2023年泰迪杯数据分析赛a题解析(一)
一、背景
档案数字化是随着扫描、OCR、数字摄影、数据库、多媒体、存储等技术的发展而产生 的一种新型档案信息处理技术,它把各种载体的档案资源转化为数字化档案信息,以数字化 的形式存储,网络化的形式互相连接,利用计算机系统进行管理,形成一个有序结构的档案 信息库。我国档案工作采取“存量数字化、增量电子化”的信息化战略。当前我国各行业的 存量档案数量巨大,档案数字化的需求不断增加,档案数字化加工行业的市场规模呈现逐年 增长的趋势。
二、目标
对加工流程数据进行统计分析,并作可视化展示,便于管理人员及时了解档案加工处理 动态。 1. 统计档案数字化流程的耗时和进度情况。 2. 统计操作人员的工作量和工作效率情况。
三、任务一
1.1统计完成四道工序的案卷数量,在报告中列出统计结果。汇总各案卷各工序 的开始时间及各案卷的完成时长,以表 1 的格式将汇总结果保存到文件“result1_1.xlsx” 中,同时在报告中列出案卷完成时长最长的三个案卷的结果。
 首先对数据中sARCH_I,iFLOW_NODE_NO,dUPDATE_TIME,dNODE_TIME这几列的缺失值(工序未完成)进行删除;提取出各个工序数据并进行重命名;最后对数据进行合并
首先对数据中sARCH_I,iFLOW_NODE_NO,dUPDATE_TIME,dNODE_TIME这几列的缺失值(工序未完成)进行删除;提取出各个工序数据并进行重命名;最后对数据进行合并

对合并后的数据进行统计得出案卷数量为33980
汇总各案卷各工序的开始时间及各案卷的完成时长
设计一个算法来得出完成时长是多少,首先定义一个工作时间段,将时间段转化成datetime对象;设置初始工作时长为0,接下来遍历两个时间之间的每一天,在循环里判断是否为工作日,是的话设置当日上下午工作时间段;还要判断是否跨天一直判断到最后一天,最后累加工作时长。返回这个算法的工作时长。
一个工序实现一次最后相加就为总时长。
部分代码如下
?
import datetime
def calculate_working_hours(start_time, end_time):
# 定义工作时间段
working_days = [0,1,2,3,4,5]
working_hours = {
'start_morning': (8, 30, 0),
'end_morning': (12, 0, 0),
'start_afternoon': (13, 0, 0),
'end_afternoon': (18, 0, 0)
}
# 将时间字符串转换为 datetime 对象
start_datetime = start_time
end_datetime = end_time
# 初始化工作时长为0
working_duration = datetime.timedelta()
# 遍历两个时间之间的每一天
current_datetime = start_datetime
while current_datetime.date() <= end_datetime.date():
# 检查是否为工作日
if current_datetime.weekday() in working_days:
rest_time = datetime.timedelta()
# 设置当日上午工作时间段
morning_start = datetime.datetime(
current_datetime.year, current_datetime.month, current_datetime.day,
working_hours['start_morning'][0], working_hours['start_morning'][1],
working_hours['start_morning'][2]
)
morning_end = datetime.datetime(
current_datetime.year, current_datetime.month, current_datetime.day,
working_hours['end_morning'][0], working_hours['end_morning'][1],
working_hours['end_morning'][2]
)
# 设置当日下午工作时间段
afternoon_start = datetime.datetime(
current_datetime.year, current_datetime.month, current_datetime.day,
working_hours['start_afternoon'][0], working_hours['start_afternoon'][1],
working_hours['start_afternoon'][2]
)
afternoon_end = datetime.datetime(
current_datetime.year, current_datetime.month, current_datetime.day,
working_hours['end_afternoon'][0], working_hours['end_afternoon'][1],
working_hours['end_afternoon'][2]
)最后得出列出案卷完成时长最长的三个案卷的结果

1.2统计需要返工的案卷数量及其占完工案卷总数的百分比,在报告中列出结果。 汇总返工案卷的返工工序和返工开始时间,以表 2 的格式将汇总结果保存到文件 “result1_2.xlsx”中,同时在报告中列出返工案卷号“托 40606-册六”“托 40606-册七” “托 5901_1-册三”的结果。
统计需要返工的案卷数量及其占完工案卷总数的百分比
首先我们将不用返工的案卷后删除提取出数据,如何选择我们需要的列,再选择工序状态为5的数据,计算出需要返工的案卷数是797,然后与data1_1_result中的已完成的案卷数相除得出百分比。

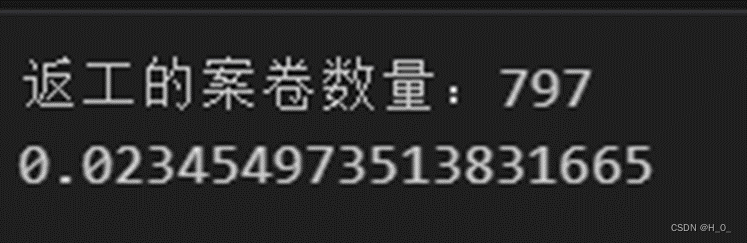
统计百分比结果为2.3454%
首先我们将扫描等四种情况分出,再对其重命名,然后对数据进行合并得出需要返工的开始时间并保存为result1_2.xlsx
# 根据iFLOW_NODE_NO值筛选不同流程节点的数据,并选择需要的列
data1_2_sm = data1_2[data1_2['iFLOW_NODE_NO'] == 1][['sARCH_ID','dUPDATE_TIME','dNODE_TIME','dPROC_TIME']]
data1_2_cl = data1_2[data1_2['iFLOW_NODE_NO'] == 2][['sARCH_ID','dUPDATE_TIME','dNODE_TIME','dPROC_TIME']]
data1_2_jc = data1_2[data1_2['iFLOW_NODE_NO'] == 3][['sARCH_ID','dUPDATE_TIME','dNODE_TIME','dPROC_TIME']]
data1_2_pdf = data1_2[data1_2['iFLOW_NODE_NO'] == 4][['sARCH_ID','dUPDATE_TIME','dNODE_TIME','dPROC_TIME']]
# 重命名列名
data1_2_sm = data1_2_sm.rename(columns={'sARCH_ID':'案卷号','dUPDATE_TIME':'扫描开始时间','dNODE_TIME':'扫描结束时间','dPROC_TIME':'返工'})
data1_2_cl = data1_2_cl.rename(columns={'sARCH_ID':'案卷号','dUPDATE_TIME':'图像处理开始时间','dNODE_TIME':'图像处理结束时间','dPROC_TIME':'返工'})
data1_2_jc = data1_2_jc.rename(columns={'sARCH_ID':'案卷号','dUPDATE_TIME':'自检全检开始时间','dNODE_TIME':'自检全检结束时间','dPROC_TIME':'返工时间'})
data1_2_pdf = data1_2_pdf.rename(columns={'sARCH_ID':'案卷号','dUPDATE_TIME':'PDF处理开始时间','dNODE_TIME':'PDF处理结束时间','dPROC_TIME':'返工时间'})
# 合并结果
data1_2_result = pd.merge(data1_2_sm, data1_2_cl, on = '案卷号',how='outer')
data1_2_result = pd.merge(data1_2_result, data1_2_jc, on = '案卷号',how='outer')
data1_2_result = pd.merge(data1_2_result, data1_2_pdf, on = '案卷号',how='outer')
# 删除不需要的列
data1_2_result=data1_2_result.drop(['扫描开始时间','扫描结束时间','图像处理开始时间','图像处理结束时间','自检全检开始时间','自检全检结束时间','PDF处理开始时间','PDF处理结束时间'],axis=1)
# 重命名列名
data1_2_result = data1_2_result.rename(columns={'返工_x':'扫描时间','返工_y':'图像处理','返工时间_x':'自检全检','返工时间_y':'PDF处理'})
# 将案卷号设置为索引
data1_2_result=data1_2_result.set_index('案卷号')
# 导出结果到Excel文件
data1_2_result.to_excel('result1_2.xlsx')返工案卷号“托 40606-册六”“托 40606-册七” “托 5901_1-册三”的结果如图所示:

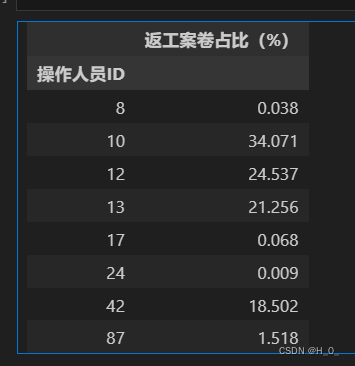
1.3 对自检全检工序,汇总每个操作人员的返工案卷数,计算其占该操作人员该 工序工作总量的百分比,按百分比降序排列,以表 3 的格式将结果保存到文件 “result1_3.xlsx”中,同时在报告中列出前三位操作人员的结果。结果保留 3 位小数,例 如:返工案卷占比为 1%,在结果表中填写“1.000”。
提取出自检全检工序的数据,对每个操作人员进行汇总返工案件数,然后运用lambda函数进行百分比计算得出结果。代码较为简单
得出一下结果:
1.4 按工序分别统计完成案卷的数量、总耗时和平均耗时,以表 4 的格式将结果 保存到文件“result1_4.xlsx”中,并在报告中列出结果。结果保留 3 位小数。
首先计算了各个阶段的最小时间和最大时间,分别存储在min_list和max_list中。然后,通过计算时间差,将各个阶段的耗时转换为小时,并存储在sum_time_list中。接着,计算了PDF处理阶段的耗时均值,将结果存储在mean_pdf中。然后,对data1_1_result中的PDF处理开始时间和结束时间进行迭代,计算每个案卷的PDF处理耗时,并将结果存储在list_pdf中。接下来,计算各个阶段的耗时均值,并将结果存储在mean_time_list中。然后,对data1_4进行一些数据处理,包括删除dNODE_TIME列和重命名iID列。最后,将总耗时和平均耗时的结果添加到data1_4中,并将结果保存为Excel文件(result1_4.xlsx)。
部分代码展示:
data1_4_dropna = data[['iID','iFLOW_NODE_NO','dNODE_TIME']].dropna()
data1_4 = data1_4_dropna.groupby(by = 'iFLOW_NODE_NO').count()
data1_4.index = ['扫描','图像处理','自检全检','PDF处理']
data1_4.index.name = '工序'
min_sm = data1_1_result['扫描开始时间'].min()
max_sm = data1_1_result['扫描结束时间'].max()
min_tx = data1_1_result['图像处理开始时间'].min()
max_tx = data1_1_result['图像处理结束时间'].max()
min_jc = data1_1_result['自检全检开始时间'].min()
max_jc = data1_1_result['自检全检结束时间'].max()
min_pdf = data1_1_result['PDF处理开始时间'].min()
max_pdf = data1_1_result['PDF处理结束时间'].max()
min_list = [min_sm, min_tx, min_jc, min_pdf]
max_list = [max_sm, max_tx, max_jc, max_pdf]
结果如下:

任务 1.5 按操作人员、工序统计工作时长、完成案卷的数量和每个案卷的平均耗时(h/ 卷),以表 5 的格式将结果按操作人员 ID 升序排列保存到文件“result1_5.xlsx”中,同 时在正文中列出操作人员 ID“10”“33”“48”的结果。结果保留 3 位小数。
先对数据进行提取然后为各个阶段的结果添加一个名为'工序'的列,并分别赋予对应的工序名称。接着,对各个阶段的结果进行重命名,将'案卷号'列重命名为'完成案卷的数量',将对应的完成时间列重命名为'工作时长'。最后,将各个阶段的结果按行进行合并,生成一个包含所有阶段的结果的DataFrame,存储在data1_5_result中。通过使用apply函数,计算了每个案卷的平均耗时,结果存储在新的列'每个案卷的平均耗时 (h/卷)'中。然后,通过调用sort_index函数,按照默认的行索引进行排序。最后,重新排列列的顺序,将'工序'、'工作时长'、'完成案卷的数量'和'每个案卷的平均耗时 (h/卷)'列置于最前面,更新了data1_5_result的列顺序。最后保存文件
结果如图所示:



该分析获得此次比赛二等奖,仅供参考!!
需要题目和代码的请私信我
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【String str = new String(“hollis“) 创建了几个对象?】
- 运用虚拟空间建造网站的缺点
- 如何用MyEclipse搭建JSF/Primefaces和Spring(一)
- VUE生命周期和生命周期四个阶段
- 量子密码学简介
- LeetCode每日一题.07(整数反转)
- java: 5-4 while循环
- 深入理解与运用Lombok的@Cleanup注解:自动化资源管理利器
- 数字之美:探秘数据可视化如何在我们的日常生活中展现魅力
- 挑战与创新:光学字符识别技术在处理复杂表格结构中的应用