机器学习的数据管理
.机器学习的数据管理注意事项
机器学习的生命周期包括如下部分
(1).业务的理解,机器学习问题框架
(2).数据理解和收集
(3).模型的训练和评估
(4)模型部署
(5).模型监控
(6).业务衡量
数据管理和机器学习的生命周期的2,3,4个阶段有关。
我们需要对数据进行分析,一般是分析数据的相关性,数据的统计,数据的分布,一般有下面这下内容
(1).进行数据验证,检测错误数据,验证数据质量。比如数据的范围,数据分布,数据类型或者空缺值。
(2).执行数据清洗以修复数据错误
(3).充实数据,通过不同的数据集的连接或者数据转换产生新的信号
再模型的训练和验证阶段,需要为正式的模型模型创建训练和验证数据集
在调用模型已部署的模型时,将特征处理所需要的数据作为输入数据的一部分提供
在调用已部署的模型时,提供预先计算的特征作为输入的一部分。
2.机器学习的数据管理架构
1.对于一个小型的机器学习项目,可以考虑使用简单的数据管理架构模式,这种模式一般有固定的数据管道。
从数据仓库或者其他数据集中提取固定的特征,然后经过数据提取工具储存到项目的数据储存区,最后进行机器学习项目。
2.对于一个大型的机器学习项目,就需要一个大型的架构方式,因为这样的机器学习项目,往往需要从各处抽取数据资源,这样的数据可能是结构化的,也可能是非结构化的,也可能是半结构化的,表格,图像,文本,都有可能是项目所需要的数据。
一般的架构如下所示????????
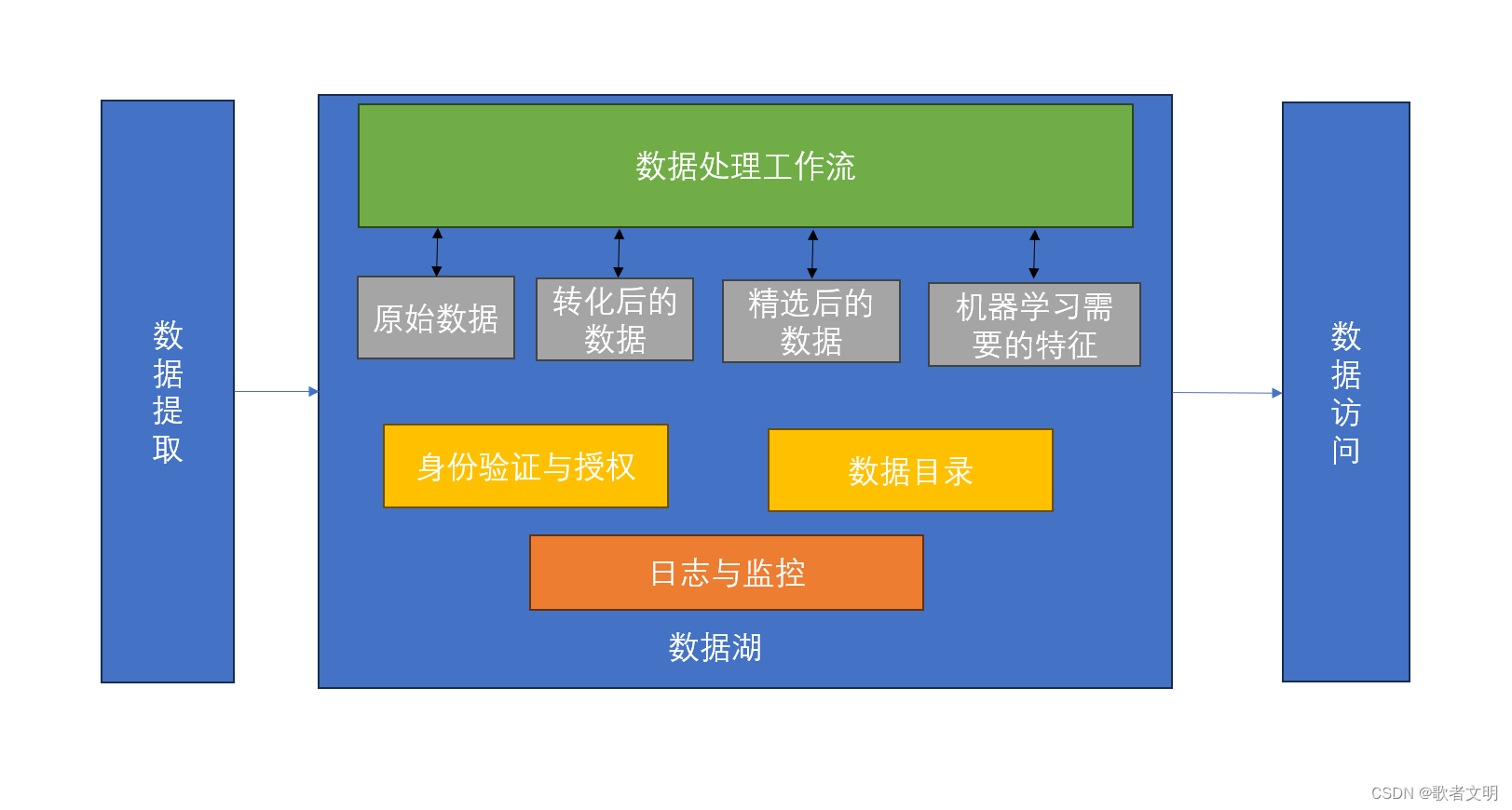
数据湖旨在存储无限量的数据并在不同的生命周期阶段进行管理。数据湖的主要目的是将不同的数据孤岛整合到一个中心存储库中,用于集中数据管理和数据访问,以满足分析需求和机器学习需求。
3.数据提取
数据提取需要注意以下几个事项
1.数据格式,数据大小和可扩展性,考虑到不同的数据格式,数据大小,和数据速度的需求;
2.提取模式,因为数据类型的一样,或者任务很复杂,有时候需要组合不同的提取工具。
3.数据的预处理能力,提取的数据可能需要进行预处理
4.安全性,选择的工具是否需要身份认证和授权提供安全机制
5.可靠性.这些工具需要提供故障恢复能力,以便再提取过程中不会丢失关键数据,如果没有恢复能力,请确保数据来源重新运行提取作业的功能。
6.支持不同的数据源和目标,提取工具需要支持广泛的数据源,比如数据库,文件和流式源,该工具还应该提供用于数据提取的API
7.可管理性:可管理型应该是另一个考虑因素,该工具是否自我管理,还是完全托管?需要综合考虑成本。
4.数据目录
数据目录是数据管理的关键组件,它使得数据分析师能够轻松发现中央数据存储的数据。
数据目录记录要考虑以下几个关键因素
(1).元数据目录:支持元数据管理的中央数据目录。
(2).自动数据编目:自动发现和编目数据集从不同数据源推断数据模式的能力。
(3).标记的灵活性
(4).与其他工具集成
(5).搜索
5.数据处理
数据湖的数据处理能力提供了数据处理框架和底层计算资源来处理不同目的的数据,比如数据纠错,数据转换,数据合并,数据拆分,数据合并,和机器学习特征工程
它需要考虑以下几个关键因素
(1).与底层存储技术的集成和互操作性:能够与底层储存进行原生协同工作的能力,这简化了数据访问和加载,移动。
(2).与数据目录集成的能力:可以和数据目录交互,查找数据
(3).可扩展性:根据数据量调整计算资源
(4).语言和框架的支持:可以使用各种编程语言和框架
6.数据版本控制
对转化或者提取后的数据根据需要控制版本,这就有赖于协调了。
7.数据管道
对数据的处理,转化,提取按照自动化的流程进行的工具,这是一项集成任务。
8.身份授权和验证
9.数据治理
数据据治理可确保数据资产受到资产受到信任,保护和分类,并且对它的访问进行监控和审计。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++经典排序算法
- 华为ospf和ospfv3双栈简单配置
- Java中通过字节流和异或运算实现简单的文件加密
- PCB设计规范及技巧顺口溜100句
- Qt屏蔽输出流技巧
- 19、生成对抗网络:基础+实战(训练一个基本的GAN模型)
- x-cmd pkg | nmap - 网络探测和安全审计工具
- 再见 Pip 和 Conda!Poetry是 Python 依赖管理的更好选择!
- 全解析阿里云Alibaba Cloud Linux镜像操作系统
- C++模板