张泽鹏:用PostgreSQL征服24点扑克牌算法的数据库高手

参赛选手:张泽鹏
个人简介:杭州隐函科技有限公司联创,技术负责人
参赛数据库:PostgreSQL
性能评测:百万级数据代码性能评测 2.46秒
综合得分:82.2
以下是张泽鹏选手的代码说明思路简介:
本算法用了取巧的方法:提前计算好4个1~10数值求24的结果,执行查询时,直接通过特征向量来查询;思路类似于“相似图片搜索”,先提前计算好图片库中每张图片的特征向量,后续通过特征向量做相似搜索即可。
算法原理
1. 预计算:因为`result`中数值的顺序无关,因此先对`10 ^ 4 = 10000`个数组做无序去重,获得715个顺序无关的数组;经过计算可得715中只有566个组合能计算出`24`。
2. 将这566个公式预置在SQL文件中,即代码中的`expressions(result)`。
3. 提取公式的特征向量
4. 得知最终测试数据集内会包含重复的题目(即c1、c2、c3、c4)会有相同,这些相同的题目只计算一次。即代码中`rounds(ids, c1, c2, c3, c4)`。
5. 用相同的方法,计算`rounds`中每道题目的特征向量,即代码中的`rounds_features(ids, features)`。
6. 然后根据特征向量,`rounds_features`从`results`中匹配出结果,并展开得到每道题目的结果`cards_results(id, result)`。
7. 最后与原始表`left join`获得最终结果。
以下是张泽鹏选手的算法说明,结尾附完整SQL:
算法说明
1. 文档概述
本文是 NineData 主办的数据库编程大赛页面「用一条 SQL 给出扑克牌 24 点的计算表达式」的解题思路。我本地测试的数据库为 PostgreSQL 16.1。
2. 比赛规则
根据题目描述可知:有一张表 cards,包括自增的数字主键字段 id,以及另外 4 个字段 c1、c2、c3、c4,且这四个字段的取值范围是1 → 10之间任意整数。要求使用一条 SQL 给出这四个字段计算 24 的公式。示例如 Table 1 所示:
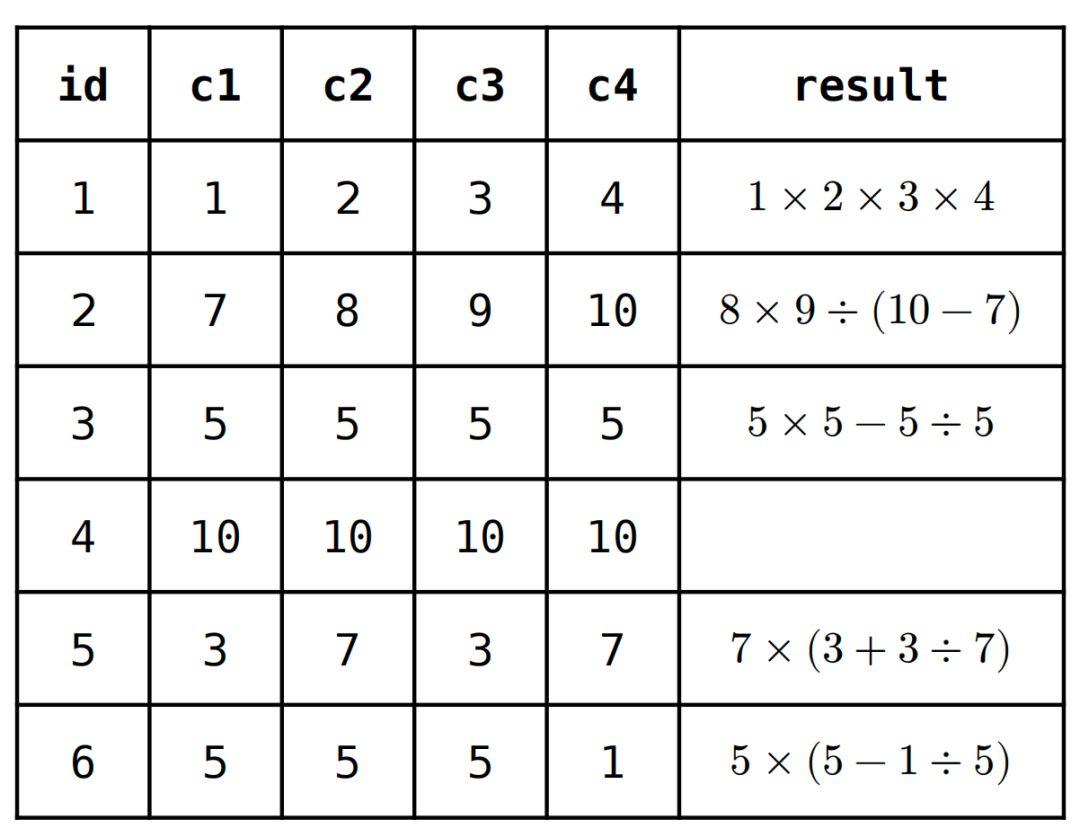
Table 1: 测试数据示例
其中:
? result 字段是计算的表达式,只需返回 1 个解,如果没有解,result 返回 null。
? 24 点的计算规则:只能使用加减乘除四则运算,不能使用阶乘、指数等运算符,每个数字
最少使用一次,且只能使用一次,可以使用小括号改变优先级。
? 只能使用一条 SQL,可以使用数据库内置函数,但是不能使用存储过程或自定义函数和代码块。
根据上述题目要求,首先在本地创建一张测试表。代码如下:
create schema if not exists poker24;
create table if not exists poker24.cards (
?id serial primary key,
?c1 int not null,
?c2 int not null,
?c3 int not null,
?c4 int not null
);仅根据题目描述,我原以为本次比赛的测试数据最多就104 = 10000行,但在比赛的答疑群里得知,初赛的测试数据量会超过 1 万行(即有重复的数据),而决赛的测试数据量甚至会超过100 万行。因此,生成测试数据时也需要生成一些重复的数据。以下代码共生成 128 万行测试数据:
create schema if not exists poker24;
insert into poker24.cards (
?c1, c2, c3, c4
)
select
?t1.c as c1,
?t2.c as c2,
?t3.c as c3,
?t4.c as c4
from
?generate_series(1, 10) as t1(c),
?generate_series(1, 10) as t2(c),
?generate_series(1, 10) as t3(c),
?generate_series(1, 10) as t4(c); -- 1W
insert into poker24.cards (c1, c2, c3, c4) select c1, c2, c3, c4 from poker24.cards;
-- 2W
insert into poker24.cards (c1, c2, c3, c4) select c1, c2, c3, c4 from poker24.cards;
-- 4W
insert into poker24.cards (c1, c2, c3, c4) select c1, c2, c3, c4 from poker24.cards;
-- 8W
insert into poker24.cards (c1, c2, c3, c4) select c1, c2, c3, c4 from poker24.cards;
-- 16W
insert into poker24.cards (c1, c2, c3, c4) select c1, c2, c3, c4 from poker24.cards;
-- 32W
insert into poker24.cards (c1, c2, c3, c4) select c1, c2, c3, c4 from poker24.cards;
-- 64W
insert into poker24.cards (c1, c2, c3, c4) select c1, c2, c3, c4 from poker24.cards;
-- 128W3. 算法设计
3.1. 去除重复数据
从前文的已知条件可知,公式中数值的顺序并不固定。例如 Table 1 中“第 2 行”,数值顺序是“7”、“8”、“9”、“10”;但公式中数值出现的顺序是“8”、“9”、“10”、“7”。同时,
前文也明确提到测试数据中会有重复的记录,如果每行数据都要计算,会增加许多冗余的计算。因此,可以按排序后的数据——sorted([c1, c2, c3, c4])——做分组,每组只计算一次,可以避免重复的计算。代码如下:
with numbers(id, number) as ( -- 行转列
?select id, c1 as number from poker24.cards
?union all
?select id, c2 from poker24.cards
?union all
?select id, c3 from poker24.cards
?union all
?select id, c4 from poker24.cards
), rounds as (
?select
?id,
?array_agg(number order by number) as numbers -- 聚合成数组时做排序
?from
?numbers
?group by
?id
), rounds_numbers as (
?select
?array_agg(id) as ids, -- 聚合有相同数值的记录
?numbers
?from
?rounds
?group by
?numbers
)
执行 select count(*) from rounds_numbers 的结果如下:
?count
-------
?715
(1 行记录)即分组后记录数量从 128 万行下降到 715 行。
3.2. 运算数(operand)排列
首先通过排列算法生成4! = 24种运算数的组合。即:
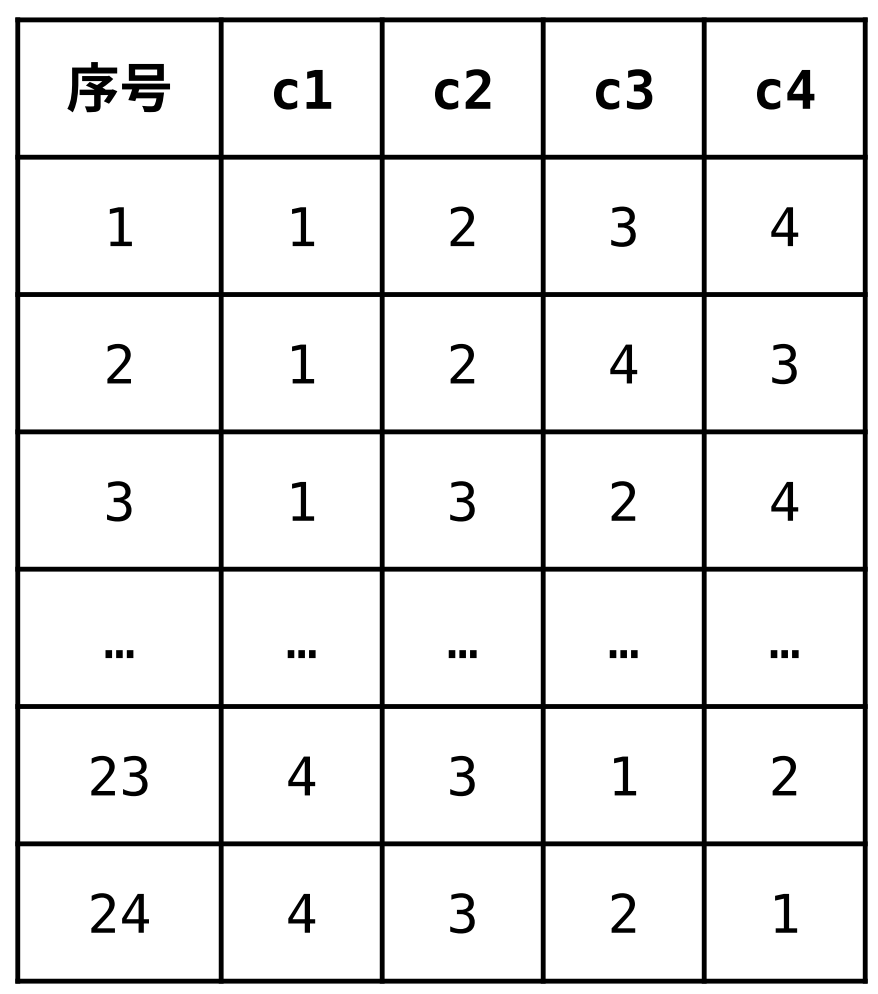
Table 2: 4 个数值的排列
因为组合数量比较少,可以直接手工罗列所有的排列。代码如下:
-- 接前文代码
, permutations as (
?select * from (values
?(ARRAY[1, 2, 3, 4]), (ARRAY[1, 2, 4, 3]), (ARRAY[1, 3, 2, 4]),
?(ARRAY[1, 3, 4, 2]), (ARRAY[1, 4, 2, 3]), (ARRAY[1, 4, 3, 2]),
?(ARRAY[2, 1, 3, 4]), (ARRAY[2, 1, 4, 3]), (ARRAY[2, 3, 1, 4]),
?(ARRAY[2, 3, 4, 1]), (ARRAY[2, 4, 1, 3]), (ARRAY[2, 4, 3, 1]),
?(ARRAY[3, 1, 2, 4]), (ARRAY[3, 1, 4, 2]), (ARRAY[3, 2, 1, 4]),
?(ARRAY[3, 2, 4, 1]), (ARRAY[3, 4, 1, 2]), (ARRAY[3, 4, 2, 1]),
?(ARRAY[4, 1, 2, 3]), (ARRAY[4, 1, 3, 2]), (ARRAY[4, 2, 1, 3]),
?(ARRAY[4, 2, 3, 1]), (ARRAY[4, 3, 1, 2]), (ARRAY[4, 3, 2, 1])
?) as t(indices)
), operands as (
?select
?distinct
?ids,
?ARRAY[
?numbers[indices[1]],
?numbers[indices[2]],
?numbers[indices[3]],
?numbers[indices[4]]
?] as numbers
?from
?rounds_numbers,
?permutations
)3.3. 运算符(operator)组合
有了 4 个运算数,需要再填充中间 3 个运算符(operator),每个运算符只能使用四则运算(加减乘除),即43 = 64种组合。生成运算符的代码如下:
-- 接前文代码
, operators as (
?select
?ARRAY[o1.sign, o2.sign, o3.sign] as signs
?from
?unnest(ARRAY['+', '-', '*', '/']) as o1(sign),
?unnest(ARRAY['+', '-', '*', '/']) as o2(sign),
?unnest(ARRAY['+', '-', '*', '/']) as o3(sign)
)3.4. 优先级(priority)枚举
通过加小括号改变运算符优先级,可以产生以下 5 种计算顺序:
1. ((𝐴 ° 𝐵) ° 𝐶) ° 𝐷
2. (𝐴 ° (𝐵 ° 𝐶)) ° 𝐷
3. (𝐴 ° 𝐵) ° (𝐶 ° 𝐷)
4. 𝐴 ° ((𝐵 ° 𝐶) ° 𝐷)
5. 𝐴 ° (𝐵 ° (𝐶 ° 𝐷))
直接在代码中描述括号的位置比较困难,所以我用一个长度为 3 的数组 priorities 记录第 i
次运算时,计算第 priorities[i]个运算符。例如表达式(𝐴 ° 𝐵) ° (𝐶 ° 𝐷):
? 第 1 次计算,计算𝐴 ° 𝐵,得到结果𝑅1;其中°是当前表达式 (𝐴 ° 𝐵) ° (𝐶 ° 𝐷) 中是第 1 个运算符,因此数组 priorities[1] = 1。
? 第 2 次计算,计算𝐶 ° 𝐷,得到结果𝑅2;其中°是当前表达式 𝑅1
° (𝐶 ° 𝐷) 中是第 2 个运算符,因此数组 priorities[2] = 2。
? 第 3 次计算,计算𝑅1
° 𝑅2,得到结果𝑅3;其中°是当前表达式 𝑅1
° 𝑅2 中是第 1 个运算符,因此数组 priorities[3] = 1。
综上所述,表达式 (𝐴 ° 𝐵) ° (𝐶 ° 𝐷) 的优先级数组是 ARRAY[1, 2, 1]。5 种优先级的数组表达式如下:
? ((𝐴 ° 𝐵) ° 𝐶) ° 𝐷:ARRAY[1, 1, 1]。
? (𝐴 ° (𝐵 ° 𝐶)) ° 𝐷:ARRAY[2, 1, 1]。
? (𝐴 ° 𝐵) ° (𝐶 ° 𝐷):ARRAY[1, 2, 1]。
? 𝐴 ° ((𝐵 ° 𝐶) ° 𝐷):ARRAY[2, 2, 1]。
? 𝐴 ° (𝐵 ° (𝐶 ° 𝐷)):ARRAY[3, 2, 1]。
对应的代码如下:
-- 接前文代码
, priorities(orders) as (
?select ARRAY[1, 1, 1]
?union all
?select ARRAY[2, 1, 1]
?union all
?select ARRAY[1, 2, 1]
?union all
?select ARRAY[2, 2, 1]
?union all
?select ARRAY[3, 2, 1]
)3.5. 计算表达式
运算数、运算符,以及运算顺序都准备就绪后,如前文描述,接着按照 priorities 的顺序逐一执行运算。迭代逻辑如下:
?迭代初始化:
? 需要先整数类型的数值数组 numbers float[]转换成浮点数类型,避免除法运算丢失精度。
? 同时生成数值数组对应的字符串数组 terms text[],用于后续生成表达式字符串。
? 迭代 3 轮,第 i 轮迭代时:
? 弹出运算符 operator:signs[orders[i]]。
? 弹出第一个运算数 operand1:numbers[orders[i]]。
? 弹出第二个运算数 operand2:numbers[orders[i] + 1]。
? 若 operator 是除法且 operand2 为零,则返回 null。
? 否则,计算结果并写回到运算数 numbers[orders[i]]。
? 弹出第一个表达式 expression1:terms[orders[i]]。
? 弹出第二个表达式 expression2:terms[orders[i] + 1]。
? 将表达式'(' || expression1 || operator || expression2 || ')'写回到terms[orders[i]]。
? 继续下一轮迭代,直到结束。
虽然 SQL 语法未提供 for、while 等循环语句,但可以使用递归的 CTE 模拟循环。代码如下:
-- 接前文代码
, expressions (ids, level, numbers, signs, orders, terms) as (
?select
?ids,
?4 as level,
?numbers::float[] as numbers,
?signs,
?orders,
?numbers::text[] as terms
?from
?operands,
?operators,
?priorities
?union all
?select
?ids,
?level - 1 as level,
?case
?when signs[orders[1]] = '/' and numbers[orders[1] + 1] = 0 -- 除 0 情况特殊判断
?then null
?when signs[orders[1]] = '+' -- 加法运算
?then numbers[:orders[1] - 1]
?|| ARRAY[numbers[orders[1]] + numbers[orders[1] + 1]]
?|| numbers[orders[1] + 2:]
?when signs[orders[1]] = '-' -- 减法运算
?then numbers[:orders[1] - 1]
?|| ARRAY[numbers[orders[1]] - numbers[orders[1] + 1]]
?|| numbers[orders[1] + 2:]
?when signs[orders[1]] = '*' -- 乘法运算
?then numbers[:orders[1] - 1]
?|| ARRAY[numbers[orders[1]] * numbers[orders[1] + 1]]
?|| numbers[orders[1] + 2:]
?else
?numbers[:orders[1] - 1] -- 除法运算
?|| ARRAY[numbers[orders[1]] / numbers[orders[1] + 1]]
?|| numbers[orders[1] + 2:]
?end as numbers,
?signs[:orders[1] - 1] || signs[orders[1] + 1:] as signs, -- 移除运算符
?orders[2:], -- 移除运算顺序
?terms[:orders[1] - 1]
?|| ARRAY['('
?|| terms[orders[1]]
?|| signs[orders[1]]
?|| terms[orders[1] + 1]
?|| ')']
?|| terms[orders[1] + 2:]
?as terms -- 合成表达式
?from
?expressions
?where
?level > 1
?and numbers is not null
)3.6. 筛选结果
然后从上述计算结果中筛选出结果值是 24 的表达式。因为题目要求只展示一个结果,在
PostgreSQL 中可以使用 distinct on 快速过滤出第一个结果,完整代码如下:
-- 接前文代码
, results (ids, result) as (
?select
?distinct on (ids)
?ids,
?terms[1] as result
?from
?expressions
?where
?level = 1
?and numbers is not null
?and round(numbers[1] * 1000000.0) = 24000000
)4. 算法优化
在前文代码的基础上执行 select * from results 就能算出 24 的表达式,但计算过程非常耗
时。在我的电脑上,10000 行记录需要执行了 20 多秒,最终能得到 566 个表达式,如
Table 3 所示:
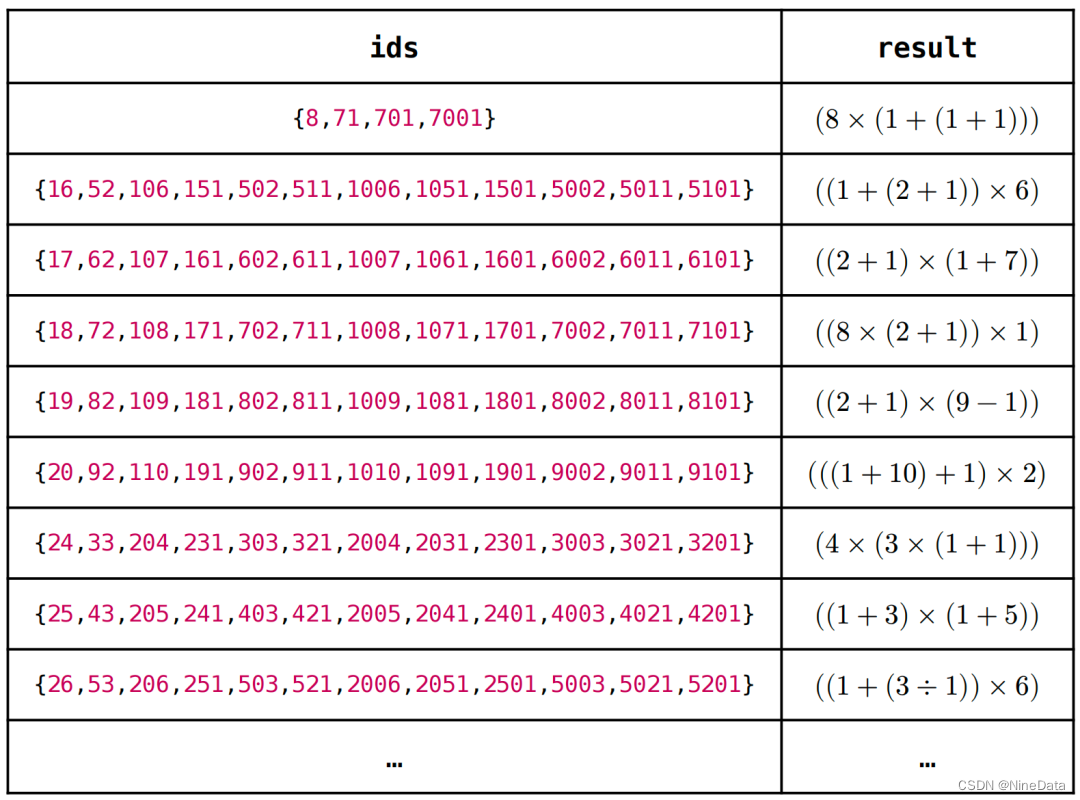
Table 3: 10000 行数据计算结果
4.1. 结果预置
经过验证,这 566 个表达式都正确,但性能非常糟糕,于是我想:如果直接把 566 个结果硬编码到代码里,性能是不是就能得到提升。尝试把这 566 个表达式输出到文件 results.txt中,用 du -bs results.txt 命令可知总共 8KB,符合题目中代码文件小于 10KB 的要求!通过移除多于的空格,例如((1 + (2 + 1)) × 6)可以精简成(1 + 2 + 1) × 6,最终文件尺寸缩减到5KB,这样就足够写剩余的代码了:
with results(result) as (values
?('8*10-7*8'),
?('8-8*(7-9)'),
?('8*9/(10-7)'),
?('8+(10-8)*8'),
?...
),4.2. 字符串型特征值
现在问题变成了如何把结果与 poker24.cards 里的记录匹配上。我想到了 PostgreSQL 有一个以图搜图的插件 imgsmlr,它会预先计算图片的特征向量,然后通过匹配特征向量来代替图片的搜索。这个技巧在落地算法模型时很常用,甚至还有专门为这个场景定制的向量数据库。
借鉴这个思路,可以对结果集和数据集做预处理,求出各自的特征向量,然后用特征向量了匹配即可。
根据前文的描述,很容易想到一个表达式的特征就是其中的 4 个运算数按顺序排列。例如((1 + (2 + 1)) × 6)的特征值是 ARRAY[1, 1, 2, 6]。为了方便后续 left join,需要选择一种方便做等值运算的数据类型保存这个特征值。我首先想到的是把这个数组转成用分号分隔的字符串,即"1;1;2;6"。
在 PostgreSQL 数据库中,可以先用 regexp_replace 函数剔除表达式中的括号,然后再用regexp_split_to_table 函数将运算符作为分隔符把表达式拆分成4 个子字符串,最后通过string_agg 窗口函数将子字符串排序后合并成特征值。代码如下:
-- 接前文代码
?
, results_terms as (
?select
?result,
?regexp_split_to_table(
?regexp_replace(result, '[()]+', '', 'g'),
?'[-+*/]'
?) as term
?from
?results
), results_features as (
?select
?result,
?string_agg(term, ';' order by term::int) as feature
?from
?results_terms
?group by
?result
?order by
?feature
)poker24.cards 中的数据也采用相同的方式做预处理,接着将两个结果集做 left join 得到最终结果。
4.3. 整型特征值
字符串型特征值在我本地执行,128 万行测试数据耗时 1 秒出头,所以我就没继续优化直接提交了。但在决赛服务器上评测结果是 2 秒多。为了进一步缩短时间,可以用整数类型代替字符串类型,毕竟整数的处理速度优于字符串。
在机器学习算法中,有一种独热编码的数据预处理技巧,用来预处理一些无序的枚举值。例如将性别的“男”和“女”分别编码成“01”与“10”。本题的运算数也是无序的,所以也可以借鉴这个思路,分别用“0”、“1”、“10”、“100”、……“10000000”、“100000000”代替“1”、“2”、“3”、“4”、……、“9”、“10”,然后将结果累加起来。例如 ARRAY[1, 1, 2, 6]编码成0 + 0 + 1 + 10000 = 10001。修改后的代码如下:
, results_terms as (
?select
?result,
?regexp_split_to_array(
?regexp_replace(result, '[()]+', '', 'g'),
?'[-+*/]'
?)::int[] as terms
?from
?results
), results_features as (
?select
?result,
?(ARRAY[0, 1, 10, 100, 1000, 10000, 100000, 1000000, 10000000, 100000000])
[terms[1]] +
?(ARRAY[0, 1, 10, 100, 1000, 10000, 100000, 1000000, 10000000, 100000000])
[terms[2]] +
?(ARRAY[0, 1, 10, 100, 1000, 10000, 100000, 1000000, 10000000, 100000000])
[terms[3]] +
?(ARRAY[0, 1, 10, 100, 1000, 10000, 100000, 1000000, 10000000, 100000000])
[terms[4]]
?as feature
?from
?results_terms
?order by
?feature
), cards_features as (
?select
?*,
?(ARRAY[0, 1, 10, 100, 1000, 10000, 100000, 1000000, 10000000, 100000000])[c1] +
?(ARRAY[0, 1, 10, 100, 1000, 10000, 100000, 1000000, 10000000, 100000000])[c2] +
?(ARRAY[0, 1, 10, 100, 1000, 10000, 100000, 1000000, 10000000, 100000000])[c3] +
?(ARRAY[0, 1, 10, 100, 1000, 10000, 100000, 1000000, 10000000, 100000000])[c4]
?as feature
?from
?poker24.cards
?order by
?feature
)
select
?cards_features.id,
?cards_features.c1,
?cards_features.c2,
?cards_features.c3,
?cards_features.c4,
?results_features.result
from
?cards_features
left join
?results_features
on
?cards_features.feature = results_features.feature其中有一个优化小技巧:results_features 与 cards_features 两张表都先按照求得的 feature排序,最终在 JOIN 的时候就会用 merge join 代替 nest loop,执行效率更高。经过优化后,128 万行测试数据在我电脑上之需耗时 0.7 秒。
5. 总结
本文详细地解释了我参与比赛时的解题过程,但由于能力有限,并且最近事情较多,并没有做过多的优化。希望有更优方案的小伙伴不吝赐教!
参赛完整SQL:
with expressions(result) as (values ('8*10-7*8'),('8-8*(7-9)'),('8*9/(10-7)'),('8+(10-8)*8'),('(1+1+1)*8'),('2*(1+10+1)'),('6*(2+1+1)'),('(1+2)*(1+7)'),('(2+1)*8*1'),('(9-1)*(2+1)'),('3*(10-1-1)'),('(1+1)*4*3'),('(3+1)*(5+1)'),('(3+1)*6*1'),('(1+7)*1*3'),('8*3*1*1'),('3*1*(9-1)'),('4+(1+1)*10'),('4*(4+1+1)'),('1*(1+5)*4'),('6*1*4*1'),('(7-1)*1*4'),('1*8*(4-1)'),('(1-9)*(1-4)'),('(5-1)*(5+1)'),('6*1*(5-1)'),('(1+1)*(7+5)'),('(5-1-1)*8'),('6*(6-1-1)'),('8*6/(1+1)'),('6+9*(1+1)'),('10+7*(1+1)'),('8+(1+1)*8'),('2*(2+10*1)'),('4*2*(1+2)'),('2*2*(5+1)'),('(2+2)*1*6'),('2*2*(7-1)'),('8*(2-1+2)'),('(9+1+2)*2'),('3+2*10+1'),('2*(1+3)*3'),('4*3*2*1'),('(2+5+1)*3'),('6*2*(3-1)'),('3*(7+2-1)'),('(2-1)*8*3'),('(3+9)*2*1'),('2*10+4*1'),('(2+4)*4*1'),('(2-1+5)*4'),('(6+2)*(4-1)'),('2*(1+4+7)'),('2*(8+4*1)'),('2*(4-1+9)'),('2*10+5-1'),('5*5+1-2'),('6*(5-2+1)'),('2*1*(7+5)'),('(8+5-1)*2'),('5+1+2*9'),('(2+1)*10-6'),('2*(6+1*6)'),('(6-2)*(7-1)'),('8*6/2*1'),('1*2*9+6'),('10+2*1*7'),('(7*7-1)/2'),('8*2+1+7'),('9+7*2+1'),('10-(1-8)*2'),('(8/2-1)*8'),('8*9/(1+2)'),('10+3+10+1'),('3*(10-3+1)'),('(3+1)*(3+3)'),('(3*1+3)*4'),('(1*5+3)*3'),('(6-1+3)*3'),('1*7*3+3'),('3+(8-1)*3'),('(3*9-3)*1'),('4-(1-3)*10'),('4*(3-1+4)'),('5*4+1+3'),('6/(1-3/4)'),('(1+3)*7-4'),('8/(4/3-1)'),('1-4+9*3'),('3*5+10-1'),('1+5+6*3'),('(3-1)*(5+7)'),('3*5+1+8'),('5*3+1*9'),('10*3*1-6'),('1*6*3+6'),('1*(7-3)*6'),('6*8/(3-1)'),('6+(3-1)*9'),('1-7+3*10'),('(3-7)*(1-7)'),('8*(7-1-3)'),('(1+7)*9/3'),('8/3*(10-1)'),('8/3*(8+1)'),('8*9*1/3'),('(10+1)*3-9'),('9*(9-1)/3'),('10+10+4*1'),('4*(10-4)*1'),('4+4*(1+4)'),('1*5*4+4'),('(6-1)*4+4'),('1*7*4-4'),('4*1*4+8'),('9-1+4*4'),('(10-4)*(5-1)'),('5*4+5-1'),('4/(1-5/6)'),('4*7-5+1'),('(8-4)*(5+1)'),('9+(4-1)*5'),('(4-1)*10-6'),('6-(1-4)*6'),('6*(7-4+1)'),('(8-4)*6*1'),('6*(9-1-4)'),('(7-4)*(1+7)'),('(7-4)*1*8'),('(4-7)*(1-9)'),('4*8*1-8'),('4*8+1-9'),('10+9+4+1'),('10+5-1+10'),('(10-5)*5-1'),('5*(5-1/5)'),('6*5-1-5'),('(9-5)*(5+1)'),('(1+5)*(10-6)'),('1*(6*5-6)'),('6*5+1-7'),('6*(1-5+8)'),('(9-5)*1*6'),('7*5-1-10'),('(1-5+7)*8'),('(7-1)*(9-5)'),('8+10+1+5'),('(5-1)*8-8'),('(5-8)*(1-9)'),('10+5+9*1'),('9+9+5+1'),('(1*10-6)*6'),('(6-1)*6-6'),('6/(1-6/8)'),('6*(1+9-6)'),('6*(10+1-7)'),('(7+1)*(9-6)'),('8+1*10+6'),('8*(8+1-6)'),('1+8+6+9'),('6+10+9-1'),('1*9+9+6'),('7*1+10+7'),('1+7+9+7'),('10+7-1+8'),('1+8+8+7'),('8*(1+9-7)'),('(9-1)*(10-7)'),('9-1+9+7'),('(1-8+10)*8'),('8*1+8+8'),('8-1+9+8'),('2+2+10+10'),('10*2+2+2'),('2*2*2*3'),('4*(2+2+2)'),('2*(2+2*5)'),('(2*7-2)*2'),('2*(2+8+2)'),('2+(9+2)*2'),('(3+10)*2-2'),('2*(3+3)*2'),('3*(2+4+2)'),('3*(5*2-2)'),('(6-2)*3*2'),('(2+7+3)*2'),('8*3*2/2'),('2*3+2*9'),('(4-2)*(10+2)'),('(2*4+4)*2'),('(2/2+5)*4'),('4*6-2+2'),('7*4-2-2'),('(8/2+2)*4'),('2+4+2*9'),('(5+2)*2+10'),('(5+2+5)*2'),('2+2*(5+6)'),('2*7+5*2'),('(5+8)*2-2'),('2*(5+9-2)'),('2+10+6*2'),('6*(2+6)/2'),('6+(7+2)*2'),('(8+6-2)*2'),('(9*2-6)*2'),('2*(10/2+7)'),('2*(7+7-2)'),('2+8+2*7'),('10*2+8/2'),('8*(8-2)/2'),('9*2+8-2'),('10-2*(2-9)'),('(10-3)*2+10'),('(10/2+3)*3'),('(2+3+3)*3'),('2*(5*3-3)'),('2*(3+6+3)'),('3*(3-2+7)'),('(3+3)*8/2'),('(9-3+2)*3'),('4*3+2+10'),('3*4/2*4'),('2*(3+4+5)'),('3*(6+4/2)'),('(7-3)*(2+4)'),('(8-4)*2*3'),('2/3*9*4'),('2*(10-3+5)'),('3*(5-2+5)'),('2*5*3-6'),('5+7*3-2'),('5+3+2*8'),('(2-5)+9*3'),('(10-2)*(6-3)'),('2*6/3*6'),('(6/2)+7*3'),('8+6*3-2'),('3+9+6*2'),('7+10*2-3'),('7+2*7+3'),('2*(7+8-3)'),('9-3*(2-7)'),('10+8+2*3'),('(8-3-2)*8'),('8*(9-2*3)'),('2+3+9+10'),('2*3+9+9'),('10*(4/10+2)'),('(4-2)*10+4'),('4*(4+4-2)'),('(5*2-4)*4'),('2+6+4*4'),('2*4*(7-4)'),('(8+4)*4/2'),('(9-2)*4-4'),('10+4+2*5'),('4+(5+5)*2'),('4*5+6-2'),('(7+5)/2*4'),('2*4*(8-5)'),('(2+4)*(9-5)'),('(2-6+10)*4'),('6*(6-4+2)'),('4+6+2*7'),('6*2/4*8'),('(9-6)*2*4'),('10+7*4/2'),('(7+7)*2-4'),('8/2*7-4'),('7+9+2*4'),('8+2+10+4'),('8-8*(2-4)'),('8*(9-4-2)'),('9*2-4+10'),('2+4+9+9'),('2*(10/5+10)'),('5*(5-2/10)'),('7*2+5+5'),('(5/5+2)*8'),('5+5*2+9'),('6*2*10/5'),('6*(5*2-6)'),('6*(7-5+2)'),('2+5*6-8'),('6*5/2+9'),('2+10+7+5'),('7+5*2+7'),('(5*2-7)*8'),('7*5-2-9'),('(10-5-2)*8'),('8*5-8*2'),('2*(9-5+8)'),('9+10*2-5'),('10+6+10-2'),('2+6+10+6'),('6+6*6/2'),('6*(7-6/2)'),('6*(2+8-6)'),('(6+2)*(9-6)'),('(10-7)*(6+2)'),('8*(2-6+7)'),('7+6+9+2'),('(6-10)*(2-8)'),('6+8+8+2'),('9*8*2/6'),('(10-2)*(9-6)'),('2*(9+9-6)'),('(10-7)*(10-2)'),('7*(10/7+2)'),('7+2+8+7'),('(8-7+2)*8'),('(9+7)*2-8'),('10-2+7+9'),('(10-8)*(10+2)'),('8+10-2+8'),('8*(8/8+2)'),('8*(9+2-8)'),('8*(10+2-9)'),('9+9+8-2'),('10/2+10+9'),('3+(10-3)*3'),('3*3*3-3'),('(3+4)*3+3'),('3*3+3*5'),('6*3+3+3'),('(7-3)*(3+3)'),('3*8*3/3'),('3*(9-3/3)'),('(3*4-4)*3'),('(5+4)*3-3'),('4*(3-3+6)'),('3*(4-3+7)'),('3*8*(4-3)'),('3+9+3*4'),('10+3*3+5'),('5*5-3/3'),('(6-3)*(3+5)'),('3*(5*3-7)'),('(5+3)/3*9'),('3*(10-6/3)'),('3*(6+6/3)'),('3-(3-6)*7'),('8*(6+3)/3'),('9-(3-3*6)'),('7*(3+3/7)'),('7+8+3*3'),('(3-7)*(3-9)'),('3+3+8+10'),('8/(3-8/3)'),('9-3*(3-8)'),('3+10*3-9'),('9+3+9+3'),('10*3-10+4'),('(10-3)*4-4'),('(3+4)*4-4'),('3+5+4*4'),('(6-4)*4*3'),('4*(3-4+7)'),('3*(4+8-4)'),('9*4-4*3'),('3*4/5*10'),('3*5+5+4'),('(5-4+3)*6'),('(5+7-4)*3'),('(3+5)*4-8'),('(9-5+4)*3'),('10-4+6*3'),('3*4+6+6'),('(4+8)/3*6'),('4*(9-6+3)'),('(7-3)*(10-4)'),('3-7+4*7'),('8-(3-7)*4'),('(7+4)*3-9'),('(8+10)*4/3'),('4+9+8+3'),('(9+9)*4/3'),('3*(10-10/5)'),('6*(3+5/5)'),('(7+5)*(5-3)'),('8*3*5/5'),('3*(9-5/5)'),('(10/5+6)*3'),('6*(6-5+3)'),('(5+7)/3*6'),('3*8*(6-5)'),('3*(9-6+5)'),('10-(3-5)*7'),('5*7-8-3'),('3+5+9+7'),('5+8+8+3'),('5-8+3*9'),('9+3*(10-5)'),('9+9*5/3'),('10*(3-6/10)'),('(6-3)*10-6'),('6*(3+6/6)'),('(6/6+7)*3'),('8*6*3/6'),('3+6+6+9'),('10+6*7/3'),('(7/7+3)*6'),('(8-7+3)*6'),('3*(6+9-7)'),('(6+10-8)*3'),('8+8/3*6'),('8*9/(6-3)'),('(3-9+10)*6'),('(9-6)*9-3'),('10-3+10+7'),('3*7-7+10'),('7+7+7+3'),('8*(3-7+7)'),('3*(9-7/7)'),('3*8*(8-7)'),('(7+9-8)*3'),('7-(10-9*3)'),('3*(7+9/9)'),('10*3/10*8'),('(10*8-8)/3'),('8*8*3/8'),('3*(9-8/8)'),('9+8+10-3'),('3*8+9-9'),('3*(9-10/10)'),('3*(9-10+9)'),('9+9+9-3'),('(10*10-4)/4'),('10*4-4*4'),('4+4*4+4'),('4*(5+4/4)'),('4*4/4*6'),('(7-4)*(4+4)'),('4*8-4-4'),('4-4*(4-9)'),('4+4*(10-5)'),('4*(5+5-4)'),('4*6*(5-4)'),('(7-5+4)*4'),('(4+4)*(8-5)'),('4+4+6+10'),('(6-4)*(8+4)'),('4*9*4/6'),('(10-7)*(4+4)'),('7*(4-4/7)'),('4*7-8+4'),('7+4+4+9'),('4*(10+4-8)'),('8+8+4+4'),('9*4-4-8'),('10/5*10+4'),('5+5+4+10'),('5*5-5+4'),('6*4*5/5'),('4*(7-5/5)'),('8*(4-5/5)'),('5*4-5+9'),('(10-6)+4*5'),('6*(6-5)*4'),('(6-4)*(5+7)'),('8*(4+5-6)'),('4+6+9+5'),('4+10*(7-5)'),('4*(7/7+5)'),('5+8+4+7'),('9-(4-7)*5'),('(4+8)*10/5'),('4*(8/8+5)'),('(9+5-8)*4'),('4*(5+10-9)'),('4*(9/9+5)'),('6*4*10/10'),('(10+6)/4*6'),('(6-6+6)*4'),('6*4*(7-6)'),('6+4+8+6'),('(9-4)*6-6'),('4*7+6-10'),('6+4+7+7'),('(6+4-7)*8'),('(7+9)/4*6'),('4+10*(8-6)'),('8*6/8*4'),('6+8/4*9'),('(10*9+6)/4'),('4*9/9*6'),('4*(7-10/10)'),('4*(7-7/7)'),('8*(4-7/7)'),('10+8*7/4'),('8*7-4*8'),('9*8/(7-4)'),('4-10*(7-9)'),('4*(7-9/9)'),('8+10-4+10'),('(8+4)*(10-8)'),('8*(4-8/8)'),('(8+4-9)*8'),('8*(9+4-10)'),('8*(4-9/9)'),('9-(4-9-10)'),('5*5-10/10'),('5*5-5/5'),('5-6+5*5'),('5+9+5+5'),('5*(6-6/5)'),('7*5-5-6'),('5+5+8+6'),('(5+7)/5*10'),('(5+7)*(7-5)'),('8*(5+5-7)'),('(10+5)*8/5'),('5*5-8/8'),('8-9+5*5'),('9+5*5-10'),('5*5-9/9'),('(10+10)*6/5'),('(6+6)*10/5'),('6*(5-6/6)'),('7+6+5+6'),('6+6*(8-5)'),('9*6-6*5'),('6*(5-7/7)'),('6*(5-8+7)'),('6+(7-5)*9'),('8*5-6-10'),('8*(6+5-8)'),('6*(8-9+5)'),('6*(9-10+5)'),('(9-6)*5+9'),('10+10*7/5'),('(7-5)*7+10'),('(7+5)*(9-7)'),('(10-8)*(5+7)'),('(7+8)*8/5'),('5*8-7-9'),('9+5*(10-7)'),('(5-10+8)*8'),('5*8-8-8'),('9*8/(8-5)'),('9+10-5+10'),('10+10+10-6'),('10*6-6*6'),('6+6+6+6'),('(6+6)*(8-6)'),('6+(9-6)*6'),('6-(7-10)*6'),('6*(7+6-9)'),('6*(8-10+6)'),('6*8/(8-6)'),('6-(6-8)*9'),('(10+6)*9/6'),('(10-7)*10-6'),('6*(7+7-10)'),('10-7*(6-8)'),('6*8/(9-7)'),('9/6*(9+7)'),('(10-6)*8-8'),('8+(8-6)*8'),('9*8-8*6'),('6-(8-10)*9'),('8*9/(9-6)'),('9+9*10/6'),('10-7*(7-9)'),('(10-8)*7+10')), vectors as (selectresult,regexp_split_to_table(regexp_replace(result, '[()]+', '', 'g'), '[-+*/]') as featurefromexpressions), results as (selectresult,string_agg(feature, ';' order by feature::int) as featuresfromvectorsgroup byresult), rounds as (selectarray_agg(id) as ids,c1, c2, c3, c4frompoker24.cardsgroup byc1, c2, c3, c4), rounds_cards as (select ids, c1 as feature from roundsunion allselect ids, c2 as feature from roundsunion allselect ids, c3 as feature from roundsunion allselect ids, c4 as feature from rounds), rounds_features as (selectids,string_agg(feature::text, ';' order by feature) as featuresfromrounds_cardsgroup byids), rounds_results as (selectrounds_features.ids,results.resultfromrounds_featuresinner joinresultsonrounds_features.features = results.features), cards_results as (select unnest(ids) as id, result from rounds_results)selectcards.*,cards_results.resultfrompoker24.cardsleft joincards_resultsoncards.id = cards_results.idorder by??cards.id;
数据库编程大赛
下一次再聚!
感谢大家对本次《数据库编程大赛》的关注和支持,欢迎加入技术交流群,更多精彩活动不断,我们下次再相聚!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【elfboard linux开发板】7.i2C工具应用与aht20温湿度寄存器读取
- 【内容管理系统】内容管理系统v1.0.0版本正式上线
- 寒假刷题第八天
- 抽象工厂模式(Abstract Factory)
- openssl3.2 - 官方demo学习 - signature - EVP_ED_Signature_demo.c
- CDMP认证与CDGA/CDGP的区别有哪些?
- OpenAI 网站上的关于 API 文档中各菜单的结构介绍
- vue ant v-decorator的使用
- 4G微型RTU如何实现冬季工业管网远程监测
- 【Python毕业设计源码】django个性化服装系统