LLM(八)| Gemini语言能力深度观察

论文地址:https://simg.baai.ac.cn/paperfile/fc2138ce-cadb-4a36-b9f7-c4000dea3369.pdf
? ? ? 谷歌最近发布的Gemini系列模型是第一个在各种任务与OpenAI GPT系列相媲美的模型。在本文中,作者对Gemini的语言能力做了深入的探索,做出了两方面的贡献。首先,提供了OpenAI GPT和Google Gemini模型的能力的第三方客观比较,有可复制的代码和完全透明的结果。其次,仔细观察结果,分析两个模型类各自擅长的领域。在10个数据集上测试了各种语言能力,包括推理、基于知识的问答、数学、机器翻译、代码生成和指令跟随代理。通过分析,发现Gemini Pro在基准测试的所有任务中准确率都接近但略低于GPT 3.5 Turbo。作者对背后的原因做了进一步解释,包括多位数数学推理的失败、对多项选择题排序的敏感性、激进的内容过滤等。可喜的是,作者分析了Gemini比较擅长的领域,包括生成非英语语言,以及处理更长、更复杂的推理链。
PS:复现代码和数据链接:https://github.com/neulab/gemini-benchmark
一、介绍
? ? ? Gemini是谷歌DeepMind发布的一系列大型语言模型中最新的一个。特别值得注意的是,Gemini是首次在各种任务中与OpenAI GPT模型系列相媲美的模型。据报道,Gemini的“Ultra”版本在各种任务上都优于GPT-4,而Gemini的“Pro”版本可与GPT-3.5相媲美。尽管这些结果具有潜在影响,但确切的评估细节和模型预测尚未公布,这限制了复制、检查和分析结果及其影响的能力。
? ? ? ?在本文中,作者对Gemini的语言理解和生成能力进行了深入的探索,目标有两个:
-
为OpenAI GPT和Google Gemini模型提供第三方、客观的比较,提供可复现的代码和完全透明的结果;
-
深入研究两个模型,确定他们各自擅长的领域。
? ? ? ?此外,作者还与最近发布的开源性能比较好的Mixtral模型进行了有限的比较。
? ? ? ?在10个数据集上进行了测试对比,测试了各种文本理解和生成能力,包括基于知识的问答(MMLU)、推理(BigBenchHard)、数学问题(GSM8K)、机器翻译(FLORES),代码生成(HumanEval),指令跟随代理(WebArena)。
? ? ? 结果汇总见表1所示。截至本文撰写之时(2023年12月19日),在所有任务中,Gemini的Pro模型与当前版本的OpenAI的GPT 3.5 Turbo相比,准确率相当但略差。在以下几节中,将详细介绍实验方法(第2节),然后对每个任务的结果进行深入描述和分析。每个分析都附有一个使用Zeno浏览器的在线结果。所有结果和复制代码都可以在https://github.com/neulab/gemini-benchmark找到。

二、实验设置
? ? ? ?在讨论评估结果和发现之前,先来配置一下实验环境,包括测试的模型、模型查询细节和评估过程。
2.1 测试的模型
作者比较了4个模型,如下所示:
Gemini Pro:Gemini系列中第二大模型,仅次于最大的Gemini Ultra。该模型基于Transformer架构,通过视频、文本和图像进行多模式训练。参数的数量和训练数据的大小没有被公开。谷歌关于Gemini的原始论文介绍说其性能与GPT 3.5 Turbo相当。
GPT 3.5 Turbo:OpenAI 的第二大文本大模型,是GPT-3系列的一部分。该模型使用基于人类反馈的强化学习(RLHF)进行了指令微调和训练,但仅在文本上进行训练。同样,模型大小和训练细节没有被公开。
GPT 4 Turbo:多模态GPT-4 系列的第二代模型。turbo版本比最初的GPT-4模型便宜一些(它更有利于基准测试),并且同样缺乏实际训练算法、数据或参数大小的细节。
Mixtral:相比之下,Mixtral是一个开源的专家混合模型,由八个7B参数模型组成。在几个任务上,它的准确率与GPT 3.5?Turbo相当。
2.2 模型访问细节
? ? ? ?在2023年12月11日至15日期间,所有模型都可以通过LiteLLM4提供的统一接口进行访问。Gemini可以使用Google Vertex AI访问,OpenAI模型可以通过OpenAI API访问,Mixtral可以通过Together提供的API进行访问。作为参考,作者还在表2中列出了每个模型通过这些API消耗1M tokens的当前定价。

? ? ? ?需要注意的是,在某些情况下,Gemini Pro会屏蔽一些问题,特别是在潜在非法或敏感话题。被屏蔽的测试样本视为不正确。
2.3?评估过程
? ? ? ?为了在模型之间进行公平的比较,作者对所有模型重新进行了实验,对所有评估的模型使用完全相同的Prompt和评估协议。总的来说,作者遵循标准存储库中的提示和评估者,无论是数据集本身正式发布的,还是Eleuther评估工具。这些Prompt通常包括查询、输入和few-shot示例,有时包括思维链推理。在某些情况下,作者发现有必要对标准实践进行微小的更改,以稳定地评估所考虑的所有模型;所有这些偏差都在下面进行了说明,并在配套代码库中得以实现。
三、基于知识的QA系统
? ? ? ?在这一类别中,关注MMLU的57项基于知识的多项选择题回答任务,这些任务涵盖STEM、人文学科、社会科学等等。MMLU已被广泛用作LLM基于知识能力的整体评估。共有14042个测试样本。
3.1?实验细节
生成参数:在这项任务中测试了两种流行的评估方法,包括Hendrycks等人提出的的标准5-shot Prompt和来自chain-of-thought-hub带前缀为“Let’s think step by step.”的5-shot CoT Prompt。请注意,作者选择不采样多个响应,像Gemini团队所做的那样执行基于自一致性的重新排序,因为这会显著增加成本,在许多情况下可能不可行。作者还通过设置温度为0进行贪婪搜索生成。
评估:对于标准提示,作者直接将模型生成的第一个字符作为他们的答案,因为这就是5-shot prompt的含义。有时,模型可能不遵循这种格式,而在其他地方输出答案。作者认为这样的例子是不正确的(并在下一节中详细说明其影响)。对于CoT prompt,从模型的响应中提取答案,如果无法提取答案,则将默认答案设置为“C”,就像在chain-of-thought-hub中所做的那样。
3.2?结果与分析
? ? ? ?在本节中,比较和分析了MMLU的总体性能、子任务的性能和输出长度的性能。
? ? ? ?首先,从图1所示的总体结果中,可以看到Gemini Pro的准确率低于GPT 3.5 Turbo,也远低于GPT 4 Turbo。还发现使用CoT提示在性能上几乎没有差异,这可能是因为MMLU主要是一种基于知识的问答任务,可能不会从更强的推理导向提示中受益。

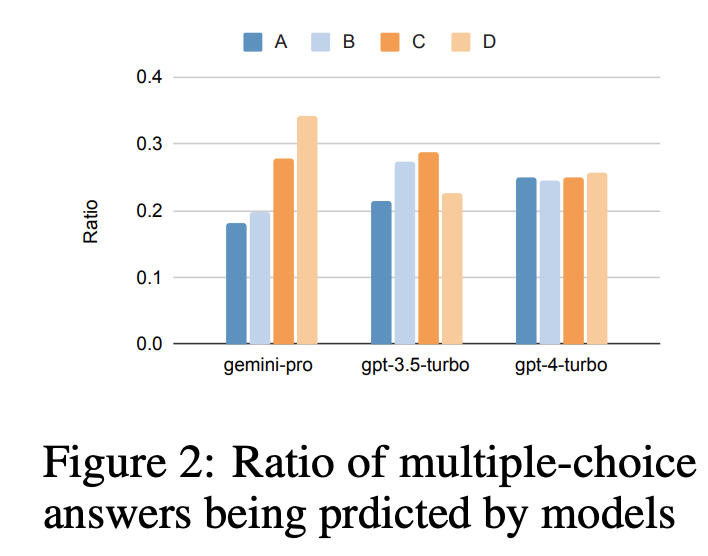
? ? ? ?基于这一总体结果,作者进行了更深入的研究。第一个值得注意的点是,MMLU中的所有问题都是多项选择题,4个潜在答案的顺序为A到D。在图2中,显示了每个模型选择每个多项选择答案的次数的比率。从这个图中,可以看到Gemini的标签分布非常偏斜,偏向于选择“D”的最终选择,这与GPT模型的结果形成了对比,后者更平衡。这可能表明Gemini没有在解决多项选择题方面进行大量的教学调整,这可能会导致模型在答案排序方面存在偏差。
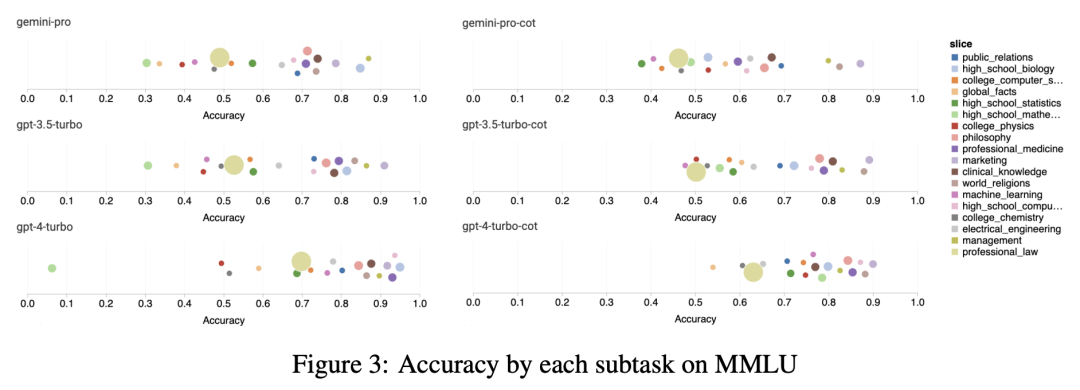
? ? ? ?接下来,检查每个子任务的性能。图3展示了每个模型在选定的代表性任务上的性能。我们注意到,与GPT 3.5相比,Gemini Pro在大多数任务中表现不佳。CoT提示可以减少子任务之间的差异。
? ? ? 此外,作者深入研究了Gemini Pro表现不佳/优于GPT 3.5的任务。从图4中,可以观察到Gemini Pro在人文(社会科学)、形式逻辑(人文)、初等数学和专业医学(专业领域)方面落后于GPT 3.5(STEM)。对于Gemini Pro表现优于GPT 3.5 Turbo的两项任务,收益微乎其微。

? ? ? ?Gemini Pro在特定任务上表现不佳可归因于两个原因。首先,如前面第2.2小节所述,在某些情况下,Gemini未能返回答案。在大多数MMLU子任务中,API的响应率大于95%,但有两个任务的响应率明显较低:moral_securations为85%,human_securrence为28%。这表明某些任务的低性能可归因于输入上的内容过滤器。第二,Gemini Pro表现在解决形式逻辑和初等数学任务所需的基本数学推理方面稍有不足,将在第4节中对此进行进一步研究。
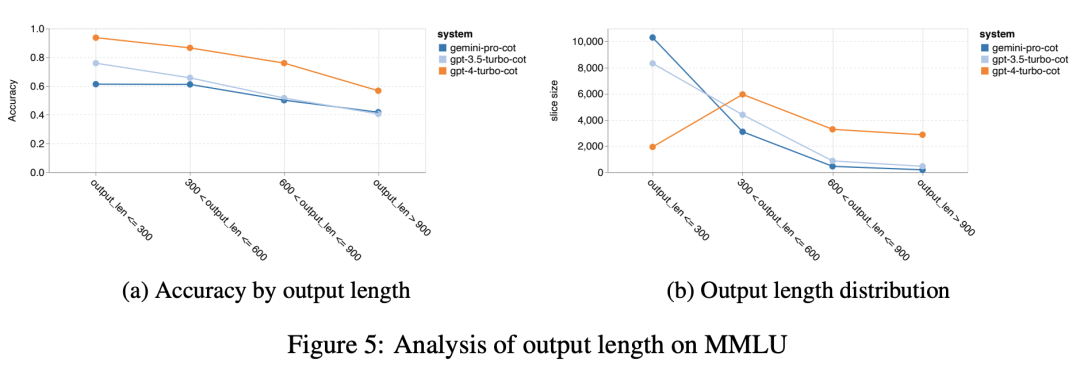
? ? ? 最后,在图5中分析了CoT提示输出长度如何影响模型性能。一般来说,更强的模型往往会执行更复杂的推理和从而输出更长的响应。值得注意的是:与两款同类产品相比,Gemini Pro的优点之一是其精度受输出长度的影响较小。当输出长度超过900时,它甚至优于GPT 3.5。然而,也可以看出,与GPT 4 Turbo相比,Gemini Pro和GPT 3.5 Turbo很少输出这些长的推理链。
四、通用推理
? ? ? 在这一类别中,我们专注于BIG-Bench Hard中的27项不同推理任务,包括算术、符号和多语言推理以及事实知识理解任务。大多数任务由250个问答对组成,少数任务则更少。
4.1 实验细节
生成参数:在所有模型中都遵循Eleuther规则采用标准3-shot prompt,每个问题后面都有一个思想链,在最后一句添加总结句:“So the answer is___.”。对于超参数,设置温度为0来执行贪婪解码。
评估:BIG-Bench Hard的Eleuther评估与句子“So the answer is ___.”匹配,并提取文本。然而,作者发现,对于一些模型,即使在生成正确答案的情况下,他们也不会逐字逐句地生成这句话,特别是在选择题任务中,答案是从问题文本中选择的选项(例如,“答案:(B)”)。为了解决这一问题,作者修改了匹配规则,在多项选择题任务中只使用生成文本的最后一个单词作为问题的答案。
4.2?结果分析
? ? ? ?对于推理任务,作者分析了总体性能、问题复杂性的性能和BIG-Bench子任务的性能。
? ? ? ?首先,在图6中说明了总体精度,可以看到Gemini Pro的精度略低于GPT 3.5 Turbo,远低于GPT 4 Turbo。相比之下Mixtral模型的精度要低得多。

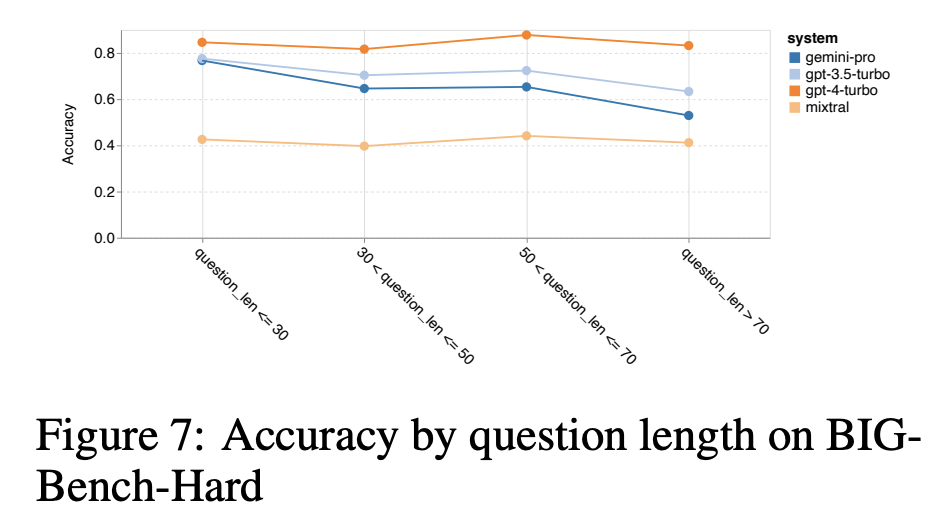
? ? ? ?基于这一总体结果,让我们更深入地探究为什么Gemini可能表现不佳。首先,通过问题的长度来检验准确性,如图7所示,发现Gemini Pro在更长、更复杂的问题上表现不佳,而GPT模型对此更为稳健。GPT 4 Turbo的情况尤其如此,即使在较长的问题上也表现出很少的退化,这表明它具有令人印象深刻的强大能力,能够理解越来越多的问题复杂的查询。GPT 3.5 Turbo在这种鲁棒性方面处于中间位置。Mixtral在问题长度方面明显稳定,但总体准确度较低。
? ? ? ?接下来,来看看BIG-Bench Hard中特定任务的准确性是否存在差异。下面列出了GPT 3.5 Turbo表现优于Gemini Pro的最大任务。
? ? ? ?可以注意到Gemini Pro在“tracking_shuffled_objects”任务方面特别糟糕。这些任务包括在人与人之间交易时跟踪谁拥有某些物品,以及Gemini?Pro通常很难保持秩序(如图8所示)。

? ? ? 在一些任务中,比如multistep_arithmetic_two, salient_translation_error_detection,snarks, disambiguition_qa and two of tracking_shuffled_objects任务,Gemini Pro的性能甚至比Mixtral模型差。
? ? ? ?然而,在一些任务中,Gemini Pro的表现优于GPT 3.5 Turbo。图9显示了Gemini Pro表现优于GPT 3.5 Turbo的六项任务。这些是异构的,包括那些需要世界知识(sports_understanding)、操作符号堆栈(dyck_languages)、按字母顺序对单词排序(word_sorting)的内容,以及解析表格(penguins_in_a_table)等。

? ? ? 在下图中进一步研究了LLM在不同答案类型中的稳健性。可以看到Gemini Pro在有效/无效答案类型中表现最差,该类型属于任务formal_flularies。有趣的是,该任务中68.4%的问题被阻止。然而,Gemini在其他答案类型(包括word_sorting和dyck_language任务)上的表现明显优于所有GPT模型和Mixtral,这与上述发现相似,即Gemini特别擅长单词重排和按正确顺序生成符号。同样在MCQ的回答中,4.39%的问题被Gemini Pro屏蔽,尽管GPT模型在这一类型中表现出色,但Gemini很难与之竞争。
? ? ? ?总之,似乎没有一种特别强烈的趋势,即一个模型的任务比另一个模型执行得更好,因此当执行通用推理任务时,可能值得同时尝试Gemini和GPT模型,然后再决定使用哪个。
五、数学
? ? ? 为了评估评估模型的数学推理能力,探索了四个数学单词问题基准(1)小学数学基准GSM8K,(2)SVAMP数据集,其中问题由不同的语序生成,以检查鲁棒推理能力,(3)具有不同语言模式和问题类型的ASDIV数据集,以及(4)由算术和代数单词问题组成的MAWPS基准。
5.1?实验细节
生成参数:采用标准的8-shot CoT提示,其中few-shot提示中的每个问题都与生成相应答案的思维链相关联。同样使用温度为0来进行贪婪解码评估所有LLM。
评估:在评估中,对Eleuther中的标准评估协议进行了轻微修改,该协议根据数字输出匹配单词“The answer is”。作者发现,即使没有这个特定的短语,所有评估的模型都有输出正确答案的趋势。为了缓解这种情况,作者简单地将生成文本的最后一个数字作为问题的答案,反而总体的准确率更高了。
5.2?结果分析
? ? ? ?在本节中,比较了Gemini Pro与GPT 3.5 Turbo、GPT 4 Turbo和Mixtral在四个数学单词问题任务上的准确性,考察了整体性能、按问题复杂性划分的性能和按思维链深度划分的性能。
? ? ?首先,从图11中的总体结果来看,可以看到Gemini Pro在GSM8K、SVAMP和ASDIV任务上的精度略低于GPT 3.5 Turbo,远低于GPT 4 Turbo,这些任务都包含不同的语言模式。对于MAWPS任务,所有模型都实现了90%以上的准确率,尽管Gemini Pro仍然比GPT型号略差。有趣的是,在这项任务中,GPT 3.5 Turbo的性能远远优于GPT 4 Turbo。相比之下,Mixtral模型实现的精度比其他模型低得多。

? ? ? ?与第4节类似,在图12中对结果进行分解,以观察每个模型对问题长度的稳健性。与BIG-Bench Hard中的推理任务一样,看到较长的问题性能有所减少。和以前一样,GPT 3.5 Turbo在性能上优于Gemini Pro问题更短,但下降得更快,Gemini Pro实现了在较长问题上的准确性相似(但仍稍差)。
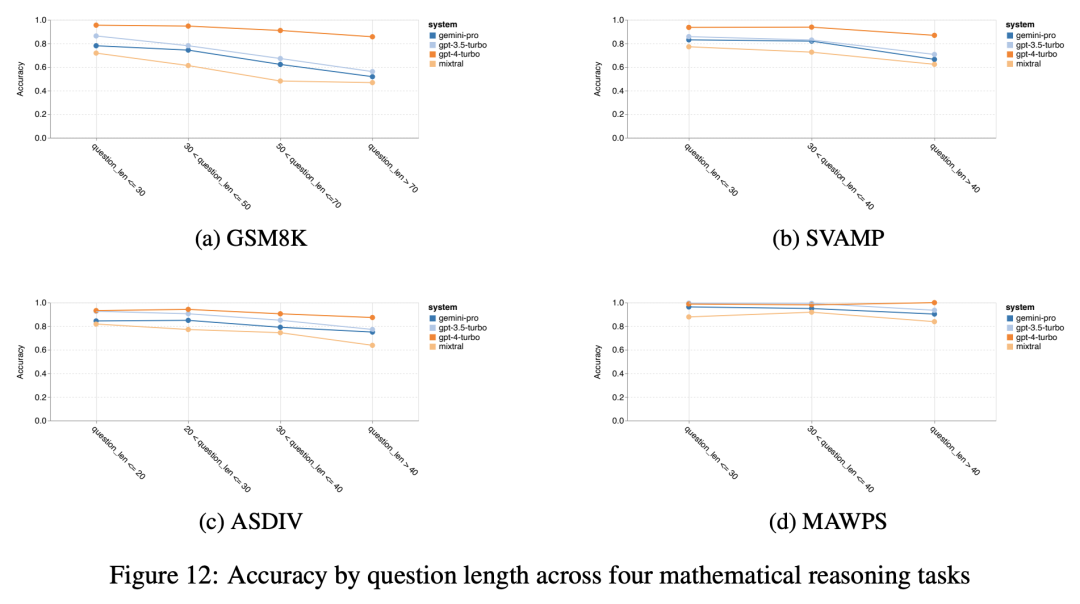
? ? ? ?此外,当答案需要更长的思维链时,我们观察LLM的准确性。如图13所示,即使使用长推理链,GPT 4 Turbo也非常健壮,其中GPT 3.5 Turbo、Gemini Pro和Mixtral在不断增加的COT长度方面举步维艰。在该分析中,还发现Gemini Pro在COT长度超过100的最复杂示例中优于GPT 3.5 Turbo,但在较短的示例中表现不佳。

? ? ? ?最后,比较了模型在生成不同位数的答案时的准确性。根据答案中的位数创建三个桶,即1、2或3+(MAWPS任务除外,该任务的答案不超过两位数)。如图14所示,GPT 3.5 Turbo似乎对多位数的数学问题更具鲁棒性,其中Gemini Pro在多位数的问题上会退化更多。

六、代码生成
? ? ? ?在这一类别中,作者使用了两个代码生成数据集HumanEval和ODEX来测试模型的编码能力。前者测试Python标准库中部分函数的基本代码理解,而后者测试整个Python生态系统中更广泛的一组库的能力。这两个数据集都是英语人工书写的任务描述作为输入(通常带有测试用例)。这些问题评估了语言、算法理解和初等数学的解释。总体而言,HumanEval有164个测试样本,ODEX有439个测试样本。
6.1 实验细节
生成参数:遵循由ODEX8提供的标准zero-shot代码评估pipeline。选择推荐的超参数,温度为0.8,top_p为0.95。作者还添加了一条自定义指令“Complete the given code with no more explanation. Remember?that there is a 4-space indent before the first line of your generated code.”以确保模型的输出符合所需的格式。
评估:使用pass@1指标来评估,用于确定模型中的单个样本是否通过测试用例。由于代码生成是以zero-shot的方式评估的,因此模型可能不可避免地输出与我们的输入格式不符的代码。因此,我们需要基本的后处理操作来调整输出代码,并使其尽可能符合最终评估pipeline,包括删除标记代码块、提取函数实现和截断停止token。值得注意的是,对于格式不正确的缩进,我们无法手动修复而是将它们视为典型的语法错误。
6.2?结果分析
? ? ? ?在本节中,将测试总体性能,并介绍代码生成的案例研究。
? ? ? ?首先,从图15所示的总体结果中,我们可以看到Gemini Pro pass@1在两个任务上都低于GPT 3.5 Turbo并且远低于GPT 4 Turbo。结果表明Gemini的代码生成能力仍有改进的空间。

? ? ? ?其次,分析了标注答案长度与模型性能之间的关系,如图16a中。答案的长度可以部分地指示解决相应代码生成任务的难度。发现,Gemini Pro在答案长度低于100时(例如,在更容易的情况下),pass@1与GPT 3.5相对,但在答案变长时会以很大的幅度落后。这与前几节的结果形成了有趣的对比,在前几节中,发现Gemini Pro在英语任务的较长输入和输出方面总体表现稳健。
? ? ? ?在图16b中,还分析了每个答案所需的库如何影响模型性能。Gemini Pro在大多数库用例(如mock、pandas、numpy和datetime)上的性能都比GPT 3.5差。然而,在matplotlib情况下,它的性能优于GPT 3.5和GPT 4,在通过代码执行绘图可视化时显示出更强的功能。

? ? ? ?最后,展示了几个失败案例的具体例子,其中Gemini Pro在代码生成方面的表现比GPT 3.5差。首先,注意到Gemini在选择Python API中的函数和参数比较差。例如,给定以下提示:
def f_3283984():"""decode a hex string '4a4b4c' to UTF-8."""
? ? ? ? Gemini Pro生成了以下代码,导致类型不匹配错误:
bytes(bytearray.fromhex('4a4b4c'), 'utf-8')? ? ? ? 相比之下,GPT 3.5 Turbo使用了以下代码,从而达到了预期的结果:
hex_string = '4a4b4c'decoded_string = bytes.fromhex(hex_string).decode('utf-8')return decoded_string
? ? ? ?此外,Gemini Pro错误比例更高,其中实现的代码在语法上是正确的,但与更复杂的意图不能正确匹配。例如,关于以下提示:
from typing import Listdef remove_duplicates(numbers: List[int]) -> List[int]:"""From a list of integers, remove all elements that occur more than once.Keep order of elements left the same as in the input.>>> remove_duplicates([1, 2, 3, 2, 4])[1, 3, 4]"""
? ? ? ?Gemini Pro只提取唯一数字而没有删除出现两次以上的数字。
seen_numbers = set()unique_numbers = []for number in numbers:if number not in seen_numbers:unique_numbers.append(number)seen_numbers.add(number)return unique_numbers
七、机器翻译
? ? ? ?这组实验评估了模型的多语言能力,特别是使用FLORES-200机器翻译基准测试各种语言对之间进行翻译的能力。重点测试Robinson等人分析所使用的20种语言的不同子集,其中包括不同级别的资源可用性和翻译难度。作者对测试集中所有所选语言对的1012个句子进行评估。作为这项研究的第一步,作者将研究范围限制在从英语到其他语言的翻译(ENG→X)。
7.1 实验细节
生成参数:研究zero-shot和5-shot prompt策略在20对语言中的效果。使用zero-shot和few-shot机器翻译(MT)提示进行测试,如表8所示,这些提示设置对大型语言模型(LLM)的用户显示出明显的优势。实验设置采用了top_p值为1、温度为0.3、context_length为-1和max_tokens 500来优化翻译模型的性能。
评估:为了评估输出,作者使用了以下指标:
- spBLEU:BLEU是机器翻译评估的一个标准。作者使用带有SPM-200标记器的sacreBLEU工具包来计算spBLEU分数;
- chrF2++:使用sacreBLEU实现的chrF2++指标进行评估,这个指标能够解决BLEU的一些局限性。为了简单起见,在讨论中将该指标称为chrF。
7.2 结果分析
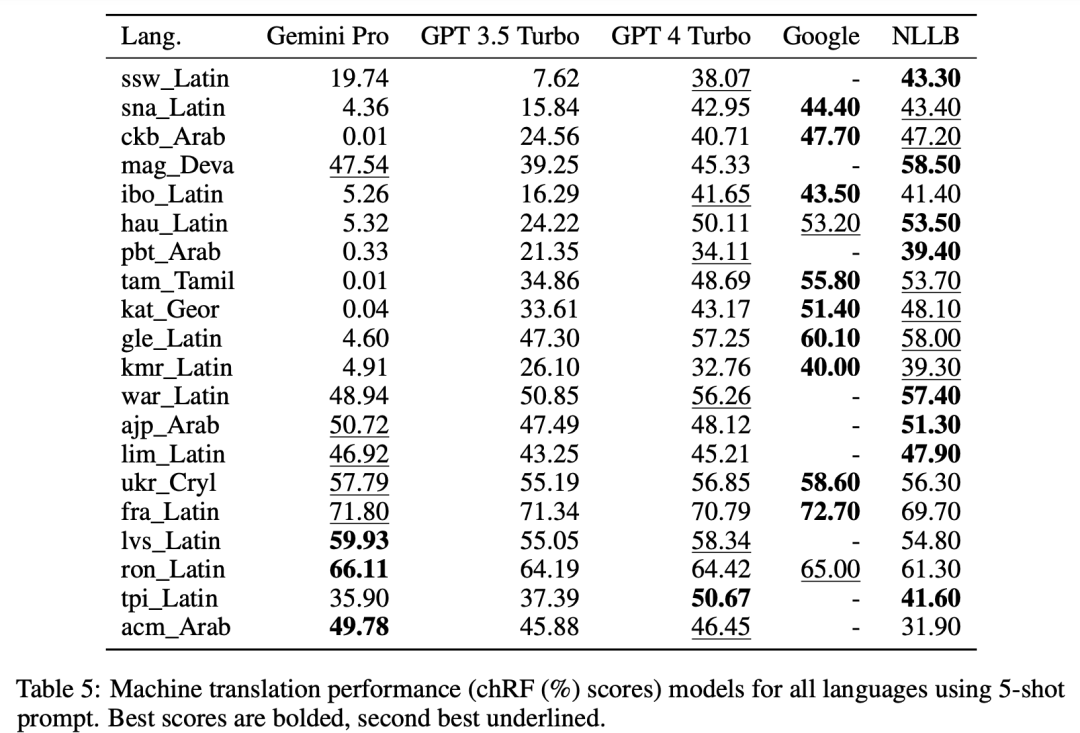
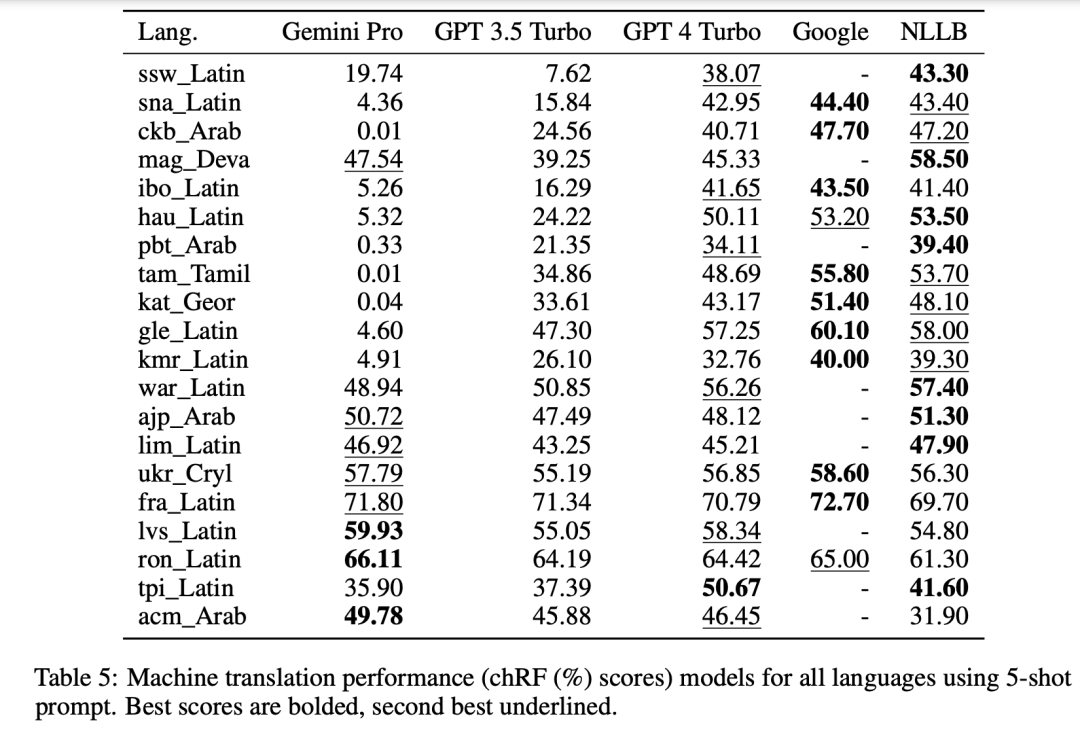
? ? ? ? 总体性能在表4和表5中,对Gemini Pro、GPT 3.5 Turbo和GPT 4 Turbo与谷歌翻译等进行了系统性的比较分析。此外,还使用了NLLB MoE基准(这是一种领先的开源机器翻译(MT)模型,以其广泛的语言覆盖范围而闻名)。结果表明,谷歌翻译通常优于其他模型,在9种语言方面表现出色,其次是NLLB,在0/5-shot设置下,它在6和8种语言方面都表现出色。通用语言模型在翻译非英语语言方面表现出很强的竞争力,但尚未超过专用机器翻译系统。

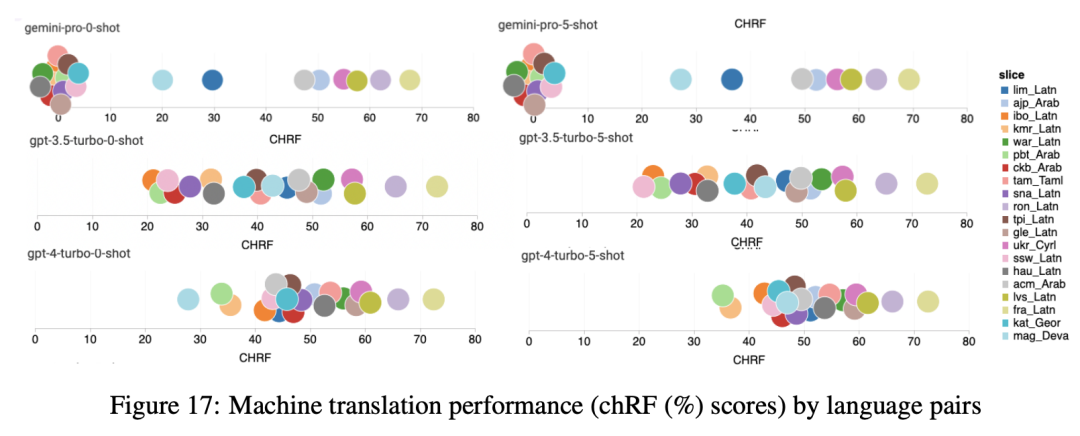
? ? ? 图17展示了跨语言对的通用语言模型的比较性能。相对于GPT 3.5 Turbo和Gemini Pro,GPT 4 Turbo与NLLB的性能表现出一致的偏差。这验证了GPT 4 Turbo在OpenAI公开文献中描述的的多语言性能,GPT 4 Turbo在低资源语言有更大的改进,而对于高资源语言,LLM之间的性能相似。相比之下,Gemini Pro在20种语言中的8种语言上都优于GPT 3.5 Turbo和GPT 4 Turbo,并在4种语言上实现了最高性能。然而,Gemini?Pro在大约10对语言中表现出强烈的屏蔽反应的倾向,我们将在下一次分析中对此进行进一步研究。
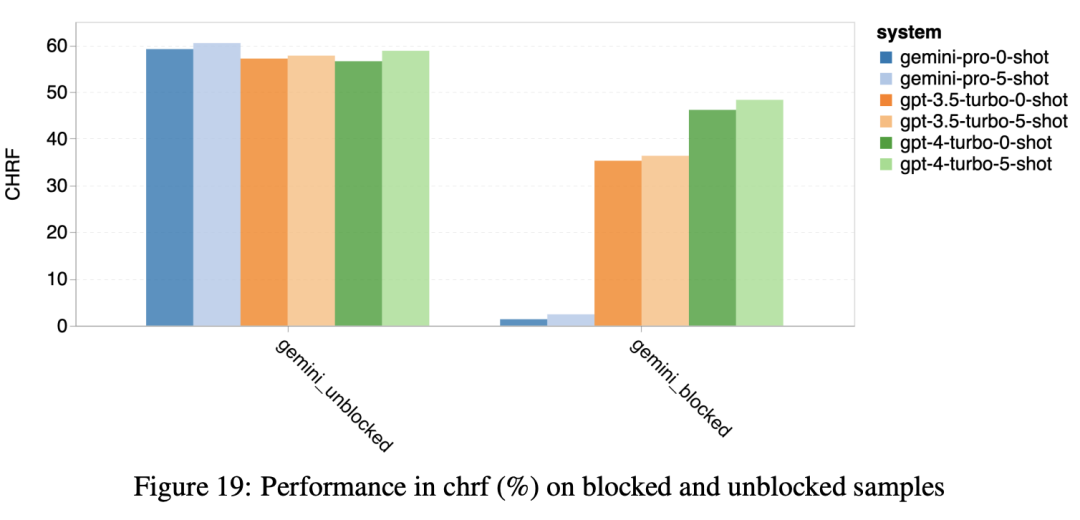
? ? ? ?Gemini响应被过滤:图18强调了Gemini Pro在这些语言中的较低性能是由于它倾向于阻止置信度较低的情况下的响应。如果Gemini Pro在0-shot或5-shot配置中产生“阻止响应”错误,则响应被视为“阻止”。图19揭示Gemini Pro在未阻塞样本中略微优于GPT 3.5 Turbo和GPT 4 Turbo,其表现更高的置信度。具体而言,它在5-shot设置中比GPT 4 Turbo高1.6 chrf,在0-shot设置中超过2.6 chrf;并在5-shot和0-shot设置中分别比GPT 3.5 Turbo高2.7?chrf和2个chrf。然而,从GPT 4 Turbo和GPT 3.5 Turbo在这些样本的表现说明它们更难翻译。Gemini Pro在这些特定样品上的较差性能在Gemini Pro 0-shot阻止响应但5-shot不阻止响应的情况下尤其明显,反之亦然。

其他趋势:从模型的整个分析可以看到,few-shot提示方差一次增加的顺序如下:GPT 4 Turbo<GPT 3.5 Turbo<Gemini Pro。虽然Gemini Pro的5-shot提示在表现出自信的语言中比0-shot提示有所改进,但在某些语言中,如hau_Latin,该模型表现出明显的自信降低,导致反应受阻(参见表5)。
八、网络Agent
? ? ? ?最后,我们检查了每个模型作为网络导航代理的能力,这项任务需要长期规划和复杂的数据理解力。作者使用WebArena,这是一个基于执行的模拟环境,成功标准基于执行结果。分配给代理的任务包括信息搜索、站点导航以及内容和配置操作。任务涵盖各种网站,包括电子商务平台、社交论坛、协作软件开发平台(如gitlab)、内容管理系统和在线地图。
8.1 实验细节
生成参数:在测试Gemini时遵循WebArena的测试方法。使用了周等人的2-shot CoT提示,其中每个提示包括两个CoT风格的例子。进一步区分了当模型认为任务无法实现时是否指示其终止执行(“无法实现”提示,或WebArena中的UA)。
? ? ? 总之,作者使用WebArena的两个提示进行了测试:p_cot_id_actree_2s和p_cot_id_actree_2s_no_na,这两个提示分别是带有UA提示的cot提示和不带UA提示的cot提示。为了使GPT和Gemini之间的结果具有可比性,我们设置了相同的上限所有观测长度的限制。使用gpt-4-1106-preview的tokenizer将这个数字设置为1920个token,与WebArena中的实验一致。在超参数方面,作者使用了每个大型语言模型提供者建议的默认值。对于Gemini模型,建议的默认温度为0.9,默认top-p为1.0,WebArena建议的GPT模型默认温度为1.0,top-p为0.9。
评估:只有agent可以完成最终目标,就认为agent的行动顺序是正确的,无论他们采取了什么中间步骤。使用WebArena的评估,通过代理的最终输出来确定任务是否成功完成。少数响应被Gemini API阻止(约占总测试案例的2%),在实验中将这些响应视为失败轨迹。
8.2 结果分析
? ? ? ?作者研究了Gemini Pro的总体成功率、不同任务的成功率、响应长度、轨迹步数,以及预测任务无法实现的趋势。总体性能如表6所示。Gemini Pro的性能与GPT-3.5-Turbo相当,但略差。与GPT-3.5m-Turbo类似,当提示提到任务可能无法实现时,Gemini Pro的性能更好(UA提示)。使用UA提示,Gemini Pro的总体成功率为7.09%。

? ? ? ?如果按网站细分,如图21所示,我们可以看到Gemini Pro在gitlab和地图上的表现比GPT-3.5-Turbo差,而在购物管理、reddit和购物方面则接近GPT-3.5-Turbo。它在多站点任务上的性能优于GPT-3.5-Turbo,这与我们之前的研究结果一致,即Gemini在跨基准测试的更复杂的子任务上表现得更好。

? ? ? ? 一般来说,Gemini Pro预测更多的任务无法实现,特别是在给出UA提示的情况下,如图22所示。Gemini Pro预测,当给出UA提示时,超过80.6%的任务是无法实现的,而GPT-3.5-Turbo预测的这一比例为47.7%。请注意,数据集中4.4%的任务实际上是不可实现的,因此两者都高估了无法实现任务的实际数量。

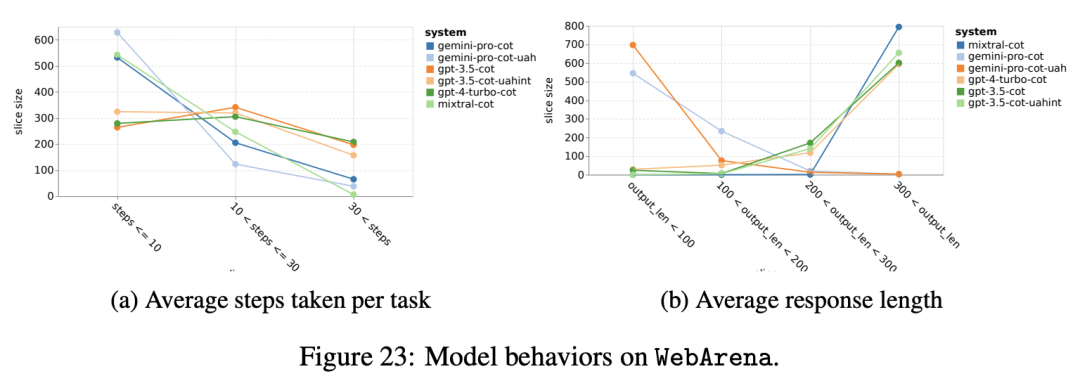
? ? ? ?同时,观察到Gemini Pro更倾向于用更短的短语做出回应,在得出结论之前采取更少的步骤。如图23a所示,Gemini Pro超过一半的轨迹在10步以下,而GPT 3.5 Turbo和GPT 4 Turbo的大多数轨迹在10到30步之间。类似地,大多数Gemini响应的长度小于100个字符,而大多数GPT 3.5 Turbo、GPT 4 Turbo和Mixtral的响应的长度超过300个字符(图23b)。Gemini倾向于直接预测行动,而其他模型则从推理开始,然后给出他们的行动预测。
九、结论
? ? ? ?在本文中,首次公正、深入地研究了谷歌的Gemini模型,将其与OpenAI的GPT 3.5和4模型以及开源的Mixtral模型进行了比较。
9.1 核心结论:
- Gemini Pro模型在模型大小和级别上与GPT 3.5 Turbo相当,其精度通常与GPT 3.5Turbo相当,但略逊于GPT 4。在测试的每一项任务上都优于Mixtral;
- 特别是,我们发现Gemini Pro的平均性能略低于GPT 3.5 Turbo,但特别是在多项选择题、大数字数学推理、代理任务提前终止等问题上存在对回答顺序的偏见作为由于积极的内容过滤而导致的失败响应;
- 另一方面,Gemini在特别长和复杂的推理任务中表现优于GPT 3.5 Turbo,在没有过滤响应的任务中也擅长使用多种语言。
9.2 局限性
? ? ? 首先,我们的工作是关于不断变化和不稳定的基于API的系统的快照。截至2023年12月19日撰写本文时,这里的所有结果都是最新的,但随着模型和周围系统的升级,未来可能会发生变化。
? ? ? ?其次,结果可能取决于我们选择的特定提示和生成参数。很有可能,随着进一步的快速工程,或者Gemini团队使用的多个样本和自洽性,结果可能会发生重大变化。然而,我们认为,在具有标准提示的几个任务上的一致结果合理地表明了测试模型的稳健性和广义指令跟随能力。
? ? ? ?最后,如果不讨论数据泄露问题,任何基准测试论文都是失职的,这会困扰当前对大型语言模型的评估。虽然我们没有明确衡量这种泄漏,但我们确实试图通过评估各种任务来缓解,包括那些输出不是来自互联网或在互联网上广泛可用的任务(如WebArena)。
9.3 展望
? ? ? ?基于这篇论文,作者可以建议研究人员和从业者仔细研究Gemini Pro模型,将其作为工具箱中的工具,与GPT 3.5 Turbo相媲美。Gemini的Ultra版本尚未发布,据报道与GPT 4不相上下当这个模型可用时,将保证对其进行检查。
参考文献:
[1]?https://simg.baai.ac.cn/paperfile/fc2138ce-cadb-4a36-b9f7-c4000dea3369.pdf
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!