机器学习 -- 数据预处理
发布时间:2023年12月29日
系列文章目录
未完待续……
目录
前言
tips:这里只是总结,不是教程哈。
以下内容仅为暂定,因为我还没找到一个好的,让小白(我自己)也能容易理解(更系统)的讲解顺序!
一、数值分析简介
咱们根据机器学习的流程来吧
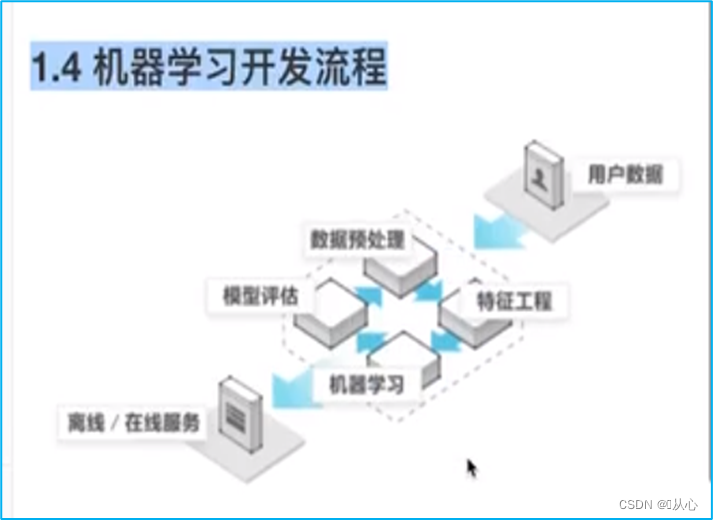
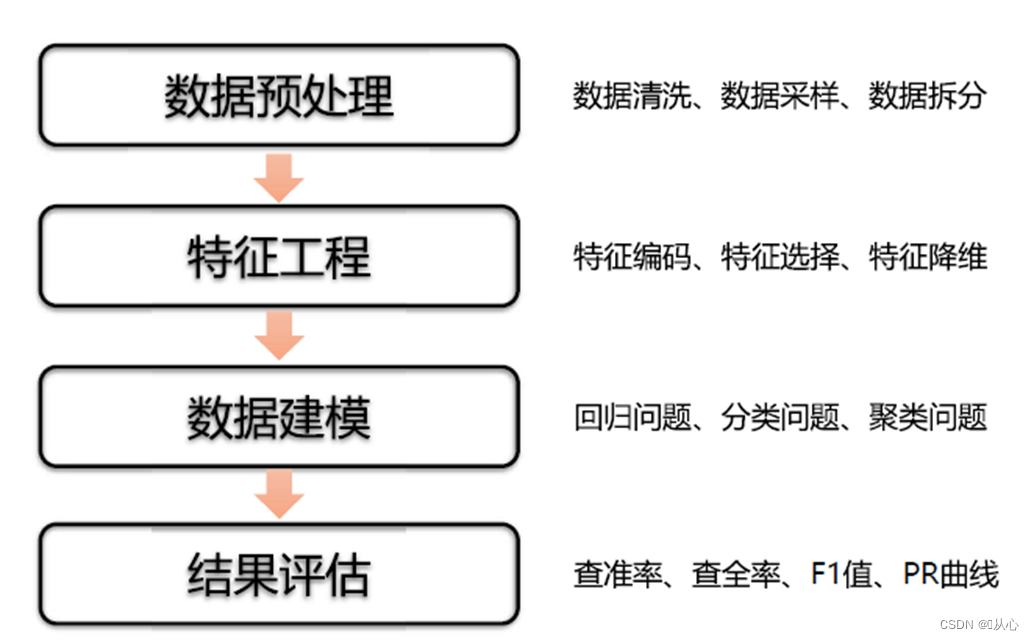
咱们要进行机器学习首先需要数据,以及对数据进行预处理。
数据获取:获取数据途径多种多样。
数据清洗:有无缺失值,有无异常数据等。
数据拆分:机器学习的数据集划分一般分为两个部分:
????????训练数据:用于训练,构建模型。一般占70%-80%(数据量越大,取得比例最好越大)
????????测试数据:用于模型评估,检验模型是否有效。一般占20%-30%
二、数据获取
睡觉了睡觉了,明天再写
三、数据清洗
四、数据拆分
1、近似值
该处使用的url网络请求的数据。
2、内容
该处使用的url网络请求的数据。
3、思维方式
该处使用的url网络请求的数据。
4、根本课题
该处使用的url网络请求的数据。
1.1、嗡嗡嗡
嗡嗡嗡
1.2、十五万
嗡嗡嗡
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
文章来源:https://blog.csdn.net/zqx1473/article/details/135280575
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 用于从未配对的3D医学图像中进行多模式分割的统一生成对抗性网络
- 参考文献管理软件EndNoter mac特点和功能
- ubuntu安装ssh
- 力扣-34. 在排序数组中查找元素的第一个和最后一个位置
- 【elfboard linux开发板】4. 文件点灯与创建多进程
- js 中的预解析
- centos7安装node-v18版本
- 本来以为 AI 生成视频没什么想象空间了
- REVIT二次开发 自动门窗墙体标注
- 学校和老师如何制作自己免费的成绩查询系统