设计 Pastebin.com
设计 Pastebin.com
设计 Bit.ly 是一个类似的问题,区别是 pastebin 需要存储的是 paste 的内容,而不是原始的未短化的 url.
怎么处理这个问题?
第一步:概述用例和约束
收集这个问题的需求和范畴。问相关问题来明确用例和约束,讨论一些假设。
我们把问题的范畴定在如下用例:
- 用户输入一段文本,然后得到一个随机生成的链接
- 过期设置
默认的设置是不会过期的
可以选择设置一个过期的时间
- 用户输入一个 paste 的 url 后,可以看到它存储的内容
- 用户是匿名的
- Service 跟踪页面分析
- 一个月的访问统计
- Service 删除过期的 pastes
- Service 需要高可用
超出范畴的用例:
- 用户可以注册一个账户
- 用户通过验证邮箱
- 用户可以用注册的账户登录
- 用户可以编辑文档
- 用户可以设置可见性
- 用户可以设置短链接
约束和假设
状态假设
- 访问流量不是均匀分布的
- 打开一个短链接应该是很快的
- pastes 只能是文本
- 页面访问分析数据可以不用实时
- 一千万的用户量
- 每个月一千万的 paste 写入量
- 每个月一亿的 paste 读取量
- 读写比例在 10:1
计算使用
向面试官说明你是否应该粗略计算一下使用情况
- 每个 paste 的大小
- 每一个 paste 1 kb
- shortlink - 7 bytes
- expiration_length_in_minutes - 4 bytes
- created_at - 5 bytes
- paste_path - 255 bytes
总共 = ~1.27 kb
- 每个月新的 paste 内容在12.7 GB
- (1.27 * 10000000) kb / 月的 paste
- 三年将近 450 GB 的新 paste 内容
- 三年内 3.6 亿短链接
- 假设大部分都是新的 paste, 而不是需要更新已存在的 paste
- 平均 4 paste/s 的写入速度
- 平均 40 paste/s 的读取速度
简单的转换指南:
2.5 百万 req/s
1 req/s = 2.5 百万 req/m
40 req/s = 1 亿 req/m
400 req/s = 10 亿 req/m
第二步:创建一个高层次设计
概述一个包括所有重要的组件的高层次设计
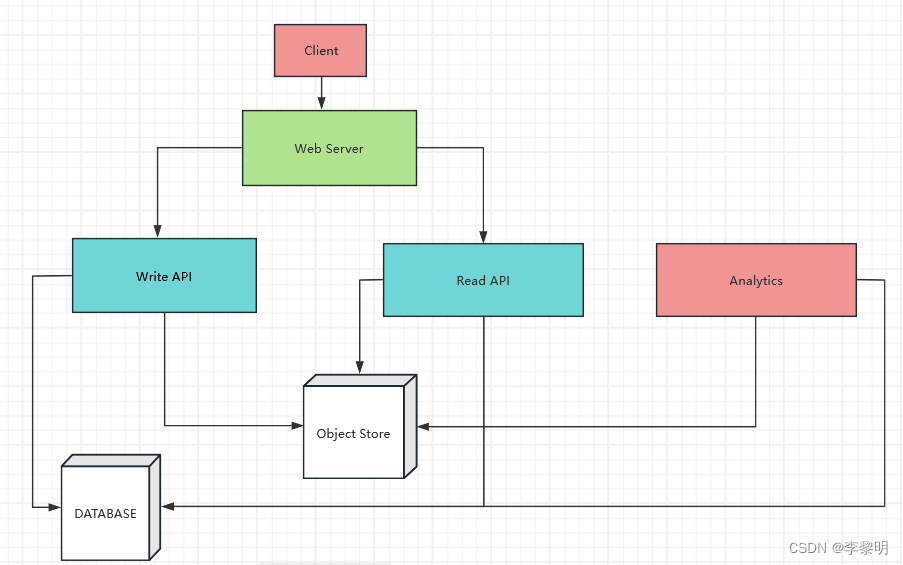
第三步:设计核心组件
深入每一个核心组件的细节
用例:用户输入一段文本,然后得到一个随机生成的链接
我们可以用一个 关系型数据库 作为一个大的哈希表,用来把生成的 url 映射到一个包含 paste 文件的文件服务器和路径上。
为了避免托管一个文件服务器,我们可以用一个拖管的对象存储,比如 Amazon 的 S3 或者 NoSQL文档类型存储。
作为一个大的哈希表的关系型数据库的替代方案,我们可以用 NoSQL键值存储。我们需要讨论选择 SQL 和 NoSQL 之间的权衡。
- 客户端发送一个创建 paste 的请求到作为一个反向代理启动的服务器
- Web 服务器转发请求给写接口服务器
- 写接口服务器执行如下操作:
- 生成一个唯一的 url
- 检查这个 url 在 SQL 数据库里面是否唯一
- 如果这个 url 不是唯一的,生成另外一个 url
- 如果我们支持自定义 url,我们可以使用用户提供的 url
- 把生成的 url 存储到 SQL 数据库的 pastes 表中
- 存储 paste 的内容数据到对象存储中
- 返回生成的 url
向面试官阐明你需要写多少代码
paste 表可以有如下结构:
shortlink char(7) NOT NULL
expiration_length_in_minutes int NOT NULL
created_at datetime NOT NULL
paste_path varchar(255) NOT NULL
PRIMARY KEY(shortlink)
我们将在 shortlink 字段和 created_at 字段上创建一个数据库索引,用来提高查询的速度(避免因为扫描全表导致的长时间查询)并将数据保存到内存中,从内存里面顺序读取 1MB 的数据需要大概 250 微秒,而从 SSD 上读取则需要花费 4 倍的时间,从磁盘上则需要花费 80 倍的时间。
为了生成唯一的 url, 我们可以:
- 使用 MD5 来哈希用户的 IP 地址 + 时间戳
- MD5 是一个普遍用来生成一个 128 bit长度的hash值的一种hash办法
- MD5 是一致分布的
- 或者我们也可以用MD5 哈希一个随机生成的数据
- 用 Base 62编码 MD5 哈希值
- 对于 urls,使用 Base 62编码[a-zA-Z0-9]是比较合适的
- 对于每一个原始输入只会有一个 hash 结果, Base62是不确定的
- Base 64 是另外一个流行的编码方案,但是对于 urls,会因为额外的 + 和 - 字符串而产生一些问题
def base_encode(num, base=62):
digits = []
while num > 0
remainder = modulo(num, base)
digits.push(remainder)
num = divide(num, base)
digits = digits.reverse
取输出的前7个字符,结果会有63*7个可能的值,应该足以满足在3年内处理3.6亿个短视频的约束:
url = base_encode(md5(ip_address+timestamp))[:URL_LENGTH]
我们将会用一个公开的 REST 风格接口:
curl -X POST --data '{"expiration_length_in_minutes":"60",\"paste_contents":"Hello World"}' https://pastebin.com/api/v1/paste
于内部通信,我们可以用 RPC。
用例:用户输入一个 paste 的 url 后可以看到它存储的内容
- 客户端 发送一个获取 paste 请求到 Web Server
- Web Server 转发请求给 读取接口 服务器
- 读取接口 服务器执行如下操作:
- 在 SQL 数据库 检查这个生成的 url
- 如果这个 url 在 SQL 数据库 里面,则从 对象存储 获取这个 paste 的内容
- 否则,返回一个错误页面给用户
- 在 SQL 数据库 检查这个生成的 url
REST API:
curl https://pastebin.com/api/v1/paste?shortlink=foobar
Response:
{
"paste_contents": "Hello World",
"created_at": "YYYY-MM-DD HH:MM:SS",
"expiration_length_in_minutes": "60"
}
用例: 服务跟踪分析页面
因为实时分析不是必须的,所以我们可以简单的 MapReduce Web Server 的日志,用来生成点击次数。
class HitCounts(MRJob):
def extract_url(self, line):
"""Extract the generated url from the log line."""
...
def extract_year_month(self, line):
"""Return the year and month portions of the timestamp."""
...
def mapper(self, _, line):
"""Parse each log line, extract and transform relevant lines.
Emit key value pairs of the form:
(2016-01, url0), 1
(2016-01, url0), 1
(2016-01, url1), 1
"""
url = self.extract_url(line)
period = self.extract_year_month(line)
yield (period, url), 1
def reducer(self, key, values):
"""Sum values for each key.
(2016-01, url0), 2
(2016-01, url1), 1
"""
yield key, sum(values)
用例: 服务删除过期的 pastes
为了删除过期的 pastes,我们可以直接搜索 SQL 数据库 中所有的过期时间比当前时间更早的记录,
所有过期的记录将从这张表里面删除(或者将其标记为过期)。
第四步:扩展这个设计
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- LSTM Siamese neural network
- 携带研究材料(第六期模拟笔试)
- vue data变量不能以“_”开头,否则会产生很多怪异问题
- 【Alibaba工具型技术系列】「EasyExcel技术专题」实战研究一下 EasyExcel 如何从指定文件位置进行读取数据
- 31 3D日历组件
- 【AMD Xilinx】ZUBoard(4):PS端的IO读写
- 用ImageJ处理高斯光束的光斑
- 2 python基本语法 - Tuple不可变序列
- 用友GRP-U8 UploadFile 文件上传漏洞
- MySQL基础笔记(9)事务