YOLOv7-tiny,通过pycocotools包得到预测大中小尺寸目标的指标值
发布时间:2024年01月12日
参考链接
- 需要先在环境中安装
pycocotools
pip install pycocotools
-
一些概念上的了解:通过pycocotools获取每个类别的COCO指标
步骤
步骤很简单,但难在第一步:
- 得到待检测的数据集的
instances_val2017.json文件,参考魔鬼面具代码和视频即可(我直接使用起来有错,应该是因为数据集分布的问题) - 在
test.py里面定位到anno_json =,然后指明1得到的instances_val2017.json文件的位置(我是像下面那样直接指明的绝对位置)
anno_json = r'G:\pycharmprojects\autodl-yolov7\yolov7-main-biyebase\TXTOCOCO\instances_val2017.json'
- 在
test.py中定位到'--save-json', action='store_true',然后加上default=True,(加上就能检测大中小尺寸了,就算json文件格式不对也不会直接报错终止,但是不会出现结果)
认识正确的instances_val2017.json文件格式
圈起来的就是正确信息,如果annotations为0 items的话,那就说明转出来的json文件内容有误(下图格式是在AutoDL云服务器上看的,看起来比较清楚,本地上看就比较杂乱。之前一直我运行一直有错,就是因为没有转正确,我的image_id的value值写成了test/Czech_000037,有了test/就报错了)
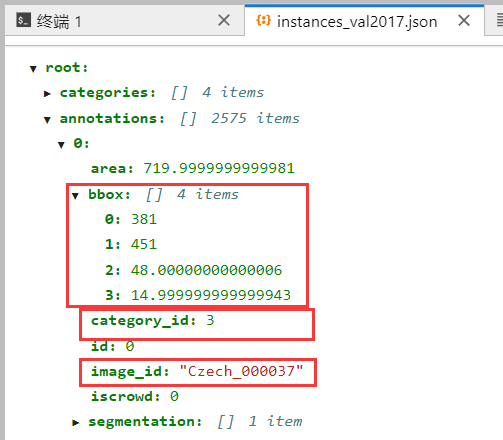
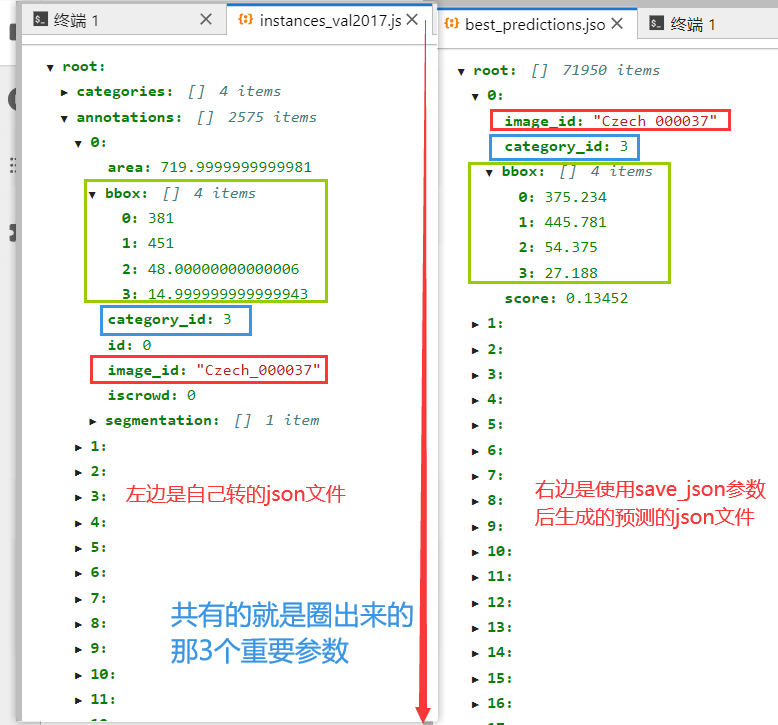
instances_val2017.json和best_predictions.json对比:
代码(mogui_tococo.py,用于我自己的数据集)
参考魔鬼面具的应该会没有错,以下是我针对我的数据集进行的一代你代码改动,留作备份
import os
import cv2
import json
from tqdm import tqdm
from sklearn.model_selection import train_test_split
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--root_dir', default='/home/hjj/Desktop/dataset/dataset_seaship', type=str, help="root path of images and labels, include ./images and ./labels and classes.txt")
parser.add_argument('--save_path', type=str, default='instances_val2017.json', help="if not split the dataset, give a path to a json file")
arg = parser.parse_args()
def yolo2coco(arg):
with open(r'G:\pycharmprojects\autodl-yolov7\yolov7-main-biyebase\TXTOCOCO\classes.txt', 'r') as f:
classes = list(map(lambda x: x.strip(), f.readlines()))
# --------------- lwd ---------------- #
cities = ['Czech', 'India', 'Japan']
indexes = []
for city in cities:
city_imagedir = f'F:/A_Publicdatasets/RDD2020-1202/train_valid/{city}/images/test'
for file in os.listdir(city_imagedir):
indexes.append(f'{city_imagedir}/{file}')
# --------------- lwd ---------------- #
dataset = {'categories': [], 'annotations': [], 'images': []}
for i, cls in enumerate(classes, 0):
dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'mark'})
# 标注的id
ann_id_cnt = 0
for k, index in enumerate(tqdm(indexes)):
# 支持 png jpg 格式的图片。
txtPath = index.replace('images', 'labels').replace('.jpg', '.txt')
# 读取图像的宽和高
im = cv2.imread(index)
imageFile = index.split('/')[-1] # img.jpg
height, width, _ = im.shape
# 添加图像的信息
if not os.path.exists(txtPath):
# 如没标签,跳过,只保留图片信息。
continue
dataset['images'].append({'file_name': imageFile,
'id': int(imageFile[:-4]) if imageFile[:-4].isnumeric() else imageFile[:-4],
'width': width,
'height': height})
with open(txtPath, 'r') as fr:
labelList = fr.readlines()
for label in labelList:
label = label.strip().split()
x = float(label[1])
y = float(label[2])
w = float(label[3])
h = float(label[4])
# convert x,y,w,h to x1,y1,x2,y2
H, W, _ = im.shape
x1 = (x - w / 2) * W
y1 = (y - h / 2) * H
x2 = (x + w / 2) * W
y2 = (y + h / 2) * H
# 标签序号从0开始计算, coco2017数据集标号混乱,不管它了。
cls_id = int(label[0])
width = max(0, x2 - x1)
height = max(0, y2 - y1)
dataset['annotations'].append({
'area': width * height,
'bbox': [x1, y1, width, height],
'category_id': cls_id,
'id': ann_id_cnt,
'image_id': int(imageFile[:-4]) if imageFile[:-4].isnumeric() else imageFile[:-4],
'iscrowd': 0,
# mask, 矩形是从左上角点按顺时针的四个顶点
'segmentation': [[x1, y1, x2, y1, x2, y2, x1, y2]]
})
ann_id_cnt += 1
# 保存结果
with open(arg.save_path, 'w') as f:
json.dump(dataset, f)
print('Save annotation to {}'.format(arg.save_path))
if __name__ == "__main__":
yolo2coco(arg)
文章来源:https://blog.csdn.net/LWD19981223/article/details/135550278
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 华为FusionStorage Block、OceanStor 100D、OceanStor pacific的区别
- RHCE9学习指南 第7章 服务管理
- 教育部:培育一批国家级专业教学资源库、示范性虚拟仿真实训基地
- Xfs文件系统磁盘布局
- 了解ASP.NET Core 中的文件提供程序
- Shell三剑客:awk(awk编辑编程)二
- Python爬虫-大麦网演出数据和票价数据
- c语言While循环语句
- JavaScript系列——Generator
- 【实用代码片段】从原图像到目标图像的颜色迁移