Pytorch深度学习实践 13循环神经网络(高级)
最近在?B站 刘二大人 学习PyTorch ,上传一些学习用的代码,仅供参考和交流。
循环神经网络基础部分参考:
Pytorch深度学习实践 12 循环神经网络(基础篇)-CSDN博客
目录
1、数据集预处理
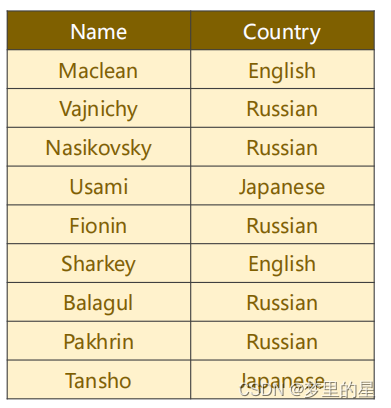
????????names数据集包含Name,Country两个属性,我们要构建一个基于循环神经网络(RNN)的名字分类器,根据名字Name预测国家Country。我们首先要进行数据集的预处理,将输入的名字序列和对应的国家标签转换为PyTorch张量。
? ? ? ??
- 将名字转换为 ASCII 码表示
? ? ? ? 由于名字不能直接输出循环神经网络,先将名字变为ASCII码表示,将每个名字表示为一个由 ASCII 码构成的序列,而 input_size 就是 ASCII 码的总数,即 128。
def name2list(name):
arr=[ord(c) for c in name]#ord函数返回ASCII码值,将名字从string类型变为
return arr,len(arr)
- 将名字序列填充
? ? ? ? 由于名字序列的长度不统一,我们应当使用零元素按照最长序列长度进行填充,保证序列长度一致。在这里,先构建一个大小为(BatchSize,SeqLen)的零张量,然后使用名字ASCII码序列进行填充。
#make tensor of name,BatchSizeXSeqLen 实现填充零的功能
seq_tensor=torch.zeros(len(name_sequences),seq_lengths.max()).long()
for idx,(seq,seq_len) in enumerate(zip(name_sequences,seq_lengths),0):
seq_tensor[idx, :seq_len]=torch.LongTensor(seq)#按照名字序列长度赋值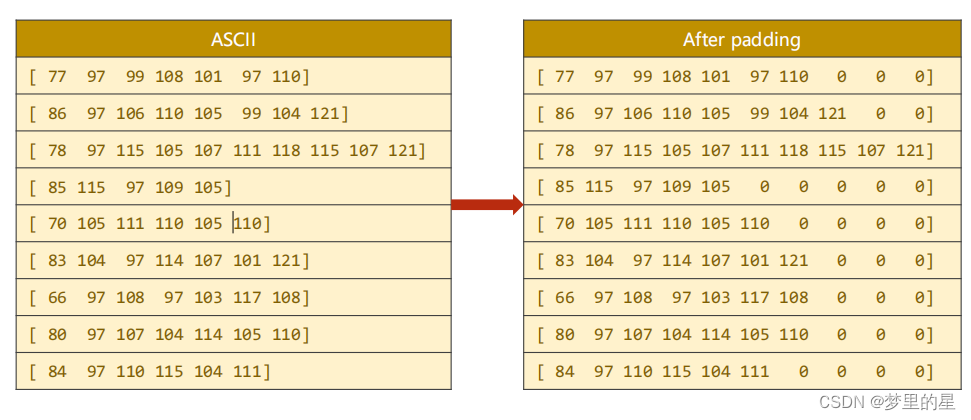
- 对数据进行排序
? ? ? ??在循环神经网络中,如果输入序列的长度不同,需要对序列进行填充(padding)以满足相同长度的要求。然而,由于填充的存在,实际的序列长度可能会变得不同。pack_padded_sequence 的作用就是将填充后的序列打包成一个紧凑的数据结构,以便在 RNN 中高效地处理。
? ? ? ?pack_padded_sequence(input,lengths)
? ? ? ?inputs:?需要被打包的填充后的序列,是一个形状为 (max_seq_len, batch_size, input_size) 的张量,其中 max_seq_len 是填充后的最大序列长度。
? ? ? ?lengths:一个包含每个序列实际长度的列表(或张量)。
? ? ? ? 因此,需要进行转置操作,将张量的大小由(batchSzie,seqLen)变为(seqLen,batchSzie)。另外,在使用 pack_padded_sequence 时,需要注意保持序列的顺序,因此在使用前需要按序列长度进行排序,这里我们使用降序排序。
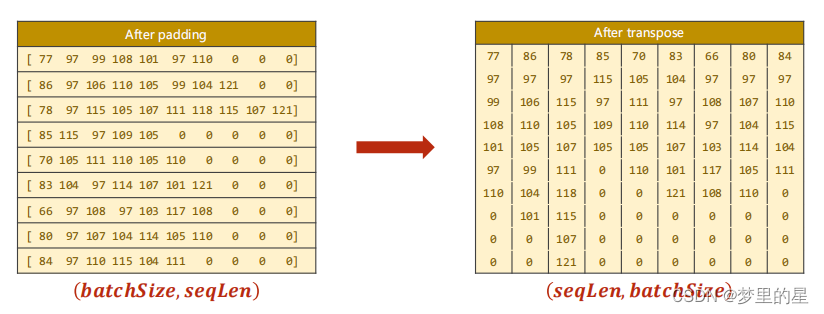
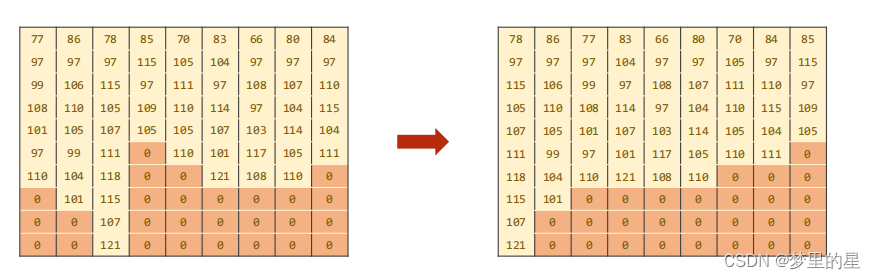
将上述步骤封装为一个函数make_tensors:?
def make_tensors(names,countries):
sequences_and_lengths=[name2list(name) for name in names]#返回元组([name_list],len(name_list))构成的列表
name_sequences=[s1[0] for s1 in sequences_and_lengths]
seq_lengths=torch.LongTensor([s1[1] for s1 in sequences_and_lengths])
countries=countries.long()#转换为long类型
#make tensor of name,BatchSizeXSeqLen 实现填充零的功能
seq_tensor=torch.zeros(len(name_sequences),seq_lengths.max()).long()
for idx,(seq,seq_len) in enumerate(zip(name_sequences,seq_lengths),0):
seq_tensor[idx, :seq_len]=torch.LongTensor(seq)#按照名字序列长度赋值
#sort by length to use pack_padded_sequence
seq_lengths,perm_idx=seq_lengths.sort(dim=0,descending=True)
seq_tensor=seq_tensor[perm_idx]
countries=countries[perm_idx]
return create_tensor(seq_tensor),\
create_tensor(seq_lengths),\
create_tensor(countries)2、循环神经网络
- 编码器
????????将每个输入元素(ASCII 码值)映射为一个密集的低维向量,将高维离散的输入数据(如单词、字符等)转换为低维稠密的连续向量表示,从而提供更丰富的语义信息。
????????torch.nn.Embedding(input_size, hidden_size)
? ?input_size 是输入数据的大小,通常表示为词汇表的大小或字符集的大小。在代码中,input_size 是 128,表示ASCII码的范围(0-127)。
? ?hidden_size 是嵌入向量的维度,即每个输入元素将被嵌入为一个 hidden_size 维的向量。这个维度是一个超参数,需要根据问题和模型的性能进行调整。
- GRU
????????门控循环单元(Gated Recurrent Unit,简称GRU)是一种循环神经网络(RNN)的变体,用于处理序列数据,与LSTM相比,它简化了LSTM结构,减少了LSTM中的门控单元的数量,使得模型更容易训练。
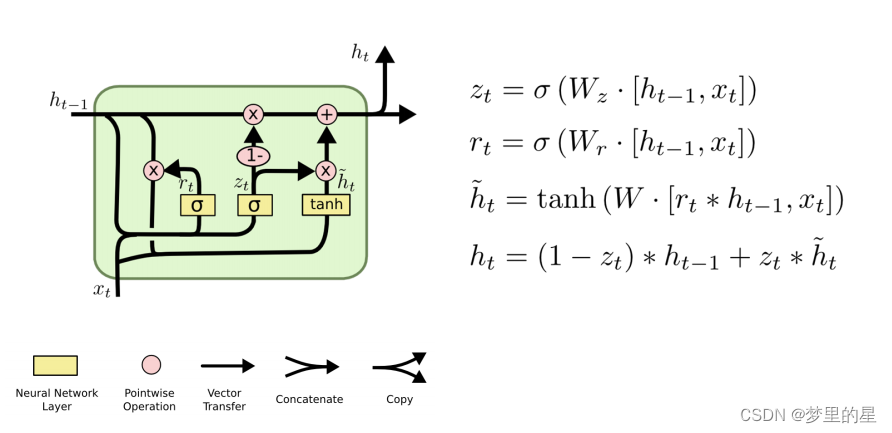
? ? ? ? 可参考:人人都能看懂的GRU - 知乎 (zhihu.com)
- 模型结构
????????循环神经网络有编码器、GRU和线性层构成,我们只在最终的输出通过线性层进行映射,中间隐藏层输出不再进行处理。
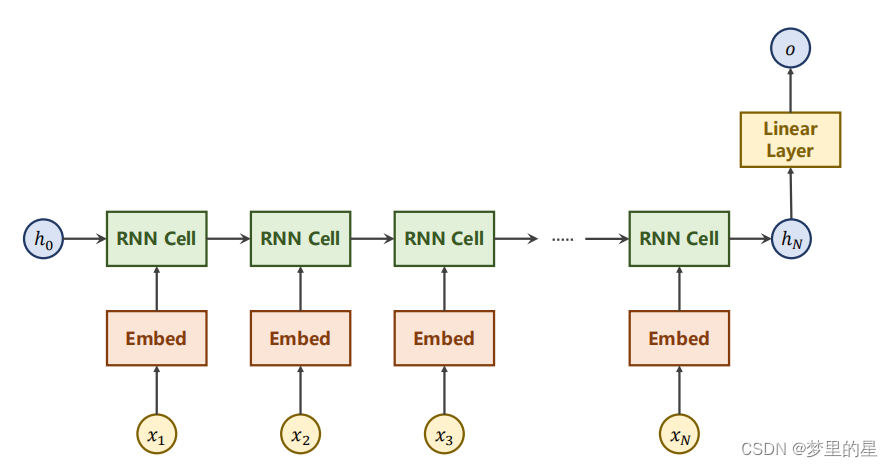
????????在此,使用双向循环神经网络通过在每个时间步骤同时考虑过去和未来的信息,包含两个独立的隐含层,一个按时间正向传播(正向层),另一个按时间逆向传播(逆向层),最终输出需要将两个隐含层输出拼接起来。?
????????当设置循环神经网络的层数为2,并且启用了双向循环神经网络(bidirectional=True)时,实际上会有两个隐藏层,一个是正向层,另一个是逆向层。具体来说,如果设置 num_layers=2,那么模型的结构将包含两个正向循环层和两个逆向循环层,总共四个隐含层。在每个时间步,这四个隐含层的输出将被拼接在一起,形成最终的输出。在pytorch中,使用torch.cat进行拼接操作:
if self.n_directions==2:
hidden_cat=torch.cat([hidden[-1],hidden[-2]],dim=1)
#hidden[-1]的形状是(256,100),hidden[-2]的形状是(256,100),拼接后的形状是(256,200)
else:
hidden_cat=hidden[-1]????????定义模型的代码如下:
class RNNClassifier(torch.nn.Module):
def __init__(self,input_size,hidden_size,output_size,n_layers=1,bidirectional=True):
super(RNNClassifier,self).__init__()
self.hidden_size=hidden_size
self.n_layers=n_layers
self.n_directions=2 if bidirectional else 1
self.embedding=torch.nn.Embedding(input_size,hidden_size)
#input_size: 输入特征的大小;hidden_size: 隐藏状态的大小,即每个时间步的隐藏单元的数量;num_layers: GRU 的层数,即堆叠的GRU层的数量。
self.gru=torch.nn.GRU(hidden_size,hidden_size,n_layers,bidirectional=bidirectional)
self.fc=torch.nn.Linear(hidden_size*self.n_directions,output_size)
def __init__hidden(self,batch_size):
hidden=torch.zeros(self.n_layers*self.n_directions,batch_size,self.hidden_size)
return create_tensor(hidden)
def forward(self,input,seq_lengths):
#input shape :BXS->SXB
input=input.t()#(14,256)
batch_size=input.size(1)
hidden=self.__init__hidden(batch_size)#(4,256,100)
embedding=self.embedding(input)#(14,256,100)
#pack them up
gru_input=pack_padded_sequence(embedding,seq_lengths)
# output:(*, hidden_size * num_directions),*表示输入的形状(seq_len,batch_size)
# hidden:(num_layers * num_directions, batch, hidden_size)
output,hidden=self.gru(gru_input,hidden)#hidden的size为(4,256,100)
if self.n_directions==2:
hidden_cat=torch.cat([hidden[-1],hidden[-2]],dim=1)
#hidden[-1]的形状是(256,100),hidden[-2]的形状是(256,100),拼接后的形状是(256,200)
else:
hidden_cat=hidden[-1]
fc_output=self.fc(hidden_cat)#(256,18)
return fc_output3、模型训练
? ? ? ? 如果使用CPU训练,设置USE_GPU=False,进行训练即可;如果使用GPU训练,设置USE_GPU=True,并且将134行和153行的seq_lengths修改为seq_lengths.cpu()。
????????如果电脑没有GPU或者GPU性能过低,可以上传kaggle网站使用GPU进行训练,网址:Kaggle: Your Home for Data Science
????????参考:kaggle免费GPU资源计算 - 知乎 (zhihu.com)
? ? ? ? 在训练过程中,当准确率升高时,可以使用torch.save()保存模型参数,再次使用时,可以通过torchload()加载,示例:
#模型参数保存
torch.save(classifier.state_dict(), 'best_model.pth')
#模型参数加载
classifier.load_state_dict(torch.load('./best_model.pth'))#加载上一次的最优化参数????????完整代码:
import time
import csv
import math
import torch
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset
from torch.nn.utils.rnn import pack_padded_sequence
from torch.utils.data import DataLoader
#Parameters 超参数
HIDDEN_SIZE=100
BATCH_SIZE=256
N_LAYER=2
N_EPOCHS=100
N_CHARS=128
USE_GPU=False
class NameDataset(Dataset):
def __init__(self,is_train_set=True):
filename='../dataset/names/names_train.csv' if is_train_set else '../dataset/names/names_test.csv'
with open(filename,'rt')as f:
reader=csv.reader(f)
rows=list(reader)
self.names=[row[0] for row in rows]#取出第一列,名字
self.len=len(self.names)#计算出有多少个名字
self.countries=[row[1] for row in rows]
self.country_list=list(sorted(set(self.countries)))#转换为集合去除重复元素,进行升序排列,转变为list
self.country_dict=self.getCountryDict()#转换为字典
self.country_num=len(self.country_list)#计算出有多少个国家
#获取名字和国家序号
def __getitem__(self,index):
return self.names[index],self.country_dict[self.countries[index]]
#获取数据集长度
def __len__(self):
return self.len#训练集13374,测试集6700
#将国家list变为dictionary
def getCountryDict(self):
country_dict=dict()
for idx,country_name in enumerate(self.country_list,0):
country_dict[country_name]=idx
return country_dict
#根据索引返回国家名称
def idx2country(self,index):
return self.country_list[index]
#获取国家数量
def getCountriesNum(self):
return self.country_num
trainset=NameDataset(is_train_set=True)
trainloader=DataLoader(trainset,batch_size=BATCH_SIZE,shuffle=True)
testset=NameDataset(is_train_set=False)
testloader=DataLoader(testset,batch_size=BATCH_SIZE,shuffle=False)
N_COUNTRY=trainset.getCountriesNum()
class RNNClassifier(torch.nn.Module):
def __init__(self,input_size,hidden_size,output_size,n_layers=1,bidirectional=True):
super(RNNClassifier,self).__init__()
self.hidden_size=hidden_size
self.n_layers=n_layers
self.n_directions=2 if bidirectional else 1
self.embedding=torch.nn.Embedding(input_size,hidden_size)
#input_size: 输入特征的大小;hidden_size: 隐藏状态的大小,即每个时间步的隐藏单元的数量;num_layers: GRU 的层数,即堆叠的GRU层的数量。
self.gru=torch.nn.GRU(hidden_size,hidden_size,n_layers,bidirectional=bidirectional)
self.fc=torch.nn.Linear(hidden_size*self.n_directions,output_size)
def __init__hidden(self,batch_size):
hidden=torch.zeros(self.n_layers*self.n_directions,batch_size,self.hidden_size)
return create_tensor(hidden)
def forward(self,input,seq_lengths):
#input shape :BXS->SXB
input=input.t()#(14,256)
batch_size=input.size(1)
hidden=self.__init__hidden(batch_size)#(4,256,100)
embedding=self.embedding(input)#(14,256,100)
#pack them up
gru_input=pack_padded_sequence(embedding,seq_lengths)
# output:(*, hidden_size * num_directions),*表示输入的形状(seq_len,batch_size)
# hidden:(num_layers * num_directions, batch, hidden_size)
output,hidden=self.gru(gru_input,hidden)#hidden的size为(4,256,100)
if self.n_directions==2:
hidden_cat=torch.cat([hidden[-1],hidden[-2]],dim=1)
#hidden[-1]的形状是(256,100),hidden[-2]的形状是(256,100),拼接后的形状是(256,200)
else:
hidden_cat=hidden[-1]
fc_output=self.fc(hidden_cat)#(256,18)
return fc_output
def make_tensors(names,countries):
sequences_and_lengths=[name2list(name) for name in names]#返回元组([name_list],len(name_list))构成的列表
name_sequences=[s1[0] for s1 in sequences_and_lengths]#返回一个列表,列表每个元素是名字单个字母ASICC码构成的列表
seq_lengths=torch.LongTensor([s1[1] for s1 in sequences_and_lengths])#括号内返回一个列表,每个元素是对应名字的长度,后面转换为longTensor类型
countries=countries.long()#转换为long类型
# PyTorch 中,张量的默认数据类型是浮点型 (float),这里转换成整型,可以避免浮点数比较时的精度误差,从而提高模型的训练效果
#make tensor of name,BatchSizeXSeqLen 实现填充零的功能
seq_tensor=torch.zeros(len(name_sequences),seq_lengths.max()).long()#构建一个全部名字(行)X最大名字长度(列)构成元素类型为long的张量
for idx,(seq,seq_len) in enumerate(zip(name_sequences,seq_lengths),0):
seq_tensor[idx, :seq_len]=torch.LongTensor(seq)#按照名字序列长度赋值
#sort by length to use pack_padded_sequence
# perm_idx是排序后的数据在原数据中的索引,seq_lengths是排序后的数据的长度
# seq_tensor是排序后的数据,seq_lengths是排序后的数据的长度,countries是排序后的国家
seq_lengths,perm_idx=seq_lengths.sort(dim=0,descending=True)
seq_tensor=seq_tensor[perm_idx]
countries=countries[perm_idx]
return create_tensor(seq_tensor),\
create_tensor(seq_lengths),\
create_tensor(countries)
# 把名字转换成ASCII码,返回ASCII码值列表和名字的长度
def name2list(name):
arr=[ord(c) for c in name]#ord函数返回ASCII码值,将名字从string类型变为
return arr,len(arr)
#是否把数据放在GPU上
def create_tensor(tensor):
if USE_GPU:
device=torch.device("cuda:0")
tensor=tensor.to(device)
return tensor
def time_since(since):
s=time.time()-since
m=math.floor(s/60)#向下取整
s-=m*60
return '%dm %ds'%(m,s)
def trainModel():
total_loss=0
for i,(names,countries) in enumerate(trainloader,1):
inputs,seq_lengths,target=make_tensors(names,countries)
output=classifier(inputs,seq_lengths)#seq_lengths用来做pack_padded_sequence
loss=criterion(output,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss+=loss.item()
if i%10==0:
print(f'[{time_since(start)}] Epoch{epoch}',end='')#end=''表示不换行
print(f'[{i*len(inputs)}/ {len(trainset)}]', end='')
print(f'loss={total_loss/(i*len(inputs))}')
return total_loss
def testModel():
correct=0
total=len(testset)
print("evaluating trained model...")
with torch.no_grad():
for i,(names,countries) in enumerate(testloader,1):
inputs,seq_lengths,target=make_tensors(names,countries)
output=classifier(inputs,seq_lengths)#(256,18)
pred=output.max(dim=1,keepdim=True)[1]#(256,1) 返回每一行中最大值的那个元素的索引,且keepdim=True,表示保持输出的二维特性
correct += pred.eq(target.view_as(pred)).sum().item() # 计算正确的个数
percent='%.2f'%(100*correct/total)
print(f'Test set:Accuracy {correct}/{total} {percent}%')
return correct/total
if __name__=='__main__':
classifier=RNNClassifier(N_CHARS,HIDDEN_SIZE,N_COUNTRY,N_LAYER)
if USE_GPU:
device=torch.device("cuda:0")
classifier.to(device)
#classifier.load_state_dict(torch.load('./best_model.pth'))#加载上一次的最优化参数
criterion=torch.nn.CrossEntropyLoss()#使用交叉熵函数
optimizer=torch.optim.Adam(classifier.parameters(),lr=0.001)#使用优化器Adam
start=time.time()#需要定义函数或者导入包
print("Training for %d epochs..."%N_EPOCHS)
acc_list=[]
best_accuracy=0.0
for epoch in range(1,N_EPOCHS+1):
#Train cycle
trainModel()
acc=testModel()
acc_list.append(acc)
if acc>best_accuracy:
best_accuracy=acc
# 保存模型参数
torch.save(classifier.state_dict(), 'best_model.pth')
#画出测试集准确率
epoch=np.arange(1,len(acc_list)+1,1)
acc_list=np.array(acc_list)
plt.plot(epoch,acc_list)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.grid()
plt.show()????????训练过程中测试集准确率变化:

????????使用kaggle网站GPU训练,准确率变化为:
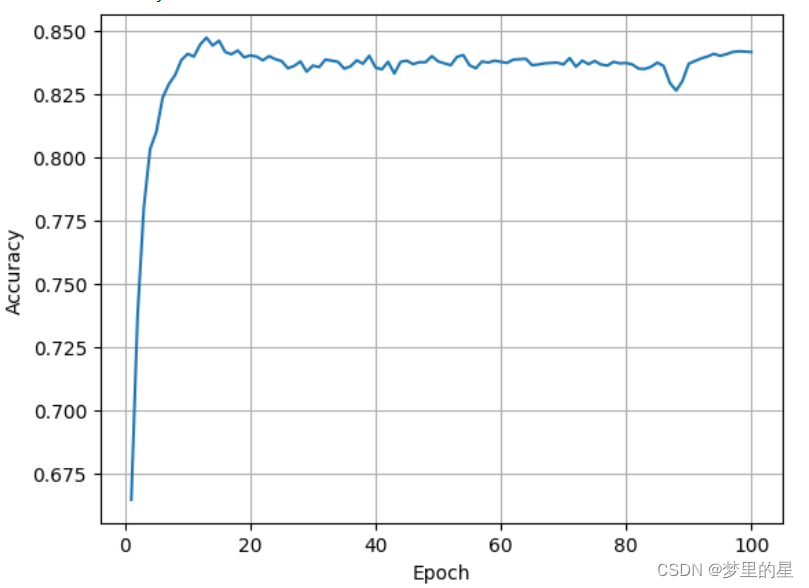
? ? ? ? 可以看出两者变化基本上是相同的,但是使用GPU训练时间更短,效率更高。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!