架构师的36项修炼-06高性能系统架构设计
本课时讲解大家常听到的高性能系统架构。
高性能系统架构,主要包括两部分内容,性能测试与性能优化。性能优化又可以细分为硬件优化、中间件优化、架构优化及代码优化,知识架构图如下。
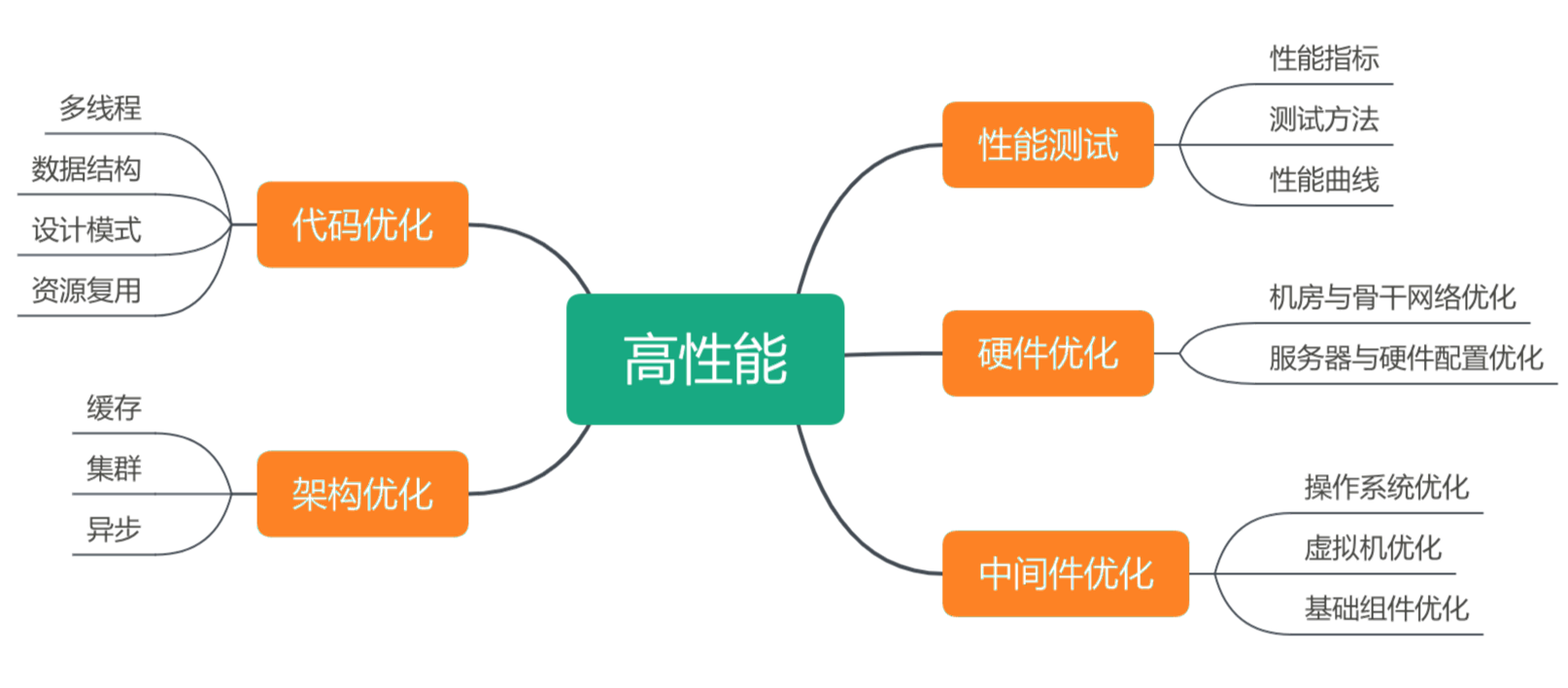
性能测试
先看系统的性能测试。性能测试是性能优化的前提和基础,也是性能优化结果的检查和度量标准。
关于性能测试有一句著名的论断,叫作“你不能优化一个你未经测试的系统,你也不能优化一个你不了解的系统”。所以要进行性能优化,首先要进行性能测试,看系统的当前各项性能指标是什么样子的,问题在哪里,从哪些方面进行优化。
而具体在优化的时候,又必须要了解系统。系统的架构是什么样子的?系统的关键技术点、瓶颈点在哪里?为何会产生这样的瓶颈点?以及如何对它进行优化?也就是说必须要在了解系统的基础之上才能进行优化。所以性能测试以及了解系统,是性能优化的两个关键前提。
关于性能的标准,在不同的视角下,性能的度量标准是不同的,性能优劣也是不同的,性能标准有主观和客观两种视角。
& 主观标准是说使用者在体验上的快慢,用户在使用系统的时候,它主观上感觉快还是慢,那么就会得到一个性能好还是差的主观标准;
& 客观标准,也就是在客观上性能指标到底是好还是差。
主观标准和客观标准,虽然它们本质上是统一的,但是也并不是完全一致的。比如客观性能指标相同的两个系统,其中一个系统通过页面渲染,通过一些动画提示,通过更良好的用户交互体验,可以使用户主观感觉系统响应更快。而另一个如果没有做任何交互上的设计优化,仅仅是直接向用户输出内容,那么用户可能会感觉等得更久一些,在主观体验上性能也更差一点。
客观性能指标
在客观视角上,性能优劣的指标主要有响应时间、并发数、吞吐量以及性能计数器。这些指标通常也是我们技术上要进行优化的主要指标,后面我们的性能讨论主要是围绕这些客观上的性能指标展开的。
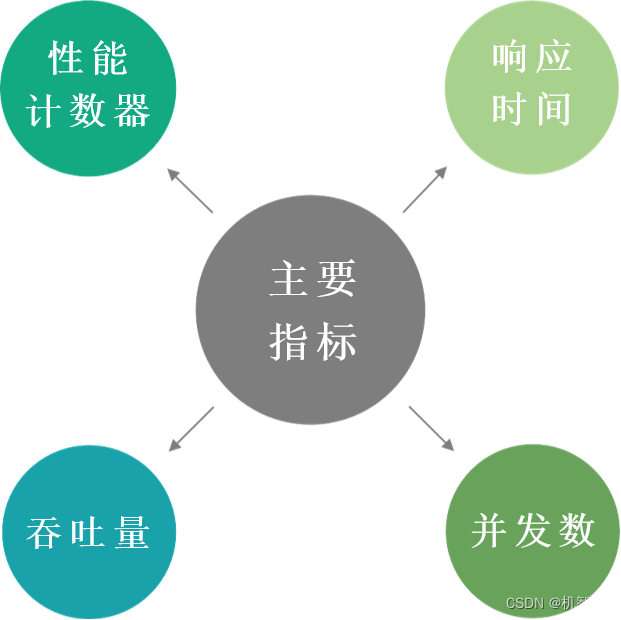
响应时间
第一重要的就是响应时间。所谓响应时间是指应用系统从发出请求开始到收到最后响应数据所需要的时间。响应时间是系统最重要的性能指标,最直接地反映了系统的快慢。
并发数
第二个指标是并发数。并发数是指系统同时处理的请求数,这个数字反映了系统的负载特性。对于互联网系统而言,并发数就是同时访问系统的用户数,也就是指同时提交请求的用户数目。和并发用户数相对应的还有在线用户数,也就是当前登录系统在使用系统的用户数,当前登录系统在使用系统的用户数并不是并发用户数,因为登录系统在使用的时候,它可能在查看页面内容,在填写页面信息,这个时候只要不提交请求,虽然它当前在系统上是在线的,但是它并不是并发用户数,而是在线用户数。另外,还有系统总用户数,指可能访问系统的总用户数。一般说来,系统的总用户数远大于在线用户数,在线用户数远大于并发用户数,对系统性能产生影响的主要是并发用户数。
吞吐量
另一个性能指标是吞吐量。吞吐量是指单位时间内系统处理请求的数量,体现的是系统的处理能力。我们一般用每秒的请求数、每秒的事务数这样的一些指标来衡量,也就是 HPS、TPS 这些,HPS 是每秒的 HTTP 数目,TPS 是每秒事务数。还可以用 QPS,即每秒的查询数来表示,总之,就是单位时间内处理的请求数目。
吞吐量、响应时间和并发数三者之间是有关联性的,响应时间足够快,那么单位时间的吞吐量也会相应的提高。比如说响应时间如果是 100ms,对于一个并发用户,并发数是 1,那么 TPS 就可以是 10。如果响应时间是 500ms,用户并发数还是 1,那么 TPS 吞吐量就变成了 2。
性能计数器
最后一个性能指标是性能计数器。指的是服务器或者操作系统性能的一些指标数据,包括系统负载 System Load、对象和线程数、内存使用、CPU 使用、磁盘和网络 I/O 使用等指标。这些指标是系统监控的重要参数,反映系统负载和处理能力的一些关键指标,通常这些指标和性能是强相关的。这些指标很高,成为瓶颈,通常也预示着性能可能会出现问题。在实践中会对这些性能指标设置一些报警的阈值。当监控系统发现性能计数器超过阈值的时候,就会向运维和开发人员报警,以便及时发现、处理系统的性能问题。
性能测试方法
再来看性能测试的方法。通常我们说性能测试的时候指的是一个总称,是广义上的性能测试,具体可以分为狭义上的性能测试、负载测试、压力测试和稳定性测试。
性能测试
狭义的性能测试是指以系统设计初期规划的性能指标为预期目标,对系统不断施加压力,验证系统在资源可接受的范围内是否达到了性能的预期。所以性能测试主要是测试系统的性能是否达到了设计预期这样一个目标,对系统的压力相对比较小的。
负载测试
负载测试,则是对系统不断施加并发请求,增加系统的压力,直到系统的某项或多项指标达到安全临界值。比如某种系统资源已经呈现饱和状态,这个时候继续对系统施加压力,系统的处理能力不但不能提高,反而会下降。所以简单说,负载测试是指通过不断施加负载压力,寻找系统最优的处理能力,最好的性能状态,达到最大的性能指标。通常说来,负载测试的结果比性能测试的结果高一点。
压力测试
第三个压力测试,是指在超过安全负载的情况下,对系统继续施加压力,直到系统崩溃,或者不再处理任何请求,以此获得系统的最大压力承受能力。压力测试也就是,将系统压崩溃需要多大的负载压力或者是并发请求压力,测试系统在最坏的情况下可以承受多大的访问压力。
稳定性测试
稳定性测试则是指被测试的系统在特定的硬件、软件和网络环境条件下,给系统施加一定的业务压力,使系统运行较长一段时间,以此检测系统是否稳定。在生产环境中,请求压力是不均匀的、呈现波浪的特性,因此为了更好地模拟生产环境,稳定性测试也应该不均匀地对系统施加压力,看系统在这种持续的、长时间的、不均匀的访问压力之下,能否稳定地提供响应特性,系统性能是否保持稳定。
性能特性曲线
吞吐量特性曲线
前面提到的,性能测试、负载测试和压力测试,它的测试曲线如下图所示。横轴是系统资源或者并发用户数,对于性能测试,系统资源和并发用户数本质上是一样的,因为随着并发用户数的增加,系统资源消耗是线性增加的。纵轴是它的吞吐量 TPS。

在性能测试阶段,随着并发访问逐渐的增加,系统资源的不断消耗,TPS 是在不断上升的。
到了负载测试阶段,这种上升的斜率会变小,直到达到了系统负载能力的最大点,也就是 c 点。而过了 c 点以后继续施加压力,继续提高并发请求的数量,系统资源消耗进一步增加,TPS 吞吐量不增反降,会呈现下降趋势。直到到达了某个点,d 点,系统超过了它的最大承受能力,系统崩溃。
压力测试的时候,吞吐量之所以会下降,是因为更多的并发请求、更多的用户请求进入系统以后,系统已经无法正常处理这样多的用户请求,系统的资源消耗情况会更加恶化,系统不能够有效地处理用户的正常请求,却又不得不分配出大量的资源,来调度用户的访问请求。这时候系统资源虽然被更多的消耗,但是响应时间在不断地加长,它的 TPS 在下降。
响应时间特性曲线
和 TPS 相对应的响应时间曲线则是相反的,如下图。随着并发用户数的增加,以及系统资源的不断消耗,系统的响应时间在不断增加。在性能测试阶段,系统的响应时间几乎没有太多的变化,但是到了负载测试的时候,系统的响应时间就开始增加,当超过了它最大负载点——c 点以后继续增加压力,系统的响应时间会急剧增加,系统的性能状况急剧恶化,最后到达了它的崩溃点——d 点。

一般说来,性能测试是通过增加并发数,不断测试各项性能指标获得的。如下图性能测试结果表所示,并发数不断地增加,响应时间也不断地增加,TPS 先增加后下降,而错误率超过了某些点以后开始增加,后来增速加剧,同时系统的负载也在不断增加。通过这个表,绘制出来的性能特性曲线就如上面的图中所示。
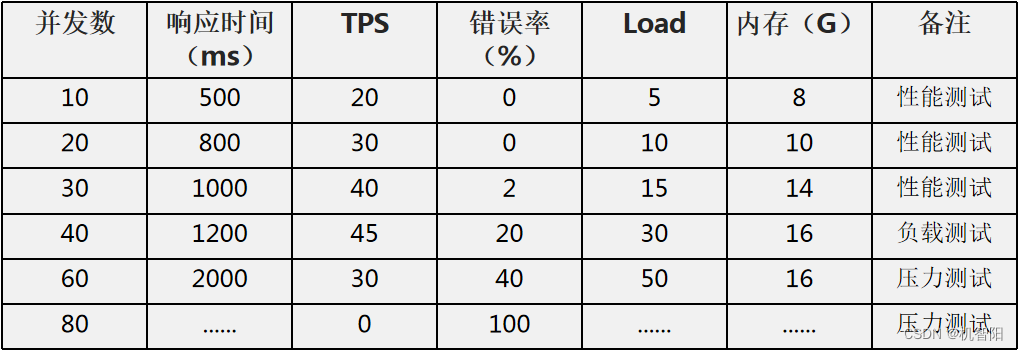
性能测试就是要测试出性能特性曲线,看当前的系统是否达到了性能目标,以及系统最好的性能特性是什么,能达到的最大负载压力是多大。从而做到对自己的系统心中有数,面对高并发访问的时候,心中不慌,从容应对。
系统性能优化
现在我们已经了解了系统的各项性能指标,那么如何对系统进行性能优化呢?
分层优化系统性能
通常当说起对系统性能进行优化的时候,大家一般想到的是对系统内自己写的代码进行优化,或者大不了对系统的架构进行优化,但实际上对系统的性能优化可以有更高层次的思考。如下图所示,将系统的性能优化分为七层,可以在不同的层面对系统进行性能优化。
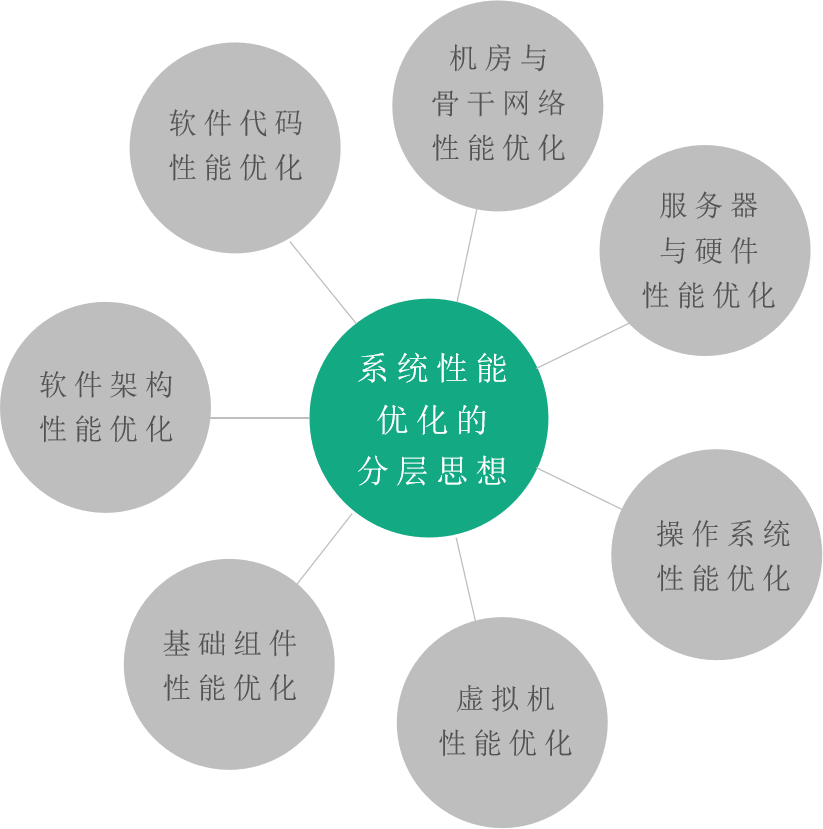
& 第一层是机房与骨干网络的性能优化
对于高并发的、大流量的、海量用户访问的一个互联网应用而言,通常它可能是全球级的,它的用户可能分布在全球各个地方,我们知道,即使是以光的速度进行传输,从地球的另一面对一个数据中心进行数据访问,它的一次请求响应的网络通讯时间都需要几百毫秒的时间,而我们对一个成熟的应用进行性能优化,通常是难以获得几百毫秒的响应时间优化的。所以对于大型互联网应用,它们通常会进行全球各地的多机房部署,就近为当地用户提供访问服务,即使是只针对国内的用户使用的一些大型互联网应用,为了提高不同地区的用户的访问体验,也会进行多机房架构设计。比如说像新浪微博,它们在上海、北京和广州建设了 3 个机房,分别为中国不同地域的用户提供服务。
所以机房与骨干网络的性能优化,主要手段就是采用异地多活的多机房架构,同时为了联通这些异地多活的多机房架构,会建设自己专用的骨干网络,并且自主进行 CDN 建设。
& 第二层是对服务器内的硬件进行优化
我们前面讨论过系统伸缩,有垂直伸缩和水平伸缩两种,互联网应用主要使用的是水平伸缩。但是某些情况下,垂直伸缩实际上带来的性能优化也是不可忽视的。在成本允许的情况下,考虑使用垂直伸缩,提高服务器硬件的性能,对系统性能的提升会有很大的好处。
比如说我们用 SSD 硬盘代替传统的机械硬盘,就可以使磁盘的访问读写特性得到数量级的提升。
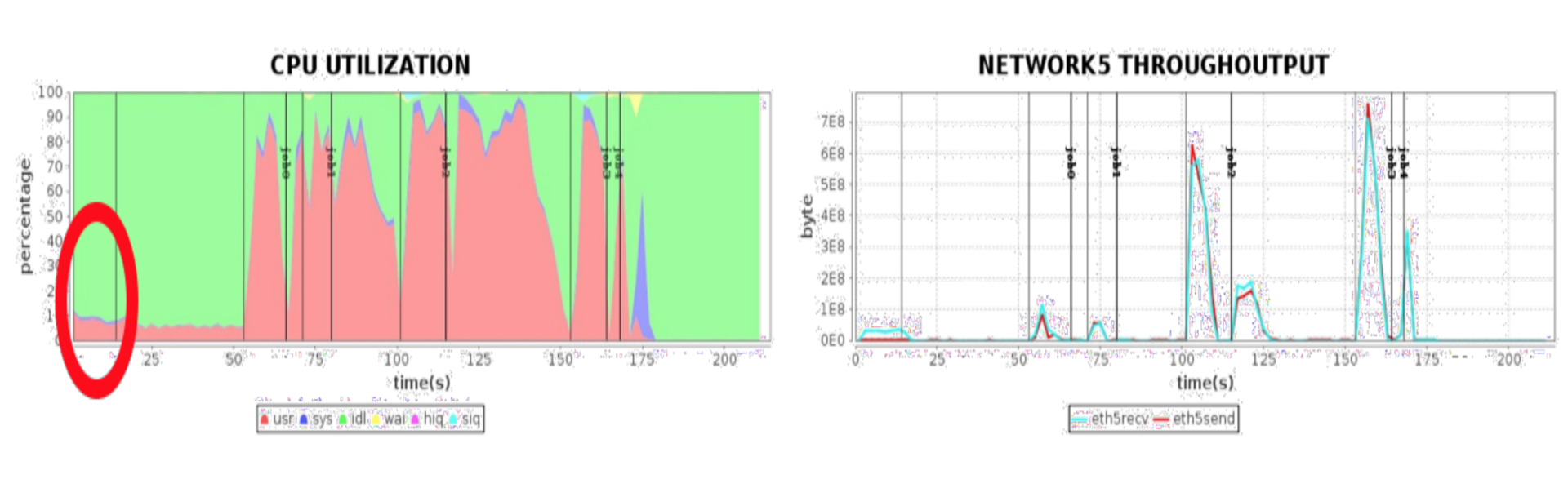
如下图所示,这是一个 Spark 性能优化的案例。因为 Spark 是一个大数据处理平台,所以需要处理大量的数据,在作业处理过程中,不同的服务器之间需要传输大量的数据。经过性能指标分析,我们发现,在一次作业运行中,大量的时间消耗在网络传输上。对这种情况进行性能优化,如果要是从程序或者代码的层面进行优化,那么主要手段就是使用数据压缩,将数据压缩以后进行传输,这样可以减少数据的传输量,减少网络传输的性能压力,降低网络传输花费的时间。但是对数据进行压缩和解压缩,需要消耗大量的 CPU 资源,事实上大数据计算通常也是 CPU 密集型,将宝贵的 CPU 资源花费在数据压缩和解压缩上,最后的性能结果可能会变的更差。
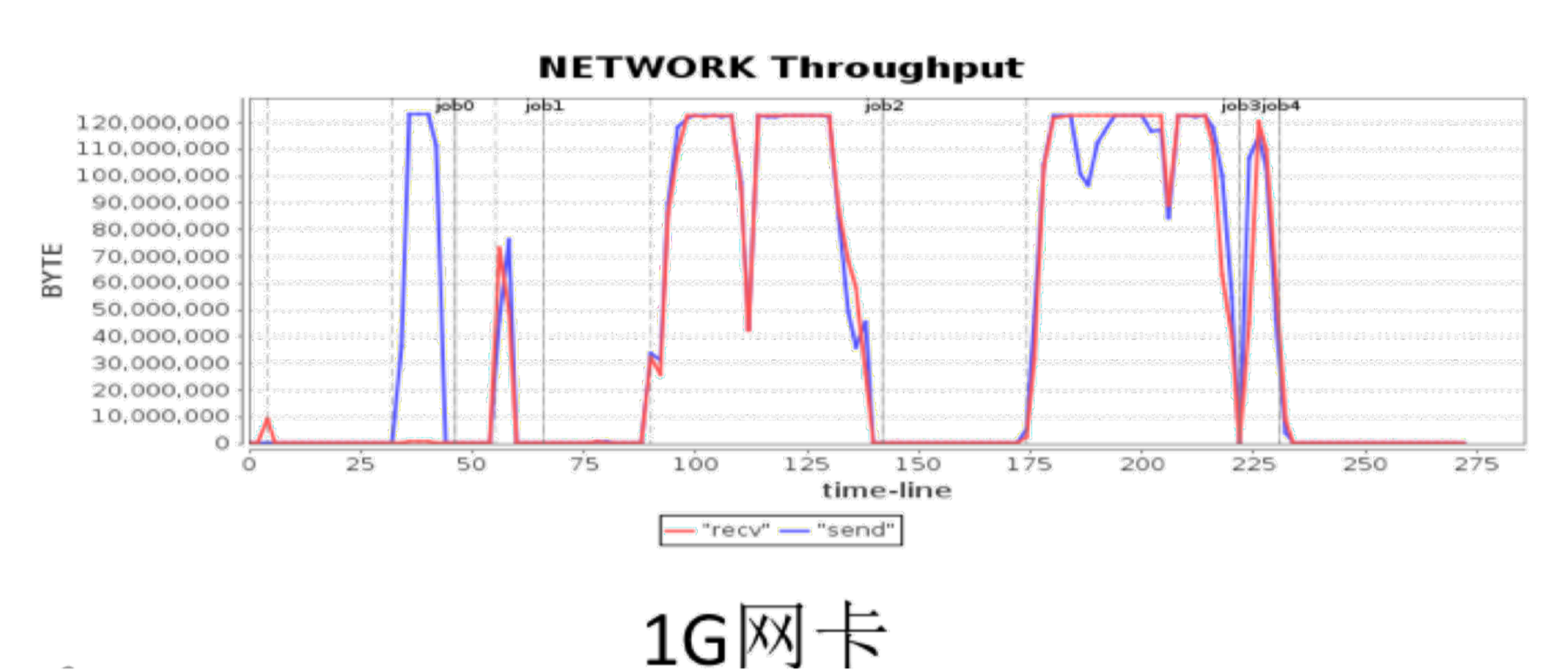
但是我们可以对硬件进行优化,如上图例子中看到的。在优化前,我们使用的是如图这种 1G 的网卡,里面的曲线表示的是网卡读写性能,在某些阶段,网卡的读写传输能力已经达到了它的极限,需要几十秒的时间去完成数据传输,然后再进入下一个计算阶段。
我们通过硬件优化的方法,将网卡更换为 10G 网卡,如下图,得到了这样一条网卡传输的性能曲线,我们看到系统在最大的数据传输压力情况下,它依然没有触发到网卡处理能力的极限,而网络传输的时间也从以前的几十秒缩短到了十多秒。

& 硬件与服务器性能优化再下面一层,是操作系统的性能优化
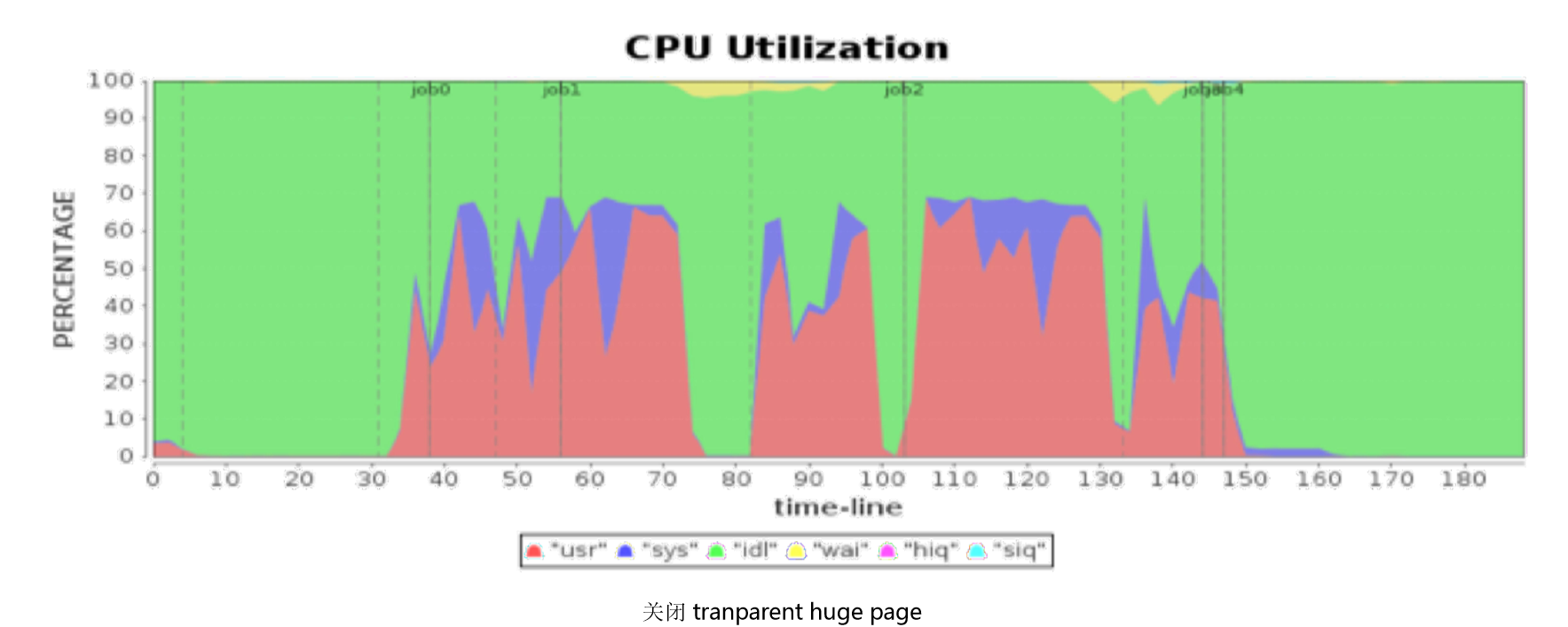
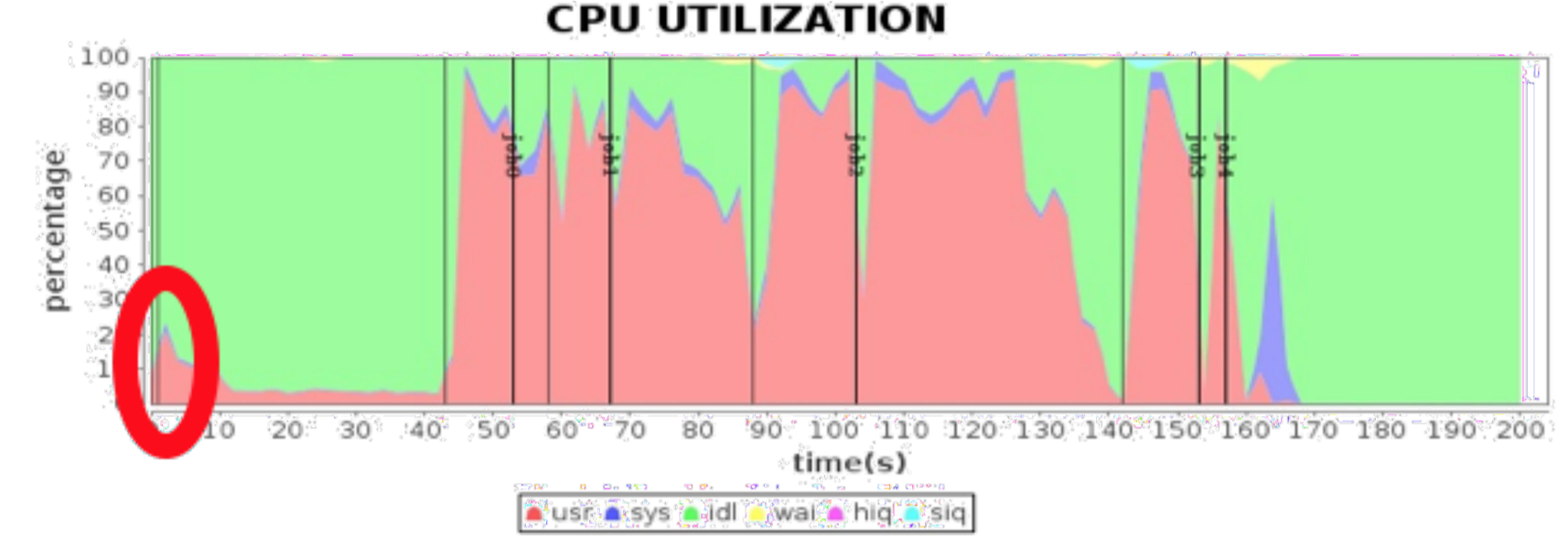
这里我们再看一个案例,依然是 Spark 的性能优化案例。下图中是 CPU 的使用率,我们看到其中红色的是用户程序使用的,表示的是 CPU 的用户态,紫色部分是 CPU 的系统态,红色部分是 User 状态,紫色部分是 sys 状态。紫色部分表示的是当前 CPU 被操作系统占据,执行操作系统的指令。但是为什么在一个大数据处理作业过程中,有这样多的 CPU 时间花费在系统处理上?

经过进一步的性能分析,发现部分 Linux 版本在缺省状况下打开了 tranparent huge page 这样一个参数,当我们关闭参数的时候,发现处于 sys 状态 CPU 的消耗得到了极大的优化,也就是下图。如图所示,关闭 tranparent huge page 后,处于 sys 状态消耗的指标,也就是紫色部分消耗的 CPU 指标得到了极大的改善,而整个的系统作业时间也从 200 多秒优化到了 150 多秒。
& 第四层是虚拟机的性能优化
目前主流的像 Java、C# 这样的一些互联网 Web 应用,都是运行在虚拟机之上的,那么对虚拟机的性能优化也会对系统的整个性能产生巨大的影响。
最典型的就是垃圾回收器对系统的性能优化,如下图,我们看到 Java 的几种不同垃圾回收器,从最早的串行垃圾回收器,到目前比较新的 G1、ZGC 等垃圾回收器,每一类的垃圾回收器都会对系统性能有不同的影响。

在互联网应用中使用的主要的垃圾回收器是 CMS 垃圾回收器。CMS 垃圾回收线程和用户的线程在很多时候是并发运行的,这也是 CMS 被称为并发垃圾回收器的原因。因为用户线程和垃圾回收线程并发运行,所以在垃圾回收的时候对用户的性能影响相对比较小一点。而在未来,主流的垃圾回收器应该是 G1。
在虚拟机之下是基础组件的性能优化
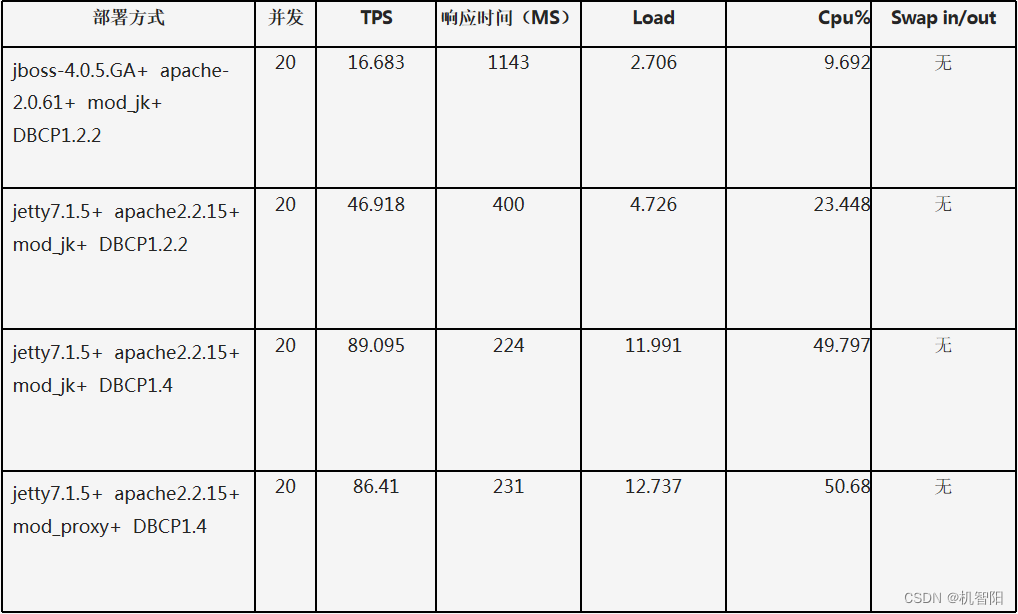
我们的 Web 应用主要是运行和部署在 Web 容器组件上,比如像 Java 运行在 Tomcat、Jetty 或者 JBoss(WildFly)这样的 Web 容器之中,那么 Web 容器本身的性能也一定会对我们这些系统性能产生很大的影响。举一个现实的例子,在阿里巴巴曾经使用 Jetty 代替 JBoss,通过这样一种替换,实现了系统性能的极大的提升,特别是节省了大量的服务器,在替换后,阿里巴巴全站下线 1/3 的应用服务器。主要原因是 Jetty 比 JBoss 的架构更轻量,配置更加简单,使用较少的 Jetty 容器,就可以实现原来 JBoss 能够提供的处理能力,如下图所示。
在基础组件性能优化之下才是软件架构性能优化
事实上我们整个课程都是围绕着架构性能优化的各种工具和技术展开的。在这里面我们精简一下,抽象了关于软件架构性能优化的三板斧。这三板斧也是互联网系统架构的最主要的三个技术,分别是缓存、异步和集群。
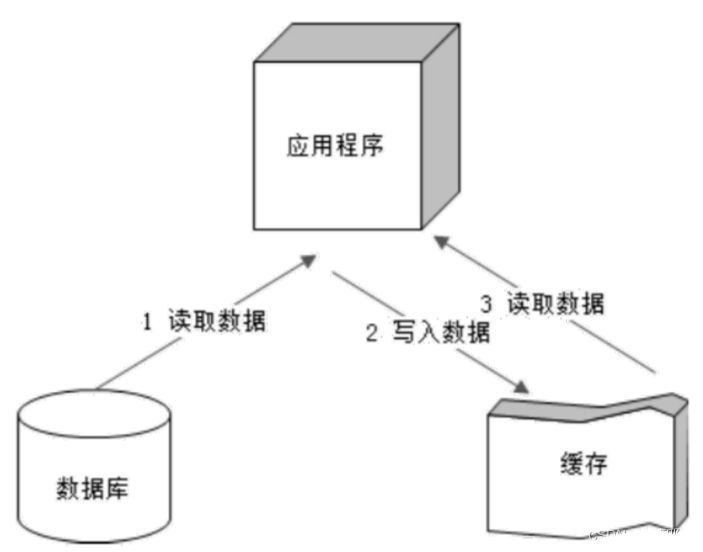
& 缓存
通过缓存可以减少数据库的负载压力。缓存使用内存中的数据,比数据库访问磁盘中的数据要有更好的性能,同时缓存中存储着的计算结果数据,也比数据库中存储的原始数据计算速度更快,资源消耗更小。此外还有一点,缓存减少了数据库的负载压力,从而可以使数据库提供更多的数据访问,支撑更大的系统访问压力,从而提升整体的系统性能。
& 异步
通过异步的方式,通过分布式消息队列,使系统不同应用之间、不同服务之间异步调用,可以使调用者尽快的返回用户响应,使系统能够得到更好的响应特性。同时分布式消息队列的异步架构,还有削峰填谷的作用,在访问高峰期,通过异步将用户请求数据写入到消息队列中,在访问低谷的时候还在继续消费处理这些消息,避免对数据库等产生较大的负载访问压力,使系统能够维持在一个较好地响应曲线上。
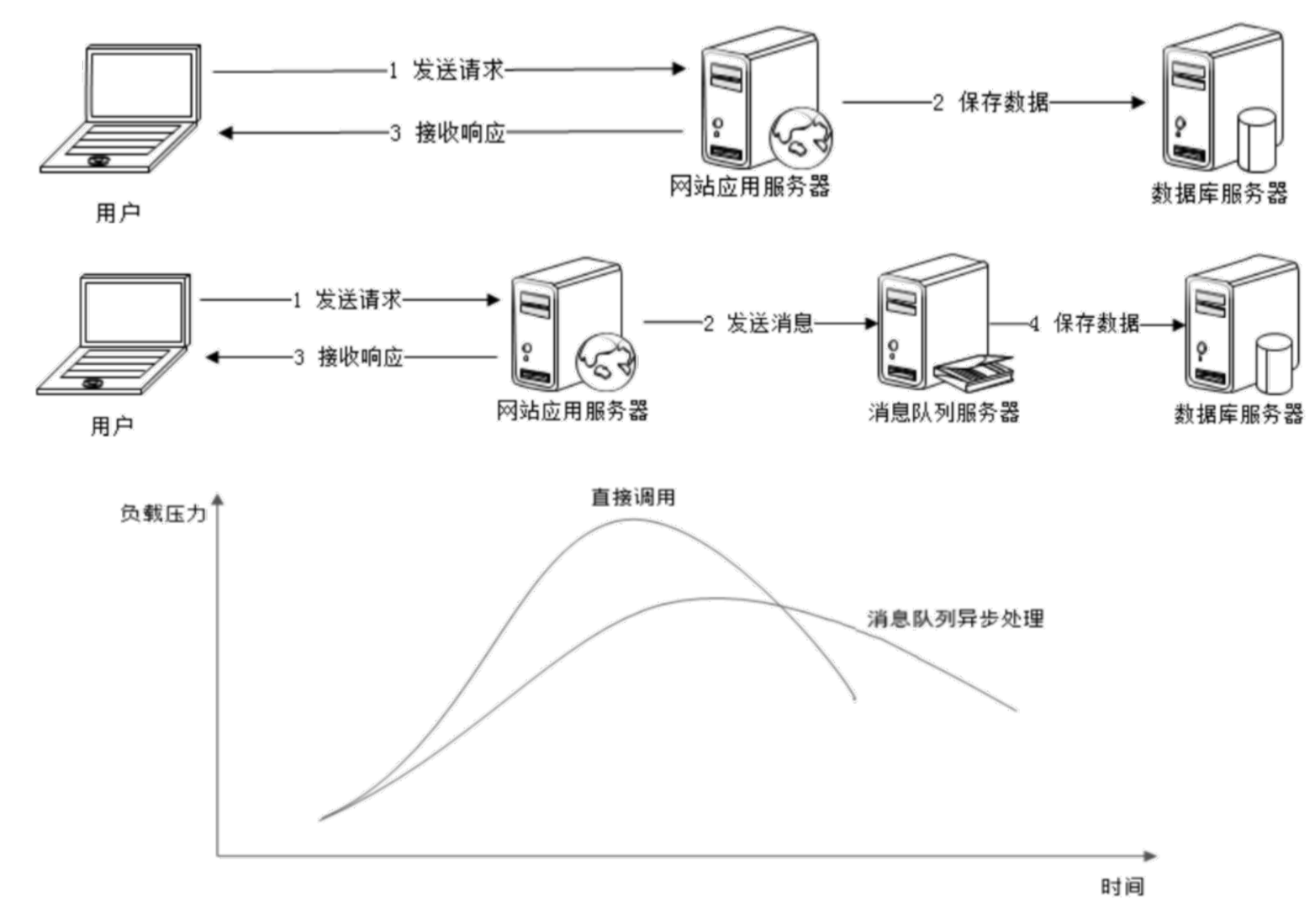
& 集群
通过负载均衡的手段,将多种应用服务器构建成一个集群,共同提供服务,以提高系统整个的处理能力,提升系统的响应性能。
& 在性能优化的最底层才是软件代码的性能优化
关于代码的性能优化,有这样一些实践可供参考。
& 第一点是遵循面向对象的设计原则与设计模式编程,避免烂代码。
很多时候,我们应用程序性能不好,并不是性能上有什么技术挑战或者是缺陷,仅仅就是因为代码太烂了,系统之间调用耦合严重,很多已经不用的代码,无法清理下线,执行逻辑混乱,导致系统性能差。使用良好的原则与模式编程,编写清晰、灵活、健壮的代码对性能优化有长远的好处。
& 第二点是并发编程,可以在程序并发运行的时候使用多线程。
& 第三点是资源的复用。
对于一些比较昂贵的资源,比如说线程或者数据库连接,通过线程池或者数据库连接池对外提供服务。通过资源池复用对象或者是线程,供应用程序使用,应用程序每次需要资源的时候,从资源池获取,用完了放回到资源池中继续复用,而不是每次使用的时候都去创建,用完了以后就销毁。
& 第四点是用异步编程。
在程序内部使用消费者,生产者,以队列数据结构的方式,实现程序内的异步架构,以此来提高系统性能。
& 第五点是要使用正确的数据结构进行编程。
要熟悉数组、链表、栈、队列、Hash 表、树等常用数据结构,熟悉它们的特性、优缺点以及使用场景,正确地使用它们来管理和访问程序数据。
性能优化案例
我们以 Spark 为例,看一个代码的性能优化案例。如下图,我们通过对 CPU 的性能指标的分析发现,在 Spark 作业过程中有一个计算阶段 Stage,运行时间特别长,消耗时间 14 秒。CPU 和网络也都有一定的开销,研究应用代码,发现这段代码仅仅是做了一个数组的初始化,不应该需要花这么长的时间,那么时间究竟花在哪里呢?
进一步对 Spark 的源代码进行分析,发现 Spark 的任务初始化加载应用代码的时候,每一个执行器 Executor 都要加载一次可执行的应用代码,当时每台服务器启动了 48 个 Executor,每个应用程序的代码包是 17M,所以每一个服务器需要下载 48×17M,而集群有 5 台服务器。通过网络传输这么大的代码包,导致网络阻塞,性能劣化。后来我们对 Spark 的源代码进行了优化,主要优化手段就是在 Executor 加载应用程序的时候,启动了本地文件的缓存模式,先检查本地文件中是否有需要执行的应用程序代码,如果没有,远程从 Driver 服务器上去加载,如果有直接拷贝本地代码到自己的执行路径下,通过这种优化,我们使第一个运行阶段,从 14 秒下降到了不到 1 秒,如下图所示。
优化代码如下图所示,在 Spark 源码增加基于缓存的文件加载函数,十多行代码,获得极大的性能提升。

总结回顾
性能优化的前提和基础是性能测试,通过性能测试,了解系统的性能特性才能进行优化,而性能测试主要就是要测试出来系统的性能曲线,通过对性能曲线进行分析,了解系统的瓶颈点和系统资源消耗,再进行性能优化。性能优化的时候需要建立一个整体的思维,要从整体系统的层面去思考优化,而不只是仅仅关注自己的代码,或者是自己设计的架构。
最上层的优化是硬件优化,包括骨干网络、数据中心服务器硬件这样的优化;然后是基础组件的性能优化,包括操作系统、虚拟机、应用中间件这几个方面;这之后才是架构的优化,包括核心的三板斧,缓存、异步和集群;最后才是代码的优化,代码优化的主要手段,有并发、复用、异步以及正确的数据结构,当然最重要的是设计清晰、易维护、易懂、简单、灵活的代码,也就是说最重要的是要遵循面向对象的设计原则和设计模式进行编程。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 游泳耳机排行榜前四名,分享几款值得推荐的游泳耳机
- 手把手从0开始SpringBoot多模块项目搭建
- Android蓝牙协议栈fluoride(八) - 音乐播放与控制(1)
- SpringBoot3知识总结
- 买卖股票,会产生这些费用,你知道吗?
- 【uniapp】多规格选择
- 【LabVIEW FPGA入门】使用LabVIEW FPGA进行编程并进行编译
- thinkphp学习04-控制器定义
- 【STL】std::map使用小结
- 手机崩溃日志的查找与分析