kubernetes-监控系统Prometheus
一、概述
在微服务分布式系统中,监控是极其重要的。监控能够对系统的运行状态了如指掌,有问题及时发现。
监控的目的:
- 长期预测分析:比如资源用量预测。
- 告警:当系统出现或者即将出现故障时,监控系统迅速反应并通知管理员。
- 故障分析与定位:通过监控以及历史数据分析,能够找到根源问题。
- 数据可视化:通过可视化仪表盘能够直接获取系统的运行状态、资源使用情况以及服务运行状态等直观信息。
二、kubernetes集群监控系统
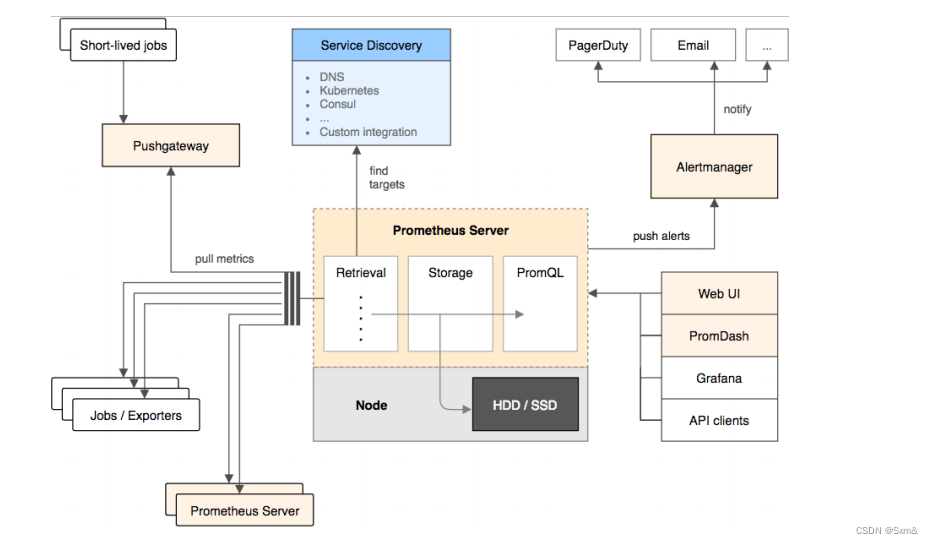
- 基于HTTP协议的Pull模式进行时间序列指标采集。
- 以指标名称和键值对标签唯一标识的基于时间序列的数据模型。
- 支持多维灵活查询的PromQL。
- 灵活的图形化展示。
- 基于静态配置或服务发现的目标发现机制。
三、Prometheus指标类型
- Counter(计数器器)
- Counter类型代表一种样本数据单调递增的指标,即只增不减,除非监控系统发生了重置。
- Gauge(仪表盘)
- Guage 类型代表一种样本数据可以任意变化的指标,即可增可减。
- Histogram(直方图)
- Histogram在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中,后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图。
四、应用上报指标
apiVersion: apps/v1
kind: Deployment
metadata:
name: httpserver-metrics-deploy
labels:
app: httpserver-metrics
namespace: default
spec:
selector:
matchLabels:
app: httpserver-metrics
replicas: 1
template:
metadata:
labels:
app: httpserver-metrics
#增加注解
annotations:
prometheus.io/port: "80"
prometheus.io/scrape: "true"
spec:
containers:
- name: httpserver
image: httpserver-metrics:v1.0
ports:
- containerPort: 80
pod需要显示的增加annotations:prometheus.io/port和prometheus.io/scrape,这样Prometheus才会收集这个pod的指标。默认情况下,应用往/metrics暴露指标即可,Prometheus会从应用的/metrics收集指标。若应用有特定的指标暴露路径,那么Prometheus的配置文件指定自定义指标路径。
五、kubernetes原生暴露Prometheus指标
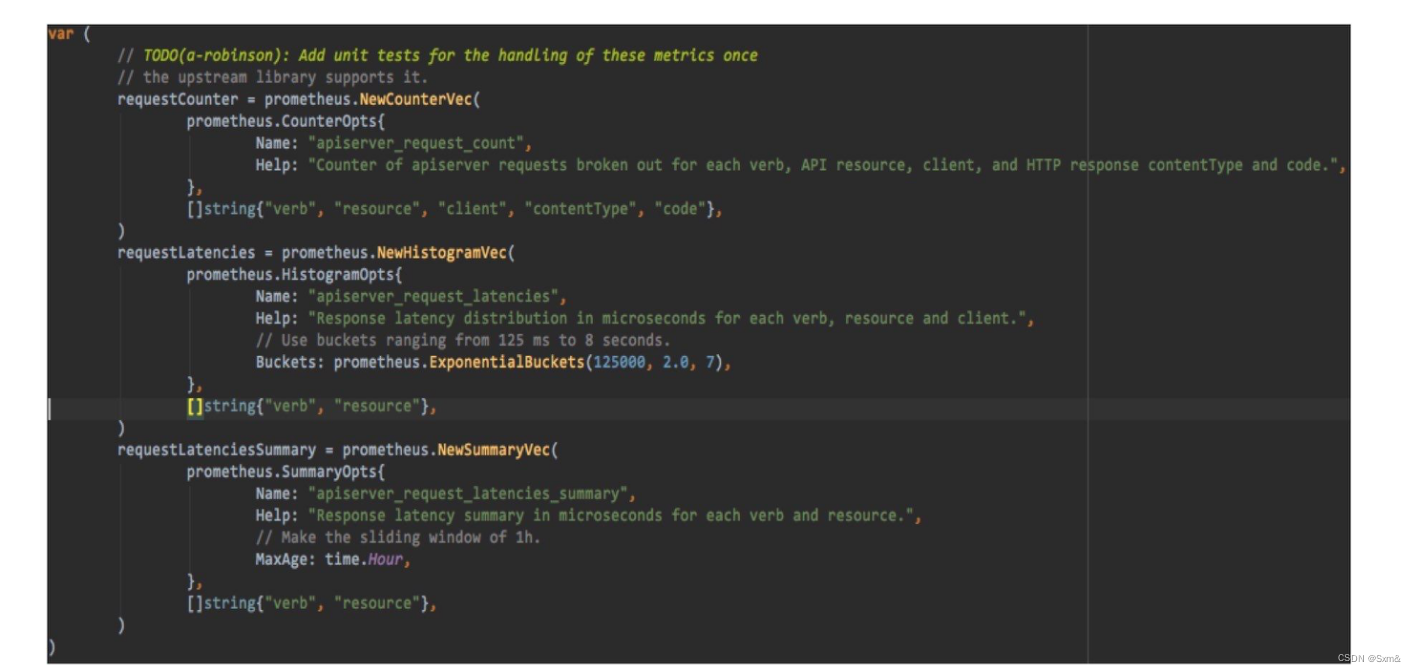
之所以说Prometheus是云原生的监控标准,因为kubernetes的很多组件都原生的暴露Prometheus 格式的 metrics。所以Prometheus很容易就收集到这些指标。
5.1 cAdvisor
cAdvisor (Container Advisor) 是一个用于监控和收集容器资源使用情况的开源工具。cAdvisor 默认会收集以下几个主要的容器指标:
- CPU:包括容器的 CPU 使用率、限制和限制的时间窗口等信息。
- 内存:包括容器的内存使用情况、限制和 Swap 使用情况等。
- 文件系统:包括容器的文件系统使用情况和磁盘 I/O 指标。
- 网络:包括容器的网络 I/O 指标,例如接收和发送的字节数。
- 负载:包括容器的负载平均值、运行线程数量等。
- 进程:包括容器内部的进程数和进程状态等信息。
每个节点的kubelet集成了cAdvisor ,Prometheus 会 pull 这些信息,给每个节点打上标签来区分不同的节点。
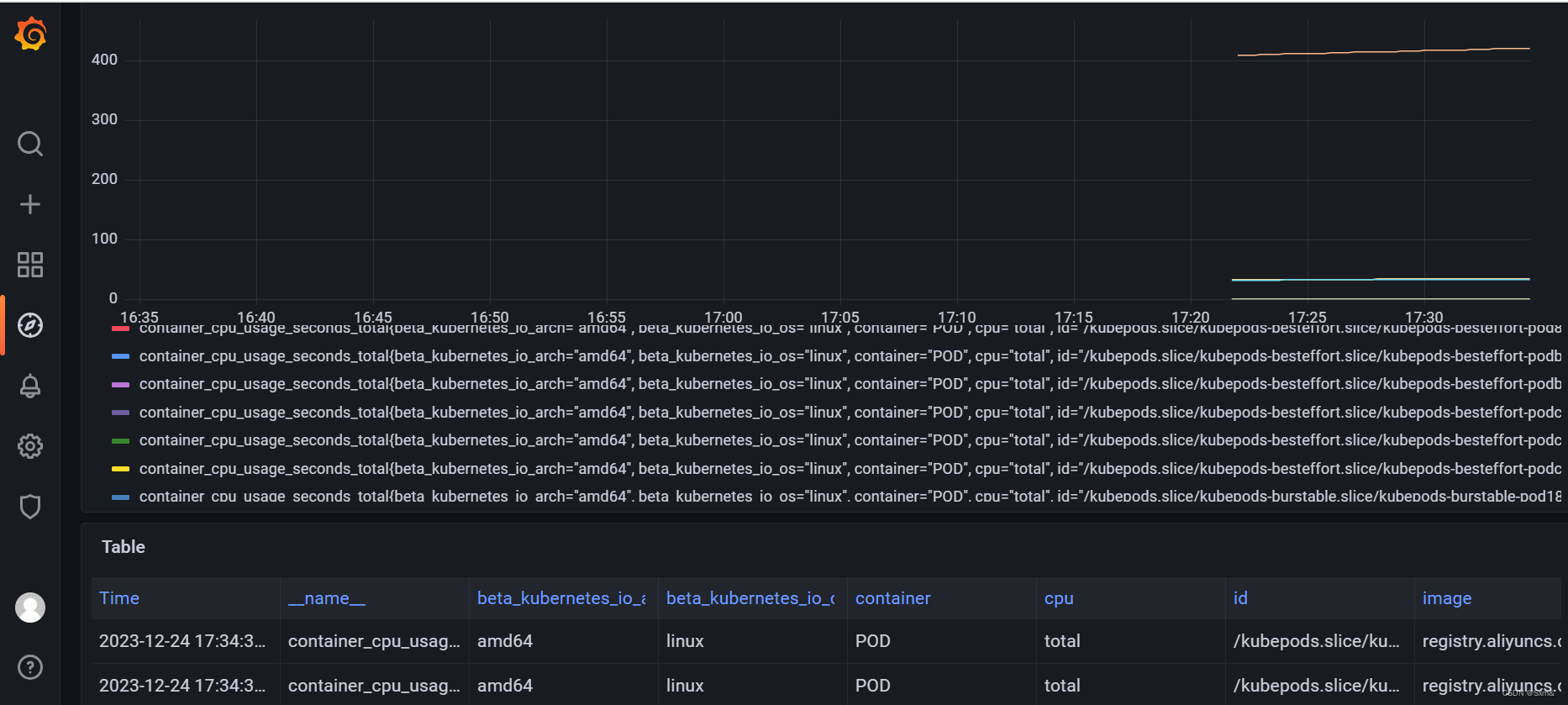
例如cAdvisor其中一个监控指标container_cpu_usage_seconds_total(容器在每个CPU内核上的累积占用时间 (单位:秒)),上报了每个pod容器的这个指标。
5.2 Node Exporter
Node Exporter 是prometheus官方提供的agent,用于收集主机的硬件和操作系统指标。
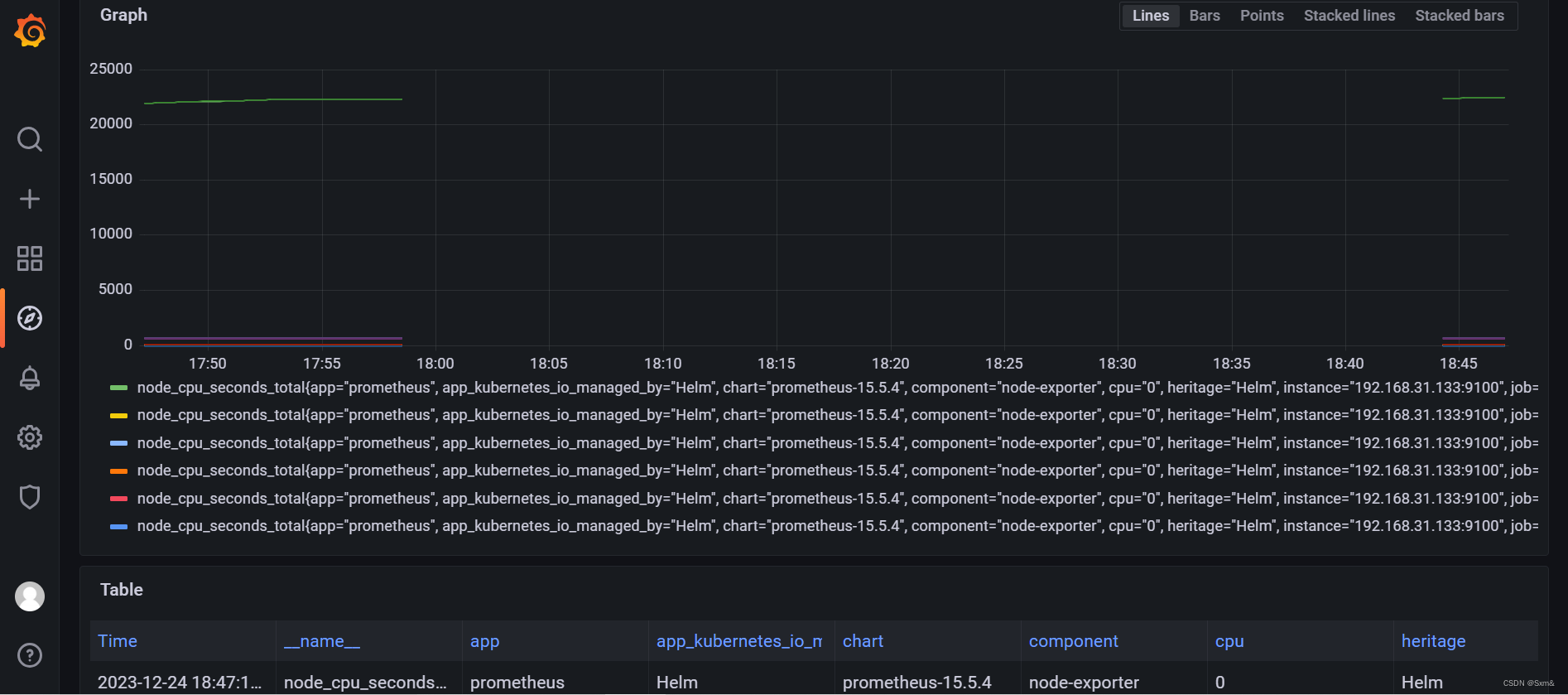
例如node_cpu_seconds_total,它代表CPU每种模式下花费的时间,是counter型的,会随着时间一直增长。其标签,cpu表示第几个核,instance表node_exporter所在机器,job表示来自prometheus配置的哪个任务,mode表示这是cpu处于哪种模式。
六、Prometheus的服务发现
云原生提倡的是动态的系统,也就是说pod ip是会经常发生变化的,那么Prometheus如何获取到这些要收集指标的target,kubernetes体系下的服务注册中心是什么?我们知道,kubernetes的服务注册中心是apiserver,依赖etcd进行存储。
6.1 基于文件的服务发现

Prometheus配置文件定义了file_sd_configs(file service discovery)
targets是拉取指标的地址,labels表示拉取的指标都要打上这些标签。
6.2 基于kubernetes的服务发现

七、Relabel
为什么需要relabel?
- 按照不同的环境dev、test、prod聚合监控数据。
- 对于研发团队,我可能只关心dev环境的监控数据。
- 对于超大集群,我可能只关心部分关键指标的监控,忽略非关键指标,降低监控系统的负担。
- 多租户场景下,多个团队的Prometheus Server可能只需要采集自己的业务数据。
面对以上需求,我们实际上希望Prometheus Server能够按照某些规则(比如标签)从服务发现注册中心返回的Target实例中有选择性的采集某些Exporter实例的监控数据。
Relabel示例:

这也就是为什么pod上要加prometheus.io/scrape注解的原因了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 第08章_面向对象编程(高级)(static,单例设计模式,理解mian方法,代码块,final,抽象类与抽象方法,接口,内部类,枚举类,注解,包装类)
- Java在SpringCloud中自定义Gateway负载均衡策略
- 2.6 KERNEL LAUNCH
- 基于SpringBoot的APK检测管理系统 JAVA简易版
- k8s的存储卷、数据卷---动态PV创建
- 智慧工厂人员定位系统源码,采用多维定位模式,精确定位人员、机具、物料的实时位置
- 深度学习中Batch/Layer/Instance/Group normalization方法
- 算法通关村第十五关—继续研究超大规模数据场景的问题(黄金)
- Redis-网络模型
- Channel 使用事项和注意细节