【数据结构和算法】---二叉树(2)--堆的实现和应用
一、堆的概念及结构
如果有一个数字集合,并把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,且在逻辑结构(即二叉树)中,如果每个父亲节点都大于它的孩子节点那么此堆可以称为大堆;那么如果每个父亲节点都小于它的孩子节点那么此堆可以称为小堆。
堆的性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值;
- 堆总是一棵完全二叉树。
关于大/小堆的逻辑结构和存储结构如下:

由上图我们也可以观察出,虽然在大堆的逻辑结构中,每个父亲节点都要大于它的孩子节点,但在大堆的存储结构中并不是以完全的从大到小的顺序存储的,小堆亦然。
二、堆结构的实现
上面讲述了堆的存储结构结构为数组,那么我们可以像建顺序表那样来建堆,用int capacity来表示堆可存储的数据个数,int size表示当前已存储的数据个数·,HPDataType* a表示存储堆数据的数组。
typedef int HPDataType;
typedef struct Heap
{
HPDataType* a;
int capacity;//数组容量
int size;//当前数据个数
}HP;
虽然堆的本质上是一个数组,但我们实现插入和删除操作时,是将其当作一个二叉树来调整的。对于如何标识逻辑结构下的堆的每个节点,因为已知根节点是数组中下标为0的元素,那么用各个节点所对应数组中元素的下标来标识节点(即将完全二叉树结构自第一层次向下依次遍历每一层次节点并计数)。基于此,用parent表示父亲节点,child表示其孩子节点,可以得到如下表达式parent = (child - 1) / 2;、child1(左) = parent * 2 + 1;、child2(右) = parent * 2 + 2。
下面各个函数是以建小堆为目的实现的。
2.1堆向下调整算法
能运用向下调整算法AdjustDown()的前提是,除根节点以外其余都以满足小堆的条件(即父亲节点小于各个孩子节点)。此函数需要三个参数:a表示需要调整的数组(堆),parent表示需要调整的那个节点的下标,size表示数组长度。
首先我们要找到此父亲节点的孩子节点,并假设左孩子小于右孩子(child = parent * 2 + 1)。然后比较左右孩子节点大小,取较小的那个作为新的孩子,还需要注意的是我们要新增判断(child + 1 < size)防止没有右孩子导致越界访问,最后比较父亲和孩子节点的大小,并更新父亲和孩子,直至child超出size范围(即再无孩子节点)。
逻辑大致如下:

//向下调整算法
void AdjustDown(HPDataType* a, int size, int parent)
{
//假设判断
int child = parent * 2 + 1;
//调整
if (child + 1 < size && a[child] > a[child + 1])
{
++child;
}
//交换
while (child < size)
{
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
2.2堆向上调整算法
同理,能运用向上调整算法AdjustUp()的前提是,除要插入节点的位置(即下标为size)以外其余都以满足小堆的条件(即父亲节点小于各个孩子节点)。与向下调整算法不同的是,AdustUp()只需要两个参数,一个为a表示需要调整的数组(堆),另一个为child表示所需调整节点的下标(即数组最后一个元素)。
与向下调整算法不同的是,向上调整不需要比较两个孩子的大小,因为其余节点已满足父亲节点大于孩子节点。于是乎,首先我们要找到父亲节点parent = (child - 1) / 2,然后比较父亲和孩子大小,若a[child] < a[parent]就交换,直到child值小于0或父亲节点大于孩子节点结束。
逻辑大致如下:

//堆向上调整
void AdjustUp(HPDataType* a, int child)
{
int parent = (child - 1) / 2;
//交换
while (child > 0)
{
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
2.3删除堆顶元素
在堆结构中进行删除操作,一般会选择删除堆顶元素,但首先还要确保堆中有节点(断言assert(php->size > 0);),然后可以将最后一个元素(即下标为size - 1),移动到堆顶,并将size--,再进行向下调整算法。
逻辑大致如下:

//删除堆顶--根节点
void HeapPop(HP* php)
{
assert(php);
assert(php->size > 0);
//首尾互换
Swap(&php->a[0], &php->a[php->size - 1]);
php->size--;
//向下调整
AdjustDown(php->a, php->size , 0);
}
2.4插入元素
在堆结构中进行插入操作,一般会选择堆尾。因为堆的底层是用数组实现的,且是需要动态开辟的。那么在每次插入元素之前都要先判断一下数组容量capacity,若size == capacity就需要扩容。最后只需要在完成插入操作后,对最后一个元素进行向上调整即可。
逻辑大致如下:

//插入元素
void HeapPush(HP* php, HPDataType x)
{
assert(php);
//判断容量
if (php->size == php->capacity)
{
size_t newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;
HPDataType* tmp = (HPDataType*)realloc(php->a, sizeof(HPDataType) * newcapacity);
if (tmp == NULL)
{
perror("HeapPush()::realloc");
return;
}
php->a = tmp;
php->capacity = newcapacity;
}
//插入
php->a[php->size] = x;
php->size++;
//堆向上调整
AdjustUp(php->a, php->size - 1);
}
2.5其他函数接口
- 判断堆是否为空:
php->size就代表堆中的有效的元素个数,那么当php->size == 0为真时就代表堆为空。
//为空判断
bool HeapEmpty(HP* php)
{
assert(php);
return php->size == 0;
}
- 返回堆顶元素:首先就要判断堆中是否有元素(断言即可
assert(php->size != 0)),若有则返回数组中下标为0的元素(即堆顶,根节点)。
//返回堆顶
HPDataType HeapTop(HP* php)
{
assert(php);
assert(php->size != 0);
return php->a[0];
}
三、堆结构的应用
了解了堆结构的实现方法,我们便可以将其运用到以下两个问题中:
3.1堆排序
这里的堆排序是基于数组,运用二叉树的性质(即将待排序的数组当作一棵完全二叉树)来实现的,不会过多的动态开辟空间。 要与重新建堆的堆排序区别开(下面topk问题会用到,所以这里就不介绍了)!
如果我们要将此数组排成一个升序的数组,要如何实现呢?
既然此数组可当作一棵完全二叉树,那么首先我们就要将此树排成大堆,那么要建大堆而不建小堆呢?根据堆的性质,大堆的根节点可以筛选最大值,同理 小堆的根节点可以用来筛选最小值,那么如果我们建了小堆,就要 将最小值(即根节点)保留,然后将除此元素的数组的逻辑结构重新当作一个完全二叉树,那么这个二叉树的 各个节点间的关系就全都乱了,需要重新排成小堆。

由以上逻辑我们也可以看出,如果建小堆,那么此问题将变得十分复杂,且时间复杂度也很高。 既然这样,那么我们就可以建大堆来将数组排为升序:
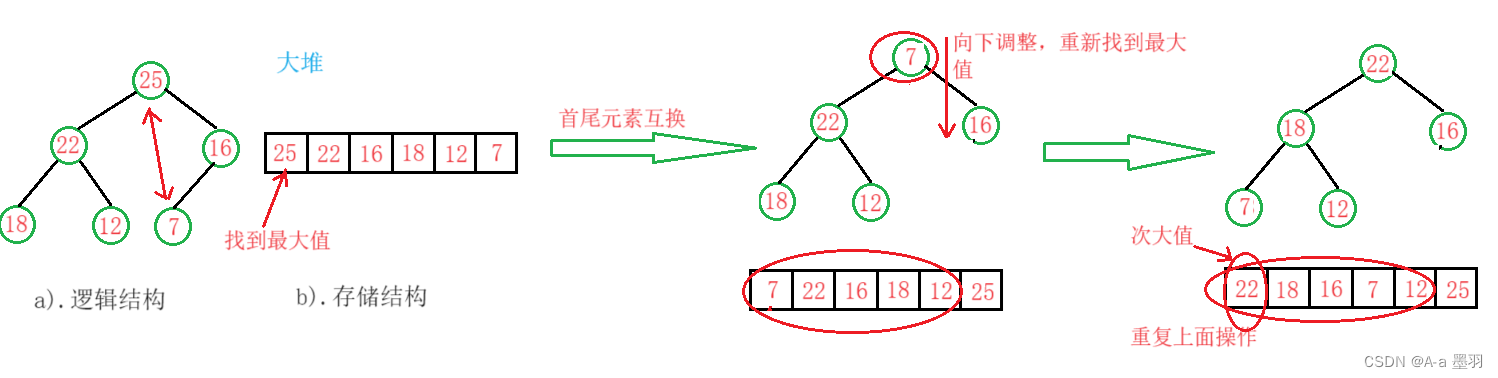
我们用大堆找到最大值,然后将首尾元素互换,这样大堆的各个节点的关系就不会被打乱(不需要重新排大堆),最后只需要将堆顶的元素向下调整AdjustDown()重新找到次大值,需要注意的是调整时要将size-- 以避免已有最大值对此次调整造成影响,以此类推便得到一个升序数组。
那么我们要如何在一个数组上将其排为大堆呢?介绍以下两种方法:
- 方法一:向下调整
给定一个数组,从下标为(len - 1 - 1) / 2的元素开始,直到下标为0,并将此值赋给parent。对下标为parent到len - 1之间的元素排大堆。(从后面元素开始向下调整)逻辑大致如下:
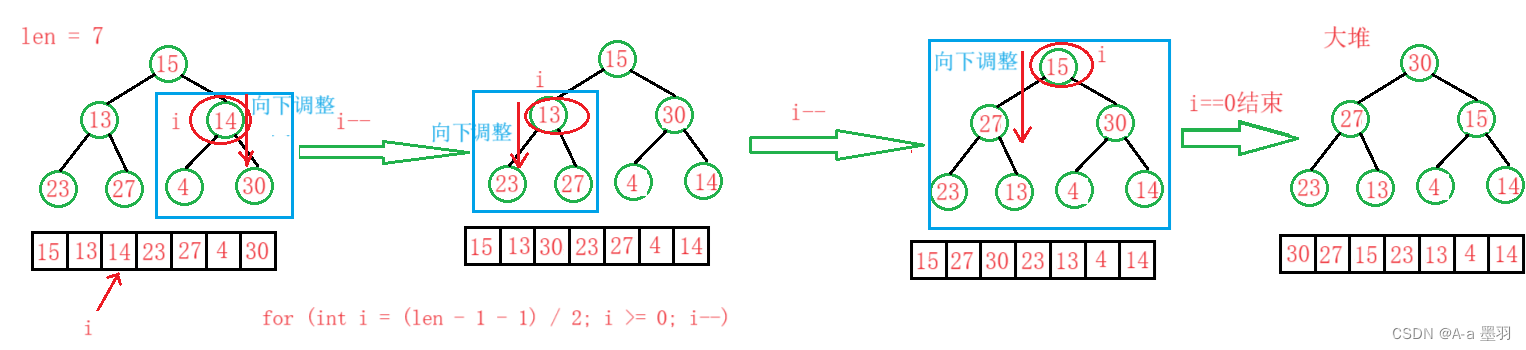
- 方法二:向上调整
与向下调整相似,我们可以从下标为1的元素开始,直到下标为len - 1,并将此值赋给child。对下标为0到child之间的元素排大堆。(从前面元素开始向上调整)逻辑大致如下:
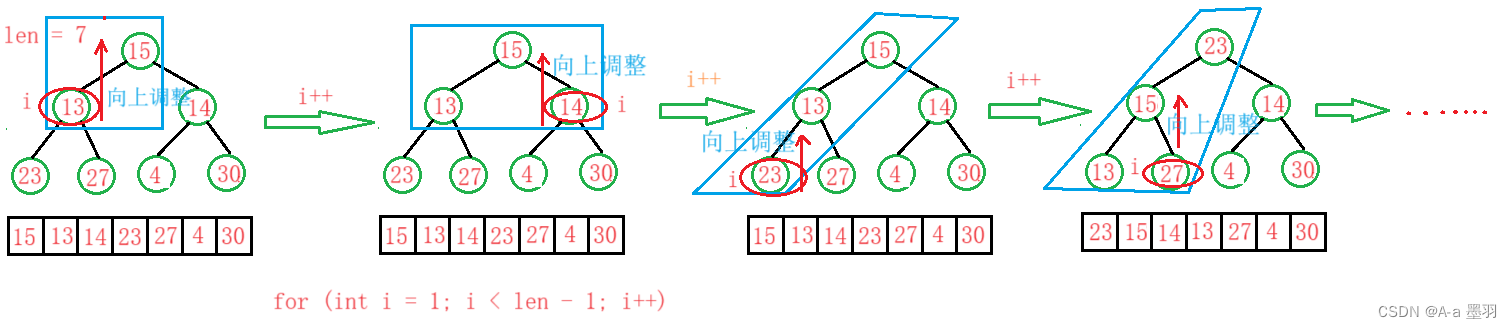
那么两种方法谁更优呢?事实上方法一要优于方法二,这里就不多介绍了,只提供一下思路:方法一中我们所需要调整的节点个数相较于数组长度少一半(即少了二叉树最后一层次的调整),且越靠后的层次(节点数多)所需调整的步数越少;而方法二中我们所需要调整的节点个数与数组长度相近,且越靠后的层次(节点数多)所需要调整的步数越多。
那么虽然两种方法时间复杂度都为O(N*log(N)),但实际上方法一中调整次数要少于方法二。
// 对数组进行堆排序--从小到大
void HeapSort(int* a, int len)
{
//方法二:--O(N*logN)
/*for (int i = 1; i < len - 1; i++)
{
AdjustUp(a, i);
}*/
//方法一:--O(N*logN)
for (int i = (len - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, len - 1, i);
}
int end = len - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end-1, 0);
end--;
}
}
3.2Top-k问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。 比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能数据都不能一下子全部加载到内存中)。最佳的方式就是用堆来解决,基本思路如下:
- 用数据集合中前K个元素来建堆
前k个最大的元素,则建小堆
前k个最小的元素,则建大堆 - 用剩余的N-K个元素依次与堆顶元素来比较,满足则替换堆顶元素,并向下调整
为了模拟此问题,我们可以先造10000个整型放到文件中,要找最大值时再从文件中一个个读出。为了保证数据的随机性,我们可以使用srand()函数,并设置一个不断变化的时间戳(unsigned int)time(0)。 具体造数据方法如下:
//造数据
void CreatData()
{
int n = 10000;
srand((unsigned int)time(0));
const char* fileName = "data.txt";
FILE* file = fopen(fileName, "w");
if (file == NULL)
{
printf("fopen()::fail");
exit(-1);
}
for(size_t i = 0; i < n; i++)
{
int x = (rand() + i) % 10000;
fprintf(file, "%d\n", x);
}
}
既然此问题的目的是找出最大的k个数(k远小于数据个数),那么我们可以建一个只能存放k个数据的小堆。 估计会有以下两个疑问:
- 为什么只建能存放
k个数据的堆?
因为如果将文件中的所以数据都建成堆,那么当数据一多时,动态开辟内存将十分巨大,甚至会造成溢出问题。 且有一个数据插入时,堆都需要重新调整,这样一来时间复杂度将会很高,运行效率也大大降低。 - 为什么建小堆而不建大堆?
反过来想一下,如果建大堆的话,当最大的数已找到,那么它将一直堵在堆顶,其余的所有数都无法进堆。所以我们选择建小堆,堆顶元素最小,每当有新元素时只需要和堆顶进行比较即可,大的替换堆顶并向下调整,小的直接跳过即可。
代码实现如下:
//前k个大的数
void PrintTopK(int k)
{
//建有五个数的堆--小堆
FILE* file = fopen("data.txt", "r");
if (file == NULL)
{
printf("fopen()::fail");
exit(-1);
}
int* minheap = (int*)malloc(sizeof(int) * k);
if (minheap == NULL)
{
perror("malloc()::fail");
exit(-1);
}
for (int i = 0; i < k; i++)
{
fscanf(file, "%d", &minheap[i]);
AdjustUp(minheap, i);
}
//将数据依次比较,大的下沉--向下调整
int x;
while (fscanf(file, "%d", &x) != EOF)
{
if (x > minheap[0])
{
minheap[0] = x;
AdjustDown(minheap, k, 0);
}
}
//打印堆
for (int i = 0; i < k; i++)
{
printf("%d ", minheap[i]);
}
putchar('\n');
//销毁堆
free(minheap);
minheap = NULL;
}
四、堆概念及结构相关题目
- 已知小根堆为
8,15,10,21,34,16,12,删除关键字8之后需重建堆,在此过程中,关键字之间的比较次
数是(C)。
A 1
B 2
C 3
D 4解: 由此结构可以推断出,逻辑结构的二叉树有三层,将
12移动到堆顶,然后向下调整,在调整过程中首先比较两个孩子节点找出较小的那个(第一次),然后比较孩子和父亲节点大小(第两次),因为满足条件所以交换(8来到右子树),因为此时并无右孩子所以省略左右孩子大小的比较,最后只需要比较一次孩子和父亲节点即可(第三次)。
- 最小堆[0,3,2,5,7,4,6,8],在删除堆顶元素0之后,其结果是(
C)
A[3,2,5,7,4,6,8]
B[2,3,5,7,4,6,8]
C[2,3,4,5,7,8,6]
D[2,3,4,5,6,7,8]解: 首尾互换,堆顶向下调整
- 下列关于向下调整算法的说法正确的是(
B)
A.构建堆的时候要对每个结点都执行一次
B.删除操作时要执行一次
C.插入操作时要执行一次
D.以上说法都不正确解: A: 建堆时,从每一个非叶子节点开始,倒着一直到根节点,都要执行一次向下调整算法。
B: 删除元素时,首先交换堆顶元素与堆中最后一个元素,对中有效元素个数减1,即删除了堆中最后一个元素,最后将堆顶元素向下调整
C: 插入操作需要执行向上调整算法。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Mysql主从复制
- 商业加速终极指南:创业家的10个关键步骤
- nn.BCEWithLogitsLoss中weight参数和pos_weight参数的作用及用法
- 01.阿里Java开发手册——命名规范
- 持续领跑云安全赛道!安全狗多项安全能力获认可
- ios 裁剪拼装图片
- Serverless架构学习路线及平台对比
- 时尚炫酷动态图文幻灯片视频素材AE模板
- 基于深度学习的PCB板缺陷检测系统(含UI界面、yolov8、Python代码、数据集)
- C++学习笔记--函数