旅游大数据分析预测系统+可视化 +贝叶斯预测模型 大数据毕业设计(附源码)?
发布时间:2024年01月05日
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业?。🍅
1、项目介绍
技术栈: Flask框架、requests爬虫、Echarts可视化、MySQL数据库、贝叶斯预测模型
利用网络爬虫技术从马蜂窝网站爬取各城市的景点旅游数据,根据马蜂窝旅游网的数据综合分析每个城市的热度、热门小吃和景点周边住宿,
可以很方便的通过浏览器端找到自己所需要的信息,获取到当前的热门目的地,根据各城市景点的数据,
周围小吃,住宿等信息,制定出适合自己的最佳旅游方案。
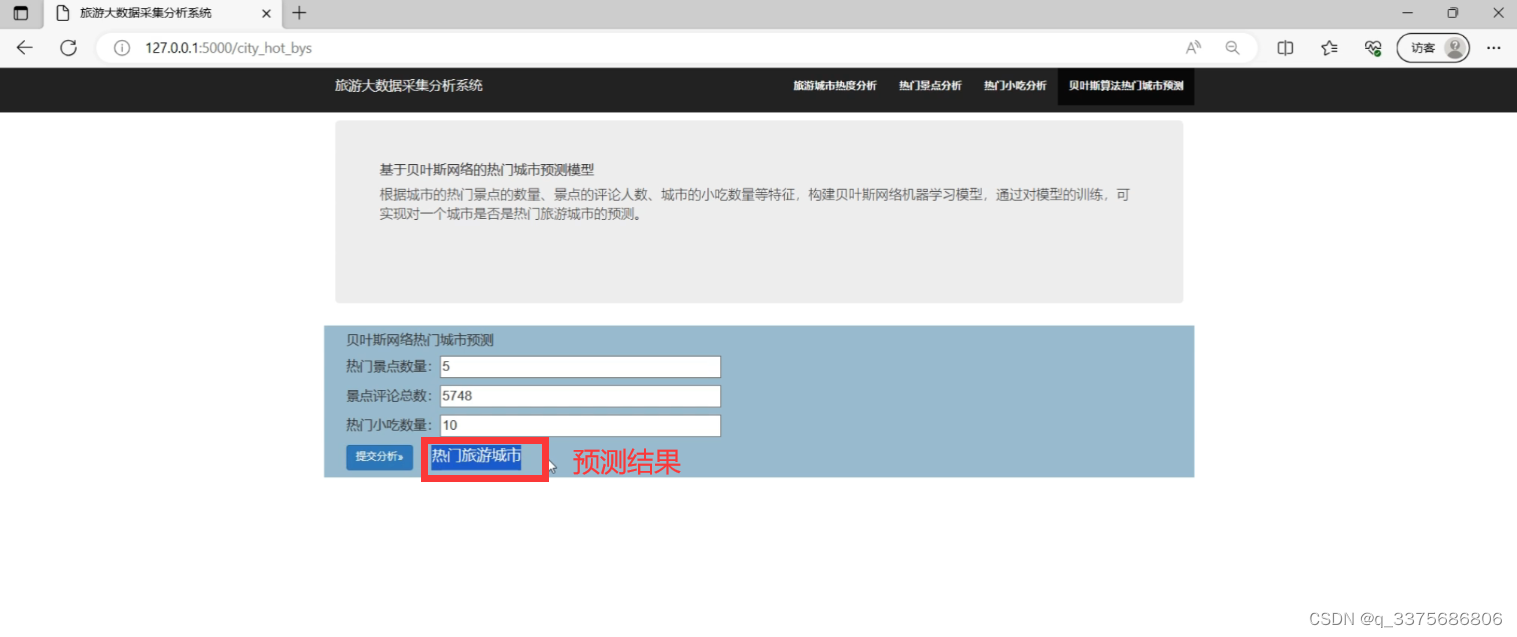
贝叶斯预测模型 (基于贝叶斯网络的热门城市预测模型)
根据城市的热门景点的数量、景点的评论人数、城市的小吃数量等特征,构建贝叶斯网络机器学习模型,通过对模型的训练,可实现对一个城市是否是热门旅游城市的预测。
用户可以通过系统的前端界面,选择需要的数据分析和可视化功能,系统将根据用户的选择,从数据库中提取相应的数据进行处理和展示。用户可以通过系统的搜索功能,查找特定的旅游数据,并进行数据分析和预测,以便做出更好的决策。系统还提供导出数据的功能,用户可以将分析结果导出为Excel或CSV文件,以便进行进一步的分析或报告生成。
通过这个系统,用户可以更方便地获取和分析旅游相关的大数据,从而更好地理解市场需求、优化旅游产品和服务,提升旅游业的发展和竞争力。
2、项目界面
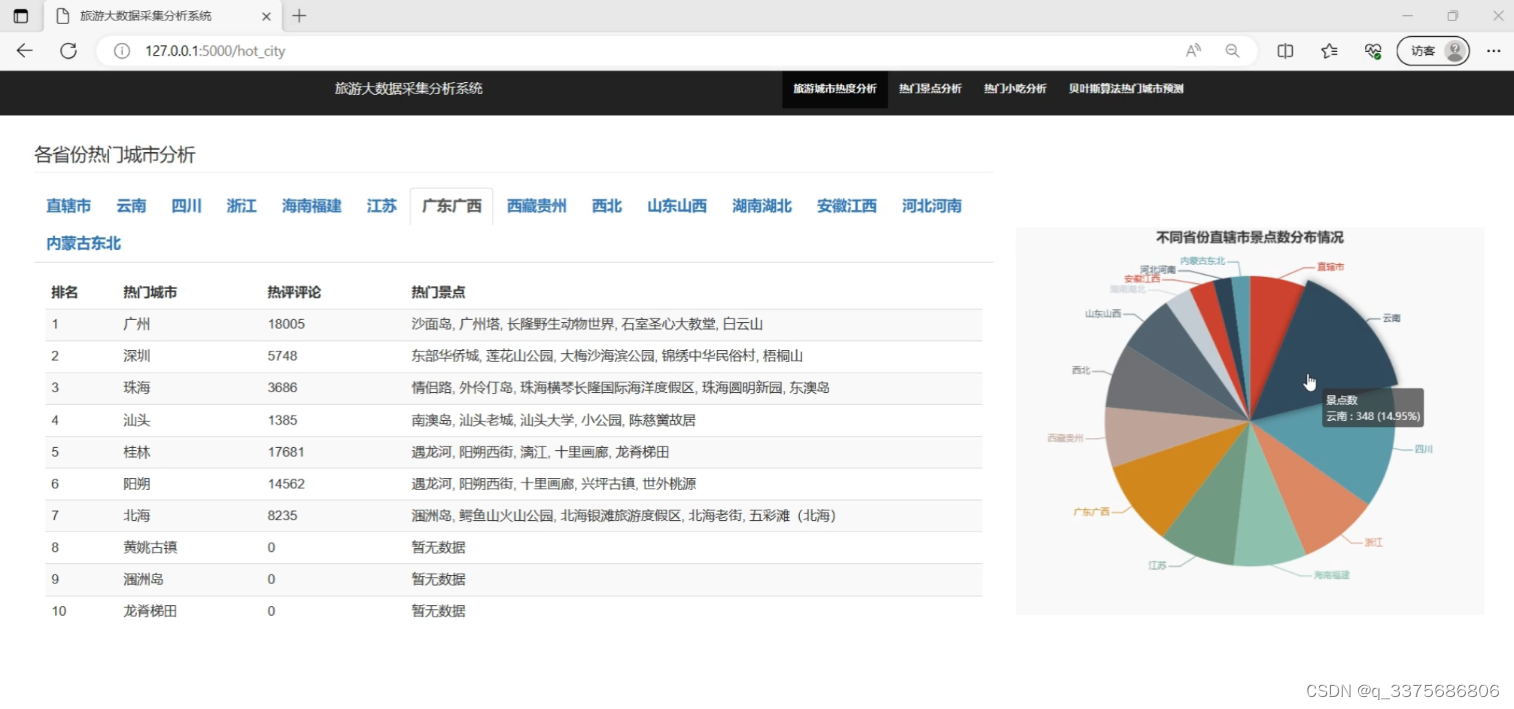
(1)各省份热门城市分析
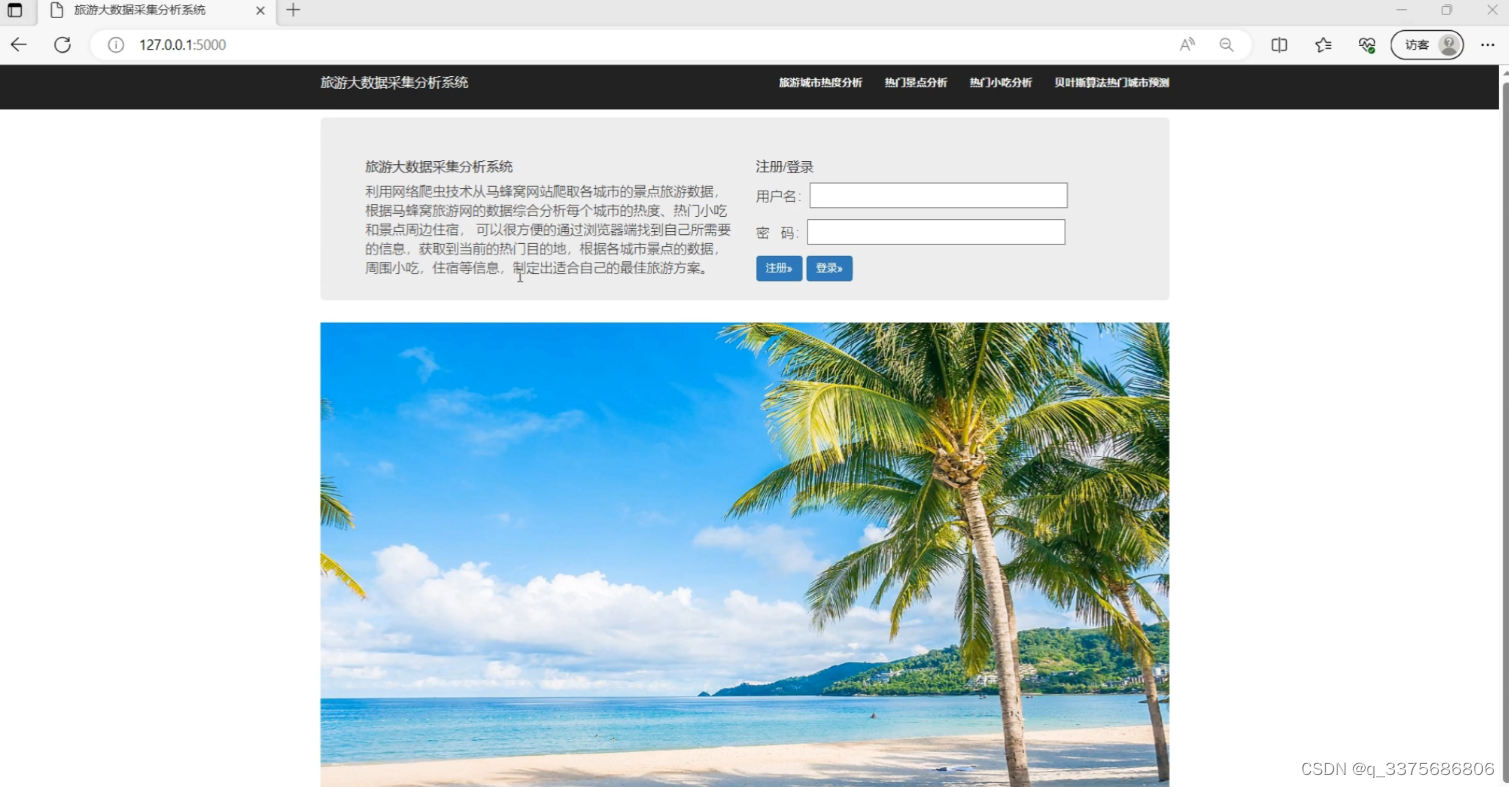
(2)首页–注册登录
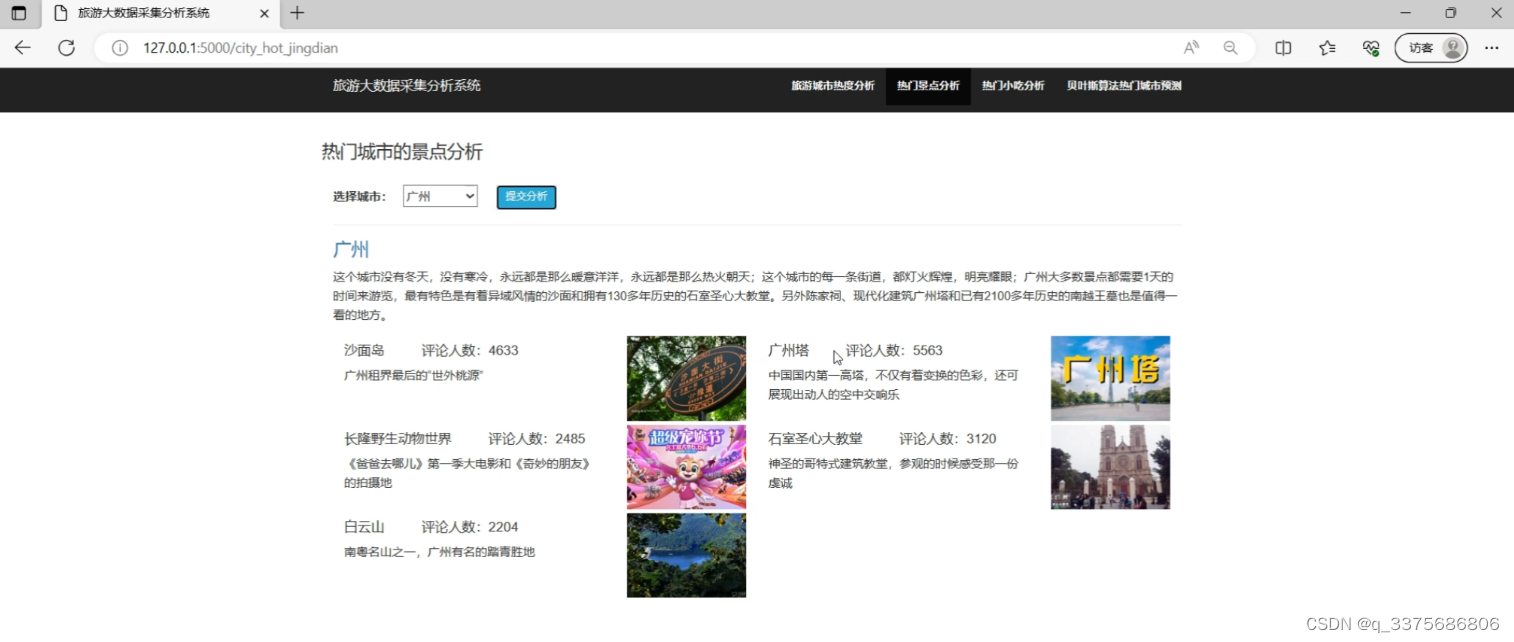
(3)热门城市的景点分析
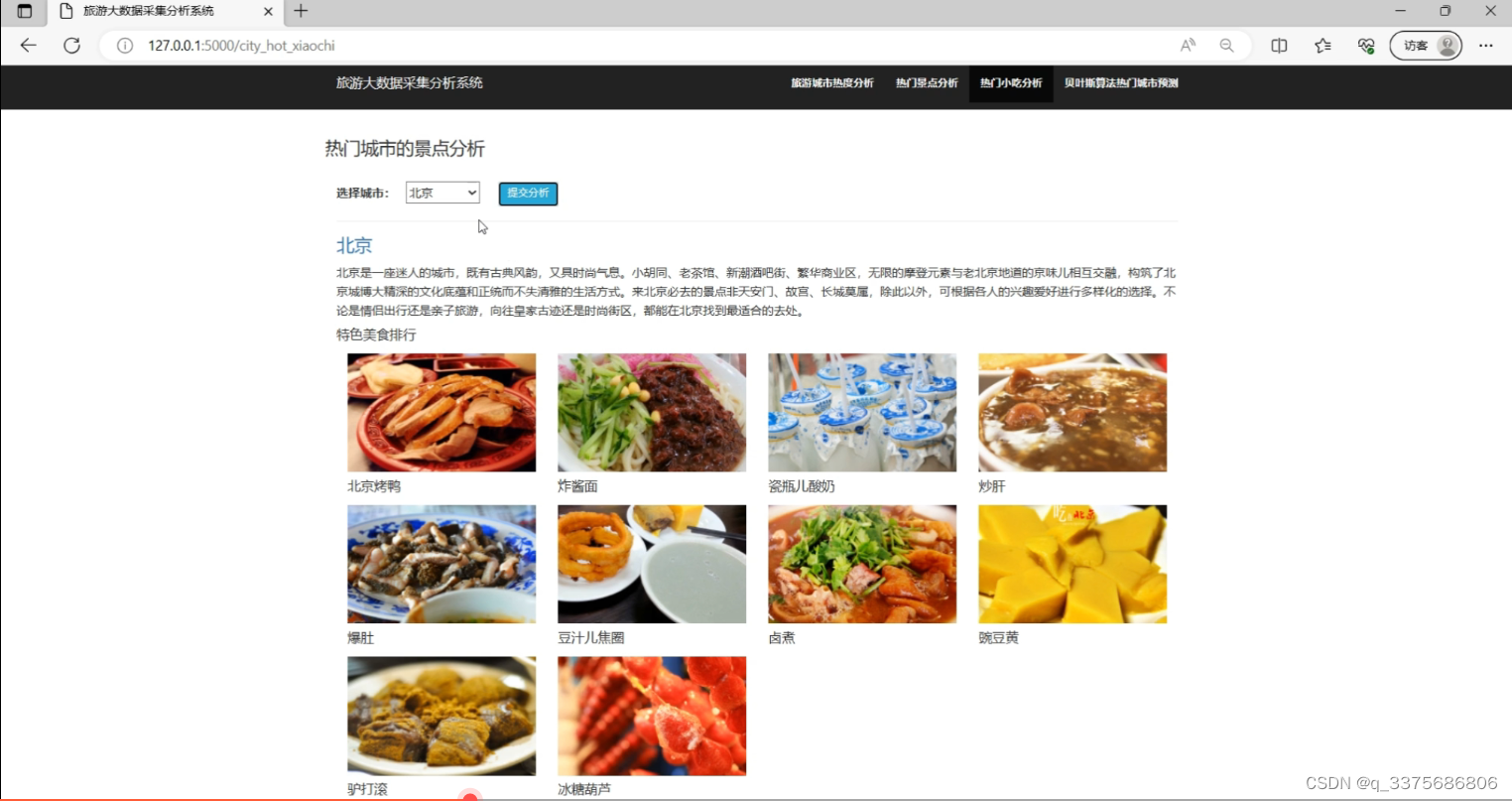
(4)热门城市美食分析
(5)贝叶斯预测模型 (基于贝叶斯网络的热门城市预测模型)
(6)数据爬虫页面
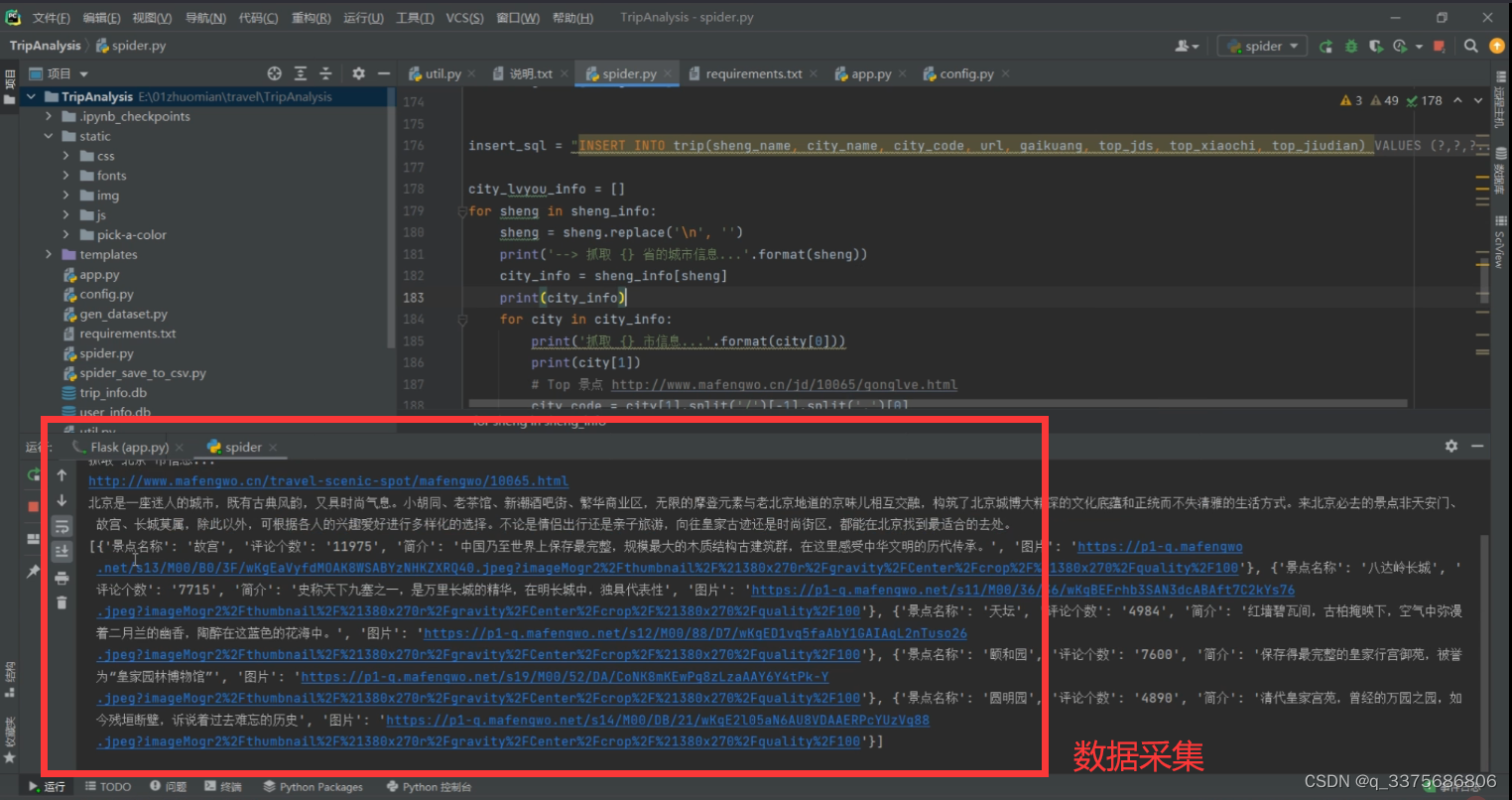
3、项目说明
旅游大数据采集分析系统是基于Flask框架搭建的Web应用程序,主要用于采集、分析和可视化旅游相关的大数据。系统主要包括以下模块:
-
数据采集模块:使用requests爬虫库,通过爬取各种旅游相关网站的数据,包括景点信息、酒店信息、交通信息等,并将数据存储到MySQL数据库中。
-
数据处理模块:使用MySQL数据库进行数据的存储和管理,包括数据清洗、数据整合、数据分析等操作。可以使用贝叶斯预测模型对旅游数据进行预测和分析。
-
数据可视化模块:使用Echarts可视化库,将从数据库中提取的数据进行可视化展示,包括各种统计图表、地图等,以便用户更直观地了解旅游数据。
用户可以通过系统的前端界面,选择需要的数据分析和可视化功能,系统将根据用户的选择,从数据库中提取相应的数据进行处理和展示。用户可以通过系统的搜索功能,查找特定的旅游数据,并进行数据分析和预测,以便做出更好的决策。系统还提供导出数据的功能,用户可以将分析结果导出为Excel或CSV文件,以便进行进一步的分析或报告生成。
通过这个系统,用户可以更方便地获取和分析旅游相关的大数据,从而更好地理解市场需求、优化旅游产品和服务,提升旅游业的发展和竞争力。
4、核心代码
#!/usr/bin/python
# coding=utf-8
import sqlite3
from flask import Flask, render_template, jsonify
import json
from collections import Counter
import pandas as pd
app = Flask(__name__)
app.config.from_object('config')
login_name = None
@app.route('/register/<name>/<password>')
def register(name, password):
conn = sqlite3.connect('user_info.db')
cursor = conn.cursor()
check_sql = "SELECT * FROM sqlite_master where type='table' and name='user'"
cursor.execute(check_sql)
results = cursor.fetchall()
# 数据库表不存在
if len(results) == 0:
# 创建数据库表
sql = """
CREATE TABLE user(
name CHAR(256),
password CHAR(256)
);
"""
cursor.execute(sql)
conn.commit()
print('创建数据库表成功!')
sql = "INSERT INTO user (name, password) VALUES (?,?);"
cursor.executemany(sql, [(name, password)])
conn.commit()
return jsonify({'info': '用户注册成功!', 'status': 'ok'})
@app.route('/login/<name>/<password>')
def login(name, password):
global login_name
conn = sqlite3.connect('user_info.db')
cursor = conn.cursor()
check_sql = "SELECT * FROM sqlite_master where type='table' and name='user'"
cursor.execute(check_sql)
results = cursor.fetchall()
# 数据库表不存在
if len(results) == 0:
# 创建数据库表
sql = """
CREATE TABLE user(
name CHAR(256),
password CHAR(256)
);
"""
cursor.execute(sql)
conn.commit()
print('创建数据库表成功!')
sql = "select * from user where name='{}' and password='{}'".format(name, password)
cursor.execute(sql)
results = cursor.fetchall()
login_name = name
if len(results) > 0:
return jsonify({'info': name + '用户登录成功!', 'status': 'ok'})
else:
return jsonify({'info': '当前用户不存在!', 'status': 'error'})
@app.route('/get_all_sheng')
def get_all_sheng():
"""获取所有省"""
conn = sqlite3.connect('trip_info.db')
cursor = conn.cursor()
sql = 'select sheng_name from trip'
cursor.execute(sql)
results = cursor.fetchall()
results = [r[0] for r in results]
sheng_dict = dict(Counter(results))
sheng = list(sheng_dict.keys())
count = [sheng_dict[s] for s in sheng]
return jsonify({'sheng': sheng, 'count': count})
@app.route('/get_top_city')
def get_top_city():
"""
获取热门城市
"""
conn = sqlite3.connect('trip_info.db')
cursor = conn.cursor()
sql = 'select city_name, top_jds from trip'
cursor.execute(sql)
results = cursor.fetchall()
city_comments = {}
for city, jds in results:
jds = json.loads(jds)
try:
all_comment = sum([int(j['评论个数']) for j in jds])
except:
all_comment = 0
city_comments[city] = all_comment
city_comments = sorted(city_comments.items(), key=lambda d: d[1], reverse=True)
citys = [c[0] for c in city_comments]
return jsonify({'top_city': citys})
@app.route('/query_hot_citys/<sheng>')
def query_hot_citys(sheng):
"""获取省的热门城市"""
conn = sqlite3.connect('trip_info.db')
cursor = conn.cursor()
sql = 'select * from trip where sheng_name="{}"'.format(sheng)
cursor.execute(sql)
results = cursor.fetchall()
city = []
comment = []
jingdian = []
city_jingdian_count = {}
for res in results:
city_name = res[1]
print(city_name)
if city_name in city_jingdian_count:
city_jingdian_count[city_name] = []
jds = json.loads(res[5])
try:
all_comment = sum([int(j['评论个数']) for j in jds])
except:
all_comment = 0
city.append(city_name)
comment.append(all_comment)
try:
jingdian.append(', '.join([j['景点名称'] for j in jds][:5]))
except:
jingdian.append('暂无数据')
# 去重
city_set = []
comment_set = []
jingdian_set = []
for c, com, jd in zip(city, comment, jingdian):
if c in city_set:
continue
city_set.append(c)
comment_set.append(com)
jingdian_set.append(jd)
result = {'city': city_set, 'comment': comment_set, 'jingdian': jingdian_set}
return jsonify(result)
@app.route('/city_jingdian_analysis/<city>')
def city_jingdian_analysis(city):
"""
热门城市的景点分析
"""
conn = sqlite3.connect('trip_info.db')
cursor = conn.cursor()
sql = 'select * from trip where city_name="{}"'.format(city)
cursor.execute(sql)
results = cursor.fetchall()[0]
print(results)
mfw_url = results[3]
gaikuang = results[4]
jds = json.loads(results[5])
xiaochi = json.loads(results[6])
jiudian = json.loads(results[7])
return jsonify({'mfw_url': mfw_url, 'gaikuang': gaikuang, 'jds': jds, 'xiaochi': xiaochi, 'jiudian': jiudian})
# ------------- 训练贝叶斯模型 ---------------
dataset = pd.read_csv('热门城市数据集.csv', encoding='utf8')
from sklearn.naive_bayes import GaussianNB
print('-------贝叶斯模型训练------')
gnb = GaussianNB()
X_train = dataset[['热门景点数量', '热门景点评论的总数', '热门小吃数量']].values
y_train = dataset['标签'].values
gnb.fit(X_train, y_train)
# 贝叶斯网络模型预测
@app.route('/bayes_predict/<hot_jd_count>/<hot_com_count>/<hot_xiaochi_count>')
def bayes_predict(hot_jd_count, hot_com_count, hot_xiaochi_count):
"""
贝叶斯网络模型预测
"""
pred = gnb.predict([[int(hot_jd_count), int(hot_com_count), int(hot_xiaochi_count)]])[0]
print(pred)
result = '热门旅游城市' if pred else '非热门旅游城市'
return jsonify({'result': result})
if __name__ == "__main__":
app.run(host='127.0.0.1')
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻
文章来源:https://blog.csdn.net/q_3375686806/article/details/135397121
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JS常用工具:Webpack 和 JShaman分别有什么用?
- “快速排序”
- 深度学习中的优化方法
- DataFunSummit:2023年数据平台架构峰会-核心PPT资料下载
- 操作系统课设-银行家算法VS2022
- GPT-Pilot:AI开发者的伴侣
- 嵌入式学习第一天
- HBase基础知识(三):HBase架构进阶、读写流程、MemStoreFlush、StoreFile Compaction、Region Split
- springboot中的各种下载文件的方式
- 【100个 Unity实用技能】?? | UGUI中 判断屏幕中某个坐标点的位置是否在指定UI区域内