多模态推荐系统综述:五、挑战
五、挑战
1、Multimodal Recommender Systems: A Survey 2023
?通用解决方案。 值得注意的是,尽管针对模型中的不同阶段提出了一些方法[24],但没有提供这些技术组合的最新通用解决方案。
?模型可解释性。 多模态模型的复杂性会使系统生成的建议难以理解和解释,从而限制系统的信任和透明度。虽然很少有先驱者提到它,但它仍然需要探索。
?计算复杂性。 MRS需要大量数据和计算资源,因此难以扩展到大型数据集和总体。多模态数据和模型的复杂性会增加生成推荐所需的计算成本和时间,这给实时应用带来了挑战。
?通用MRS数据集。 目前,MRS的数据集仍然有限,涉及的模式不够广泛。此外,不同模式的数据质量和可用性可能会有所不同,这会影响建议的准确性和可靠性。
2、A Comprehensive Survey on Multimodal Recommender Systems: Taxonomy, Evaluation, and Future Directions 2023
2.1 如何有效融合多模态信息?
(1)找出有效的模态融合方法,能够捕获单一模态无法包含的互补信息。 每种模态可能捕获项目的不同方面,我们应该找到一种方法将它们融合在一起,同时保留特定于模态的信息,以学习包含单一模态表示无法包含的补充信息的多模态表示。但对于某些模型,单一模态也能取得比同时利用多模态信息更好的性能。如果模型能够有效地融合多模态特征,推荐精度应该比利用单一模态特征更高。
(2)如何解决模态缺失问题并重构有意义的表示。 模态缺失问题在现实世界中很常见。然而,一些模型假设所有模态信息在训练和推理过程中都是可用的,这在面对不完整和缺失模态时将不起作用。LRMM通过利用生成模型来重建特定于模态的嵌入并估算缺失的模态,从而减轻了模态缺失和冷启动问题。
LRMM: Learning to Recommend with Missing Modalities 2018
LRMM概述。采用CNN进行可视化嵌入(粉红色部分),采用三个LSTM分别对用户评论文本(红色部分)、项目评论文本(绿色部分)和项目元数据(蓝色部分)进行文本嵌入。生成(自动编码)模型用于重建模态特定嵌入和填充缺失模态。缺少user和item review文本分别导致基于user和item的冷启动。
2.2 如何规范数据分割策略和使用的通用数据集?
找到具有合适提取技术和合适分割策略的最佳预处理方法,以标准化实验的训练/测试集。
(1)正如前面的实验所示,即使使用相同的数据集和评估指标,模型使用不同的数据分割策略也会得到不同的性能数据,模型性能的排名也会受到不同分割策略的影响。
(2)虽然最常用的是随机分割,但基于时间的分割更接近现实场景。鲁棒的多模态推荐模型无论是随机分割还是时间分割都应该表现良好。
(3)用于多模态推荐的数据集并不标准化,而且审稿论文中使用的大多数数据集都不像快手、抖音和大众点评那样公开。
(4)特征提取技术也会影响学习到的最终表示,每篇论文都使用不同的技术。
2.3 评估指标
推荐模型的评价是一个重要的研究课题。 推荐系统不仅要考虑准确性,还要考虑其他推荐质量,如推荐列表的多样性和独特项的存在,这可能会对推荐系统的整体质量产生重大影响。
文献[11]指出,通用推荐的评价指标可能不完全适用于多模态推荐。
2.4 研究与应用差距
(1)在面对大数据集时如何平衡模型的复杂度和可扩展性。
(2)高维张量和多模态信息的计算效率。
2.5 多模态顺序推荐
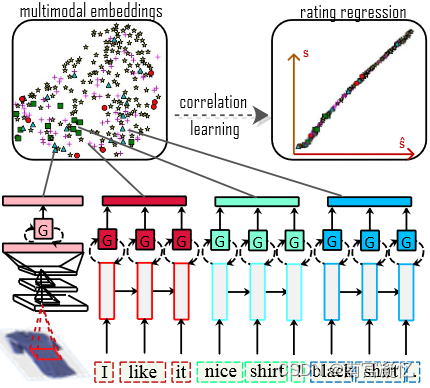
序贯推荐系统不同于使用协同过滤和基于内容过滤的推荐系统,因为它试图理解和建模用户随时间变化的序贯行为。多模态信息会极大地影响用户的偏好,然而现有的序贯推荐模型大多忽略了这些有用信息。MML结合了项目的多模态边信息,以改进和稳定元学习过程,并帮助解决冷启动问题。因此,在序贯推荐系统中利用多模态信息将是今后工作的一个重要方向。
2.6 跨域推荐
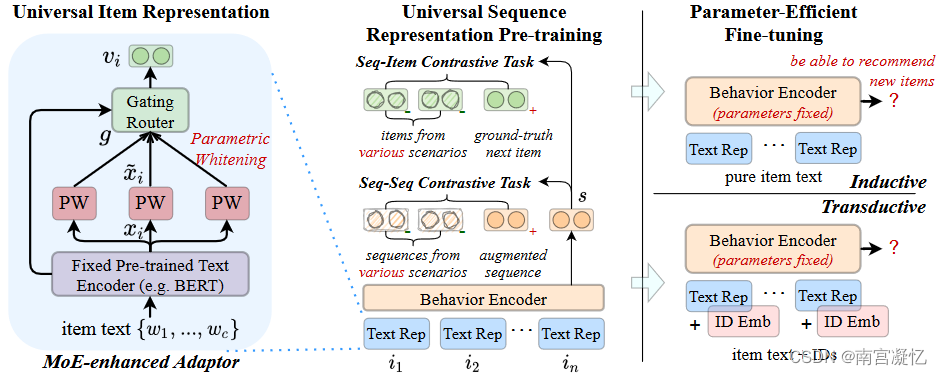
跨域推荐系统利用来自其他域或平台的行为信息来提高目标域的性能。常用的技术依赖于显式重叠数据(例如,公共用户和项目)跨域传输数据。最近,一些工作学习了用户和项目的通用表示,可以应用于跨域推荐。UniSRec利用文本信息学习通用项目表示,而不需要公共用户和项目,这可能适用于不同的领域。在未来,利用多模态信息可能有助于模型学习通用表示。
UniSRec: Towards Universal Sequence Representation Learning for Recommender Systems. 2022
为了开发有效的序列推荐器,提出了一系列序列表示学习(SRL)方法来对历史用户行为进行建模。大多数现有的SRL方法都依赖于显式项目ID来开发序列模型,以更好地捕获用户偏好。尽管这些方法在一定程度上是有效的,但由于显式建模项目ID的局限性,很难推广到新的推荐场景。
为了解决这个问题,我们提出了一种新的通用序列表示学习方法UniSRec。该方法利用项目的相关描述文本学习不同推荐场景下的可转换表示。为了学习通用项目表示,设计了一种基于参数白化和专家混合增强适配器的轻量级项目编码体系结构。为了学习通用序列表示,我们引入了两个对比的预训练任务,通过采样多域否定。利用预先训练好的通用序列表示模型,我们的方法可以在归纳和直推两种情况下以参数有效的方式有效地转移到新的推荐域或推荐平台。
参考论文
Multimodal Recommender Systems: A Survey
A Comprehensive Survey on Multimodal Recommender Systems: Taxonomy, Evaluation, and Future Directions
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C#不会循环响应的Action设计与实现
- 如何给openai的assistant添加Functions
- 初识MyBatis
- 开关电源反馈环路重要参数设计,PC817和TL431实例计算和取值详解
- 1971. Find if Path Exists in Graph
- SCT52A40——120V,4A,高频高压侧和低压侧栅极驱动器,替代UCC27200/UCC27201/MIC4604YM等
- Qt移植曲线显示
- 【netstat】
- 最优轨迹生成(四)—— 带约束轨迹优化
- 带你拿捏SpringBoot自动装配的核心技术?模块装配(@EnableXXX注解+@Import)+ 条件装配(@ConditionalXXX)