Transformer热门魔改方案汇总!大大提升模型速度与效果!
随着序列长度的增加,Transformer中注意力机制的计算量会持续上升,导致计算代价较高。
不过为了解决这个问题,业内也出现了许多针对Transformer的魔改,这里给大家整理了Transformer魔改的方案论文,大家可以学习一下。
1、Longformer: The Long-Document Transformer
Longformer:长文档转换器
简述:本文中提出了Longformer,一种具有线性扩展注意力机制的模型,能够高效处理超长序列,它将局部窗口注意力与全局注意力相结合,可作为标准自注意力的替代。在字符级语言建模上,Longformer达到了最佳性能,并通过预训练和微调在多个长文档任务中超过了RoBERTa,刷新了WikiHop和TriviaQA的记录。此外研究人员还开发了Longformer的变体LED,适用于长文档的生成任务。
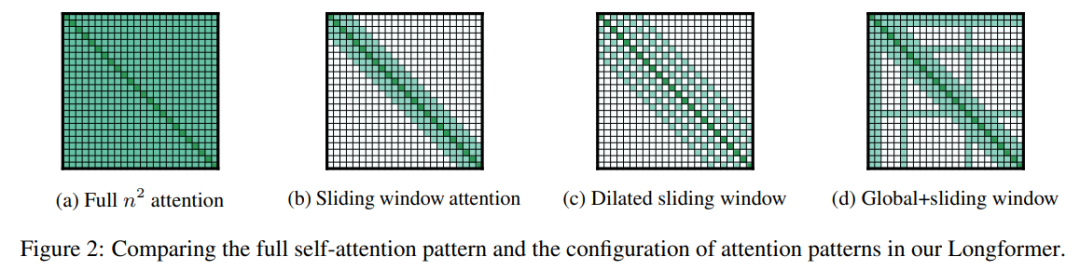
2、Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Transformer-XL:超越固定长度上下文的专注语言模型
简述:本文中提出了一种新的神经架构Transformer-XL,能够学习超过固定长度的依赖并解决上下文碎片问题。它通过新颖的段级递归和位置编码机制,显著提升了对长期依赖的捕捉能力,性能超越了传统的RNN和Transformer模型,并且还能生成长篇且连贯的文本内容。
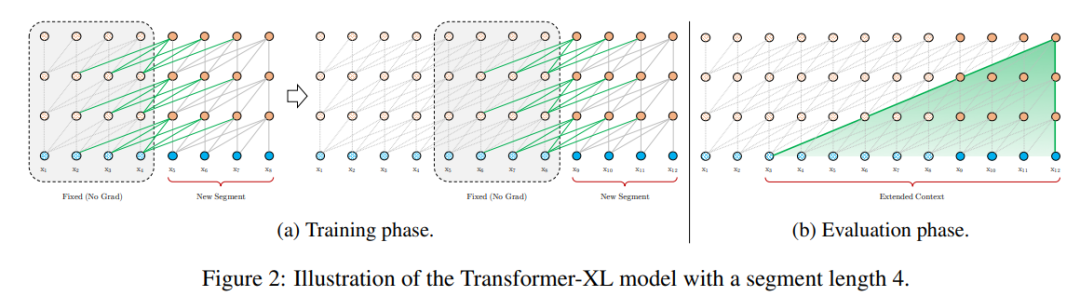
3、Efficient Long-Range Transformers: You Need to Attend More, but Not Necessarily at Every Layer
高效的远程变压器:需要更多关注,但不一定在每一层
简述:本文中提出了MASFormer,一种混合注意力跨度的Transformer变体,它通过在部分层上集中捕获远程依赖关系,而在其他层上采用稀疏注意力处理近程依赖,这种设计在自然语言处理任务上以更低的计算成本(减少高达75%)实现了与传统Transformer相媲美的性能。
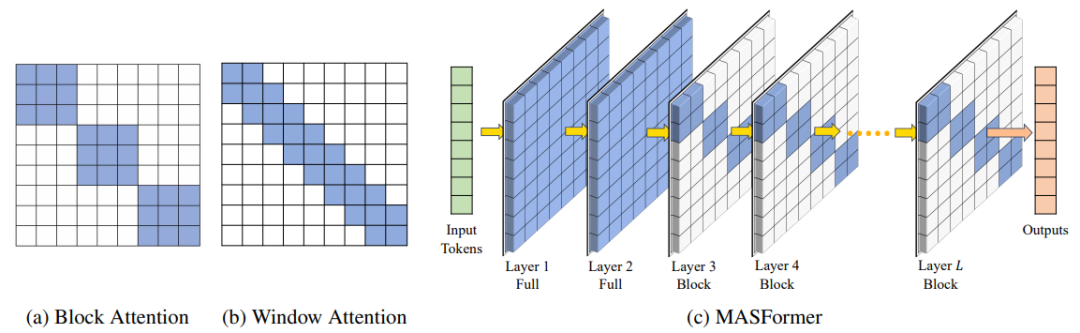
4、REFORMER: THE EFFICIENT TRANSFORMER
Reformer:?高效的变压器
简述:本文中引入了两项技术来提高Transformer的效率,使用局部敏感哈希替换点积注意力,将复杂性从O(L2)更改为O(LlogL),其中L是序列的长度,还使用可逆残差层,减少激活存储次数。结果得到的模型Reformer,在处理长序列时性能优异,且内存效率更高、速度更快。
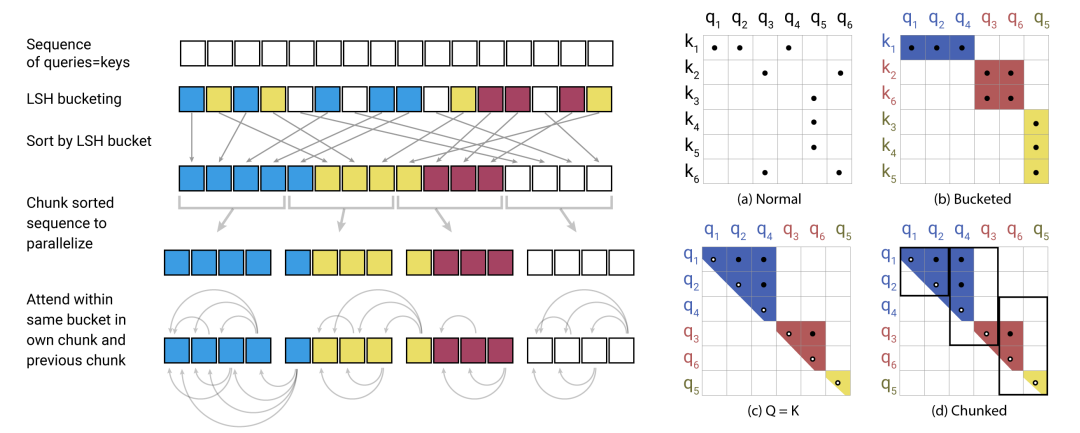
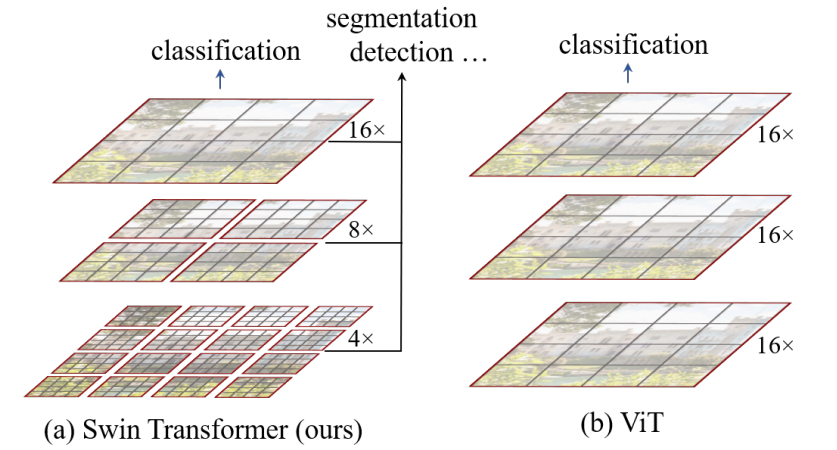
5、Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin Transformer:使用移位窗口的分层视觉转换器
简述:本文中提出了Swin Transformer,一种基于分层和移位窗口机制的Transformer模型,通过在不重叠的本地窗口内计算自注意力,并允许跨窗口连接,实现了高效率和灵活性。这种结构对图像大小的计算复杂度是线性的,可广泛适用于图像分类、对象检测和语义分割等视觉任务,且性能显著超过现有最先进技术。
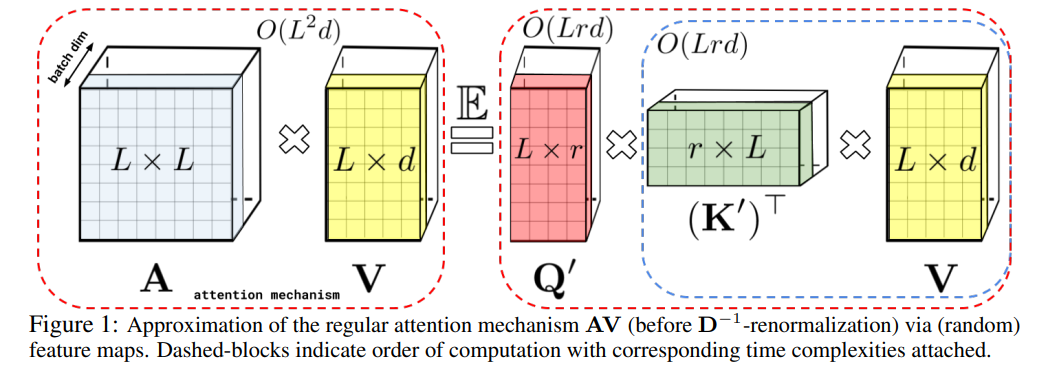
6、RETHINKING ATTENTION WITH PERFORMERS?
重新思考Performers的注意力
简述:本文中提出了Performers,一种线性 Transformer 架构,能够高效估计常规 softmax 全秩注意力,同时仅需线性空间和时间复杂度。为了近似 softmax 核,Performers 采用 FAVOR+ 方法,该方法对可扩展核方法具有价值。此架构与常规 Transformer 兼容,具有强大的理论保障,并且在多种任务上表现出色,证明了其新型注意力机制的有效性。
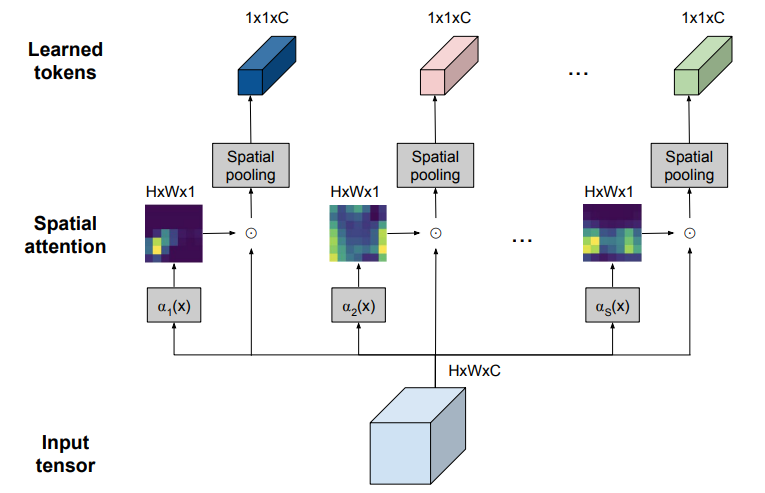
7、TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?
TokenLearner:8个学习令牌能为图像和视频做些什么?
简述:本文提出一种新的视觉表示学习方法TokenLearner,它依赖于自适应学习的少量标记,适用于图像和视频理解任务。这种方法能够自主学习并挖掘关键的视觉标记,有效识别重要视觉信息,并处理标记之间的注意力关系。在图像和视频识别的多个基准测试中,该方法显示出了强大的性能,并且在大幅降低计算成本的同时,仍保持了与最新技术相比的竞争力。
8、Linformer: Self-Attention with Linear Complexity
Linformer:具有线性复杂性的自注意力
简述:该文论证了Transformer的自注意力机制可以用低秩矩阵近似,并提出了一种新的自注意力机制Linformer,该机制在时间和空间上将整体自注意力复杂度从$O(n^2)$降低到$O(n)$,在性能上可与传统Transformer媲美,同时更节省内存和时间。
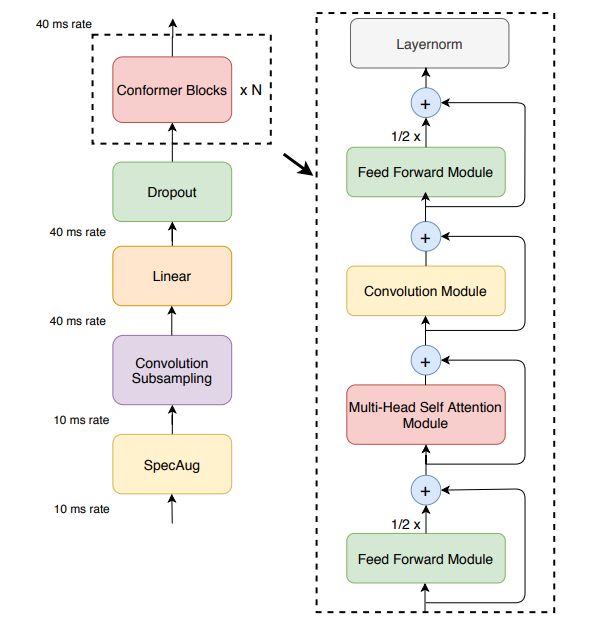
9、Conformer: Convolution-augmented Transformer for Speech Recognition
Conformer:用于语音识别的卷积增强型Transformer
简述:本文中提出了Conformer,一个用于语音识别的卷积增强Transformer,它在性能上显著超越了之前的Transformer和CNN模型,达到了最高精度。在LibriSpeech测试中,Conformer模型无语言模型时WER为2.1%/4.3%,有语言模型时为1.9%/3.9%,而10M参数的小模型也达到了2.7%/6.3%的竞争性WER。
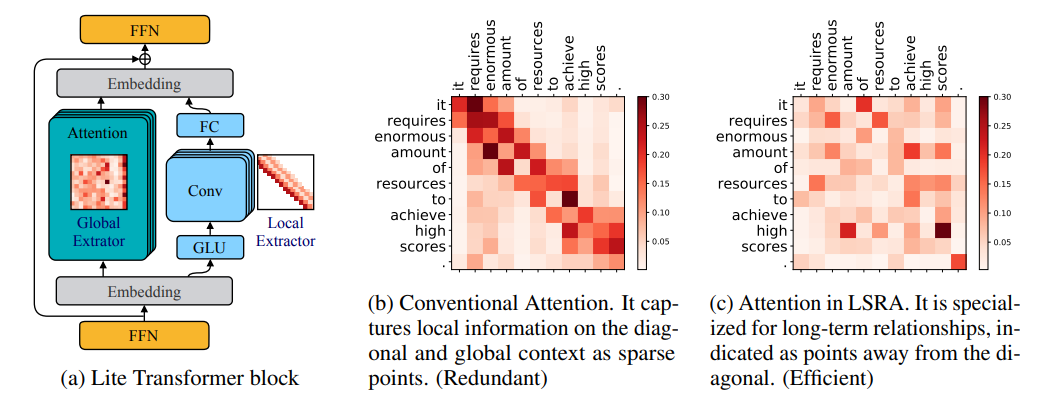
10、LITE TRANSFORMER WITH LONG-SHORT RANGE ATTENTION
轻量级Transformer与长短时注意力机制
简述:本文中提出了Lite Transformer,一种为移动设备设计的高效NLP架构,通过长短距离注意力机制有效处理不同范围的信息,显著提高了机器翻译、摘要生成和语言建模的性能。在资源有限的情况下,它的性能超越了传统Transformer,计算量减少了2.5倍,模型大小经过压缩后减少了18.2倍,同时语言建模困惑度更低,且无需耗费大量GPU资源进行架构搜索。
码字不易,欢迎大家点赞评论收藏!
关注下方《享享学AI》
回复【GNN】获取完整论文
👇
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【BI】FineBI功能学习路径-20231211
- 企业公司门户网站联系我们页设计(html+css静态实现,响应式布局,带源码)
- Java Stream 比较两个 List 的差异,并取出不同的对象
- 【每日一题】2719. 统计整数数目-2024.1.16
- 外贸SaaS软件功能有哪些?
- Loki日志多行显示
- 使用人工智能优化常见业务流程
- 网站后台拿Webshell
- cmake 打印日志命令
- [VASP learning]用MS绘制矩形格子石墨烯