DDPM: Denoising Diffusion Probabilistic Models的白话总结
目前所采用的扩散模型大都是来自于2020年的工作DDPM: Denoising Diffusion Probabilistic Models。本文主要是对b站视频大白话AI | 图像生成模型DDPM 的记录和总结。该视频是目前见到的对DDPM讲述最为浅显易懂的,首先表达对视频作者的敬意,推荐看原视频,本文的讲述略去了一些比较常识性的东西,原视频非常值得看,会有很多收获。故记录总结之。
对深入的知识进行本质的理解,并以形象、浅显、易懂的形式呈现出来,是毕生之追求。目前能力尚浅,有幸看到很多大神已经做出了很多漂亮的工作。所以先做好转呈记录。
1 正文开始
1.1 扩散模型
扩散过程:物质粒子从高浓度区域向低浓度区域移动的过程。

扩散模型受其启发,通过逐步向图像中加入高斯噪声来模拟这种现像。并通过逆向过程从(随机)噪声中生成图片。

1.2 前向加噪
首先将图片各通道的像素强度归一化到【-1,1】之间,然后随机采样生成一张同样大小的噪声图片。

噪声图片中所有通道像素遵从标准正态分布。将高斯噪声图片与同尺寸图片进行混合。相同位置像素使用公式
β
×
?
+
1
?
β
×
x
(1)
\sqrt \beta \times \epsilon + \sqrt {1-\beta} \times x \tag{1}
β?×?+1?β?×x(1)
进行混合,其中
?
\epsilon
?是噪声,
x
x
x是图片。
β
\beta
β是0-1之间的数。注意系数的平方和等于 1.
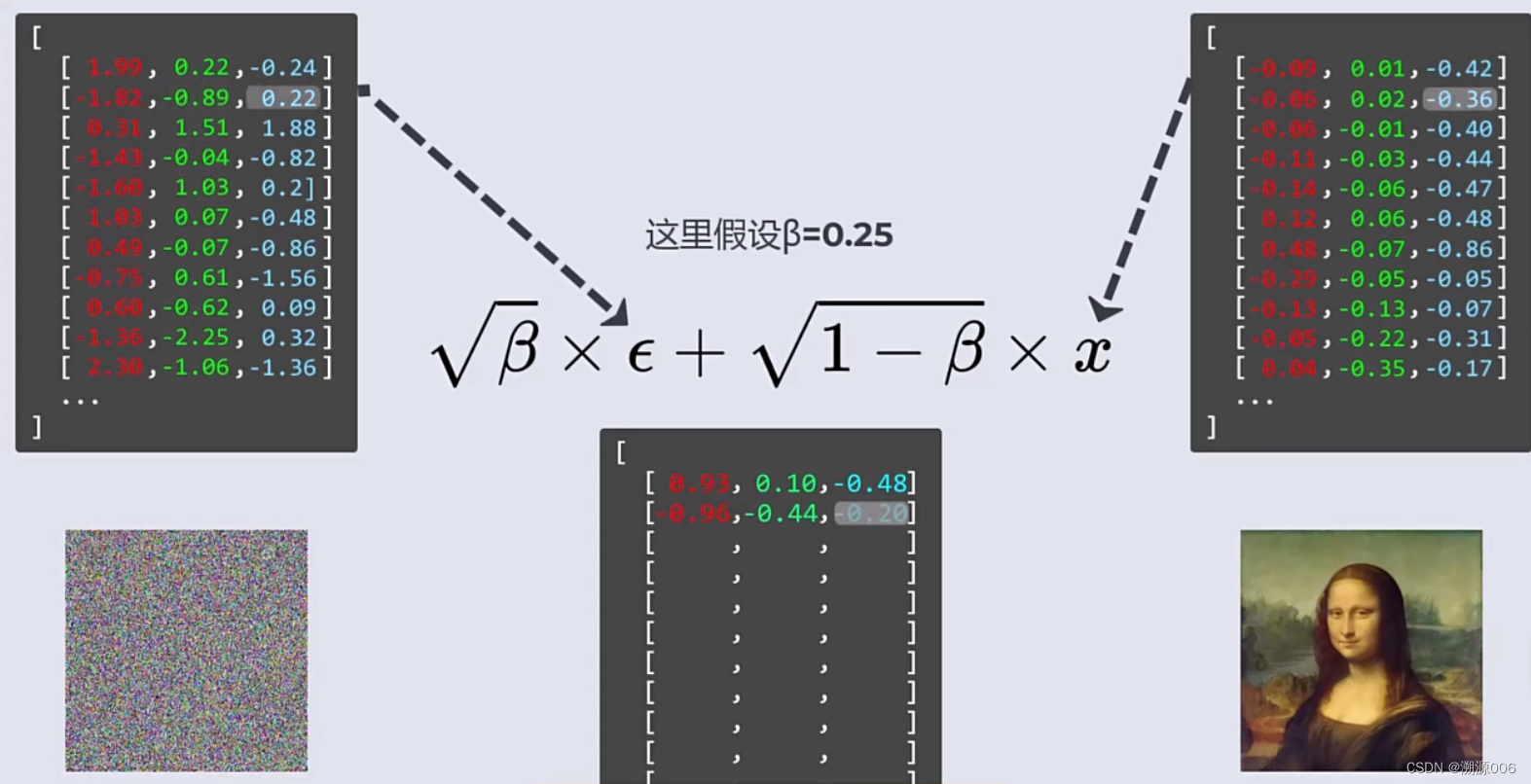
通过对图像加噪(公式(1))来模拟扩散过程。

这样就有了一个递推公式:
x
t
=
β
t
×
?
t
+
1
?
β
t
×
x
t
?
1
(2)
x_t = \sqrt {\beta_t} \times \epsilon_t + \sqrt {1-\beta_t} \times x_{t-1} \tag{2}
xt?=βt??×?t?+1?βt??×xt?1?(2)
其中的
?
t
~
N
(
0
,
1
)
\epsilon_t \sim N(0,1)
?t?~N(0,1),也就是噪声图像都是基于标准正太分布随机采样的随机数。而且每一步中的
β
\beta
β并不相同。
0
<
β
1
<
β
2
<
.
.
.
<
β
t
<
.
.
.
.
.
<
β
t
<
1
0<\beta_1<\beta_2<...<\beta_t<.....<\beta_t<1
0<β1?<β2?<...<βt?<.....<βt?<1
β
\beta
β越来越大,扩散速度越来越快。
为了方便后面的推导,定义:
α
t
=
1
?
β
t
\alpha_t=1-\beta_t
αt?=1?βt?,这样(2)式就变成:
x
t
=
1
?
α
t
×
?
t
+
α
t
×
x
t
?
1
(3)
x_t = \sqrt {1-\alpha_t} \times \epsilon_t + \sqrt {\alpha_t} \times x_{t-1} \tag{3}
xt?=1?αt??×?t?+αt??×xt?1?(3)
使用公式(3)可以从
x
0
x_0
x0?开始,逐步迭代,T次后就可以得到
x
T
x_T
xT?。

现在思考一个问题,能否直接从
x
0
x_0
x0?得到
x
T
x_T
xT?,从而避免多次迭代?

先看下
x
t
x_t
xt?与
x
t
?
2
x_{t-2}
xt?2?的关系

将上图中的第二个式子带入上面的式子,得到:

上图的第二个式子是整理后的结果,其中的
a
a
a应该是
α
\alpha
α,小错误,不影响观看。其中的
?
t
\epsilon_t
?t?与
?
t
?
1
\epsilon_{t-1}
?t?1?是两个相互独立的随机噪声变量。所以此式子表示了
x
t
x_t
xt?与
x
t
?
2
x_{t-2}
xt?2?的关系。而两个独立的随机变量可以一个一个按顺序采样,也可以两个同时采样。所以要知道
α
t
(
1
?
α
t
?
1
)
?
t
?
1
+
1
?
α
t
?
t
\sqrt {\alpha_t(1-\alpha_{t-1})}\epsilon_{t-1}+\sqrt {1-\alpha_{t}}\epsilon_{t}
αt?(1?αt?1?)??t?1?+1?αt???t?的概率分布。首先我们知道,两个正太分布的随机变量的和任然是正太分布:
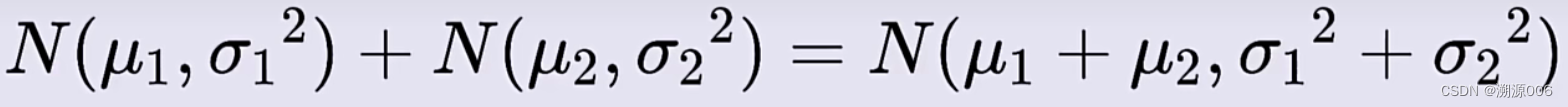
因为
?
t
?
1
~
N
(
0
,
1
)
\epsilon_{t-1} \sim N(0,1)
?t?1?~N(0,1),所以
α
t
(
1
?
α
t
?
1
)
?
t
?
1
~
N
(
0
,
α
t
(
1
?
α
t
?
1
)
)
\sqrt {\alpha_t(1-\alpha_{t-1})}\epsilon_{t-1}\sim N(0,\alpha_t(1-\alpha_{t-1}))
αt?(1?αt?1?)??t?1?~N(0,αt?(1?αt?1?));同理,
1
?
α
t
?
t
~
N
(
0
,
1
?
α
t
?
1
)
\sqrt {1-\alpha_{t}}\epsilon_{t} \sim N(0,1-\alpha_{t-1})
1?αt???t?~N(0,1?αt?1?),所以会有:
N
(
0
,
α
t
(
1
?
α
t
?
1
)
)
+
N
(
0
,
1
?
α
t
?
1
)
=
N
(
0
,
1
?
α
t
α
t
?
1
)
(4)
N(0,\alpha_t(1-\alpha_{t-1}))+N(0,1-\alpha_{t-1})=N(0,1-\alpha_t\alpha_{t-1}) \tag{4}
N(0,αt?(1?αt?1?))+N(0,1?αt?1?)=N(0,1?αt?αt?1?)(4)
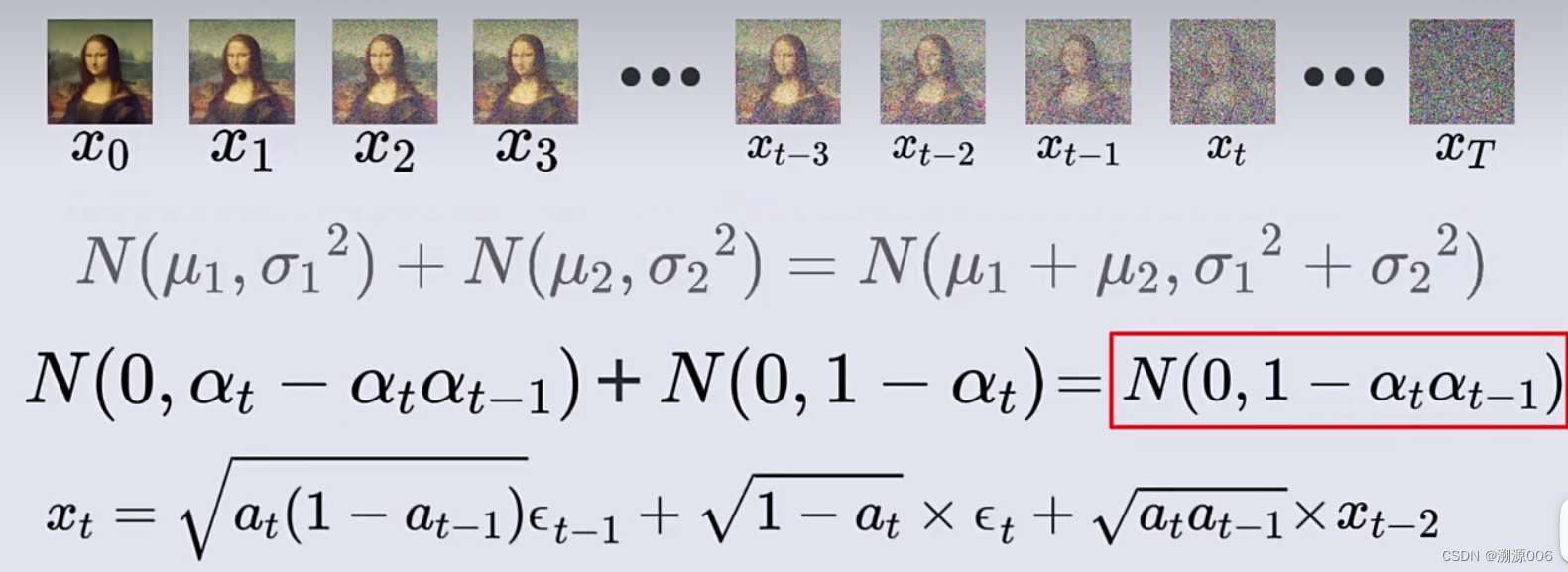
所以上式的两个正太分布随机变量可以合并成一个正态分布随机变量,所以上面的式子可以改写如下(这种改写方式称为“重参数化技巧”):

上面得到了
x
t
x_t
xt?与
x
t
?
2
x_{t-2}
xt?2?的关系,下面再来看
x
t
x_t
xt?与
x
t
?
3
x_{t-3}
xt?3?的关系的关系:

把
x
t
?
2
与
x_{t-2}与
xt?2?与x_{t-3}的关系带入刚刚得到的式子就得到:
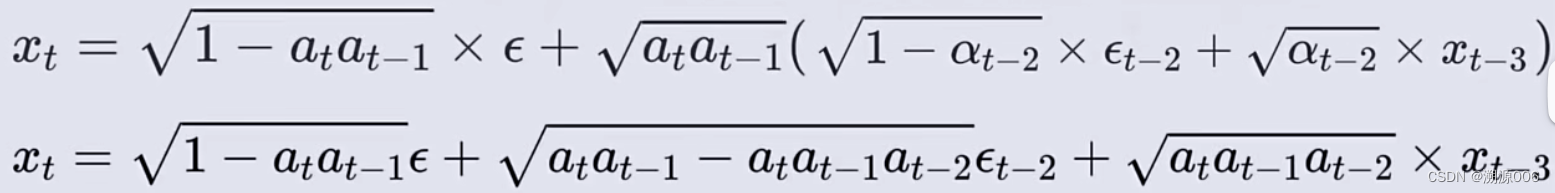
又得到了两个独立分布的正态分布随机变量。再次使用重参数化技巧,可以继续将其合并为一个正太分布随机变量。

这样就有了
x
t
与
x_{t}与
xt?与x_{t-3}的关系,结合之前
x
t
与
x_{t}与
xt?与x_{t-2}的关系

使用数学归纳法,可以证明得到(证明过程略):

让
k
=
t
k=t
k=t得到怎么从
x
0
x_0
x0?直接到
x
t
x_t
xt?

为了简化长度,让:

从而有:

至此,得到了一个从
x
0
x_0
x0?直接到
x
t
x_t
xt?的式子
1.3 反向过程
从随机噪声
x
T
x_T
xT?得到图像
x
0
x_0
x0?

先思考怎么从后一时刻可到前一时刻的图像

然后就可以逐步向前,从
x
T
x_T
xT?计算到
x
0
x_0
x0?

1.3.1 贝叶斯公式
一个例子:小明一般80%的情况下坐地铁回家,一般20%的情况下坐公交回家,坐地铁会抓一次娃娃,有30%的可能抓到一个娃娃,坐公交也会抓一次娃娃,有80%的可能性抓到一个娃娃。有一天小明拿着一个娃娃回家,那他是怎么回来的?可能性分别是多少?

用一个正方形表示所有可能性,是100%。横轴表示坐公交和坐地铁,分别是20%和80%的概率。

用
P
(
W
∣
X
)
P(W|X)
P(W∣X)的概率表示坐公交抓到娃娃的概率,为0.8,
P
(
W
∣
Y
)
P(W|Y)
P(W∣Y)的概率表示坐地铁抓到娃娃的概率,为0.3.在正方形中的表示如下:

那么抓到娃娃的概率就是:

那么抓到一个娃娃,从地铁过来的概率和从公交过来的概率分别是:

这就是传说中的贝叶斯公式:

P
(
A
)
P(A)
P(A):先验概率(prior),基于之前的经验,知道乘坐地铁或者公交的概率
P
(
A
∣
B
)
P(A|B)
P(A∣B):后验概率(posterior),也是乘坐地铁或者公交的概率,但是是B事件发生后,对先验概率的修正
P
(
B
)
P(B)
P(B):这种修正的基础是看到了B事件的发生,所以B事件称为证据(Evidence)
P
(
B
∣
A
)
P(B|A)
P(B∣A):似然(likelihood),表示A事件发生下,B很有可能发生,这个可能性是多少。它的值可以看作B事件对A事件的归因力度(证据强度)。

1.3.2 反向过程
反向过程需要用到贝叶斯公式:

实际上是在给定图像
x
0
x_0
x0?的情况下

因为
?
t
~
N
(
0
,
1
)
\epsilon_t \sim N(0,1)
?t?~N(0,1),所以
1
?
α
t
?
t
~
N
(
0
,
1
?
α
t
?
1
)
\sqrt {1-\alpha_{t}}\epsilon_{t} \sim N(0,1-\alpha_{t-1})
1?αt???t?~N(0,1?αt?1?),所以从(3)式
x
t
=
1
?
α
t
×
?
t
+
α
t
×
x
t
?
1
(3)
x_t = \sqrt {1-\alpha_t} \times \epsilon_t + \sqrt {\alpha_t} \times x_{t-1} \tag{3}
xt?=1?αt??×?t?+αt??×xt?1?(3)
可以知道
x
t
~
N
(
α
t
x
t
?
1
,
1
?
α
t
)
x_t \sim N(\sqrt {\alpha_t}x_{t-1} ,1-\alpha_t)
xt?~N(αt??xt?1?,1?αt?),从而可以知道
P
(
x
t
∣
x
t
?
1
,
x
0
)
P(x_t|x_{t-1},x_0)
P(xt?∣xt?1?,x0?)
 同理可以从上图的第二个式子推导出
同理可以从上图的第二个式子推导出
x
t
~
N
(
α
ˉ
t
x
0
,
1
?
α
ˉ
t
)
x_t \sim N(\sqrt {\bar \alpha_t}x_{0} ,1-\bar \alpha_t)
xt?~N(αˉt??x0?,1?αˉt?)
x
t
?
1
~
N
(
α
ˉ
t
?
1
x
0
,
1
?
α
ˉ
t
?
1
)
x_{t-1} \sim N(\sqrt {\bar \alpha_{t-1}}x_{0} ,1-\bar \alpha_{t-1})
xt?1?~N(αˉt?1??x0?,1?αˉt?1?)
然后就可以知道概率分布密度函数:

然后带入贝叶斯公式得到:

上面的式子化简一下就是:

从而有: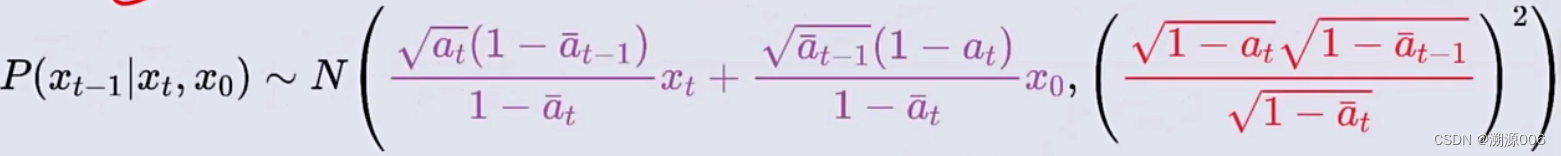
从之前的式子(任意
x
t
x_t
xt?图像都可以认为是从
x
0
x_0
x0?直接加噪得来的)可以推导出:

将
x
0
x_0
x0?带入得到
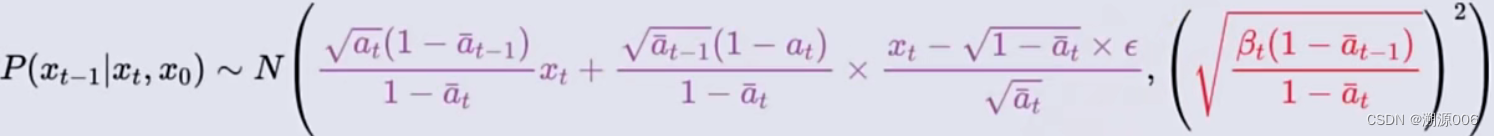
任意
x
t
x_t
xt?图像都可以认为是从
x
0
x_0
x0?直接加噪得来的,而只要知道了从
x
0
x_0
x0?到
x
t
x_t
xt?加入的噪声,就能得到他前一时刻
x
t
?
1
x_{t-1}
xt?1?的概率分布。可以训练一个神经网络,输入
x
t
x_t
xt?,来预测此图像相对于某个原图
x
0
x_0
x0?加入的噪声。

神经网络输出的是噪声
?
\epsilon
?,然后根据这个噪声就可以得到前一时刻图像的概率分布。

然后用此概率分布进行随机采样就能得到前一时刻的图像,然后再将前一时刻图像作为神经网络输入预测他的噪声
?
\epsilon
?,不断重复此过程知道得到
x
0
x_0
x0?。

这个过程最开始的时候怎么得到
x
T
x_T
xT?呢?看下式
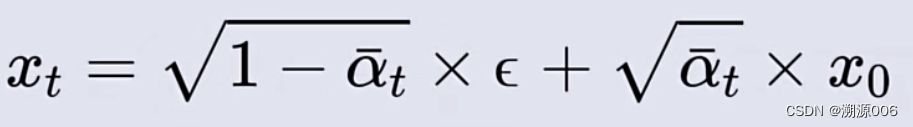
接近于T的时候
α
ˉ
t
\bar \alpha_t
αˉt?接近于0,从而
x
T
≈
?
x_T \approx\epsilon
xT?≈?,也就是
x
T
x_T
xT?接近于标准正太分布,因此可以认为任何一张标准正太分布的噪声图片都是某张
x
0
x_0
x0?原图加噪声以后得来的。只需要用标准正太分布随机采样就能生成
x
T
x_T
xT?
神经网络输入:t和
x
t
x_t
xt?,为了更好的学习到该图像在整个加噪过程中的位置。
输出:
?
\epsilon
?

从T时刻到0时刻反向的过程中可以看到,前一时刻图像正太分布标准差越来越小,越来越接近于0,前一时刻的图像分布越来越接近均值,越来越确定
参考
[1] https://zhuanlan.zhihu.com/p/563661713
[2] https://zhuanlan.zhihu.com/p/566618077
[3] https://zhuanlan.zhihu.com/p/630354327
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- XDOJ135.拼数字排序
- B 树如何让您的查询更快?
- 优化复杂查询:使用临时表——案例:提取最新工资记录
- 使用知行之桥EDI系统的HTTP签名身份验证
- C语言K&R圣经笔记 5.7多维数组 5.8指针数组初始化 5.9指针vs多维数组
- 记录汇川:H5U与Fctory IO测试10
- Springboot整合Canal -- Canal 多客户端
- 5D动感影院新奇体验丰富环境特效7D互动影院
- makefile编译静态链接库(.a文件)
- 操作系统--内存管理