Mysql查询与更新语句的执行
一条SQL查询语句的执行顺序

FROM:对 FROM 子句中的左表<left_table>和右表<right_table>执行笛卡儿积(Cartesianproduct),产生虚拟表 VT1
ON:对虚拟表 VT1 应用 ON 筛选,只有那些符合<join_condition>的行才被插入虚拟表 VT2 中
JOIN:如果指定了 OUTER JOIN(如 LEFT OUTER JOIN、RIGHT OUTER JOIN),那么保留表中未匹配的行作为外部行添加到虚拟表 VT2 中,产生虚拟表 VT3。如果 FROM 子句包含两个以上表,则对上一个连接生成的结果表 VT3 和下一个表重复执行步骤 1)~步骤 3),直到处理完所有的表为止
WHERE:对虚拟表 VT3 应用 WHERE 过滤条件,只有符合<where_condition>的记录才被插入虚拟表 VT4 中
GROUP BY:根据 GROUP BY 子句中的列,对 VT4 中的记录进行分组操作,产生 VT5
CUBE|ROLLUP:对表 VT5 进行 CUBE 或 ROLLUP 操作,产生表 VT6
HAVING:对虚拟表 VT6 应用 HAVING 过滤器,只有符合<having_condition>的记录才被插入虚拟表 VT7 中。
SELECT:第二次执行 SELECT 操作,选择指定的列,插入到虚拟表 VT8 中
DISTINCT:去除重复数据,产生虚拟表 VT9
ORDER BY:将虚拟表 VT9 中的记录按照<order_by_list>进行排序操作,产生虚拟表 VT10。11)
LIMIT:取出指定行的记录,产生虚拟表 VT11,并返回给查询用户
一条更新语句怎么执行的
更新语句的执行是 Server 层和引擎层配合完成,数据除了要写入表中,还要记录相应的日志。
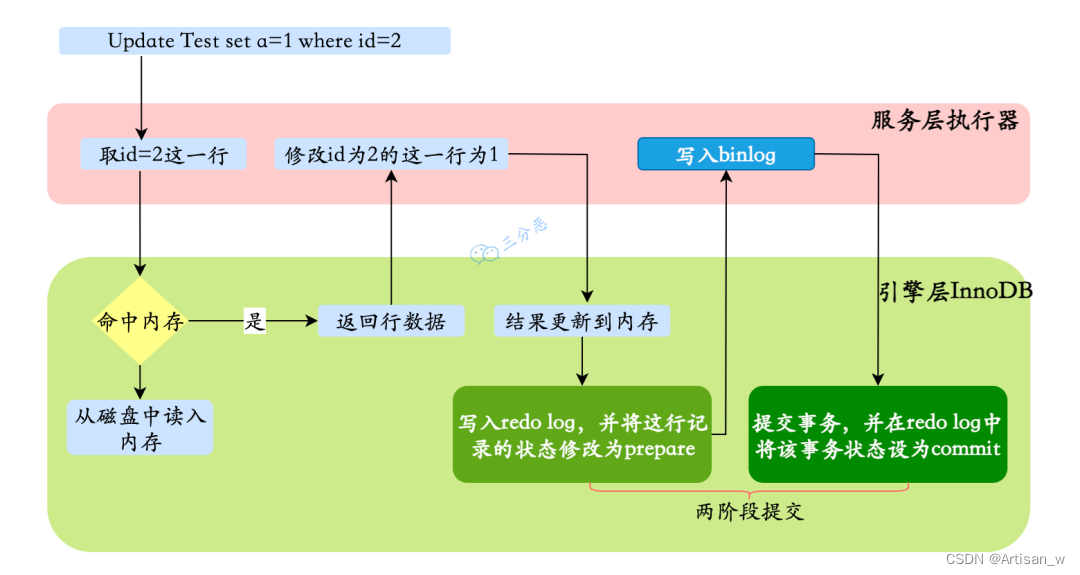
1·、执行器先找引擎获取 ID=2 这一行。ID 是主键,存储引擎检索数据,找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
2、执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
3、执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
4、执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
从上图可以看出,MySQL 在执行更新语句的时候,在服务层进行语句的解析和执行,在引擎层进行数据的提取和存储;同时在服务层对 binlog 进行写入,在 InnoDB 内进行 redo log 的写入。
不仅如此,在对 redo log 写入时有两个阶段的提交,一是 binlog 写入之前prepare状态的写入,二是 binlog 写入之后commit状态的写入。
redo 的prepare代表开始更新数据
redo的commit代表已经提交了事务,这个过程写入了binlog
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【PHP】PHP实现与硬件串口交互,接收硬件发送的实时数据
- 群晖Drive搭建云同步服务器结合内网穿透实现Obsidian笔记文件远程多端同步
- 并发编程之深入理解AQS
- SATA和M.2接口的异同点
- 光明源智能:智慧厕所系统,打造智慧化科技智能生活
- 面向企业的 ChatGPT 究极手册:第三章到第四章
- 【Win10安装Tensorrt和torch2trt】
- Linux脚本shell的编写
- Prepared statement needs to be re-prepared
- CSS Day6-Day8 浮动和定位