TensorRT 简单介绍
一、TensorRT
对于算法工程师来说,相信大家已经对TensorRT耳熟能详了,那么这个TensorRT是什么呢?
其实,TensorRT是一个可以在NVIDIA各种GPU硬件平台下运行的推理引擎,同时也是一个高性能的深度学习推理优化器,可以为深度学习的落地应用起到低延迟、高吞吐的作用。
TensorRT是由C++、CUDA、Python三种语言编写成的一个库,其中核心代码的语言为C++和CUDA,当然,它也有Python的API接口。
二、应用场景
算法工程师的日常工作当然是训练,我们在进行模型训练的时候可能会选用Pytorch、Tensorflow、Caffe等不同的深度学习框架,并且训练的时候可以使用很充裕的GPU算力。但是在实际部署的时候,为了节省成本,所以在推理时并不会使用过多的GPU资源,甚至是使用CPU来进行模型的推理。鉴于低GPU算力的原因,在嵌入式平台或自动驾驶平台就会使用TensorRT进行推理加速。
在实际项目中,我们可能需要将目标检测、实例分割、OCR等模型部署到一块,这里可能会遇到一种情况:A模型使用了Tensorflow框架,B模型使用了Pytorch框架,C模型使用了Caffe框架。那这样会导致一个问题:代码运行环境的适配就成了大问题。
所以我们希望有一个通用的框架来运行以上的模型。
TensorRT就是用来解决这些问题,它可以将不同框架下训练好的模型统一转为TensorRT引擎再运行,同时会对模型进行优化,从而节省模型在推理时所使用的GPU资源和运行时间。TensorRT与NVIDIA的GPU结合后,几乎可以在所有的深度学习框架中高效部署。
三、TensorRT的加速效果如何?
TensorRT主要通过融合层、优化内核的选择和量化等方式来加速网络的推理速度,从而改善推理的延迟和内存消耗。

当然,具体的加速效果取决于模型的类型与它的大小,也取决于我们所使用的显卡类型。对于GPU来说,它底层硬件的设计更适合并行计算,它也更喜欢密集型的计算。因此,对于通道数较多的卷积层和转置卷积层,TensorRT的加速效果比较明显;而对于比较繁琐而细小的OP操作,如reshape、gather、split这些操作就没有那么显而易见。
在调研中发现,不同模型在TensorRT下的加速效果如下:
- 在Caffe框架下训练出来的的SSD检测模型可以加速3倍;
- 在Caffe框架下训练出来的的SSD检测模型可以加速3倍;
- Pytorch下的大模型,如GAN网络,加速比较明显,能有7到20倍;
- Tensorflow下的LSTM、Transformer模型则只能起到0.5倍到1倍的加速效果;
- 在Keras下,ResNet能加速3倍左右;
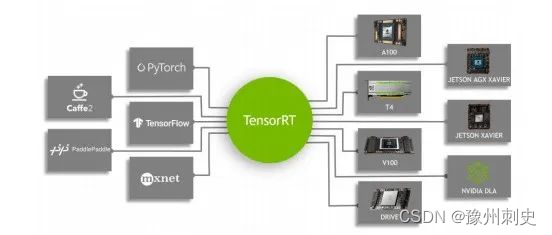
四、TensorRT支持那些生态
首先需要你的设备有NVIDIA的显卡或者能够支持NVIDIA的显卡,并且算力在5.0以上。像A100、2080Ti、1080Ti这一些都是可以的。据说TX2、Nano这些载有嵌入式端显卡的设备也是支持的。
TensorRT目前支持的语言有C++和Python。对于大多炼丹师来说,使用的语言应该都是Python,上述也提到,对于Tensorflow、Pytorch这一些我们平常用于训练模型的深度学习框架来说,TensorRT也都是支持的。
所以对于大多数深度学习工作者来说,都是可以轻松上手的。这样对于大多数AI开发者来说就十分友好!
五、TensorRT 缺点
万事万物都有两面性,TensorRT也是如此。虽然TensorRT很强大,但是它也是有缺点的。
-
高版本的TensorRT依赖于高版本的CUDA,低版本的CUDA是无法支持的。而高版本的CUDA依赖于高版本的驱动。所以如果你想从低版本的TensorRT升级到高版本的TensorRT,就必须更换环境。
-
TensorRT并没有完全开源。TensorRT的推理优化部分并没有完全开源出来,因此在实际使用的时候,我们就好像在使用一个黑盒子,没有办法知道里面具体发生了哪一些过程。
-
经过推理优化后的Engine引擎与特定的GPU型号绑定,不同的GPU型号无法进行共享。例如在3090上生成的引擎不能在A100上使用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 浅学JAVAFX布局
- 了解不同方式导入导出的速度之快
- Java版直播商城免 费 搭 建:电商、小程序、三级分销及免 费 搭 建,平台规划与营销策略全掌握
- K8S 中对 Windows 节点的利用
- vsCode编辑器中wxml微信小程序代码没有高亮
- 安装tensorrt环境在linux上
- json 读取中文、保存为中文的json文件
- 天软特色因子看板 (2024.01 第1期)
- 扩散模型基础
- Socket.D 基于消息的响应式应用层网络协议