【霹雳吧啦】手把手带你入门语义分割の番外14:U2-Net 源码讲解(PyTorch)—— 自定义数据集读取
目录
前言
文章性质:学习笔记 📖
视频教程:U2-Net 源码讲解(PyTorch)- 4 自定义数据读取
主要内容:根据 视频教程 中提供的 U2-Net?源代码(PyTorch),对 my_dataset.py?文件进行具体讲解。
Preparation
├── src: 搭建网络相关代码
├── train_utils: 训练以及验证相关代码
├── my_dataset.py: 自定义数据集读取相关代码
├── predict.py: 简易的预测代码
├── train.py: 单GPU或CPU训练代码
├── train_multi_GPU.py: 多GPU并行训练代码
├── validation.py: 单独验证模型相关代码
├── transforms.py: 数据预处理相关代码
└── requirements.txt: 项目依赖
 ?
?
?
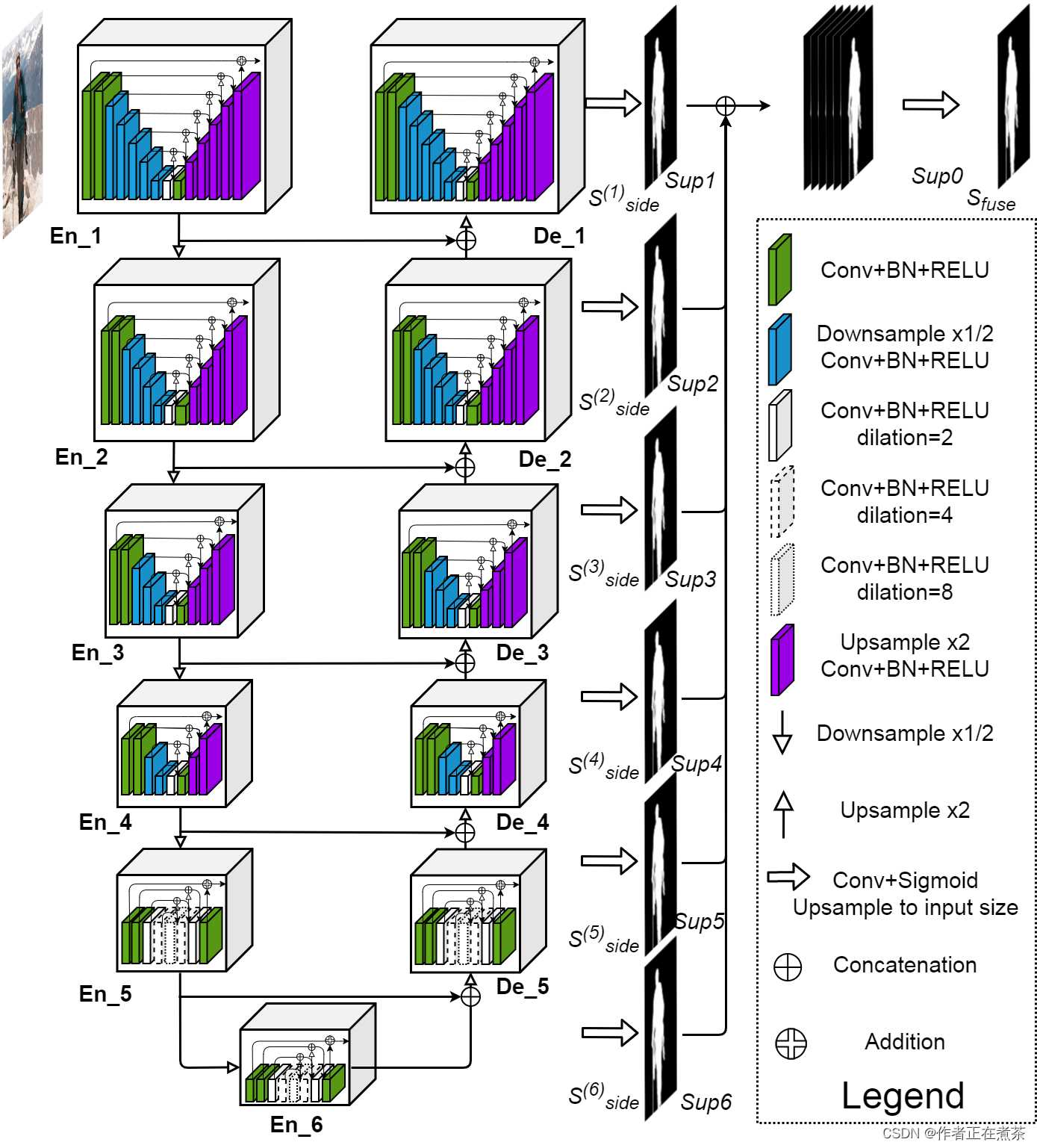
一、U2-Net 网络结构图
原论文提供的 U2-Net 网络结构图如下所示:?
 ???
???
【说明】在 Encoder 阶段,每通过一个 block 后都经 Maxpool 下采样 2 倍,在 Decoder 阶段,每通过一个 block 后都经 Bilinear 上采样 2 倍。U2-Net 网络的核心 block 是 ReSidual U-block,分为具备上下采样的 block 和不具备上下采样的 block:
- 具备了上下采样的 block:Encoder1~Encoder4、Decoder1~Decoder4
- 不具备上下采样的 block:Encoder5、Encoder6、Decoder5
二、U2-Net 网络源代码
1、DUTS 数据集的目录结构
DUTS 数据集解压后的目录结构:
├── DUTS-TR
│ ? ? ?├── DUTS-TR-Image: 该文件夹存放所有训练集的图片
│ ? ? ?└── DUTS-TR-Mask: 该文件夹存放对应训练图片的 GT 标签(Mask 蒙板形式)
│
└── DUTS-TE
? ? ? ?├── DUTS-TE-Image: 该文件夹存放所有测试(验证)集的图片
? ? ? ?└── DUTS-TE-Mask: 该文件夹存放对应测试(验证)图片的 GT 标签(Mask 蒙板形式)
2、my_dataset.py 解析?
这个 DUTSDataset 类继承自 data.Dataset 父类,在其初始化 __init__ 方法中,传入参数包括:
- root,指向 DUTS 数据集所在的根目录,包括 DUTS-TR 训练集和 DUTS-TE 验证集
- train,布尔变量,其值为 True 时读取训练集,其值为 False 时读取验证集
- transforms,我们所需指定的数据预处理以及增强方法

【代码解析1】对 DUTSDataset 类代码的具体解析(结合上图):?
- 第 9 行:断言数据集所在的根目录路径是否存在
- 第 10-12 行:对训练集的 image 图像和 mask 蒙版的路径进行拼接
- 第 13-15 行:对验证集的 image 图像和 mask 蒙版的路径进行拼接
- 第 16-17 行:断言 image 图像和 mask 蒙版的拼接路径是否存在
- 第 19?行:遍历 image_root?图像路径,得到以 .jpg 结尾的文件,将其名称存到 listdir 中并复制给 image_names
- 第 20?行:遍历 mask_root 蒙版路径,得到以 .png 结尾的文件,将其名称存到 listdir 中并复制给 mask_names
- 第 21 行:断言 image_names 列表是否为空,若是则说明我们没有找到任何图片
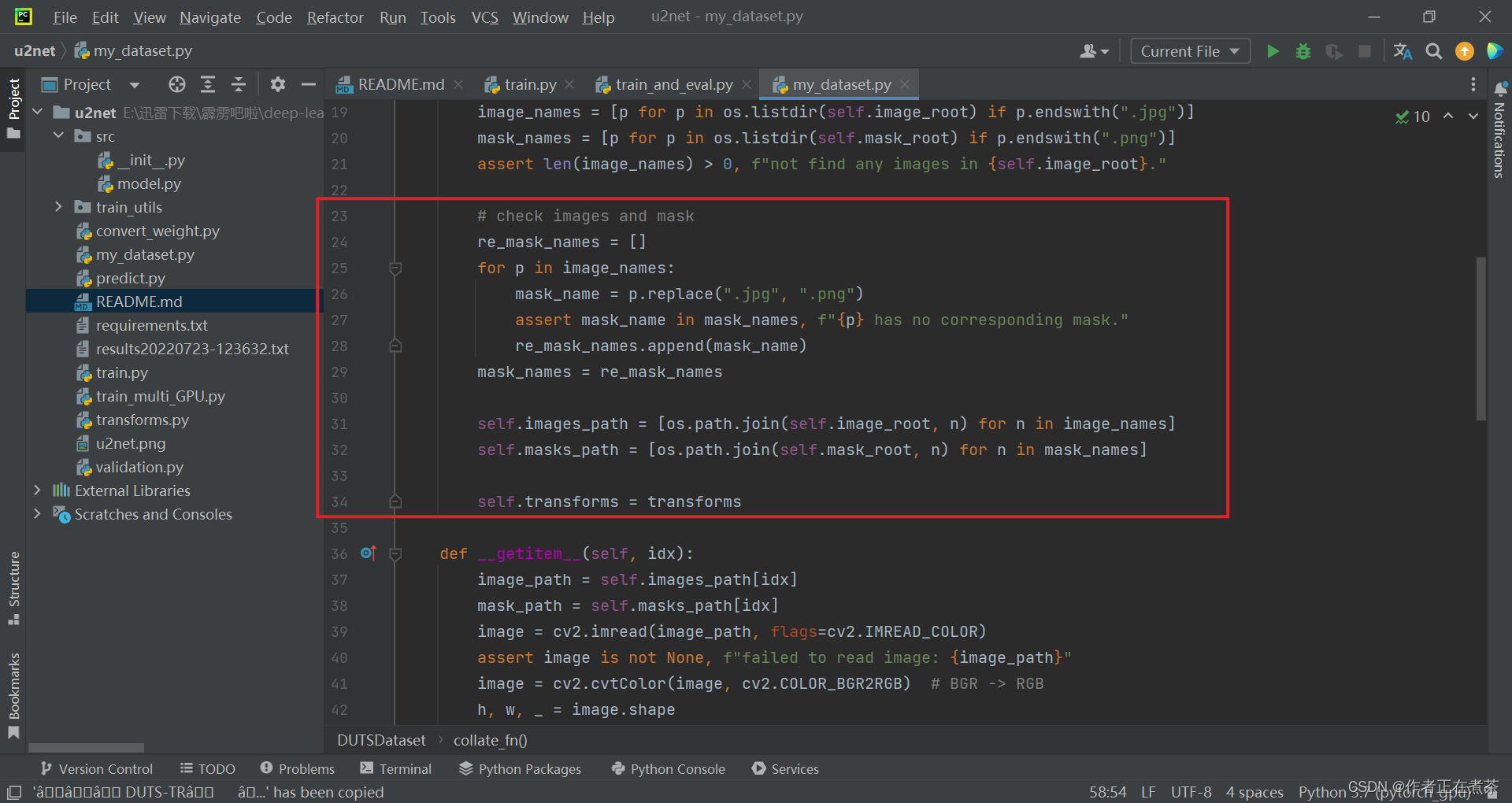
【代码解析2】对 DUTSDataset 类代码的具体解析(结合上图):?
- 第 23-24 行:这块用于检查是否每张 image 图片都有对应的 mask 蒙版,初始化 re_mask_names 列表
- 第 25-26 行:遍历 image_names 图像名称,并将 .jpg 后缀替换为 .png 后缀,得到 mask_name
- 第 27-28 行:断言得到的 mask_name 是否在刚刚构建的 mask_names 列表中,若存在则传到 re_mask_names 列表
- 第 31-32 行:通过拼接得到 image 图像和 mask 蒙版的路径

【代码解析3】对 DUTSDataset 类代码的具体解析(结合上图):?
- 第 39 行:使用 OpenCV 库读取图像文件,并将其解码为 BGR 格式的 numpy 数组。
- 第 41 行:将 BGR 格式的图像转换为 RGB 格式,因为在 PyTorch 中,图像通道的顺序是 RGB 。
- 第 44 行:使用 OpenCV 库读取标签文件,并将其解码为灰度图像,因为标签通常只包含像素值为 0 或 1 的二进制信息。
3、my_dataset.py 代码
import os
import cv2
import torch.utils.data as data
class DUTSDataset(data.Dataset):
def __init__(self, root: str, train: bool = True, transforms=None):
assert os.path.exists(root), f"path '{root}' does not exist."
if train:
self.image_root = os.path.join(root, "DUTS-TR", "DUTS-TR-Image")
self.mask_root = os.path.join(root, "DUTS-TR", "DUTS-TR-Mask")
else:
self.image_root = os.path.join(root, "DUTS-TE", "DUTS-TE-Image")
self.mask_root = os.path.join(root, "DUTS-TE", "DUTS-TE-Mask")
assert os.path.exists(self.image_root), f"path '{self.image_root}' does not exist."
assert os.path.exists(self.mask_root), f"path '{self.mask_root}' does not exist."
image_names = [p for p in os.listdir(self.image_root) if p.endswith(".jpg")]
mask_names = [p for p in os.listdir(self.mask_root) if p.endswith(".png")]
assert len(image_names) > 0, f"not find any images in {self.image_root}."
# check images and mask
re_mask_names = []
for p in image_names:
mask_name = p.replace(".jpg", ".png")
assert mask_name in mask_names, f"{p} has no corresponding mask."
re_mask_names.append(mask_name)
mask_names = re_mask_names
self.images_path = [os.path.join(self.image_root, n) for n in image_names]
self.masks_path = [os.path.join(self.mask_root, n) for n in mask_names]
self.transforms = transforms
def __getitem__(self, idx):
image_path = self.images_path[idx]
mask_path = self.masks_path[idx]
image = cv2.imread(image_path, flags=cv2.IMREAD_COLOR)
assert image is not None, f"failed to read image: {image_path}"
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # BGR -> RGB
h, w, _ = image.shape
target = cv2.imread(mask_path, flags=cv2.IMREAD_GRAYSCALE)
assert target is not None, f"failed to read mask: {mask_path}"
if self.transforms is not None:
image, target = self.transforms(image, target)
return image, target
def __len__(self):
return len(self.images_path)
@staticmethod
def collate_fn(batch):
images, targets = list(zip(*batch))
batched_imgs = cat_list(images, fill_value=0)
batched_targets = cat_list(targets, fill_value=0)
return batched_imgs, batched_targets
def cat_list(images, fill_value=0):
max_size = tuple(max(s) for s in zip(*[img.shape for img in images]))
batch_shape = (len(images),) + max_size
batched_imgs = images[0].new(*batch_shape).fill_(fill_value)
for img, pad_img in zip(images, batched_imgs):
pad_img[..., :img.shape[-2], :img.shape[-1]].copy_(img)
return batched_imgs
if __name__ == '__main__':
train_dataset = DUTSDataset("./", train=True)
print(len(train_dataset))
val_dataset = DUTSDataset("./", train=False)
print(len(val_dataset))
i, t = train_dataset[0]本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C语言-memchr函数字节查找
- MySQL-DQL
- C语言——高精度除法
- 企业网络常用技术-快速生成树RSTP原理与配置
- 缓存高可用:缓存如何保证高可用?
- shell shell脚本编写常用命令 语法 shell 脚本工具推荐
- Python列表推导式(for表达式)及用法
- Python格式化字符串
- python中三种常用格式化字符串的方法(%s, format,f-string)
- STM32CubeMX教程8 TIM 通用定时器 - 输出比较