【Redis】七、Redis主从复制(重点)
文章目录
参考:狂神说Java
1、概念
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(Master/Leader),后者称为从节点(Slave/Follower),
数据的复制是单向的!只能由主节点复制到从节点(主节点以写为主、从节点以读为主)。
默认情况下,每台Redis服务器都是主节点,
一个主节点可以有0个或者多个从节点,但每个从节点只能由一个主节点。(父子关系)
1.1、主从复制的作用主要包括
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余的方式。
- 故障恢复:当主节点故障时,从节点可以暂时替代主节点提供服务,是一种服务冗余的方式
- 负载均衡:在主从复制的基础上,配合读写分离,由主节点进行写操作,从节点进行读操作,分担服务器的负载;尤其是在多读少写的场景下,通过多个从节点分担负载,提高并发量。
- 高可用基石:主从复制还是 哨兵和集群能够实施的基础。
1.2、一般来说,要将Redis运用于工程项目中,只使用一台Redis是万万不能的(宕机),原因如下
- 从结构上,单个Redis服务器会发生单点故障,并且一台服务器需要处理所有的请求负载,压力较 大;
- 从容量上,单个Redis服务器内存容量有限,就算一台Redis服务器内存容量为256G,也不能将所有 内存用作Redis存储内存,一般来说,单台Redis大使用内存不应该超过20G。
- 电商网站上的商品,一般都是一次上传,无数次浏览的,说专业点也就是"多读少写"。
对于这种场景,我们可以使如下这种架构:
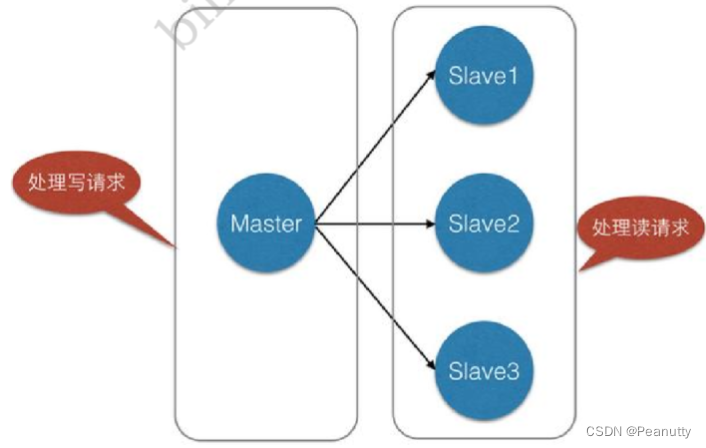
主从复制,读写分离!80%的情况下都是在进行读操作!减缓服务器的压力!架构中经常使用! 一主 二从!
只要在公司中,主从复制就是必须要使用的,因为在真实的项目中不可能单机使用Redis!
2、环境配置
只配置从库,不用配置主库!,因为每个redis默认都是主库。
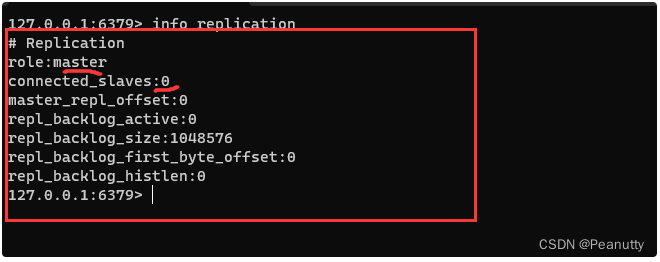
info replication# 查看当前库的信息 # Replication
在这里插入代码片127.0.0.1:6379> info replication # 查看当前库的信息 # Replication
role:master # 角色
master connected_slaves:0 # 没有从机
master_replid:b63c90e6c501143759cb0e7f450bd1eb0c70882a
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
2.1、复制拷贝3个配置文件,然后修改对应的信息
通过配置文件启动redis,分别在三个端口启动redis服务
- 端口
- pid 名字
- log文件名字
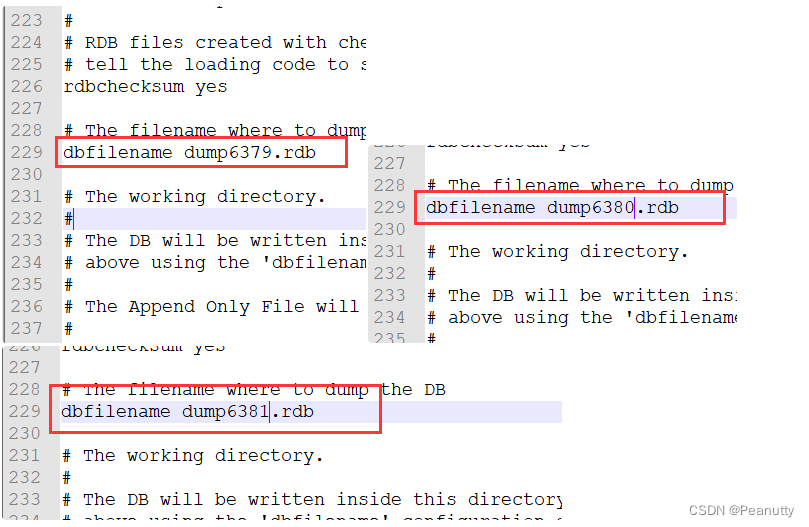
- dump.rdb 名字
拷贝文件
windows操作如下
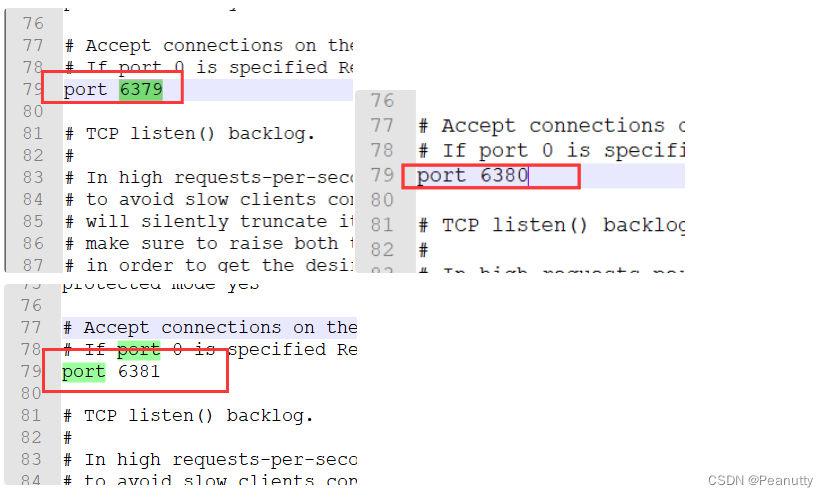
改端口
分别改端口
改pid文件名
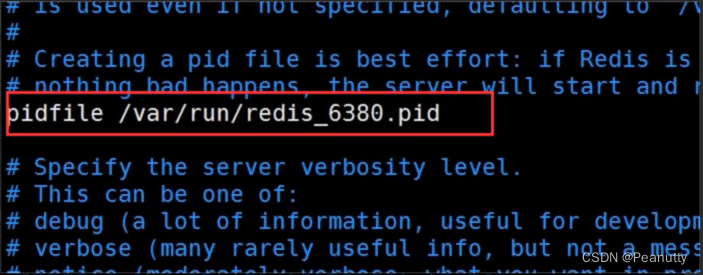
log文件名
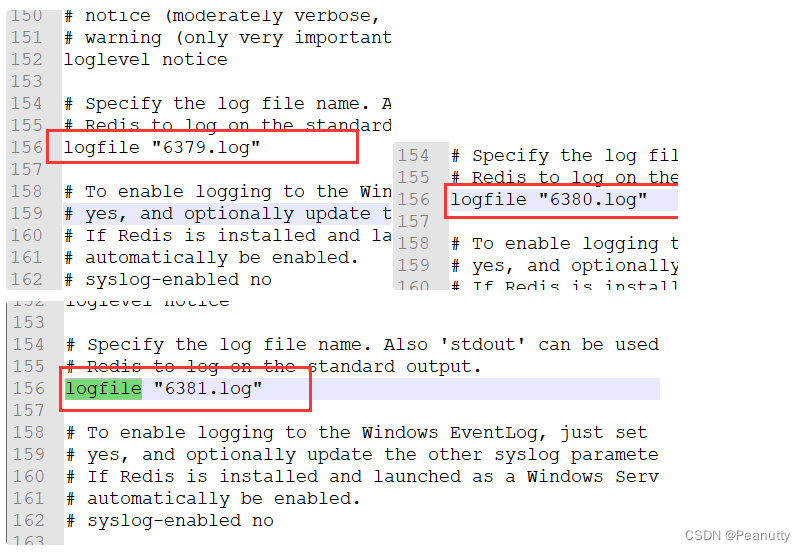
dump.rdb文件名字
2.2、 分别启动三个服务
开三个命令行
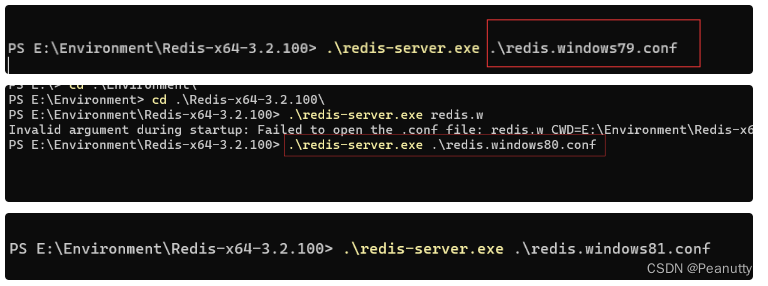
windows/linux: 在redis目录下查看是否启动成功,有log文件
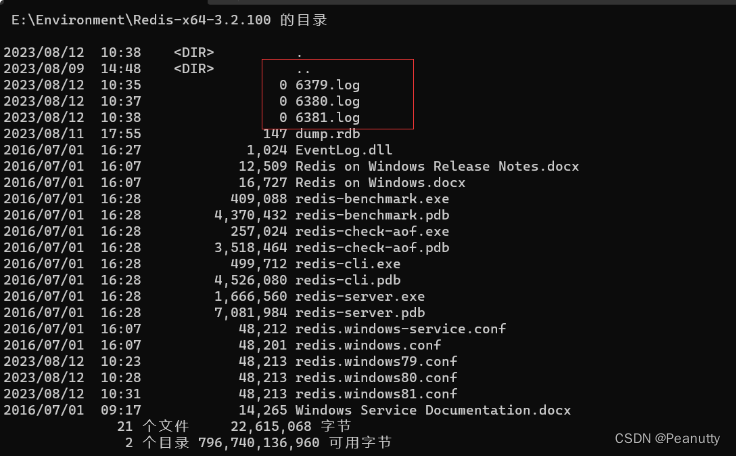
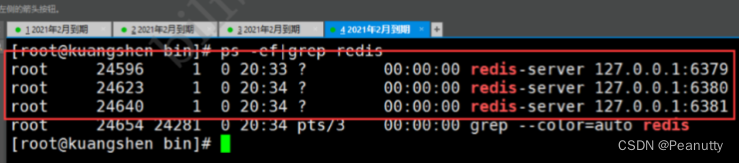
linux:修改完毕之后,启动我们的3个redis服务器,可以通过进程信息查看!
3、配置一主二从
默认情况下,每台Redis服务器都是主节点;我们一般情况下只用配置从就好了!
认老大! 一主 (79)二从(80,81)
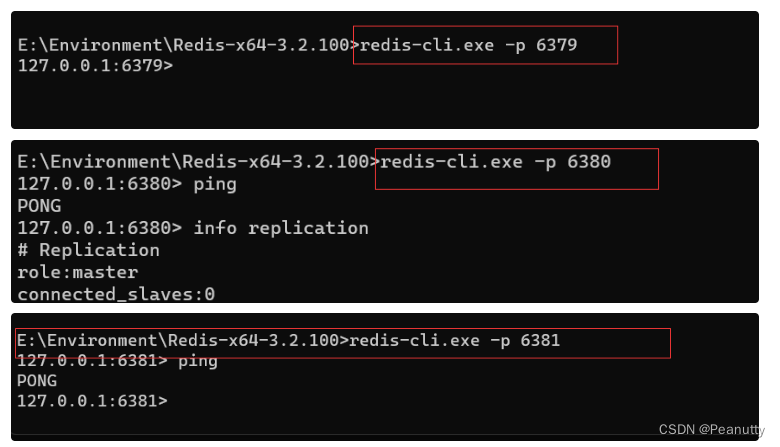
3.1、分别连接三个redis-cli
开三个窗口,命令如下
3.2、配置从机,认老大
命令 slaveof [ip] [port]
如下配置6380。6381的配置操作相同
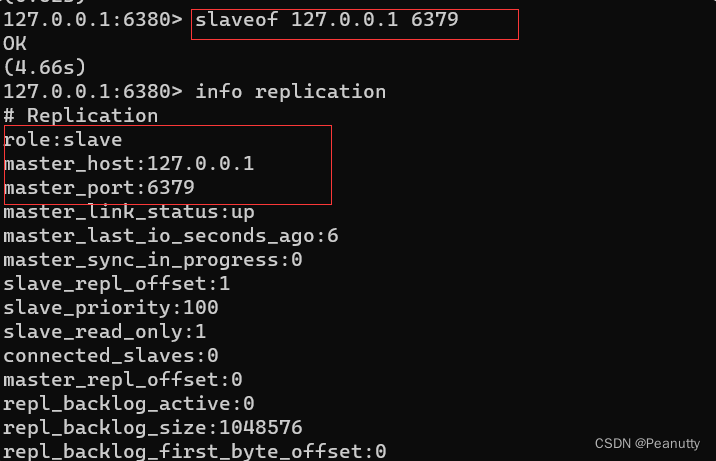
127.0.0.1:6380> SLAVEOF 127.0.0.1 6379 # SLAVEOF host 6379 找谁当自己的老大!
OK
127.0.0.1:6380> info replication
# Replication
role:slave # 当前角色是从机
master_host:127.0.0.1 # 可以的看到主机的信息
master_port:6379
master_link_status:up
master_last_io_seconds_ago:3
master_sync_in_progress:0
slave_repl_offset:14
slave_priority:100
slave_read_only:1
connected_slaves:0 master_replid:a81be8dd257636b2d3e7a9f595e69d73ff03774e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:14
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:14
# 在主机中查看!
127.0.0.1:6379> info replication
# Replication
role:master connected_slaves:1 # 多了从机的配置
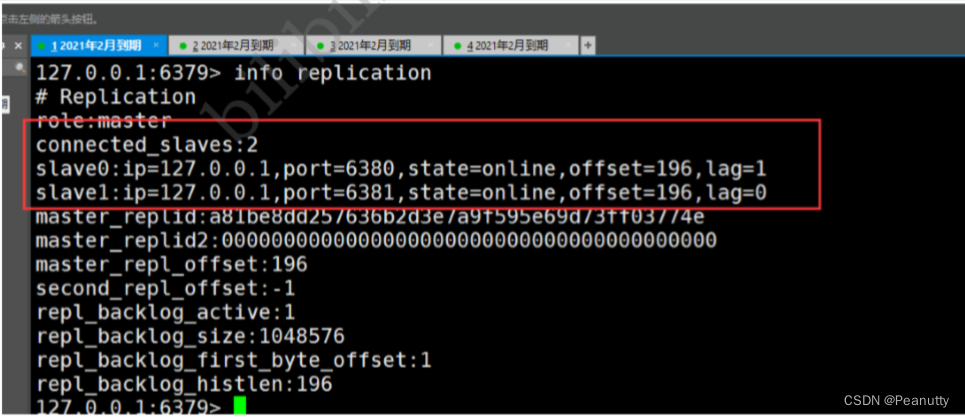
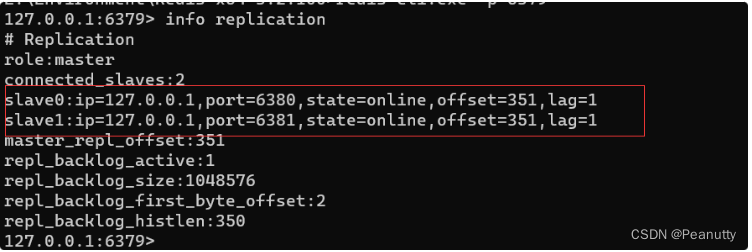
slave0:ip=127.0.0.1,port=6380,state=online,offset=42,lag=1 # 多了从机的配置
master_replid:a81be8dd257636b2d3e7a9f595e69d73ff03774e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:42
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:42
3.3、在主机中查看从机信息
info replication
如果两个都配置完了,就是有两个从机
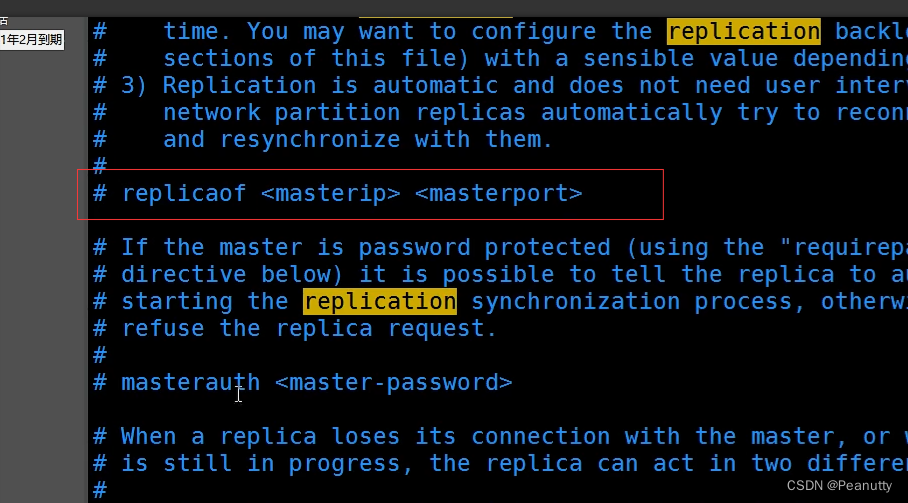
3.4、从配置文件实现主从复制
真实的从主配置应该在配置文件中配置,这样的话是永久的,我们这里用的是命令,暂时的!
去掉注释,换成对应的ip和端口
3.5、细节
主机可以写,从机不能写只能读!主机中的所有信息和数据,都会自动从机保存!
主机写
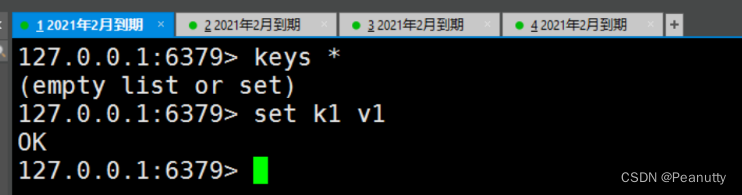
从机只能读取内容!
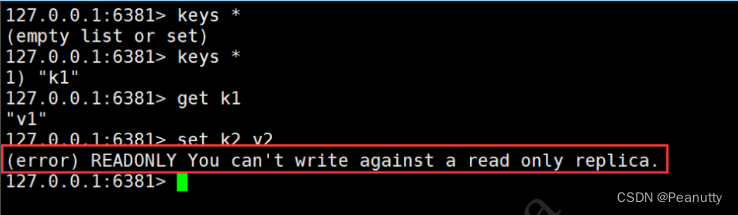
4、主从测试:
主机断开连接,从机依旧连接到主机的,但是没有写操作,这个候,主机如果回来了,从机依旧可以直接获取到主机写的信息!
如果是使用命令行来配置的主从(而不是配置文件),这个时候从机如果重启了,就会变回主机!但是只要变为从机,立马就会从主机中获取值!
4.2、复制原理
- Slave 启动成功连接到 master 后会发送一个sync同步命令
- Master 接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行。
完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。(全量复制) - 全量复制:slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
- 增量复制:Master 继续将新的所有收集到的修改命令依次传给slave,完成同步
- 但是只要是重新连接master,一次完全同步(全量复制)将被自动执行! 我们的数据一定可以在从机中看到!
4.3、另一种主从配置方案、层层链路
上一个M链接下一个 S!
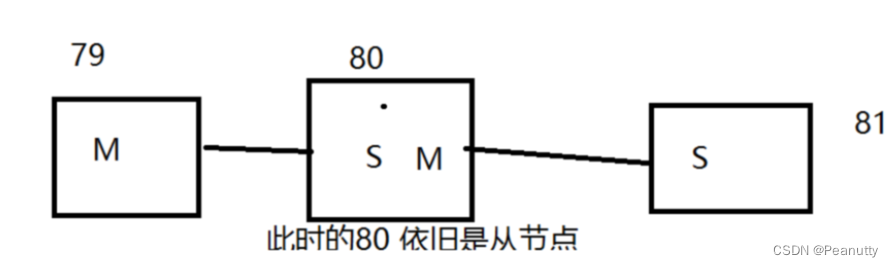
这时候也可以完成我们的主从复制!
如果没有老大了,这个时候能不能选择一个老大出来呢?在哨兵模式之前需要手动!
谋朝篡位
如果主机断开了连接,我们可以使用 SLAVEOF no one 让自己变成主机!其他的节点就可以手动连接到最新的这个主节点(手动)!如果这个时候老大修复了,那就只能重新配置连接!
上面这些都是手动的,后面会有哨兵模式(自动)

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JAVA读取文本转成JSON
- 国际语音呼叫中心的工作流程
- mysql的性能调优,explain的用法,explain各字段的解释
- [AutoSar]基础部分 RTE 07 VFB虚拟功能总线
- 微服务之服务注册与发现
- CAPL入门到精通之CAPL Functions(四) 下 - 字符串函数实例
- 应用开发平台集成工作流系列之14——流程表单实现示例
- SoapUI 怎么下载:实用指南
- beego的控制器Controller篇 — 过滤器
- 外贸SOHO建站产品图来源?海洋建站教程?