Numpy实现K-means算法
发布时间:2023年12月20日
Numpy实现K-means算法
import numpy as np
import matplotlib.pyplot as plt
def kmeans(X, k, max_iters=1000, tol=1e-4):
"""
K-means聚类算法的NumPy实现
Parameters:
X (numpy.ndarray): 输入数据集,每一行代表一个样本,每一列代表一个特征。
k (int): 簇的数量。
max_iters (int): 最大迭代次数。
tol (float): 收敛阈值,当簇中心变化小于该值时停止迭代。
Returns:
centroids (numpy.ndarray): 最终的簇中心。
labels (numpy.ndarray): 每个样本的簇标签。
"""
m, n = X.shape
centroids = X[np.random.choice(m, k, replace=False)]
labels = np.zeros(m)
for _ in range(max_iters):
distances = np.linalg.norm(X - centroids[:, np.newaxis], axis=2)
new_labels = np.argmin(distances, axis=0)
new_centroids = np.array([X[new_labels == z].mean(axis=0) for z in range(k)])
if np.linalg.norm(new_centroids - centroids) < tol:
break
centroids = new_centroids
labels = new_labels
return centroids, labels
# 生成100个随机数据点作为示例
np.random.seed(0)
X = np.random.rand(1000, 2) * 10
# 使用自定义的K-means算法进行聚类
k = 3
centroids, labels = kmeans(X, k)
# 可视化结果
colors = ["g.", "r.","b."]
for i in range(len(X)):
plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize=5)
# 绘制簇中心
plt.scatter(centroids[:, 0], centroids[:, 1], marker="x", s=150, linewidths=5, zorder=10)
plt.show()
K=3时的聚类结果

k=2时的聚类结果
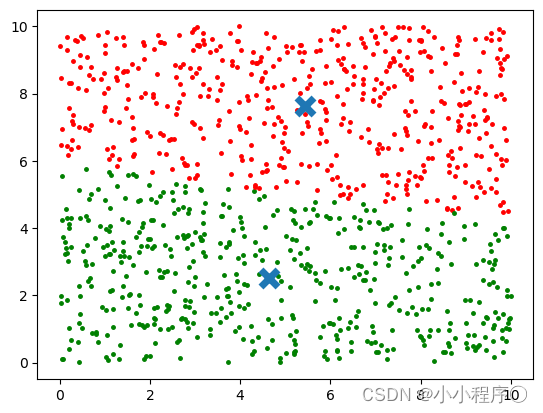
k=4的聚类结果
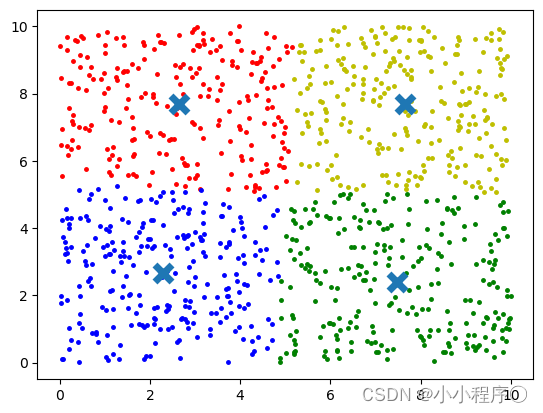
不同的k对应不同的结果,运行的时间也不相同。并且随着数据的增加,K-means计算的消耗成倍增长。
基于上篇博客K-means算法的代码实现
到这里,如果还有什么疑问欢迎私信、或评论博主问题哦,博主会尽自己能力为你解答疑惑的!
如果对你有帮助,你的赞和关注是对博主最大的支持!!
文章来源:https://blog.csdn.net/2201_75381449/article/details/135102607
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SpringSecurity集成JWT实现后端认证授权保姆级教程-授权配置篇
- tcp的聊天室
- 第三章 类和对象进阶之——构造函数
- javaScript设计模式-工厂
- math.isnan()方法的理解
- openssl3.2 - 官方demo学习 - cms - cms_comp.c
- Python:合并两个PDF文件为一个PDF
- Minikube安装
- 基于Springboot+vue高校宿舍管理系统(前后端分离)
- 情暖寒冬,趣味运动 ——开封市鼓楼区民政局社工开展养老院老年人关爱活动