ToolLearning Eval:CodeFuse发布首个中文Function Call的大语言模型评测基准!

1.?背景
随着ChatGPT等通用大模型的出现,它们可以生成令人惊叹的自然语言,使得机器能够更好地理解和回应人类的需求,但在特定领域的任务上仅靠通用问答是无法满足日常工作需要。随着OpenAI推出了Function Call功能,工具学习能力越来越作为开源模型的标配,目前业界较有影响力的是ToolBench的英文数据集。但是中文数据集的稀缺,使得我们很难判断各个模型在中文型工具上Function Call的能力差异。
为弥补这一不足,CodeFuse发布了首个面向ToolLearning领域的中文评测基准ToolLearning-Eval,以帮助开发者跟踪ToolLearning领域大模型的进展,并了解各个ToolLearning领域大模型的优势与不足。ToolLearning-Eval按照Function Call流程进行划分,包含工具选择、工具调用、工具执行结果总结这三个过程,方便通用模型可以对各个过程进行评测分析。
目前,我们已发布了第一期的评测榜单,首批评测大模型包含CodeFuse、Qwen、Baichuan、Internlm、CodeLLaMa等开源大语言模型;我们欢迎相关从业者一起来共建ToolLearning Eval项目,持续丰富ToolLearning领域评测题目或大模型,我们也会定期更新评测集和评测榜单。
ModelScope 地址:devopseval-exam
2.?评测数据
2.1.?数据来源
ToolLearning-Eval最终生成的样本格式都为Function Call标准格式,采用此类格式的原因是与业界数据统一,不但能够提高样本收集效率,也方便进行其它自动化评测。经过统计,该项目的数据来源可以分为3类:
- 开源数据:对开源的ToolBench原始英文数据进行清洗;
- 英译中:选取高质量的ToolBench数据,并翻译为中文;
- 大模型生成:采用Self-Instruct方法构建了中文 Function Call 训练数据&评测集;
我们希望越来越多的团队能参与到中文的functioncall数据构建,共同优化模型调用工具的能力。我们也会不断地强化这部分开源的数据集。
2.2.?数据类别
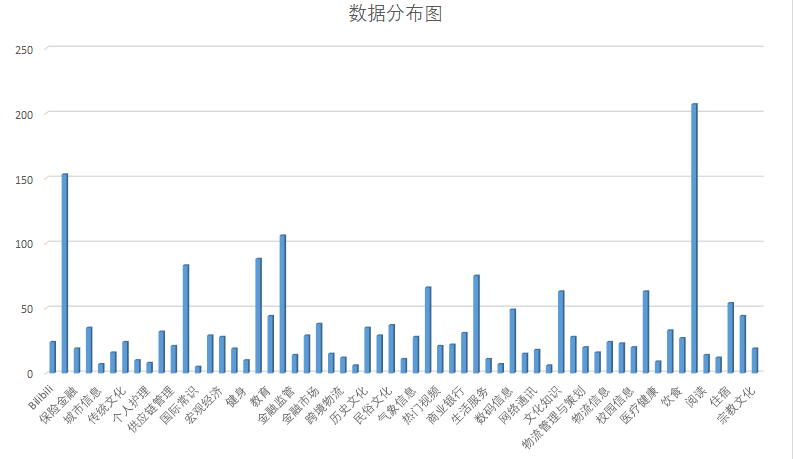
ToolLearning-Eval里面包含了两份评测集,fcdata-zh-luban和fcdata-zh-codefuse。里面总共包含 239 种工具类别,涵盖了59个领域,包含了1509 条评测数据。ToolLearning-Eval的具体数据分布可见下图
2.3.?数据样例
在数据上我们完全兼容了 OpenAI Function Calling,具体格式如下:
Function Call的数据格式
| Input Key | Input Type | Input Description |
| functions | List[Swagger] | 工具集合 |
| chatrounds | List[chatround] | 多轮对话数据 |
chatrounds的数据格式
| Input Key | Input Type | Input Description |
| role | string | 角色名称,包含三种类别,user、assistant、function |
| name | string | 若role为function,则存在name字段,为function的名称 |
| content | string | role的返回内容 |
| function_call | dict | 工具调用 |
{
"functions":
[
{
"name": "get_fudan_university_scoreline",
"description": "查询复旦大学往年分数线,例如:查询2020年复旦大学的分数线",
"parameters":
{
"type": "object",
"properties":
{
"year":
{
"type": "string",
"description": "年份,例如:2020,2019,2018"
}
},
"required":
[
"year"
]
}
}
],
"chatrounds":
[
{
"role": "system",
"content": "CodeFuse是一个面向研发领域的智能助手,旨在中立的、无害的帮助用户解决开发相关的问题,所有的回答均使用Markdown格式返回。\n你能利用许多工具和功能来完成给定的任务,在每一步中,你需要分析当前状态,并通过执行函数调用来确定下一步的行动方向。你可以进行多次尝试。如果你计划连续尝试不同的条件,请每次尝试一种条件。若给定了Finish函数,则以Finish调用结束,若没提供Finish函数,则以不带function_call的对话结束。"
},
{
"role": "user",
"content": "查询2020年复旦大学的分数线"
},
{
"role": "assistant",
"content": null,
"function_call":
{
"name": "get_fudan_university_scoreline",
"arguments": "{\n \"year\": \"2020\"\n}"
}
},
{
"role": "function",
"name": "get_fudan_university_scoreline",
"content": "{\n \"scoreline\":{\n \"文科一批\": 630, \n \"文科二批\": 610, \n \"理科一批\": 650, \n \"理科二批\": 630 \n }\n}"
},
{
"role": "assistant",
"content": "2020年复旦大学的分数线如下:\n\n- 文科一批:630分\n- 文科二批:610分\n- 理科一批:650分\n- 理科二批:630分"
}
]
}上述Function Call的数据样例为给定特定工具集后,用于回答用户查询某高校录取分数线的问题。此外限于篇幅,此处不再其它工具使用样例,具体可以查看HuggingFace数据集。
2.4.?数据下载
- 方法一: 直接下载(用浏览器打开下面的链接)
- 方法二:使用ModelScope datasets库函数
from modelscope.msdatasets import MsDataset
MsDataset.clone_meta(dataset_work_dir='./xxx', dataset_id='codefuse-ai/devopseval-exam')
sample_data
|- sampleData.json # 数据样例
train_data
|- fcdata_toolbenchG1.jsonl # 72783 toolbenchG1整理数据
|- fcdata_toolbenchG2.jsonl # 29417 toolbenchG2整理数据
|- fcdata_toolbenchG3.jsonl # 24286 toolbenchG3整理数据
|- fcdata_toolbenchG1_zh.jsonl # 16335 toolbenchG1部分中文翻译数据
|- fcdata_zh_train_v1.jsonl # 72032 自有采集生成的数据V1
|- fcdata_zh_train_luban.jsonl # 10214 自有采集生成的数据luban
test_data
|- fcdata_zh_test_v1.jsonl # 1250 自有采集生成的测试数据V1
|- fcdata_zh_test_luban.jsonl # 259 自有采集生成的测试数据luban3.?评测设置
3.1.?评测模型
一期我们选取了比较热门的不同参数大小、不同机构发布的通用大模型和CodeFuse大模型,具体细节如下表。后续我们也会评测更多其他的大模型。
| 模型名称 | 参数量 |
| Qwen-7B-Chat | 7B |
| Qwen-14B-Chat | 14B |
| Baichuan2-7B-Chat | 7B |
| Internlm-7B-Chat | 7B |
| CodeLLaMA | 7B |
| CodeFuse-4k | 7B |
| CodeFuse-16k | 7B |
3.2.?评测指标
由于一般通用模型无法具备工具调用的能力,因此在进行Tool Learn-Eval评测之前需要对通用模型进行微调,先让模型学会工具使用的基本范式
下面,我们定义了几种评估工具使用的指标:

②③④⑤的和为1,代表工具调用失败的总数,⑤工具幻觉是工具名识别失败的一种特殊情况
在此基础上,我们提供了一个相应的评测脚本,具体评测过程欢迎到Github项目中进一步了解。
4.?评测结果
4.1.?🏆?fcdata_luban_zh数据集评测
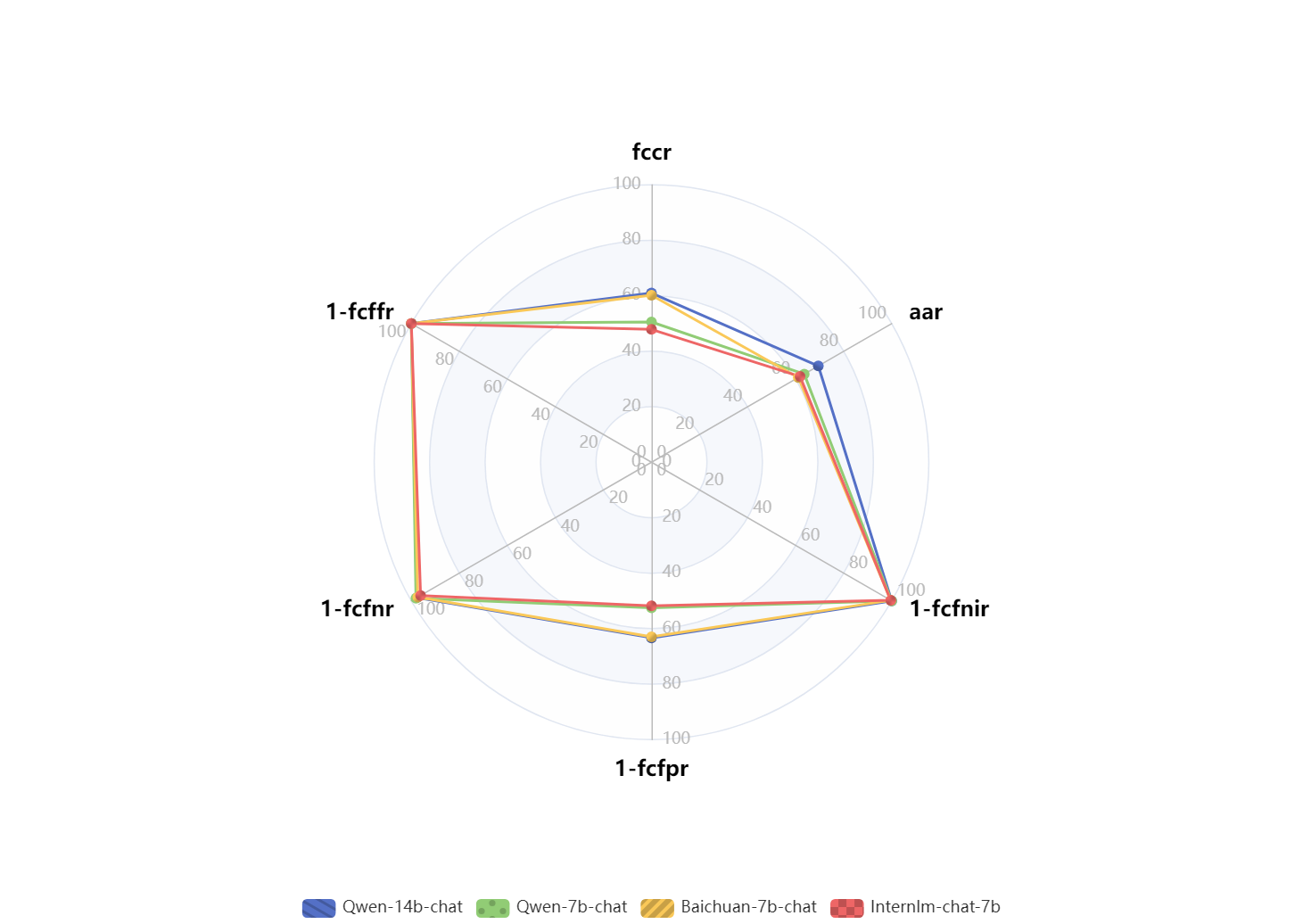
如下图所示,在fcdata_luban_zh的评测结果中,不同模型在指令微调后function call能力存在一定的分化现象。Qwen-14B-Chat在工具调用准确率fccr和aar的得分最高,说明通过Qwen-14B-Chat遵循指令微调的能力最好,同时也可以看到Qwen-7b-chat的fccr也基本与Qwen-14b-chat持平。Internlm-7B-Base评分较低相对其它模型的指令微调能力较弱。从总体上来看,各模型经过FunctionCall的训练数据微调后,分数区分度不大。
4.2.?🏆?fcdata_zh数据集评测
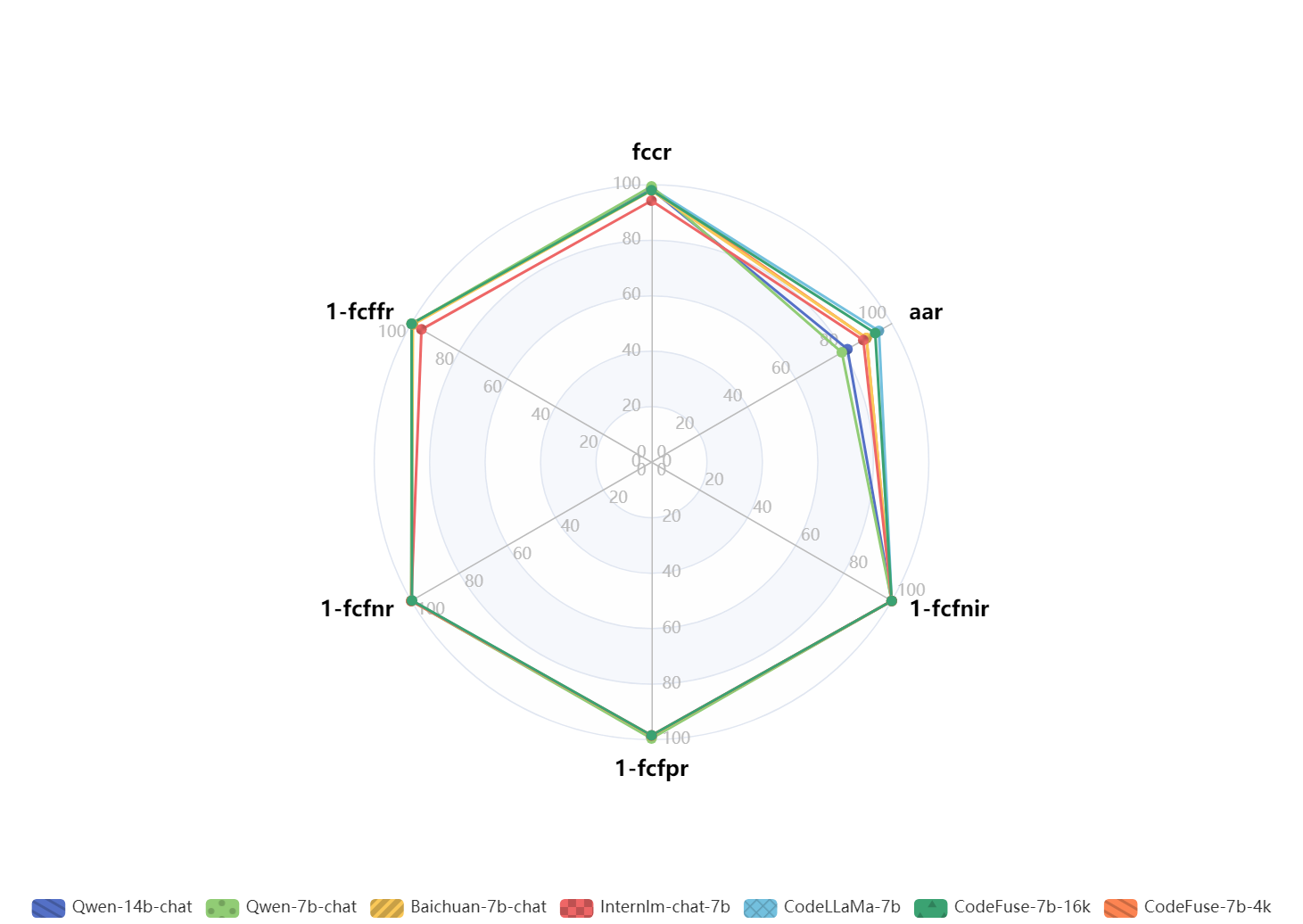
如下图所示,在fcdata_zh的评测结果中,不同模型在指令微调后function call能力不存在太大差异。同时也可以看到在fcdata_zh数据集上的arr评分相较于luban数据集有较大的提升,可能是luban评测集表述上与整体训练集上的回答存在较大差异,模型无法做出与luban数据匹配的合理回答。最好的aar得分模型分别是CodeLLaMa和CodeFuse-7b-16k,而CodeFuse-7b-16k比4k要好也说明长Token模型拥有对工具进行总结的更优能力。
5.?未来展望
Tool Learning现在已然成为大模型领域的研究热点,大模型与Tool Learning能碰撞出什么火花也是当前行业内最关心的话题。未来我们将持续对ToolLearning-Eval项目进行优化,主要优化方向包括以下几点:
1)不断优化评测数据集:
-
- 目前ToolLearning-Eval已涵盖日常领域常见的工具集合,后续将继续增加不同领域的Tool集合,直至覆盖全领域的所有智能化任务;
- Tool Learning的数据质量决定了模型掌握工具学习范式的上限,后面将通过更完善的数据构造方法和人工评测手段来生成更高质量的数据
2)拓展多工具多轮对话数据集:
-
- 当前工具评测任务仅限于单工具的评测,对于不同类别之间的数据量存在较大差异,需要持续补充数据集,平衡各类别的数据量;
3)持续增加评测模型:
-
- 一期主要评测了一些主流的、规模不是很大的开源模型,后续将覆盖更多的模型,并重点跟踪评测面向相关领域的大模型。
希望大家一起来共建ToolLearning-Eval,期待在大家的努力下,建立更准确、更全面的ToolLearning领域大模型评测体系,推动ToolLearning领域大模型技术的不断发展与创新。
6.?联系我们
欢迎使用&讨论&共建
(1)Eval - DevOps 领域 LLM 行业标准评测:GitHub - codefuse-ai/codefuse-devops-eval: Industrial-first evaluation benchmark for LLMs in the DevOps/AIOps domain.
(2)ChatBot - 开箱即用的 DevOps 智能助手:GitHub - codefuse-ai/codefuse-chatbot: An intelligent assistant serving the entire software development lifecycle, powered by a Multi-Agent Framework, working with DevOps Toolkits, Code&Doc Repo RAG, etc.
(3)Model - DevOps 领域专属大模型:GitHub - codefuse-ai/CodeFuse-DevOps-Model: DevOps-Models is a series of industrial-first LLMs for theDevOps domain. Asking it for any question in the DevOps domain to get solution!
(4) CodeFuse官网:?https://codefuse.alipay.com
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024年评武汉中级职称需要哪些条件,习称珺
- Docker-harbor私有仓库部署与管理
- MR-GCN
- Java 并发性和多线程3
- springcloud之Feign超时提示Read timed out executing POST
- 模板类结构与元函数
- 团队协作工具推荐:提升团队效率与协作效果的利器
- 跟这台计算机连接的一个USB设备运行不正常?造成这样的原因可能有这些
- 【亲测可用】Python操作oss
- TypeScript学习笔记归纳(持续更新ing)