwi Sanyoto,2017)。然而,据我们所知,抽象的乌尔都语文本摘要仍然没有采用深度学习。这项研究的总体目标是 ? 生成有意义且简洁的摘要,其中包括乌尔都语语言的新单词和句子。通过抽象的文本摘要增强了源文档的可读性和整体含义的掌握。 ? 提高生成的波斯语摘要的正确性和可读性。这项工作的重点是利用抽象文本摘要模型。它考虑源数据或其他文档以生成摘要。生成两个摘要。第一个摘要由语言学家生成,而模型生成另一个摘要。将模型生成的摘要与语言学家生成的摘要进行比较。生成的摘要可以是多个文档或单个文档。
二.相关工作
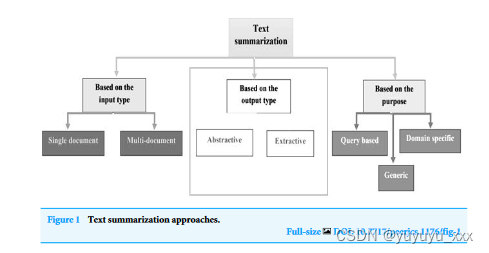
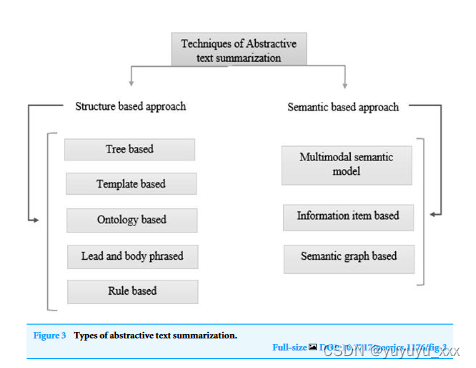
近年来,乌尔都语语言学取得了重大进展。众多门户网站和新闻网站日复一日地产生大量数据。在不知道短语含义的情况下,提取摘要方法会构建摘要(Dwi Sanyoto,2017)。因此,抽象摘要比提取摘要更精确(Kiyani & Tas,2017)。然而,由于统计方法比语言学程序更快,因此提取的摘要生成得更快。专利标签的抽象和提取方法已经过研究(Moratanch & Chitrakala,2016)。总体而言,由于各种原因,比较抽象方法与提取方法(Dalal & Malik,2013)很困难。文本摘要的方法如图 1 所示。根据输出分为抽取式文本摘要和抽象式文本摘要。类型。提取摘要类型概述如图2所示,摘要摘要类型概述如图3所示。
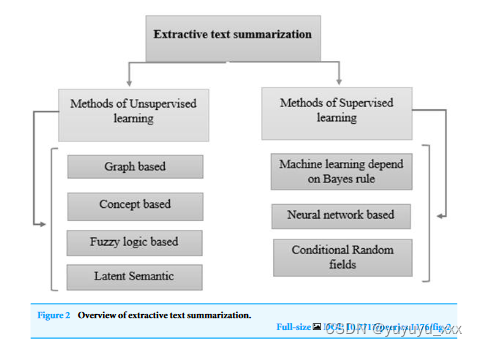
无监督学习:这些方法不需要人工摘要(用户输入)来确定内容的关键方面。
基于图的方法:由于图可以有效地反映文档结构(Iyer,Chanussot&Bertozzi,2018),因此这些模型经常用于文档摘要。
基于概念的方法:这种方法使用 HowNet 和 Wikipedia 等外部知识库从文本中提取理论(Hashemi、Tyler & Antonelli,2014)。
基于模糊逻辑的方法:句子长度、句子相似性(Ropero et al., 2012)和其他文本属性是模糊逻辑技术的输入,随后提供给模糊系统。
潜在语义分析:称为潜在语义分析 (LSA) 的技术(Ozsoy、Alpaslan 和 Cicekli,2011)允许文本摘要任务提取句子和短语的潜在语义结构。
监督学习:在句子级别,与监督提取摘要相关的技术基于分类策略(维基百科,2022)。该模型通过使用示例来区分非摘要短语和摘要短语进行教学。机器学习依赖于贝叶斯规则:机器学习方法将文本摘要视为分类问题(Brownlee,2019)。根据每个属性,句子仅限于非摘要或摘要。基于神经网络:它考虑采用双层和反向传播方法的 RankNet 训练神经网络(Kamper 等人,2015)。为了对文档中的句子进行评分,神经网络系统必须首先进行特征提取关于测试和训练集中的句子。这是在第一阶段完成的,该阶段使用机器学习方法来标记训练数据。条件随机场:一种称为条件随机场的统计建模策略(Macherla,2020)专注于使用机器学习来产生结构化预测。
基于结构的方法:它利用深度学习算法从原始文档中选择关键段落(Garg & Saini,2019)。
基于树方法的摘要:(Kikuchi et al., 2014)使用依存树来描述文本和源文本中的信息。
基于模板方法的摘要:这是一种让最终用户可以自由地为应该摘要的信息设计模板的方法(Oya et al., 2014)。该模板包括副词、动词和名词等词性标记,最终用户可以定义句子在摘要中出现的方法。
基于本体的方法:开发本体的方法(Jishma Mohan et al., 2016)使用数据预处理、语义信息提取和本体开发。
引导和主体短语方法:它取决于“插入和替换”过程,该过程使用核心句子来替换每个步骤开始时的引导短语和类似的句法核心块(Sciforce,2019)。
基于规则的方法:使用这种方法(Vodolazova & Lloret,2019),文本材料通过显示为细节的集合来浓缩。
基于语义的方法:(Shahzad 等人,2022)在基于语义的方法中,与表型相关的想法取自领域知识库的类层次结构,语义相似性度量确定其重要性。
多模态语义模型:在这种方法中(Chen & Zhuge,2018),一个或多个文档的主题(图像和手稿数据)由提取主题内容和主题之间的相关性的语义单元表示。
基于信息项:以原文的句子为起点,利用原文的摘要表示来构造摘要数据。
基于语义图:丰富语义图(RSG)在源内容上构建语义图,压缩语义网络,然后从压缩语义图提供详尽的抽象摘要。
三.本文方法
四 实验效果
4.1数据集
4.2 对比模型
4.3实施细节
4.4评估指标
4.5 实验结果
4.6 细粒度分析
五 总结
思考
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- github上的python图片转excel,pytesseract安装相关问题
- Ubuntu 安装MySQL以及基本使用
- 1214:八皇后 深度优先搜索算法
- 最全 chrome driver
- 搬运5款帮你优化电脑的小工具软件
- 打工人副业变现秘籍,某多/某手变现底层引擎-Stable Diffusion替换背景
- ubuntu22.04 安装vscode
- 3.vue学习(14-x)
- Linux学习(12)——进程管理和计划任务
- Python 进阶(十六):二进制和ASCII码的转换(binascii 模块)