Pandas爬虫-只需要一行
发布时间:2023年12月25日
目录
????????还在为论文、大作业的数据获取而发愁吗,来试试Pandas爬虫、代码只需要一行,让爬取数据不再遥不可及。
????????众所周知数据的获取极其重要,而Python爬虫既实用又听起来高大上,本文通过两个实战小例子来介绍Pandas爬取表格数据。
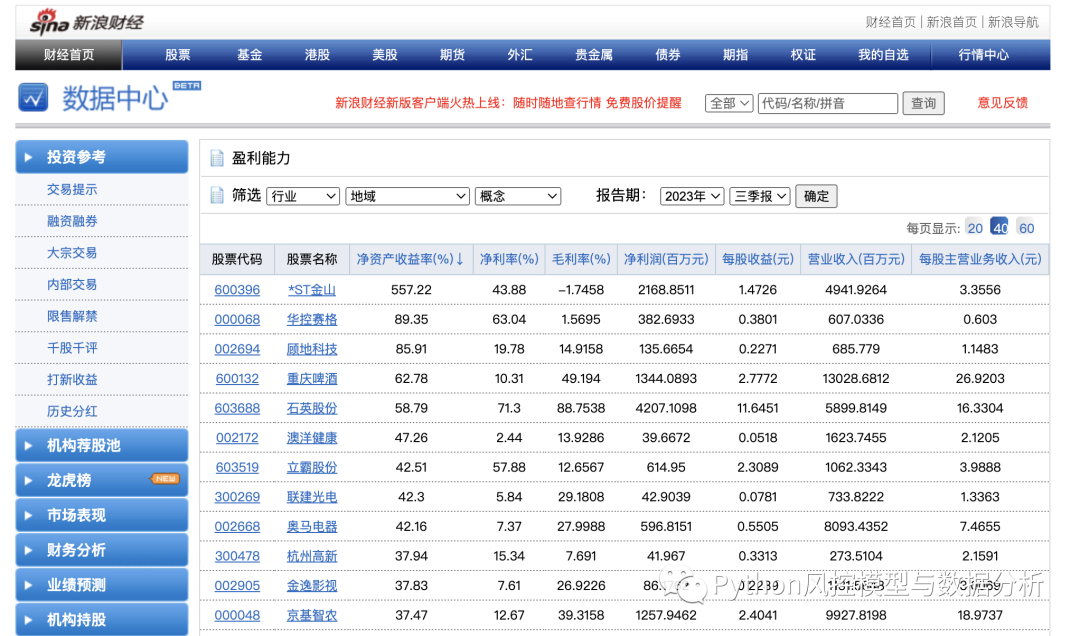
1、爬取新浪财经网股票机构的财务数据
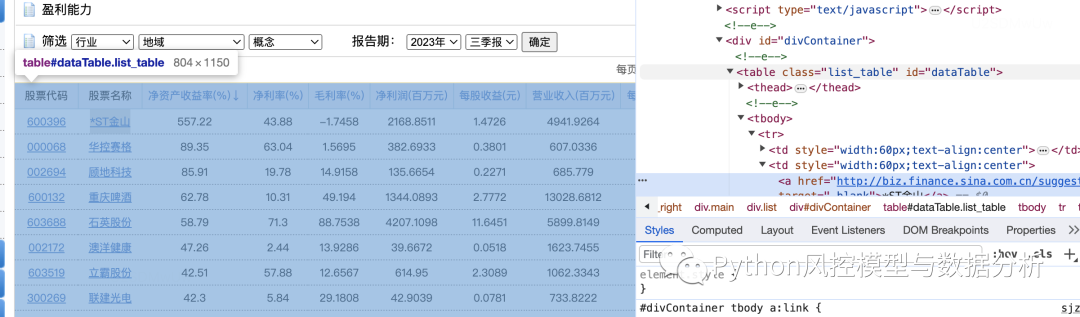
????????如图可以看到,网页里的财务数据是表格形式的,通过右键检查可以定位到网页元素为table,这种结构就可以直接用pandas来爬取数据了
import pandas as pd
url='https://vip.stock.finance.sina.com.cn/q/go.php/vFinanceAnalyze/kind/profit/index.phtml'
df=pd.read_html(url)[0] # 取这个页面中第0个table元素
df
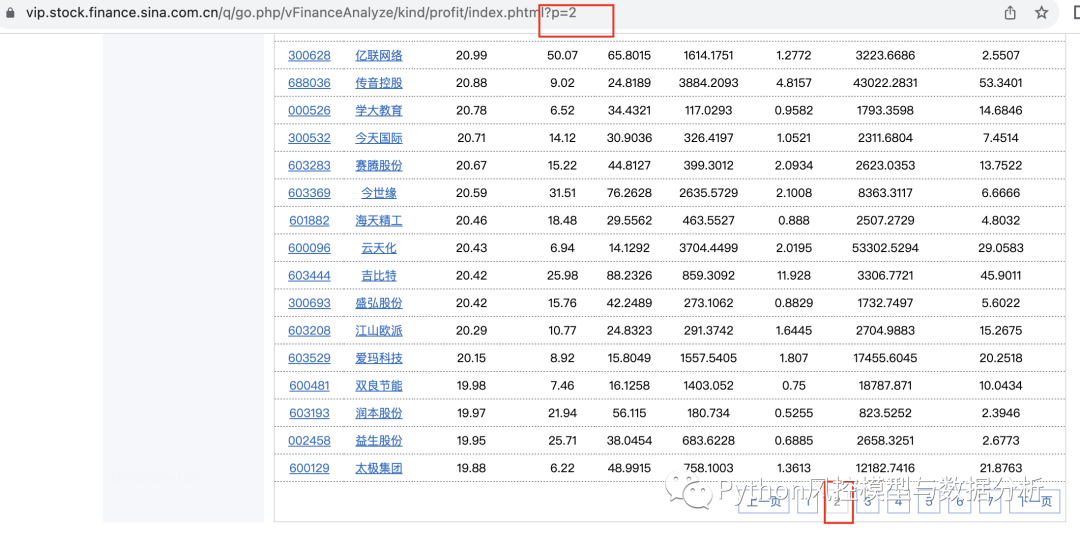
????????当然这只是第一页的数据,点击第二页可以看到网址后面多了?p=2,同理后面第三、四页也是如此,所以只需要循环改变url最后的页数就可以全量爬取数据了
import pandas as pd
l=[]
for i in range(1,10):
url='https://vip.stock.finance.sina.com.cn/q/go.php/vFinanceAnalyze/kind/profit/index.phtml?p={}'.format(i)
l.append(pd.read_html(url)[0])
df=pd.concat(l,axis=0).reset_index(drop=True)
print(df.shape)
df.head()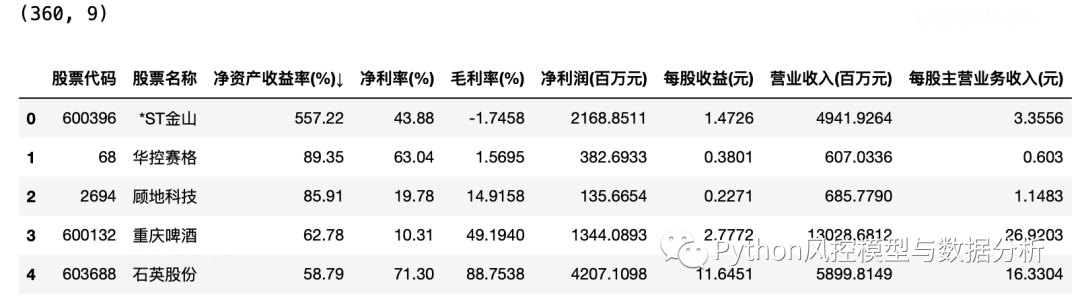
2、爬取89免费代理ip
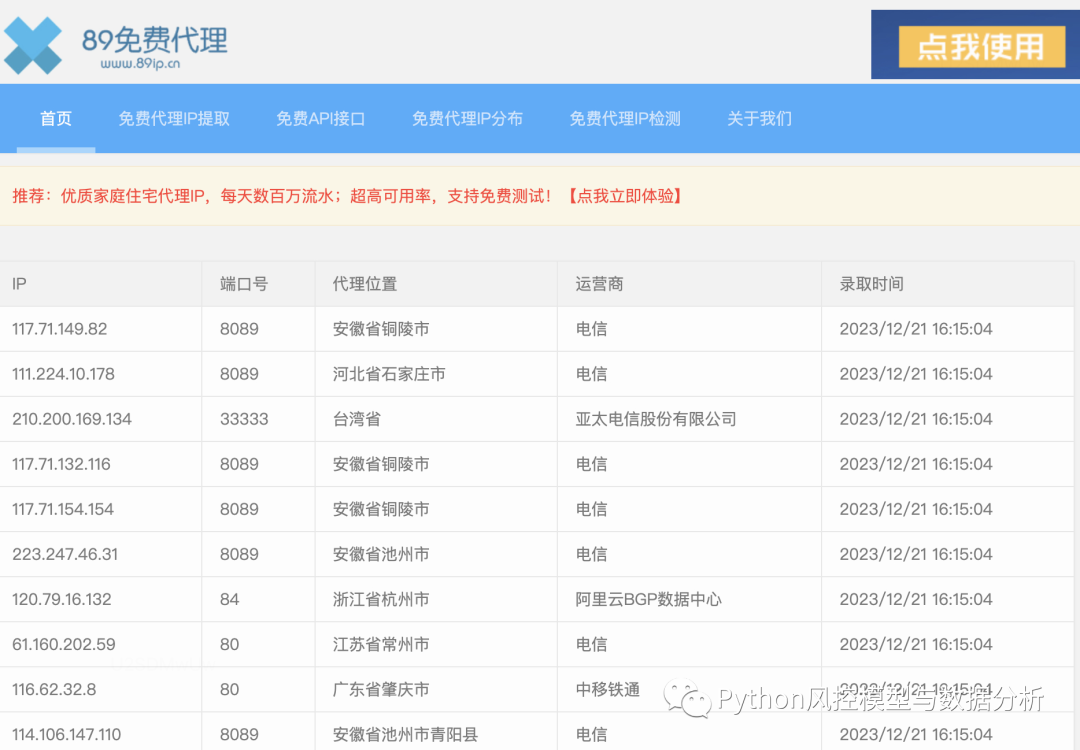
import pandas as pd
url='https://www.89ip.cn/index_1.html'
df=pd.read_html(url,encoding='utf-8')[0]
df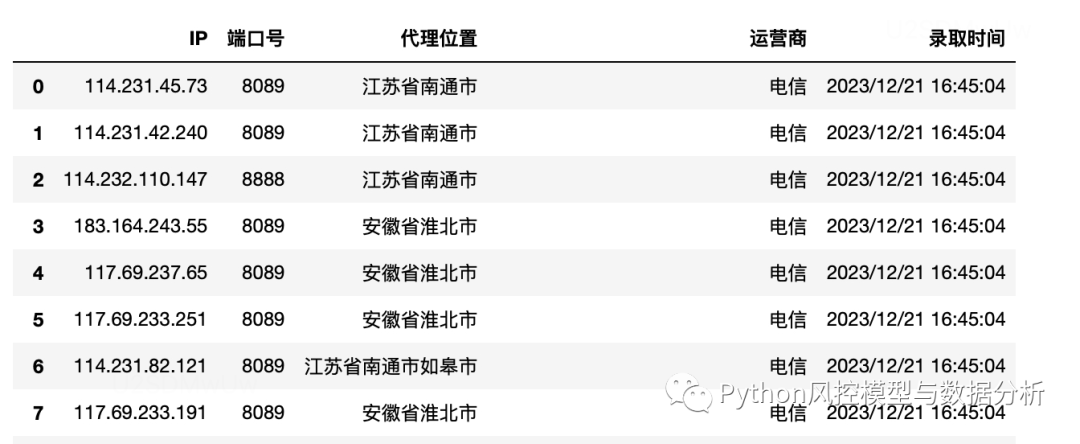
循环爬取多页
l=[]
for i in range(1,10):
url='https://www.89ip.cn/index_{}.html'.format(i)
l.append(pd.read_html(url,encoding='utf-8')[0])
df=pd.concat(l,axis=0).reset_index(drop=True)
print(df.shape)
df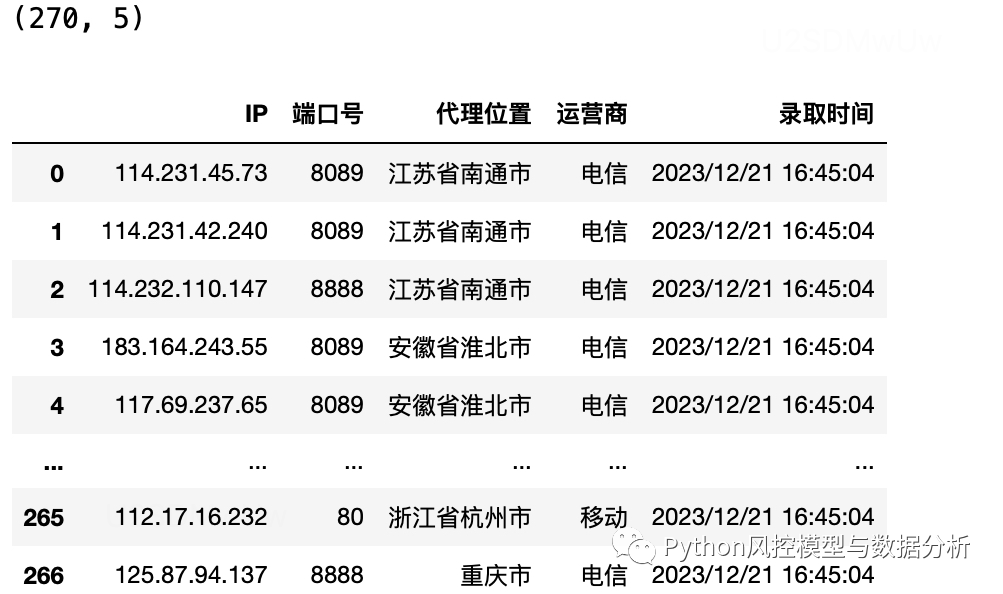
文章来源:https://blog.csdn.net/a7303349/article/details/135204389
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Pandas实战100例 | 案例 29: 时间序列分析 - 滚动窗口计算
- Parade Series - Store
- 远程访问及控制
- 基于Springboot的宠物领养系统(有报告)。Javaee项目,springboot项目。
- 72 DFS解决目标和问题
- Shell扫盲版——建议收藏
- 发布与订阅 geometry_msgs::PoseArray 的消息主题 PoseArrayConstPtr & msg_p 不弹出属性
- IIC协议24c02存储花样灯程序(IIC协议程序)
- SWUSTOJ 142: 猴子报数
- GridControl主从表设置