Z-score 因子的深入思考
最新(2024 年 1 月)出版的 SC 技术分析(Techical Analysis of Stock & Commodities)的第 4 条文章给到了 Z-score,原文标题为《Z-score: How to use it in Trading》。今天的笔记,就借此机会,同步推出我们对通过Z-score来构建量化因子的一些观点。

Z-Score 的计算
Z-score 的计算公式如下:
Z
=
X
?
μ
σ
Z = \frac{X-\mu}{\sigma}
Z=σX?μ?
这里 Z Z Z是 z-score, X X X一般取股价, μ \mu μ是均值, σ \sigma σ是标准差,也称波动率。
如果 X服从正态分布,那么将有以下结论:
- abs(z-score) >= 2 的概率小于 2.3%
- abs(z-score) >= 3 的概率小于 0.13%
由此可以作为某种反转信号,即一旦z-score超过±2,将有97.7%的概率会回归到±2 以内,也就是股价会发生向均值方向的回归。
在 scipy.stats 包中有 zscore 计算函数,但它是基于我们传入的全部数据的。在因子构建中,我们实际上要计算的是rolling-zscore。因此,我们借用 pandas 中的 rolling 方法来自行计算:
def rolling_zscore(s, win=20):
ma = s.rolling(window=win).mean()
std = s.rolling(window=win).std()
return (s - ma)/std

因子检验
这篇笔记不打算走完整的流程,我们将随机选择一个标的,计算它最近 250 期的 zscore,把 zscore 小于-2 的点作为买入点,大于 2 的点作为卖出点,进行绘图显示,然后就图的走势,来进行深入讨论:
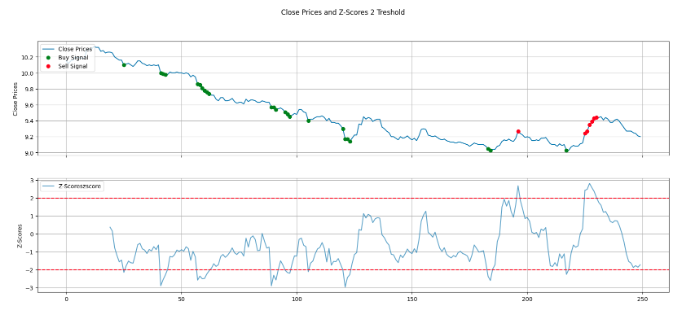
可以看出,每一个买入点差不多都是局部的最低点,每一个卖出点也差不多是局部最高点。但是,在下跌趋势中,即使我们在最低点进入了,它的反弹并不能持续多久(或者多大的幅度),而且很难等到 zscore 的卖出点,往往就已经拐头了。
或者说,zscore大于2,是一个卖出的充分但不必要条件;zscore 小于-2, 是一个买入的充分但不必要的条件。它不对未来趋势进行预测,并且在 97.7%的时间里,不会发出交易信号,这样资金利用率也不够。因此,zscore 可以构成一个因子,但不能构成一个策略。但作为因子,它仍然是优秀的,因为它能发出确定、胜率很高的信号。
与布林带的关系
如果你熟悉布林带策略,那么你会发现,z-score 的算法与布林带一模一样。不同的是,布林带的上下轨的数值是均值的±2个标准差,取值的波动可以很大,而z-score的取值是在确定的范围内(-3, +3),具有类似归一化的特征。正因为如此,它可以很方便地当成因子,用在机器学习中。实际上,要做到真正的归一化,我们直接取 z-score 的累积概率就好,它是在 [0,1] 区间分布的,并且当 z-score 为 2 时,累积概率为 0.977.

警惕黑天鹅
与其它别的因子不一样的地方是,z-score 因子的有效性来源于正态分布的假设。只有股价的波动符合正态分布,我们才能断言价格偏离均值加两个标准差的可能性小于 2.3%。然而,股价的波动并不符合正态分布(指数会更接近一点,但也是更符合广义双曲分布,而不是正态分布)。因此,z-score因子(以及布林带)的理论根基并不牢固。
另外,最重要的一点是,在偏离两个标准差的地方,尽管其概率很小,但也存在一种可能,就是它一旦发生,其后果会比较严重。这就是由 Taleb 提出的所谓黑天鹅效应。在 A 股中,需要注意的是,如果在偏离两个标准差的地方,如果发生了涨跌停,那么我们应该果断放弃 z-score 因子。因为在这种情况下,交易情绪是极端化的。
Quiz
如果价格的波动并不服从正态分布,或者任何一种已知的分布,我们又该如何把握它的统计学特征呢?
举例来说,如果有这样一个问题,今天沪指已经下跌了4%,依据过去1000个交易日的统计数据,它继续下跌的概率是多少,你应该如何回答这个问题?能够正确地回答这个问题的人,才能抓住加速赶底、或者因意外事件错误下跌的机会。
提示:这是我们在课程中,用来引出PDF/CDF概念的一个问题。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 我勒个豆,怎么没人告诉我这个偷懒神器啊
- [LitCTF 2023]snake
- 【JavaWeb】XML Tomcat10 HTTP
- node-red实现ModBus-RTU 通信协议(RS485信号输出)的数据交互
- Python绘制一个简单的圣诞树
- 构建Wiki中文语料词向量模型(python3)
- wireshark抓包分析网络延迟
- mysql 自动生成随机数
- 常用Java代码-Java中的注解处理器(Annotation Processing)
- 曼哈顿距离+蛇形走位