txt文档里筛选出重复数据,并保存到新的txt文档
发布时间:2024年01月08日
txt文档里筛选出重复数据,并保存到新的txt文档
input_file = r'D:\pythonXangmu\quchong\input_file.txt' #原始文档
#output_file = 'output.txt'#重复内容记录文档
output_file = r'D:\pythonXangmu\quchong\output.txt'#绝对路径,解决报错找不到文件或文件夹
with open(input_file, 'r', encoding='utf-8') as file:
content = file.readlines()
print('content',content)
unique_lines = set()#存储唯一的行数据,是列表
duplicate_lines = []#存储重复的行,是列表
#筛选出每行重复数据
for line in content:
if line in unique_lines:
duplicate_lines.append(line)
else:
unique_lines.add(line)
with open(output_file, 'w', encoding='utf-8') as file:
for line in duplicate_lines:
file.write(line)
for line2 in duplicate_lines:
line2 =line2
print('line2',line2)
print('unique_lines',unique_lines)
print('duplicate_lines',duplicate_lines)
打印:
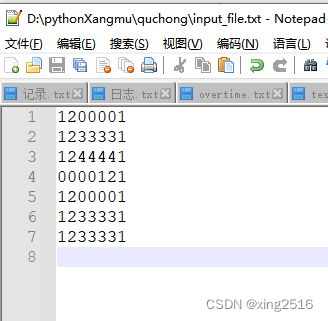
content [‘1200001\n’, ‘1233331\n’, ‘1244441\n’, ‘0000121\n’, ‘1200001\n’, ‘1233331\n’, ‘1233331\n’]
line2 1200001
line2 1233331
line2 1233331
unique_lines {‘1233331\n’, ‘1244441\n’, ‘0000121\n’, ‘1200001\n’}
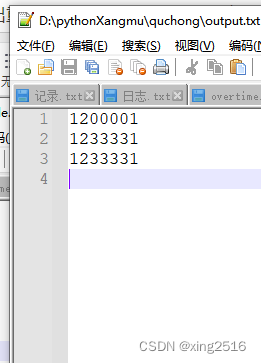
duplicate_lines [‘1200001\n’, ‘1233331\n’, ‘1233331\n’]
input_file.txt
output.txt
文章来源:https://blog.csdn.net/xing2516/article/details/135464073
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- thinkphp6.0升级到8.0
- TA百人计划学习笔记 1.2.3.1 P矩阵补充
- Vue-Cli 5.0.0搭建Cesium环境
- MSPM0L1306例程学习-ADC部分(3)
- R语言【cli】——ansi_strwrap():将ANSI样式的字符串包装为一定的宽度
- 【开题报告】基于uniapp的IT资讯阅读小程序的设计与实现
- 晶振线路匹配需要进哪一些测试
- 配置ntp时间服务器和ssh免密登录实验
- Google Scholar引用没有GB/T格式
- khbc靶场小记(upload 666靶场)