Python 中的 Iterable 和 Iterator(Iterable and Iterator in Python)
Python 中的 Iterable 和 Iterator(Iterable and Iterator in Python)
文章目录
Introduction 导言
Iterable 和 Iterator 是 Python 的重要概念。然而,有时可能会让人感到困惑。本篇文章将深入探讨这些概念,帮助您完全理解它们。
Iterable VS Iterator
首先,我们应该知道 可迭代的对象Iterable 和 迭代器Iterator 是不同的。确切地说,Iterator 是 Iterable 的子类。一个 Iterable 对象,如 list , tuple , dict , set 和 str ,可以通过 iter() 函数产生一个 Iterator。例如
my_list = [1, 2, 3, 4, 5]
print(type(my_list))
# <class 'list'>
my_list_iterator = iter(my_list)
print(type(my_list_iterator))
# <class 'list_iterator'>
直观地说,任何可以通过 for...in... 循环迭代的对象都是 Iterable 对象。Iterator 也是 Iterable,因为它是 Iterable 的子类。我们可以使用 isinstance() 函数来检查它:
from collections.abc import Iterable, Iterator
my_list = [1, 2, 3, 4, 5]
my_list_iterator = iter(my_list)
isinstance(my_list,Iterable)
#True
isinstance(my_list,Iterator)
#False
isinstance(my_list_iterator,Iterable)
#True
isinstance(my_list_iterator,Iterator)
#True
让我们来看看 Python 3.9 _collections_abc.py 源代码:
class Iterable(metaclass=ABCMeta):
__slots__ = ()
@abstractmethod
def __iter__(self):
while False:
yield None
@classmethod
def __subclasshook__(cls, C):
if cls is Iterable:
return _check_methods(C, "__iter__")
return NotImplemented
__class_getitem__ = classmethod(GenericAlias)
class Iterator(Iterable):
__slots__ = ()
@abstractmethod
def __next__(self):
'Return the next item from the iterator. When exhausted, raise StopIteration'
raise StopIteration
def __iter__(self):
return self
@classmethod
def __subclasshook__(cls, C):
if cls is Iterator:
return _check_methods(C, '__iter__', '__next__')
return NotImplemented
很明显,Iterator 继承自 Iterable。
Iterator 和 Iterable 的区别在于:
- 可迭代对象Iterable 可以一次性打印所有元素。它确实包含了所有元素。
- 迭代器Iterator 就像一个 “工厂factory”,它保存了生成元素elements的方法,而我们只能使用
next()函数逐个生成元素elements。我们不能一次打印所有元素elements,因为迭代器Iterator只知道如何生成元素的方法,而不会真正包含任何元素。
my_list = [1, 2, 3, 4, 5]
print(my_list)
# [1, 2, 3, 4, 5]
my_list_iterator = iter(my_list)
print(my_list_iterator)
# <list_iterator object at 0x7f048a4b67f0>
next(my_list_iterator)
# 1
next(my_list_iterator)
# 2
next(my_list_iterator)
# 3
next(my_list)
# TypeError: 'list' object is not an iterator
为什么 Python 有这种特殊的设计special design?
因为在 Python 中,操作一个大型容器large container(list/set/dict 等)往往非常耗时且效率低下。有时我们并不需要一次使用所有元素all the elements at once,我们只需要一次使用一个元素use one element at a time。因此,保存一个方法并在需要时产生一个元素saving a method and produce an element when we need one,而不是保存所有元素rather than saving all elements,是一个很好的主意。这样既能减少时间成本,又能减少空间成本。
简而言之,Python 中的 Iterable 对象是一个可以被遍历(通过 for 循环)的对象。Iterator 是 Iterable 的子类,但它包含一个产生项item的方法而不是项items本身。
如何获取迭代器Iterator?
1. 使用 iter() 函数
正如前面的示例所示,通过 iter() 将 Iterable 转换为 Iterator 非常方便。
2. 实现 __iter__() and __next__() 方法
迭代器Iterator对象必须实现两个特殊方法: __iter__() 和 __next__() 。我们可以自己定义这两个方法,使对象object成为一个迭代器Iterator。
__iter__() 是迭代器Iterator初始化initialization时调用的方法method。它应该返回一个具有 __next__() 方法的对象object。换句话说,它定义了 iter() 函数如何返回一个迭代器Iterator。正如前面的示例所示,由于 Python 的 list 对象object已经实现implemented了 __iter__() 方法method,所以我们可以使用 iter(my_list) 将其转换为一个迭代器Iterator。在简单的情况下,我们可以在 __iter__() 方法中直接返回 self 。
__next__() 定义了产生项目items的方法method。换句话说,它定义了 next() 函数如何获取下一个项目item。
例如,这是一个生成斐波那契数字的类:
from collections.abc import Iterable, Iterator
class Fib(object):
def __init__(self):
self.a, self.b = 0, 1
def __iter__(self):
return self
def __next__(self):
self.a, self.b = self.b, self.a + self.b
if self.a > 1000: # set a limitation to stop
raise StopIteration()
return self.a
f = Fib()
print(isinstance(f, Iterator))
print(next(f))
print(next(f))
print(next(f))
print(next(f))
# True
# 1
# 1
# 2
# 3
3. 使用生成器Generator
每次都要定义上述两个特殊方法有点复杂。实际上,Python 的生成器机制generator mechanism可以帮助我们完成这些工作。
from collections.abc import Iterable, Iterator
def Fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'
f = Fib(10000)
print(isinstance(f, Iterator))
print(next(f))
print(next(f))
print(next(f))
print(next(f))
# True
# 1
# 1
# 2
# 3
Generator 是 Iterator 的子类。它们之间的关系如下
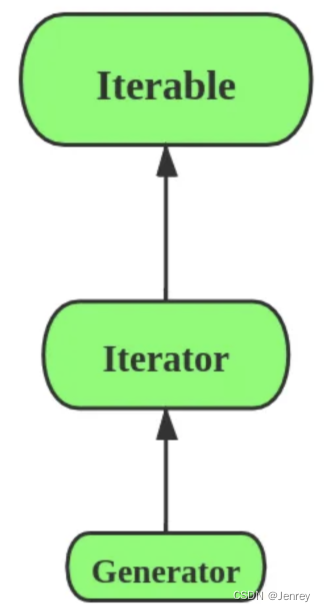
Python 中的 for 循环究竟是如何工作的?
到目前为止,我们已经知道了 Iterable 和 Iterator 的所有要点,但还有一点值得解释。 for 循环在 Python 中究竟是如何工作的呢?其实很简单。只需两步:
- 将可迭代对象Iterable 转换为迭代器Iterator 。
- 使用
next()函数获取每个元素,直到停止。
有一个最简单的 for loop 实现,可以帮助您理解。
# convert an Iterable to an Iterator
my_list_iterator = iter(my_list)
while True:
try:
# get the next item
element = next(my_list_iterator)
except StopIteration:
# if StopIteration is raised, stop for loop
break
Conclusion 结论
Python 中的 Iterable 是任何可以迭代的对象。
Iterator 只保存方法而不是项items,它是 Iterable 的子类,以减少时间和空间成本。
Python 中的 For 循环应用这些概念来生成 Iterable 的所有项items。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ipa分发平台绑定域名有什么优势
- TCP三握四挥(面试需要)
- Spring之注解实现依赖注入
- 顺序表及应用
- 隐身之术:深入解析代理模式的神秘力量
- 多人协作项目代码规范统一约定(完整全面)
- 使用Java版工程行业管理系统源码,提升工程项目的综合管理能力
- C# ref传参与out传参
- ThunderSearch(闪电搜索器)_网络空间搜索引擎工具_信息收集
- AI工具(20240116):Copilot Pro,Fitten Code等