细粒度语义对齐的视觉语言预训练
抽象
大规模的视觉语言预训练在广泛的下游任务中显示出令人印象深刻的进展。现有方法主要通过图像和文本的全局表示的相似性或对图像和文本特征的高级跨模态关注来模拟跨模态对齐。然而,他们未能明确学习视觉区域和文本短语之间的细粒度语义对齐,因为只有全局图像-文本对齐信息可用。在本文中,我们介绍放大镜![]() ,一个细粒度语义的Ligned visiOn-langUage?PrE?训练框架,从博弈论交互的新视角学习细粒度语义对齐。为了有效地计算博弈论交互作用,我们进一步提出了一种不确定性感知神经Shapley交互学习模块。实验表明,LOUPE在各种视觉语言任务上都达到了最先进的性能。此外,无需任何对象级人工注释和微调,LOUPE 在对象检测和视觉接地方面实现了具有竞争力的性能。更重要的是,LOUPE开辟了一个新的有前途的方向,即从大规模原始图像-文本对中学习细粒度语义。这项工作的存储库位于?https://github.com/YYJMJC/LOUPE。
,一个细粒度语义的Ligned visiOn-langUage?PrE?训练框架,从博弈论交互的新视角学习细粒度语义对齐。为了有效地计算博弈论交互作用,我们进一步提出了一种不确定性感知神经Shapley交互学习模块。实验表明,LOUPE在各种视觉语言任务上都达到了最先进的性能。此外,无需任何对象级人工注释和微调,LOUPE 在对象检测和视觉接地方面实现了具有竞争力的性能。更重要的是,LOUPE开辟了一个新的有前途的方向,即从大规模原始图像-文本对中学习细粒度语义。这项工作的存储库位于?https://github.com/YYJMJC/LOUPE。
1介绍
从大规模视觉语言预训练中学习可转移的跨模态表示,在各种下游任务中表现出卓越的性能。现存作品大多可分为两类:双编码器和融合编码器。双编码器方法JIA2021扩展;?LI2021监督;?拉德福德2021学习;?姚2021菲利普采用两个独立的编码器嵌入图像和文本,并通过图像和文本的全局特征之间的余弦相似度对跨模态对齐进行建模。虽然这种架构通过离线预计算图像和文本表示来有效地进行大规模图像文本检索,但它们无法对视觉区域和文本短语之间的细粒度语义对齐进行建模。另一方面,融合编码器方法陈2020uniter;?金2021维尔特;?LI2021对齐;?LI2020奥斯卡;?LU2019维尔伯特;?QI2020图片伯特;?TAN2019LXMERT;?SU2019VL系列尝试使用单个多模态编码器对图像和文本的串联序列进行联合建模。这些方法通过高级跨模态注意力模拟软对准瓦斯瓦尼2017注意.然而,他们只能通过端到端训练来学习隐式对齐,缺乏明确的监督来鼓励视觉区域和文本短语之间的语义对齐。学习到的跨模态注意力矩阵通常是分散的和无法解释的。此外,它们的检索效率低下,因为它需要在推理过程中对每个图像-文本对进行联合编码。 从图像-文本预训练中学习细粒度语义对齐对于许多跨模态推理任务(例如,视觉基础)至关重要?yu2016建模、图片说明?XU2015展会),但由于视觉区域和文本短语之间的对齐信息不可用,因此它特别具有挑战性,这使得细粒度语义对齐学习成为弱监督学习问题。在本文中,我们解决了这个问题,同时保持了较高的检索效率,提出了放大镜![]() ,从博弈论的新颖视角来看,一个细粒度的语义L ignedvisiOn-langUage?PrE-training?框架。我们将输入的补丁和单词标记表述为多个玩家到一个合作博弈中,并量化博弈论的相互作用(即 Shapley 相互作用??Grabisch1999公理;?Shapley1953值),以调查语义对齐信息。LOUPE从两个阶段学习细粒度语义对齐:标记级Shapley交互建模和语义级Shapley交互建模,我们首先学习识别图像的语义区域,这些语义区域对应于一些语义上有意义的实体,然后将这些区域与配对文本中的短语对齐。
,从博弈论的新颖视角来看,一个细粒度的语义L ignedvisiOn-langUage?PrE-training?框架。我们将输入的补丁和单词标记表述为多个玩家到一个合作博弈中,并量化博弈论的相互作用(即 Shapley 相互作用??Grabisch1999公理;?Shapley1953值),以调查语义对齐信息。LOUPE从两个阶段学习细粒度语义对齐:标记级Shapley交互建模和语义级Shapley交互建模,我们首先学习识别图像的语义区域,这些语义区域对应于一些语义上有意义的实体,然后将这些区域与配对文本中的短语对齐。
具体来说,标记级 Shapley 交互建模旨在将图像的补丁标记分组到语义区域中,这些语义区域在语义上对应于某些视觉实例。从博弈论的角度来看,我们以补丁令牌为玩家,以图像和文本之间的相似度得分为博弈函数。 直观地讲,假设一组补丁标记对应图像中的视觉实例,那么它们往往具有很强的交互性,形成对应实例的完整语义,这有助于更好地判断与配对文本的相似度。 基于这一见解,我们将标记级Shapley交互作为软监督标签,以鼓励模型从图像中捕获语义区域。然后,语义层面的Shapley交互建模推断出语义区域和短语之间的细粒度语义对齐。我们将每个区域和短语视为玩家,并将细粒度的相似度分数定义为游戏函数。如果一个区域和一个短语有很强的对应关系,它们往往会相互作用,并有助于细粒度的相似性分数。通过测量每个区域-短语对之间的Shapley交互作用,我们获得了指导预训练模型的对齐信息。 由于计算精确的Shapley相互作用是一个NP难题松井2001NP,现有方法主要采用基于抽样的方法CASTRO2009多项式以获得无偏的估计。然而,随着玩家数量的增加,他们需要数千个模型评估。为了降低计算成本,我们进一步提出了一种高效的混合Shapley交互学习策略,其中不确定性感知神经Shapley交互学习模块与基于采样的方法协同工作。实验结果表明,该混合策略在保持估计精度的同时,显著节省了计算成本。更多分析见第?4.5?节。
我们的框架用作代理训练目标,明确地在局部区域和短语表示之间建立细粒度的语义对齐。对于下游任务,可以直接删除此代理目标,从而呈现高效且语义敏感的双编码器模型。实验表明,LOUPE在图像文本检索基准上达到了最先进的水平。在MSCOCO上进行文本到图像检索方面,LOUPE在recall@1上比其最强大的竞争对手高出4.2%。此外,无需任何微调,LOUPE就成功地以零样本方式转移到物体检测和视觉接地任务。对于物体检测,它在COCO上实现了12.1%的mAP,在PASCAL VOC上实现了19.5%的mAP。在视觉接地方面,它在 RefCOCO 上实现了 26.8% 的准确度,在 RefCOCO+ 上实现了 23.6% 的准确度。我们的贡献总结如下:
- ??
我们建议放大镜
 这显式地学习了视觉区域和文本短语之间的细粒度语义对齐,同时保留了双编码器的高检索效率。
这显式地学习了视觉区域和文本短语之间的细粒度语义对齐,同时保留了双编码器的高检索效率。 - ??
我们介绍了一种高效且有效的混合Shapley交互学习策略,该策略基于不确定性感知的神经Shapley交互学习模块和基于采样的方法。
- ??
Pre-trained on image-text data, LOUPE achieves new state-of-the-art on image-text retrieval and successfully transfers to the tasks that require more fine-grained object-level visual understanding (i.e., object detection and visual grounding) without any fine-tuning.
- ??
As manual annotations for masses of object categories is time-consuming and unscalable, our work demonstrates a promising alternative, that is, learning fine-grained semantics from raw texts about images, which are easily available and contain a broader set of visual concepts.
2Related Work
Vision-Language Pre-Training.?The great success of pre-train-and-fine-tune paradigm in natural language processing?brown2020language;?devlin2018bert?and computer vision?dosovitskiy2020image;?he2020momentum;?wei2022mvp?has been expanded to the joint domain of vision and language?anderson2018bottom;?antol2015vqa;?li2020unsupervised. Dominant vision-language pre-training models can be categorized into two groups:?dual-encoder?and?fusion-encoder. The dual-encoder methods?jia2021scaling;?li2021supervision;?radford2021learning;?yao2021filip?adopt two individual encoders to embed images and texts separately, and model the cross-modal interaction by cosine similarity. Such architecture is efficient for large-scale image-text retrieval as image and text representations can be pre-computed offline. However, simply measuring the cosine similarity between global representations is shallow to capture fine-grained semantic relationships between regions and phrases. The fusion-encoder methods?chen2020uniter;?huang2021seeing;?huang2020pixel;?kim2021vilt;?li2021align;?li2020unimo;?li2020oscar;?lu2019vilbert;?qi2020imagebert;?su2019vl;?tan2019lxmert;?yu2020ernie;?zhang2021vinvl?adopt a single multi-modal encoder to jointly model the concatenated sequence of images and texts, which achieves deeper cross-modality interaction. However, these methods are less efficient as images and texts are intertwined to compute the cross-modal attention and can not be pre-computed offline. Further, there are no explicit supervision signals to encourage the alignment between regions and phrases. Some works?chen2020uniter;?li2020unimo;?li2020oscar;?lu2019vilbert;?tan2019lxmert;?yu2020ernie;?zhang2021vinvl;?zhong2022regionclip尝试利用现成的对象检测器来提取对象特征以进行预训练。然而,检测器通常在有限的对象类别上进行预训练。 此外,考虑到对内存和计算的过度需求,现有方法通常固定检测模型的参数,并将区域检测视为预处理步骤,与视觉语言预训练脱节。因此,性能也受到检测模型质量的制约。 菲 利 普姚2021菲利普使用标记级最大相似度来增强双编码器方法的跨模态交互。要学习显式细粒度语义对齐,GLIPLI2021停飞和 X-VLM曾2021多利用人工注释的数据集,其中具有边界框注释的区域与文本描述对齐。这种方式非常耗时,并且很难从互联网扩展到更大的原始图像文本数据。 相比之下,我们提出的框架从原始图像-文本数据中显式学习细粒度语义对齐,同时保持了双编码器的高效率。详细讨论可在附录 K.?Shapley Values 中找到。Shapley 价值观Shapley1953值最初是在博弈论中引入的。从理论上讲,它已被证明是公平估计每个玩家在合作博弈中的贡献的独特指标,从而满足某些理想的公理Weber1988概率.凭借坚实的理论基础,Shapley值最近被研究为深度神经网络(DNN)的事后解释方法datta2016算法;?Lundberg2017统一;?张2020口译.Lundberg等人。?Lundberg2017统一提出一种基于Shapley值的统一归因方法来解释DNN的预测。任等人。?REN2021统一建议用Shapley值来解释对抗性攻击。在本文中,我们提出了通过博弈论交互来模拟细粒度语义对齐,以及一种有效的Shapley交互学习策略。
3方法
在本节中,我们首先在第?3.1?节中介绍细粒度语义对齐视觉语言预训练的问题表述。然后,我们在第3.2节中提出了相应的细粒度语义对齐学习的LOUPE框架,并在第3.3节中提出了一种有效的Shapley交互学习方法。
3.1问题表述和模型概述
一般来说,视觉语言预训练旨在学习图像编码器�我和文本编码器�T通过跨模态对比学习,其中匹配的图像-文本对被优化以更接近,不匹配的对被优化以走得更远。让�我(我我)和�T(�我)表示图像和文本的全局表示形式。那么跨模态对比损失可以表述为:
| ?CMC公司=?日志?经验值(�我(我我)?�T(�我)/�))∑��经验值?(�我(我我)?�T(��)/�)?日志?经验值(�我(我我)?�T(�我)/�))∑��经验值(�我(我�)?�T(�我)/�)) | (1) |
哪里�是批大小和�是温度超参数。 虽然很直观,但这种方式只能学习图像和文本之间的粗略对齐,但无法明确捕获视觉区域和文本短语之间的细粒度语义对齐。为了学习细粒度的语义对齐,同时保持高检索效率,我们提出了LOUPE,这是一种从合作博弈论中萌芽的细粒度语义对齐视觉语言预训练框架。 如图?1?所示,LOUPE 从两个阶段学习细粒度语义对齐:标记级 Shapley 交互建模和语义级 Shapley 交互建模。?对于令牌级的Shapley交互建模,我们学习在基于令牌的语义聚合损失的指导下,将图像的补丁标记聚合到语义上对应于某些视觉概念的语义区域?美国运输安全管理局(TSA).在语义层面的Shapley交互建模中,通过细粒度语义对齐损失,学习聚合区域与文本短语之间的语义对齐?FSA公司.结合两个新提出的损失,细粒度语义对齐的视觉语言预训练的完整目标可以表述为:
| ?=?CMC公司+?美国运输安全管理局(TSA)+?FSA公司 | (2) |
这种新的预训练目标强制图像编码器捕获语义区域,并在视觉区域和文本短语之间建立细粒度的语义对齐。在推理过程中,可以直接将其删除,从而呈现出高效且语义敏感的双编码器。
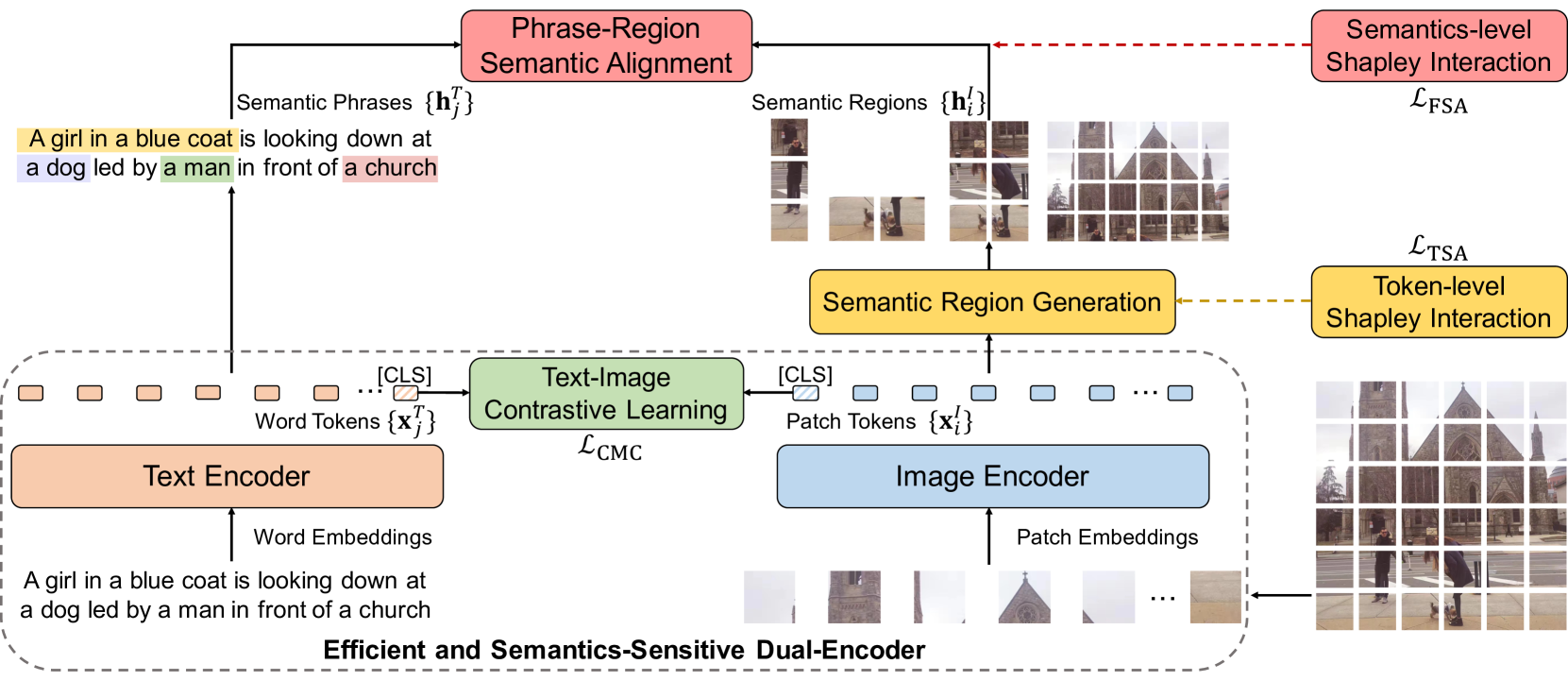
图 1:LUUPE概述。我们的框架作为一个代理训练目标,鼓励图像编码器捕获语义区域,并在区域和短语表示之间建立语义对齐。对于下游任务,可以轻松删除代理训练目标,从而呈现高效且语义敏感的双编码器。
3.2将细粒度语义对齐解释为博弈论交互
3.2.1预赛
Shapley 价值观。Shapley 价值观Shapley1953值是一种经典的博弈论解决方案,用于对合作博弈中每个参与者的重要性或贡献进行公正的估计。考虑一款带有𝒩={1,...,�}球员𝒮?𝒩表示潜在的玩家子集。游戏�(?)作为映射每个子集的函数实现𝒮的玩家得分,当玩家在𝒮参与。具体说来�(𝒩)?�(?)表示游戏中所有玩家获得的贡献。Shapley 价值观�(我|𝒩)对于玩家我定义为玩家的平均边际贡献我所有可能的联盟𝒮在没有我:
| �(我|𝒩)=∑𝒮?𝒩?{我}�(𝒮)[�(𝒮∪{我})?�(𝒮)],�(𝒮)=|𝒮|!(|𝒩|?|𝒮|?1)!|𝒩|! | (3) |
哪里�(𝒮)是𝒮正在采样。Shapley 值已被证明是满足以下公理的唯一指标:线性、对称性、假人和效率?Weber1988概率.我们在附录 B.?Shapley 相互作用中总结了这些公理。在博弈论中,一些玩家倾向于结成联盟,总是一起参与游戏。联盟中的玩家可能会相互互动或合作,这为游戏带来了额外的贡献。Shapley互动Grabisch1999公理与球员单独工作的情况相比,衡量联盟带来的这种额外贡献。对于联盟𝒮,我们考虑[𝒮]作为一个单一的假设玩家,这是玩家的联合𝒮.然后,通过删除𝒮从游戏中添加[𝒮]到游戏中。Shapley 价值观�([𝒮]|𝒩?𝒮∪{[𝒮]})对于玩家[𝒮]可以使用公式?3?在简化博弈中计算。同样,我们可以获得�(我|𝒩?𝒮∪{我})哪里我是个人玩家�.最后,沙普利联盟的互动𝒮配方如下:
| 我([𝒮])=�([𝒮]|𝒩?𝒮∪{[𝒮]})?∑我∈𝒮�(我|𝒩?𝒮∪{我}) | (4) |
这样,我([𝒮])反映内部的互动𝒮.较高的值我([𝒮])表示玩家在𝒮彼此密切合作。
3.2.2代币级 Shapley 交互建模
由于文本和图像之间固有的语义单元不匹配,直接计算单词和像素(补丁)之间的对齐方式是无效的。文本短语通常是指特定的图像区域,该区域由多个色块组成,代表一个视觉实例。因此,我们首先引入令牌级 Shapley 交互建模,将补丁聚合到语义区域。输入表示。给定一个图像-文本对,输入图像我被切成斑块并压平。然后是线性投影层和位置嵌入,我们得到了补丁令牌序列𝒳我={𝐱我我}我=1�1具有额外的令牌嵌入。输入文本[CLS_I]�被标记化并嵌入到单词标记序列中𝒳�={𝐱我�}我=1�2,添加了位置嵌入。我们还在单词标记序列中预置了一个可学习的特殊标记。然后,采用双编码器结构分别对patch token序列和word token序列进行编码。在图像和文本编码器之上,我们获得了补丁令牌序列的表示[CLS_T]𝒳~我={𝐱~我我}我=1�~1和单词标记序列𝒳~�={𝐱~我�}我=1�~2.我们将学习到的表示和标记作为图像和文本的全局表示。图像-文本对的全局相似性是通过它们之间的余弦相似度来衡量的。[CLS_I][CLS_T]
通过Shapley交互理解语义区域。假设一组斑块代表了图像中一个完整的视觉实例,那么它们往往具有很强的Shapley相互作用,因为它们共同作用形成一个视觉实例,这有助于更好地判断与文本的相似性。从博弈论的角度来看,我们以补丁标记和单词标记作为玩家𝒳=𝒳我∪𝒳�,以及图像和文本之间的全局相似性作为游戏分数�1(?).计算�1(𝒮),我们将令牌保存在𝒮并屏蔽输入标记𝒳?𝒮到零。因此,全局相似性仅考虑𝒮,这反映了代币的贡献𝒮到全局相似性判断。
语义区域生成。受?YOLOv3?启发?2018YOLOv3,我们设计了一个轻量级的区域生成模块。它采用每个补丁令牌表示形式𝐱~我我作为输入并生成以𝐱~我我,对应于视觉区域?我={𝐱我,�我}�=1�我跟�我补丁令牌。区域生成模块还可以预测置信度分数�(?我)对于每个区域。我们选择顶部�预测作为语义区域。然后,Shapley的相互作用?我可以定义为:
| 我([?我])=�([?我]|�??我∪{[?我]})?∑𝐱我,�我∈?我�(𝐱我,�我|𝒳??我∪{𝐱我,�我}) | (5) |
根据等式?3,我们可以将 Shapley 值重新表述为期望的形式:
| �([?我]|𝒳??我∪{[?我]})=𝔼�{𝔼𝒮?𝒳??我|𝒮|=�[�1(𝒮∪?我)?�1(𝒮)]} | (6) |
哪里�代表联盟规模。�(𝐱我,�我|�??我∪{𝐱我,�我})可以用类似的方式定义,并且?我可以重新表述为(我们在附录 C 中提供证明):
| 我([?我])=𝔼�{𝔼𝒮?𝒳??我|𝒮|=�[�1(𝒮∪?我)?∑𝐱我,�我∈?我�1(𝒮∪{𝐱我,�我})+(�?1)�1(𝒮)]} | (7) |
服用归一化我′([�我])作为软监督标签,基于令牌的语义聚合损失被定义为交叉熵损失:
| ?美国运输安全管理局(TSA)=?1�∑我=1�[我′([?我])日志?(�(?我))+(1?我′([?我]))日志?(1?�(?我))] | (8) |
它将梯度传播到区域生成模块和图像编码器,以调整边界框预测,从而捕获更准确的语义区域。
3.2.3语义级 Shapley 交互建模
在获得推断的语义区域后,我们提出了语义层面的Shapley交互建模,以显式地模拟区域和短语之间的细粒度语义对齐。我们首先定义细粒度相似度得分,然后基于博弈论解释语义对齐。 我们在每个Avg-Pooling?我获取区域表示形式𝐡我我∈?�.我们使用现成的选区解析器从文本中提取短语并获得短语表示𝐡我�∈?�由。总的来说,我们获得了Avg-Pooling�地区?我={𝐡我我}我=1�和�短语?�={𝐡��}�=1�.对齐矩阵可以定义为:一个=[一个我�]�×�哪里一个我�=𝐡我我?𝐡��表示我-th region 和�-th短语。接下来,我们将 softmax-normalization 应用于一个获得一个~.对于我-th 区域,我们将其最大对齐分数计算为麦克斯�?一个~我�.然后,我们使用所有区域的平均最大对齐分数作为细粒度图像与文本的相似度�1.同样,我们可以获得细粒度的文本与图像的相似度�2,并且可以定义总的细粒度相似度分数:�=(�1+�2)/2.通过Shapley交互理解语义对齐。如果一个区域和一个短语具有很强的语义对应关系,那么它们往往会相互合作,并有助于细粒度的相似性分数。因此,我们可以考虑?=?我∪?�作为玩家和细粒度相似度得分�作为游戏得分�2(?).它们的Shapley相互作用可以表述为:
| 我([?我�]) | =�([?我�]|???我�∪{[?我�]})?�(𝐡我我|???我�∪{𝐡我我})?�(𝐡��|???我�∪{𝐡��}) | (9) | ||
| =𝔼�{𝔼𝒮????我�|𝒮|=�[�2(𝒮∪?我�)?�2(𝒮∪{𝐡我我})?�2(𝒮∪{𝐡��})+�2(𝒮)]} | (10) |
哪里[?我�]代表由联盟组成的单一玩家我-th region 和�-th短语。服用归一化我′([?我�])作为软标签,细粒度语义对齐损失可以定义为:
| ?FSA公司=?1��∑我=1�∑�=1�我′([?我�])日志?(一个~我�) | (11) |
3.3不确定性感知神经Shapley交互学习
根据等式?3?和等式?4,精确计算 Shapley 值是一个 NP 难题松井2001NP.以前的方法主要采用基于抽样的方法CASTRO2009多项式来近似它。虽然基于抽样的近似是无偏的,但准确的近似需要数千次模型评估。为了降低计算成本,我们提出了一种不确定性感知神经Shapley交互学习(UNSIL)模块,与基于采样的方法配合,提供了一种高效且有效的混合策略。 具体来说,基于抽样的方法CASTRO2009多项式通过抽样来估计等式?7?和等式?10?中的期望项,以计算 Shapley 相互作用。灵感来自嘈杂的标签学习Kendall2017不确定性,联塞综合行动模块学习预测Shapley相互作用和相应的不确定性�∈(0,1).直观地说,如果联塞综合活动模块做出的预测不确定性较低,我们可以直接将其预测应用于?美国运输安全管理局(TSA)和?FSA公司,避免了数千次模型评估。如果不确定性很高,我们就会采用基于抽样的方法进行更准确的估计。 在训练期间,联塞综合活动模块首先预测具有不确定性的目标相互作用�.然后,我们对一个值进行采样�从均匀分布(0,1).如果�>�,我们直接使用它的预测。如果�≤�,然后我们使用基于抽样的方法计算Shapley相互作用,并根据基于抽样的结果更新UNSIL模块。请注意,在前几次迭代中,我们直接采用基于采样的方法,并使用其结果来训练 UNSIL 模块。
让我*和我^分别表示基于抽样的方法和联塞综合体模块的结果。采取我*作为基本事实,联塞综合活动模块由以下人员训练:
| ?联塞综合会议=1�1�?MSE的(我^,我*)+�2� | (12) |
其中第一项是均方误差?MSE的根据不确定性加权,第二项作为预测不确定性的正则化项,并且�是权重超参数。联塞综合行动模块隐式地从回归损失函数中学习不确定性。我们在第?4.5?节和附录 D 中讨论了联塞综合会议模块的实施细节。
4实验
4.1训练前详情
由于足够的数据是视觉语言预训练的先决条件,我们构建了一个来自互联网的 240M 图像文本对的数据集。我们通过 Swin-L 实现图像编码器刘2021Swin以及 BERT-Small 的文本编码器德夫林2018伯特.输入图像的大小调整为224×224输入文本由 WordPiece 标记化,最大长度为 60。我们在 128 个 NVIDIA V100 GPU 上使用 512 个批处理大小对模型预训练了 20 个 epoch。我们利用 AdamWLoshchilov2017解耦学习率为2×10?4权重衰减为0.01。附录 D、E 中提供了更多培训前和评估详细信息。我们还在附录 G、J 中分析了图像编码器和训练效率。
表 1:Flickr30K 和 MSCOCO 数据集上零样本图像文本检索的结果 (%)。
| Flickr30K的 | MSCOCO公司 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 图像到文本 | 文本到图像 | 图像到文本 | 文本到图像 | |||||||||
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| 图像BERT | 70.7 | 90.2 | 94.0 | 54.3 | 79.6 | 87.5 | 44.0 | 71.2 | 80.4 | 32.3 | 59.0 | 70.2 |
| 统一 | 83.6 | 95.7 | 97.7 | 68.7 | 89.2 | 93.9 | - | - | - | - | - | - |
| 夹 | 88.0 | 98.7 | 99.4 | 68.7 | 90.6 | 95.2 | 58.4 | 81.5 | 88.1 | 37.8 | 62.4 | 72.2 |
| 對齊 | 88.6 | 98.7 | 99.7 | 75.7 | 93.8 | 96.8 | 58.6 | 83.0 | 89.7 | 45.6 | 69.8 | 78.6 |
| 菲 利 普 | 89.8 | 99.2 | 99.8 | 75.0 | 93.4 | 96.3 | 61.3 | 84.3 | 90.4 | 45.9 | 70.6 | 79.3 |
| 放大镜 | 90.5 | 99.5 | 99.8 | 76.3 | 93.9 | 96.7 | 62.3 | 85.1 | 91.2 | 50.1 | 75.4 | 83.3 |
表2:在 11 个数据集上零样本图像分类的 Top-1 准确率 (%)。
|
CIFAR10 |
食物101 |
斯坦福汽车 |
孙氏397 |
鲜花102 |
国家211 |
FER2013 |
飞机 |
牛津宠物 |
加州理工学院101 |
图像网 |
平均 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 夹 | 96.2 | 92.9 | 77.3 | 67.7 | 78.7 | 34.9 | 57.7 | 36.1 | 93.5 | 92.6 | 75.3 | 73.0 |
| 放大镜 | 95.9 | 94.3 | 79.9 | 69.8 | 87.4 | 37.8 | 53.3 | 54.9 | 94.1 | 93.9 | 76.1 | 76.1 |
4.2零样本图像文本检索
我们比较了广泛使用的 MSCOCO 上的 LOUPELIN2014微软和 Flickr30Kplummer2015flickr30k数据。首先,表?1?中的结果表明,LOUPE 在两个数据集的大多数指标上都实现了最先进的零样本性能,证明了我们的预训练框架具有更强的泛化性。其次,虽然以前的工作主要在较大的数据集(CLIP 400M、ALIGN 1800M、FILIP 340M)上进行预训练,但 LOUPE 仍然使用更少的训练数据 (240M) 实现了卓越的性能。第三,与直接计算标记相似度的FILIP相比,我们的模型捕获了视觉区域和文本短语之间的语义对齐,这在语义上更具意义。对于MSCOCO上的文本到图像检索,LOUPE在recall@1上的表现明显优于FILIP4.2%。
4.3零样本图像分类
在本节中,我们将评估零样本图像分类任务的 LOUPE。我们在 11 个下游分类数据集上比较了 LOUPE 和 CLIP,遵循与 CLIP 相同的评估设置拉德福德2021学习.结果如表2所示。如表2所示,我们的LOUPE优于CLIP,平均改善3.1%。值得注意的是,在 11 个数据集中最大的数据集 ImageNet 上,我们的 LOUPE 比 CLIP 高出 0.8%。此外,我们观察到 LOUPE 在几个细粒度图像分类数据集(即 Flowers102 和 Aircrafts)上实现了显着的性能提升。它证明了我们的LOUPE在细粒度语义理解方面的优越性。 我们还评估了LOUPE在图像分类上的线性探测性能。详细结果见附录I。
表 3:无需微调,物体检测和视觉接地的零样本传输性能。
| 可可 | 帕斯卡挥发性有机化合物 | RefCOCO公司 | RefCOCO+系列 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| mAP@0.3 | mAP@0.5 | mAP@0.3 | mAP@0.5 | 瓦尔 | 种皮 | 测试B | 瓦尔 | 种皮 | 测试B | |
| CLIP + 像素 | 8.5 | 4.5 | 18.2 | 7.3 | 6.7 | 6.2 | 5.8 | 6.1 | 7.0 | 5.7 |
| CLIP + K-均值 | 6.4 | 1.9 | 11.7 | 4.8 | 2.1 | 2.3 | 1.7 | 1.7 | 2.0 | 2.8 |
| CLIP + 渐变凸轮 | 7.1 | 3.2 | 19.1 | 8.2 | 5.5 | 5.2 | 4.8 | 4.4 | 5.6 | 4.9 |
| 适应夹 | 14.9 | 6.6 | 28.7 | 12.9 | 16.7 | 18.4 | 18.0 | 17.5 | 18.9 | 19.6 |
| 放大镜 | 25.3 | 12.1 | 30.3 | 19.5 | 25.2 | 26.8 | 24.5 | 22.9 | 23.3 | 23.6 |
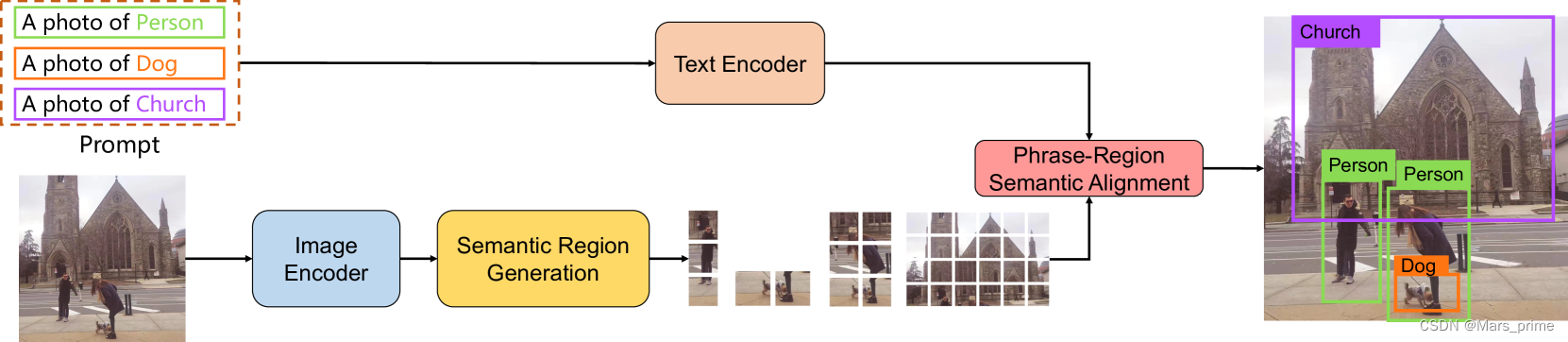
图 2:使用提示模板将 LOUPE 零样本传输到对象检测的示例。
4.4零样本传输至物体检测和视觉接地
为了回答我们的模型是否学习了细粒度语义,我们进一步评估了对象检测的 LOUPEREN2015更快和视觉接地yu2016建模,这需要更细粒度的语义理解能力,根据对象标签或指称表达式识别图像中的特定视觉区域。 视觉基础可以看作是广义的对象检测,其中预定义的类标签被引用表达式句子的语言所取代。由于 LOUPE 可以生成一组与文本短语对齐的语义区域,因此它可以轻松应用于对象检测和视觉基础,而无需修改结构。为了视觉基础,我们将引用表达式作为输入文本。对于对象检测,如图?2?所示,我们使用 prompt 将检测标签展开为输入文本。然后,我们通过学习到的文本编码器对输入文本进行编码,通过测量候选区域表示和文本表示之间的相似性来完成这些任务。 为了进行比较,我们通过在CLIP的空间特征图上应用几种非参数方法,将CLIP(ViT-L/14)零样本转移到目标检测和视觉接地。我们还与 AdaptCLIP 进行了比较LI2022适应,这是一种同时未发布的方法,它利用了经典的超级像素(SLIC阿昌塔2012SLIC) 和边界框建议(选择性搜索UIJLINGS2013选择性) 方法将 CLIP 转换为短语本地化。我们使用其公开的官方实现来获得实验结果。对于目标检测,我们在 IoU 阈值{0.3,0.5}在COCO上LIN2014微软(65 级)和 PASCAL VOC埃弗林厄姆2008帕斯卡(20节课)。对于视觉基础,我们在 RefCOCO 上评估了它们在 IoU 阈值为 0.5 时的前 1 精度yu2016建模和 RefCOCO+yu2016建模.CLIP变体和LOUPE的实验细节见附录E。 表?3?总结了结果。1)?总体而言,LOUPE 的性能大大优于所有 CLIP 变体。显著更高的性能说明了我们细粒度语义对齐的预训练范式更强的零样本迁移能力。2)其次,所有CLIP变体都依赖于CLIP特征图上的预处理步骤(例如,AdaptCLIP首先使用SLIC对像素进行分组,然后使用选择性搜索生成大量提案),这非常耗时。相比之下,我们的方法基于补丁标记表示直接预测语义区域。3)第三,在四个基准测试中始终如一的竞争性能验证了LOUPE可以从原始文本监督中学习细粒度语义。LOUPE展示了一种很有前途的替代方案,即从大规模的原始图像文本对中学习细粒度的语义,这些文本对很容易获得,并且包含更广泛的视觉概念集。 由于耗时的人工注释对于现实世界中的大量对象类是不可扩展的,因此最近的一些工作班萨尔2018零;?拉赫曼2020改进目标是训练对象检测器,对基本对象类进行注释,以泛化到同一数据集的其余对象类。最新作品GU2021开放;?Zareian2021开放利用视觉语言预训练模型的泛化性,进一步提高新类的零样本性能。然而,这些零样本方法仍然需要对基类进行边界框注释,以实现特定于任务的监督学习。相比之下,我们的 LOUPE 是在大规模原始图像文本对上训练的,这些图像文本对已经可以在互联网上访问并包含更多样化的语义。
表 4:在三项任务中对每个组件进行消融研究。
| MSCOCO公司 | 可可 | RefCOCO公司 | 培训时间 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| H25型 | T2I型 | mAP@0.3 | mAP@0.5 | 瓦尔 | 种皮 | 测试B | (秒/iter) | ||
| 1 | 骨干 | 31.0 | 24.8 | 3.8 | 1.0 | 1.3 | 0.9 | 0.8 | 1.17 |
| 2 | 骨干网 +?美国运输安全管理局(TSA) | 32.4 | 26.2 | 7.6 | 3.3 | 1.8 | 2.0 | 2.6 | 8.38 |
| 3 | 骨干网 +?美国运输安全管理局(TSA)?+??FSA公司 | 33.5 | 28.3 | 9.4 | 5.9 | 4.1 | 4.6 | 4.3 | 9.90 |
| 4 | 骨干网 +?美国运输安全管理局(TSA)?+??FSA公司+ 联塞综合行动 | 33.3 | 28.1 | 9.0 | 5.6 | 4.5 | 4.9 | 4.4 | 1.93 |
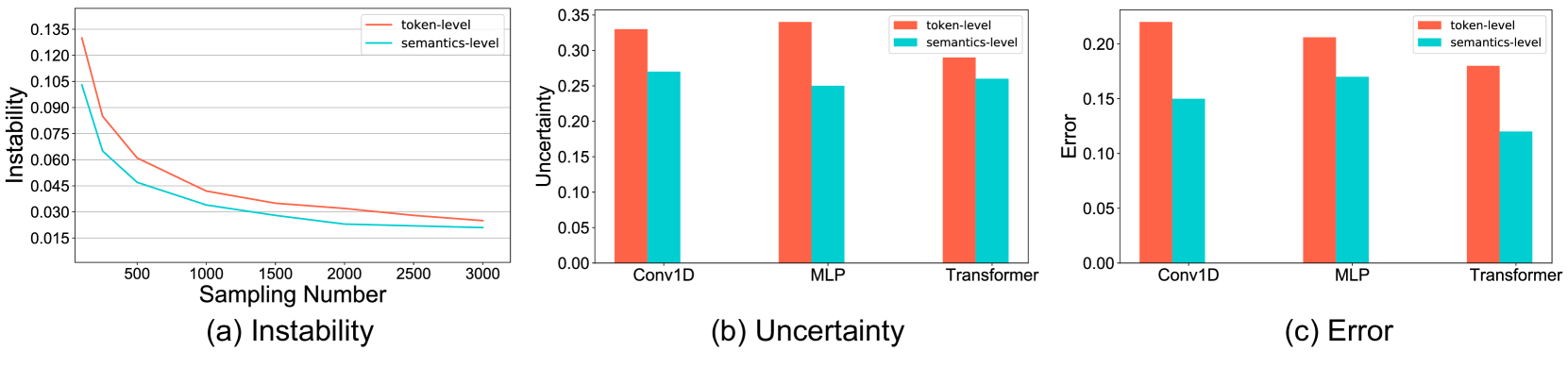
图3:(a) Shapley相互作用近似值相对于不同采样数的不稳定性。(b、c)具有不同结构的联塞综合体模块的不确定性和误差。
4.5消融研究
单个组件的有效性。在本节中,我们研究了表?4?中每个组件的有效性。鉴于昂贵的训练时间,所有消融研究都基于相对较小的数据集(概念性标题 3M2018概念).我们从骨干模型开始,该模型由一个由跨模态对比损失训练的双编码器组成。然后,我们逐步添加令牌级 Shapley 交互建模监督?美国运输安全管理局(TSA)(第 2 行),语义级 Shapley 交互建模监督?FSA公司(第 3 行)和联塞综合体模块(第 4 行)。对于第 2 行和第 3 行,Shapley 相互作用仅通过基于采样的方法计算。表?4?中的结果表明,两者?美国运输安全管理局(TSA)和?FSA公司为所有任务带来显着改进。我们观察到?美国运输安全管理局(TSA)将对象检测提高 3.8%。改进的细粒度视觉语义理解进一步促进了跨模态检索性能(+1.4%)。语义级 Shapley 交互建模通过对视觉区域和文本短语之间的语义对齐进行建模,进一步提高了所有任务的性能。比较第 3 行和第 4 行,我们观察到 UNSIL 模块在避免密集计算的同时保持了估计精度。平均训练时间从每次迭代 9.90 秒减少到每次迭代 1.93 秒。Shapley 交互学习的准确性。由于我们使用基于抽样的方法CASTRO2009多项式为了计算Shapley相互作用并训练UNSIL模块,我们进行了一项研究,以评估基于采样的方法的准确性和UNSIL模块的误差。如张2020口译,我们多次计算相互作用并测量它们的不稳定性。较低的不稳定性意味着我们从不同的采样过程中获得相似的相互作用。它表示高精度。具体来说,不稳定性定义为𝔼�,�:�≠�|我�?我�|𝔼�|我�|哪里我�表示在�-第 1 次。我们对 100 个图像-文本对的 Shapley 交互作用的不稳定性值求平均值。我们报告了不同采样数的平均不稳定性值。如图3(a)所示,不稳定性随着采样次数的增加而减小。当采样数大于500时,近似Shapley相互作用足够稳定,不稳定性小于0.06。此外,我们尝试了不同的模型(即 Conv1D、3 层 MLP + Attention、3 层 Transformer)来实现 UNSIL 模块(详情请参阅附录 D)。我们在 1000 个样本上测试了它们,并在图?3?(b) 和 (c) 中报告了它们的平均不确定性和相对误差。 我们观察到?MLP + 注意力足以以较低的复杂性预测交互。因此,我们通过MLP + Attention来实现UNSIL模块。

图 4:在COCO上进行物体检测和在RefCOCO+上进行视觉接地的定性示例。

图5:学习到的细粒度语义对齐和相应的Shapley交互值的可视化。红色框中的值表示区域的 Shapley 交互。
4.6定性分析
定性例子。如图?4?所示,LOUPE 成功捕获了与检测到的物体相对应的区域,并将参照表达式接地到参照区域上。学习的细粒度语义对齐的可视化。在图?5?中,我们可视化了 LOUPE 推断的一些关键语义区域和相应的对齐矩阵。我们呈现置信度前 3 个区域(区域 1 – 3)和两个随机抽样区域(白框)。边界框底部的红色框表示其归一化的令牌级 Shapley 交互值。通过比较它们的Shapley交互值,我们观察到标记级Shapley交互成功地将语义区域与随机采样区域区分开来。语义上有意义的区域往往具有更强的相互作用。这表明令牌级Shapley交互可以为语义区域生成提供正确的监督。此外,我们分别展示了由语义级Shapley交互和LOUPE推断的对齐矩阵。如图?5?的右图所示,LOUPE 成功识别了皮带区域![]() ,并将其与“皮带”短语对齐。请注意,现有对象检测数据集不包含“leash”类别。
,并将其与“皮带”短语对齐。请注意,现有对象检测数据集不包含“leash”类别。
5结论
本文介绍了一种新颖的视觉语言预训练框架,放大镜![]() ,它通过博弈论交互对视觉区域和文本短语之间的细粒度语义对齐进行建模。为了有效地计算交互作用,我们进一步提出了一种不确定性感知的神经Shapley交互学习模块。综合实验表明,LOUPE在图像-文本检索数据集上实现了最先进的技术,并且可以以零样本方式转移到目标检测和视觉基础。这项工作展示了从大规模原始图像文本数据中学习细粒度语义的新方向。局限性。1) 这些短语由现成的选区解析器提取,其预测可能并不完全准确。2)网络数据可能不可避免地包含不匹配的图文对,导致嘈杂的监督。社会影响。我们的模型是根据来自互联网的嘈杂数据进行训练的,这些数据可能包含不合适的图像、暴力文本或私人信息。因此,有必要对数据进行额外的分析。此外,应禁止将我们的模型用于隐私监控或其他恶意目的。确认。这项工作得到了国家重点研发计划(2018AAA0101900)、浙江省国家科学基金(LR21F020004)、浙江省重点研发计划(编号:2021C01013)、中国工程科学与技术知识中心(CKCEST)的部分支持。我们感谢所有审稿人的宝贵意见。
,它通过博弈论交互对视觉区域和文本短语之间的细粒度语义对齐进行建模。为了有效地计算交互作用,我们进一步提出了一种不确定性感知的神经Shapley交互学习模块。综合实验表明,LOUPE在图像-文本检索数据集上实现了最先进的技术,并且可以以零样本方式转移到目标检测和视觉基础。这项工作展示了从大规模原始图像文本数据中学习细粒度语义的新方向。局限性。1) 这些短语由现成的选区解析器提取,其预测可能并不完全准确。2)网络数据可能不可避免地包含不匹配的图文对,导致嘈杂的监督。社会影响。我们的模型是根据来自互联网的嘈杂数据进行训练的,这些数据可能包含不合适的图像、暴力文本或私人信息。因此,有必要对数据进行额外的分析。此外,应禁止将我们的模型用于隐私监控或其他恶意目的。确认。这项工作得到了国家重点研发计划(2018AAA0101900)、浙江省国家科学基金(LR21F020004)、浙江省重点研发计划(编号:2021C01013)、中国工程科学与技术知识中心(CKCEST)的部分支持。我们感谢所有审稿人的宝贵意见。
附录A附录概述
在本附录中,我们将介绍:
附录BShapley 值的公理化性质
在本节中,我们主要介绍Shapley值的公理化性质。Weber等人。?Weber1988概率已经证明Shapley值是满足以下公理的唯一指标:线性、对称性、假人和效率。线性公理。如果两个独立的游戏�和�可以线性合并到一个游戏中�(𝒮)=�(𝒮)+�(𝒮),然后是每个球员的 Shapley 值我∈𝒩在新游戏中�是玩家的 Shapley 值的总和我在游戏中�和�,可表述为:
| ��(我|𝒩)=��(我|𝒩)+��(我|𝒩) | (13) |
对称公理。考虑两名球员我和�在游戏中�,如果满足以下条件:
| ?𝒮∈𝒩?{我,�},�(𝒮∪{我})=�(𝒮∪{�}) | (14) |
然后��(我|𝒩)=��(�|𝒩).虚拟公理。虚拟玩家被定义为与其他玩家没有互动的玩家。正式地,如果一个球员我在游戏中�满足:
| ?𝒮∈𝒩?{我},�(𝒮∪{我})=�(𝒮)+�({我}) | (15) |
则此播放器被定义为虚拟播放器。这样,虚拟播放器我与其他玩家没有互动,即?�({我})=��(我|𝒩).效率公理。效率公理确保可以将整体奖励分配给所有玩家,可以表述为:
| ∑我∈𝒩��(我)=�(𝒩)?�(?) | (16) |
附录C等式 7 和等式 10 的证明
在本节中,我们提供了第 3.2.2 节中的公式 7 和第 3.2.3 节中的公式 10 的详细证明。 我们首先为等式 7 提供证明。令牌级 Shapley 交互?我可分解如下:
| 我([?我]) | =�([?我]|�??我∪{[?我]})?∑𝐱我,�我∈?我�(𝐱我,�我|𝒳??我∪{𝐱我,�我}) | (17) | ||
| =𝔼�{𝔼𝒮?𝒳??我|𝒮|=�[�1(𝒮∪?我)?�1(𝒮)]}?∑𝐱我,�我∈?我𝔼�{𝔼𝒮?𝒳??我|𝒮|=�[�1(𝒮∪{𝐱我,�我})?�1(𝒮)]} | (18) | |||
| =𝔼�{𝔼𝒮?𝒳??我|𝒮|=�[�1(𝒮∪?我)?�1(𝒮)]}?𝔼�{𝔼𝒮?𝒳??我|𝒮|=�[∑𝐱我,�我∈?我(�1(𝒮∪{𝐱我,�我})?�1(𝒮))]} | (19) | |||
| =𝔼�{𝔼𝒮?𝒳??我|𝒮|=�[�1(𝒮∪?我)?�1(𝒮)?∑𝐱我,�我∈?我(�1(𝒮∪{𝐱我,�我})?�1(𝒮))]} | (20) | |||
| =𝔼�{𝔼𝒮?𝒳??我|𝒮|=�[�1(𝒮∪?我)?�1(𝒮)?∑𝐱我,�我∈?我�1(𝒮∪{𝐱我,�我})+∑𝐱我,�我∈?我�1(𝒮)]} | (21) | |||
| =𝔼�{𝔼𝒮?𝒳??我|𝒮|=�[�1(𝒮∪?我)?∑𝐱我,�我∈?我�1(𝒮∪{𝐱我,�我})+(�?1)�1(𝒮)]} | (22) |
然后,我们为等式 10 提供证明。区域间的语义级Shapley交互我和短语�可分解如下:
| 我([?我�]) | =�([?我�]|???我�∪{[?我�]})?�(𝐡我我|???我�∪{𝐡我我})?�(𝐡��|???我�∪{𝐡��}) | (23) | ||
| =𝔼�{𝔼𝒮????我�|𝒮|=�[�2(𝒮∪?我�)?�2(𝒮)]}?𝔼�{𝔼𝒮????我�|𝒮|=�[�2(𝒮∪{𝐡我我})?�2(𝒮)]} | (24) | |||
| ?𝔼�{𝔼𝒮????我�|𝒮|=�[�2(𝒮∪{𝐡��})?�2(𝒮)]} | (25) | |||
| =𝔼�{𝔼𝒮????我�|𝒮|=�[�2(𝒮∪?我�)?�2(𝒮∪{𝐡我我})?�2(𝒮∪{𝐡��})+�2(𝒮)]} | (26) |
表 5:LOUPE 中各种超参数的摘要。
| 超参数 | 价值 |
| 图像编码器 - Swin-L | |
| 输入图像大小 | 224×224 |
| \hdashline阶段 1 - 修补程序大小 | 4×4 |
| 第 1 阶段 - 隐藏大小 | 192 |
| 第 1 阶段 - 窗口大小 | 7×7 |
| 第 1 阶段 - 头数 | 6 |
| \HDashLine阶段 2 - 修补程序大小 | 8×8 |
| 第 2 阶段 - 隐藏尺寸 | 384 |
| 第 2 阶段 - 窗口大小 | 7×7 |
| 第 2 阶段 - 磁头数量 | 12 |
| \hdashline阶段 3 - 修补程序大小 | 16×16 |
| 第 3 阶段 - 隐藏尺寸 | 768 |
| 第 3 阶段 - 窗口大小 | 7×7 |
| 第 3 阶段 - 头数 | 24 |
| \hdashline阶段 4 - 修补程序大小 | 32×32 |
| 第 4 阶段 - 隐藏尺寸 | 1536 |
| 第 4 阶段 - 窗口大小 | 7×7 |
| 第 4 阶段 - 头数 | 48 |
| 文本编码器 - BERT-Small | |
| 字标记的最大长度 | 60 |
| 词汇量 | 30522 |
| 注意力辍学概率 | 0.1 |
| 隐藏激活功能 | GELU的 |
| 隐藏的辍学概率 | 0.1 |
| 初始值设定项范围 | 0.02 |
| 中间尺寸 | 2048 |
| 层数 EPS | 1�?12 |
| 隐藏尺寸 | 512 |
| 注意头数量 | 8 |
| 隐藏层数 | 4 |
| 预培训 | |
| 纪元数 | 20 |
| 批量大小 | 512 |
| 学习率 | 2E-4型 |
| 学习时间表 | OneCycle |
| 周期动量 | 图雷 |
| 基础动量 | 0.85 |
| 最大动量 | 0.95 |
| AdamW 权重衰减 | 0.01 |
| 亚当�1 | 0.9 |
| 亚当�2 | 0.999 |
附录D超参数和实现细节
在本节中,我们总结了表?5?中 LOUPE 模型中的超参数,包括图像编码器、文本编码器和预训练过程的超参数。对于不确定性感知神经Shapley交互学习模块,我们尝试了三种模型(即Conv1D、3层MLP+注意力、3层Transformer)来实现令牌级和语义级Shapley交互逼近。 对于令牌级 Shapley 交互近似,它采用补丁令牌序列𝒳我={𝐱我我}我=1�1、 字标记序列𝒳�={𝐱我�}我=1�2和视觉区域?我={𝐱我,�我}�=1�我作为输入,并估计相应的令牌级 Shapley 交互值?我伴随着不确定性�.Conv1D?模型首先对学习到的补丁表示执行Avg-Pooling?我获取区域表示形式𝐡我我,然后将 word 和 patch 标记表示形式与区域表示形式融合𝐡我我分别。具体来说,我们通过全连接层将它们投射到一个统一的语义空间中,然后通过Hadamard积将它们融合为:
| ?我=(𝒲1𝐡我我1�)⊙(𝒲2𝒳我) | (27) |
哪里𝒲1和𝒲2是可学习的投影参数,1�是全一向量的转置,并且⊙代表 Hadamard 产品。我们可以获得?�以类似的方式。然后,我们应用核大小 = 4 且步幅 = 2 的 1D 卷积运算?我和?�分别。在操作之后,我们得到Max-Pooling𝐟~我∈?�和𝐟~�∈?�.接下来,我们将它们与𝐡我我并将它们馈送到两个单独的 1 层全连接层,以获得 Shapley 相互作用估计和相应的不确定性。3 层 MLP + 注意力模型首先对学习到的补丁表示执行Avg-Pooling?我获取区域表示形式𝐡我我.然后,我们使用𝐡我我作为查询,以参与修补程序令牌序列并计算修补程序令牌表示形式的加权总和,如下所示:
| �~�我= | 𝒲3(�一个�?(𝒲4𝐡我我+𝒲5𝐱�我)) | (28) | ||
| �我= | �����一个�([�~1我,...,�~�1我]) | (29) | ||
| 𝐞我= | ∑�=1�我我𝐱�我 | (30) |
哪里�1是修补程序令牌的数量。我们可以获得𝐞�对于单词标记序列,以类似的方式。因此,我们将它们连接起来,并𝐡我我并将它们馈送到两个独立的 3 层全连接层,以获得 Shapley 相互作用估计和相应的不确定性。3 层 Transformer?模型采用级联序列𝒳我和𝒳�作为输入。我们向它们添加位置嵌入和三种标记类型嵌入(即单词标记、上下文补丁标记、区域补丁标记)。然后,我们应用三层 transformer 模块来联合编码输入序列,并分别采用输出标记来预测 Shapley 相互作用估计和相应的不确定性。 对于语义层面的 Shapley 交互近似,它需要[CLS]�地区?我={𝐡我我}我=1�,�短语?�={𝐡��}�=1�和目标区域-短语对<𝐡我我,𝐡��>作为输入,并估计相应的语义级 Shapley 交互值<𝐡我我,𝐡��>伴随着不确定性�.这三个模型的体系结构与其令牌级实现一致。
附录E培训前和评估详情
E.1预训练数据集详细信息
作为最近的作品JIA2021扩展;?拉德福德2021学习;?姚2021菲利普研究表明,预训练模型可以通过扩展数据集来获得巨大的性能提升,我们构建了一个大规模数据集,该数据集由 2.4 亿个图像文本对组成,涵盖了广泛的视觉概念。具体而言,我们将在下面详细阐述更多细节。原始图像-文本对集合。我们首先从网络中获取大规模的有噪图像文本对,并设计多种过滤规则来提高网络数据的质量。基于图像的过滤。关注 ALIGNJIA2021扩展,我们会删除色情图片,并仅保留两个尺寸均大于 200 像素的图片。此外,我们删除纵横比大于 10 的图像。为了防止测试数据泄露,我们删除了所有下游评估数据集(例如,MSCOCO、Flickr30K)中出现的图像。基于文本的筛选。我们删除了重复的标题,只保留英文文本。少于 3 个单词或长度超过 100 个单词的文本将被丢弃。作为 ALIGNJIA2021扩展,我们还会从原始数据集中删除包含任何稀有标记的文本(除了 1 亿个最常见的一元组和二元组之外)。图像文本联合过滤。尽管上述过滤规则已经过滤掉了许多噪声数据,但很难检测到不匹配的图文对,即文本不能准确描述图像的视觉内容,从而导致视觉语言预训练产生不良的噪声信号。灵感来自BLIPLI2022BLIP,我们将判别器训练为过滤模型,以预测文本是否与图像匹配。具体而言,滤波模型由图像编码器和基于图像的文本编码器组成,该编码器将交叉注意力用于融合图像特征和文本特征。使用图像-文本对比损失和图像-文本匹配损失在 CC12M 数据集上训练过滤模型。
E.2评估详细信息
零镜头图像文本检索。我们评估了 LOUPE 在广泛使用的 Flickr30K 上对图像文本检索任务的零样本性能plummer2015flickr30k和 MSCOCOLIN2014微软数据。图像-文本检索由两个子任务组成:图像到文本检索和文本到图像检索,其中需要模型从给定描述其内容的标题的候选图像中识别图像,反之亦然。MSCOCO 数据集由 123,287 张图像组成,每张图像与五个标题对齐。Flickr30K 数据集包含 31,783 张图像和每张图像的五个标题。继之前的作品之后JIA2021扩展;?姚2021菲利普,我们分别评估了 Flickr30K 和 MSCOCO 的 1K 和 5K 测试集的零样本性能。我们将标记的最终表示作为图像和文本的全局表示,并使用它们来衡量图像-文本的相似度。我们首先计算所有图像文本对的相似性分数。然后,我们选择前 K 名候选人进行排名,并报告前 K 名的检索结果。零样本传输到物体检测。在没有任何微调的情况下,我们评估了LOUPE在目标检测任务上的零样本传输性能[CLS]REN2015更快在COCO上空LIN2014微软和 PASCAL VOC埃弗林厄姆2008帕斯卡数据。对于 COCO Objects 数据集,我们使用其 2017 年的验证拆分进行评估。以前的零样本目标检测模型班萨尔2018零;?拉赫曼2020改进;?ZHU2020唐遵循班萨尔2018零,由 48 个基类和 17 个小说类组成。他们在基类上训练模型,并在新类上评估模型。不同的是,我们直接评估基类和新类的零样本传输性能,而无需对基类进行微调。总的来说,我们在 4,836 张测试图像上评估模型,这些图像包含 65 个类别的 33,152 个实例。PASCAL VOC 是一个广泛使用的目标检测数据集,它包含 20 个目标类。对于 PASCAL VOC,我们在 5072 张图像的 9657 个实例上评估模型。为了完成目标检测,我们首先使用区域生成模块生成一组候选区域,然后使用提示文本(即 [object class name] 的图像)将每个检测标签扩展为一个句子。接下来,我们通过学习到的文本编码器对每个对象类的句子进行编码,并测量它们与候选区域的相似性作为分类分数。在大多数零样本目标检测方法中,我们使用 IoU{0.3,0.5}作为评估指标。零样本转移到视觉接地。视觉接地yu2016建模(也称为短语本地化和指称表达理解)旨在根据语言指称表达式定位输入图像的特定视觉区域。视觉基础可以看作是广义的对象检测,其中预定义的类标签被引用表达式句子的语言所取代。在没有任何微调的情况下,我们评估了 LOUPE 在 RefCOCO 上的视觉接地任务中的零样本传输性能yu2016建模和 RefCOCO+yu2016建模数据。这两个数据集由 ReferitGame 收集Kazemzadeh2014参考游戏,其中要求玩家编写语言表达式来引用图像中的特定对象,并要求另一个玩家在给定图像和引用表达式的情况下找到目标对象。RefCOCO数据集由19,994张图像中50,000个对象的142,209个引用表达式组成,分为train(120,624个表达式),val(10,834个表达式),testA(5,657个表达式),testB(5,095个表达式)集。testA 集中的图像涉及多个人,testB 集中的图像涉及多个对象。RefCOCO+ 数据集由 19,992 张图像中 49,856 个对象的 141,564 个表达式组成,分为 train(120,191 个表达式)、val(10,758 个表达式)、testA(5,726 个表达式)、testB(4,889 个表达式)集。我们报告了两个数据集的 val、testA 和 testB 集的零样本传输性能。
表 6:COCO“Karpathy”测试拆分的图片说明评估结果。
| 图像说明 | ||||
| BLEU@4 | 流星 | 苹果酒 | 香料 | |
| VLP(VLP)周2020统一 | 36.5 | 28.4 | 117.7 | 21.3 |
| 奥斯卡大?LI2020奥斯卡 | 37.4 | 30.7 | 127.8 | 23.5 |
| VinVL系列大?张2021VINVL | 38.5 | 30.4 | 130.8 | 23.4 |
| 昙花一现硅1?L?LI2022BLIP | 40.4 | - | 136.7 | - |
| 柠檬大?HU2021扩展 | 40.6 | 30.4 | 135.7 | 23.5 |
| 放大镜 | 40.9 | 31.5 | 137.8 | 24.3 |
附录F视觉语言生成任务的更多实验结果
为了进一步验证我们的LOUPE学习到的跨模态表示的泛化能力,我们将预训练的LOUPE适应视觉语言生成任务,即图像描述。安德森2018底部.图像描述是用自然语言描述图像的任务,这需要模型来识别和描述图像的细粒度语义。输入图像由学习到的图像编码器进行编码。饰演 BLIPLI2022BLIP,我们训练了一个基于图像的文本解码器,该解码器与学习到的文本编码器共享前馈层,并采用交叉注意力来关注图像特征。文本解码器使用语言建模损失进行训练,以根据图像生成字幕。 我们评估了 MSCOCO 上的图像字幕性能LIN2014微软数据集,分为训练(113,287 张图像)、val(5,000 张图像)、“Karpathy”测试拆分(5,000 张图像)。每张图片有 5 个标题。我们使用训练拆分来训练基于图像的文本解码器,并在公共“Karpath”5k 测试拆分上报告性能。遵循标准指标,我们使用 BLEU@4、METEOR、CIDEr 和 SPICE 作为评估指标。我们将LOUPE模型与最近的视觉语言预训练生成模型进行了比较HU2021扩展;?LI2022BLIP;?LI2020奥斯卡;?张2021VINVL;?周2020统一.所有方法都仅使用交叉熵损失进行微调,而不进行 CIDEr 优化。如表6所示,我们的LOUPE在所有指标上都取得了有竞争力的性能,这验证了我们的模型在下游视觉语言生成任务上的强大泛化能力。
表 7:关于不同图像编码器的进一步消融结果(R@1)。
| 图像编码器 | Flickr30K的 | MSCOCO公司 | |||
|---|---|---|---|---|---|
| 图像到文本 | 文本到图像 | 图像到文本 | 文本到图像 | ||
| 1對齊?JIA2021扩展 | 高效网 | 88.6 | 75.7 | 58.6 | 45.6 |
| 2菲 利 普?姚2021菲利普 | 维生素L-L | 89.8 | 75.0 | 61.3 | 45.9 |
| 3夹?拉德福德2021学习 | 维生素L-L | 88.0 | 68.7 | 58.4 | 37.8 |
| 4夹* | 斯温-L | 88.7 | 74.3 | 59.3 | 46.2 |
| 5?卢佩 | 斯温-L | 90.5 | 76.3 | 62.3 | 50.1 |
附录G对图像编码器的进一步分析
在我们的工作中,我们采用 Swin-L刘2021Swin作为我们的图像编码器,由于以下考虑。(1)Swin Transformer的移位窗口方案实现了图像尺寸的线性计算复杂度,比ViT更有效Dosovitskiy2020图片.这个优点对视觉语言预训练特别有益,因为我们需要处理大规模图像(240M)。(2)Swin Transformer的分层架构更灵活,可以对不同尺度的语义区域进行建模。 为了进一步验证我们提出的细粒度语义对齐视觉语言预训练框架的性能提升,我们实现了夹采用 Swin-L 作为图像编码器(表?7?中的第 4 行),使用与我们的 LOUPE 相同的训练数据集。它也可以被看作是我们LUOPE的骨干(没有从我们的令牌级和语义级Shapley交互建模中进行优化)。如表7所示,比较夹*跟夹,Swin-L 图像编码器确实带来了一些改进夹.但是,两者之间仍然存在明显的性能差距夹*和我们的 LOUPE。在相同的架构下,我们的 LOUPE 的平均R@1比夹*超过两个数据集。这进一步验证了主要的性能提升来自我们提出的细粒度语义对齐的视觉语言预训练框架。值得注意的是,我们观察到,我们实现的文本到图像检索明显高于夹.这种现象也得到了以下方面的证实:JIA2021扩展;?姚2021菲利普(参见表?7?中的第 1 行和第 2 行)。我们假设它可能是由一些训练细节或数据集集合引起的夹.
附录H有关物体检测和视觉接地的更多定性示例
为了更直观地了解我们的模型在物体检测和视觉接地方面的性能,我们可视化了更多的定性示例。具体而言,图?6?和图?7?显示了 COCO 上的更多目标检测示例LIN2014微软和 PASCAL VOC埃弗林厄姆2008帕斯卡数据。图?8?和图?9?显示了 RefCOCO 上的更多可视化接地示例yu2016建模和 RefCOCO+yu2016建模数据。
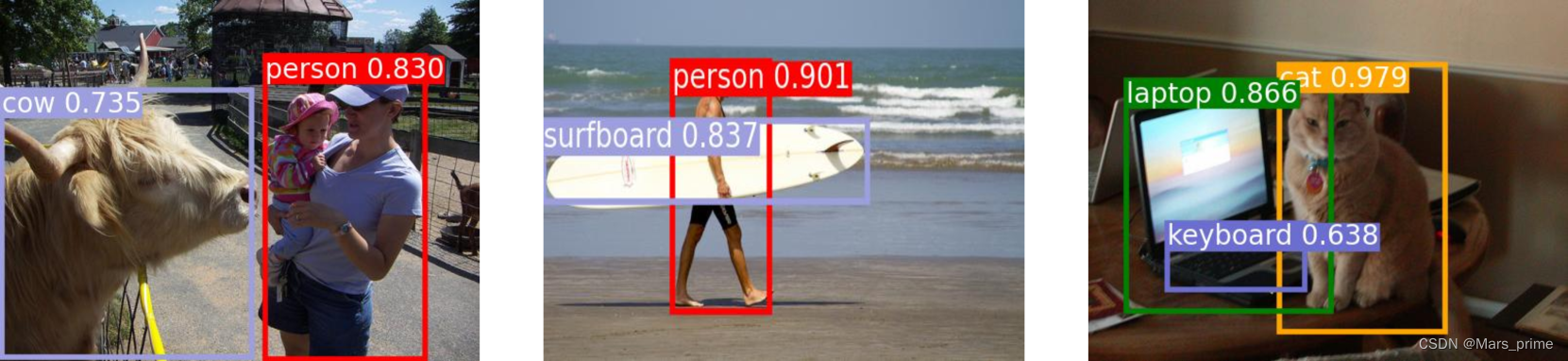
图 6:COCO Objects 数据集上对象检测的定性示例。

图 7:PASCAL VOC数据集上目标检测的定性示例。

图 8:RefCOCO数据集上视觉基础的定性示例。

图 9:RefCOCO+数据集上视觉基础的定性示例。
附录一线性探测评估
在本节中,我们评估了LOUPE在图像分类上的线性探测性能。遵循与 CLIP 相同的评估设置拉德福德2021学习,我们冻结了整个骨干网络,只微调了最后一个线性分类层,该层将令牌作为输入。我们在表?8?中报告了 11 个数据集的线性探测性能。我们的 LOUPE 优于 CLIP,平均改善 1.6%。值得注意的是,在 11 个数据集中最大的数据集 ImageNet 上,我们的 LOUPE 比 CLIP 高出 1.8%。[CLS]
表 8:对 11 个数据集的线性探测性能(前 1 精度)。
|
CIFAR10 |
食物101 |
斯坦福汽车 |
孙氏397 |
鲜花102 |
国家211 |
FER2013 |
飞机 |
牛津宠物 |
加州理工学院101 |
图像网 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 夹 | 98.0 | 95.2 | 90.9 | 81.8 | 99.2 | 46.4 | 72.9 | 69.4 | 95.1 | 96.5 | 83.9 |
| 放大镜 | 97.6 | 96.0 | 92.1 | 82.6 | 99.5 | 49.3 | 70.7 | 80.2 | 95.5 | 97.5 | 85.7 |
表 9:训练成本和架构参数的比较。
| 预训练图像-文本对 | 参数 | GPU | 日 | GPU 天数 | |
|---|---|---|---|---|---|
| 夹 | 400米 | 425 米 | 奔驰256 V100 | 12天 | 3072 |
| 對齊 | 1800米 | 820米 | 1024 TPUv3 | - | - |
| 菲 利 普 | 340米 | 417米 | 192 V100型 | 24天 | 4608 |
| 放大镜 | 240米 | 226 米 | 128 V100 | 20天 | 2560 |
附录J培训效率讨论
尽管我们提出的Shapley交互建模增加了每次迭代的训练时间,但它通过鼓励我们的模型学习细粒度的区域短语对齐,而不是粗略的图像-文本对齐,使我们的模型能够以更少的总迭代收敛。如表?9?所示,我们的 LOUPE 在使用相对较少的 GPU 天数(128 个 GPU)时实现了最佳性能×20 天)。 事实上,所提出的Shapley交互建模增加了每次迭代的训练时间,但它使我们的模型能够从原始图像-文本对中学习细粒度的区域-短语对齐,而无需任何对象级的人工注释。我们的 LOUPE 可以用作零样本物体检测器,无需任何微调。与人工注释的昂贵成本相比,增加的训练时间可能是可以接受的。同时,在现实世界中对极其多样化的对象类别进行手动注释是不可扩展的,甚至是不可能的,而我们的模型展示了一个有前途的替代方案,即从有关图像的原始文本中学习细粒度的语义,这些文本很容易获得并包含更广泛的视觉概念。例如,正文中图 4 的正确情况表明,LOUPE 成功识别了皮带区域,并将其与“皮带”短语对齐。请注意,“皮带”类别从未出现在任何现有的对象检测数据集中。 另一方面,我们的方法比依赖现成的物体检测器(例如,Faster R-CNN)提取视觉特征的方法要有效得多。近期研究金2021维尔特;?姚2021菲利普已经注意到,使用对象检测器提取视觉特征会大大减慢训练速度(每个 GPU 约 20 FPS),并且需要更多的 GPU 内存。因此,我们的模型避免了如此沉重的负担,同时能够在没有任何预训练检测器或人工注释的情况下识别语义丰富的视觉区域。
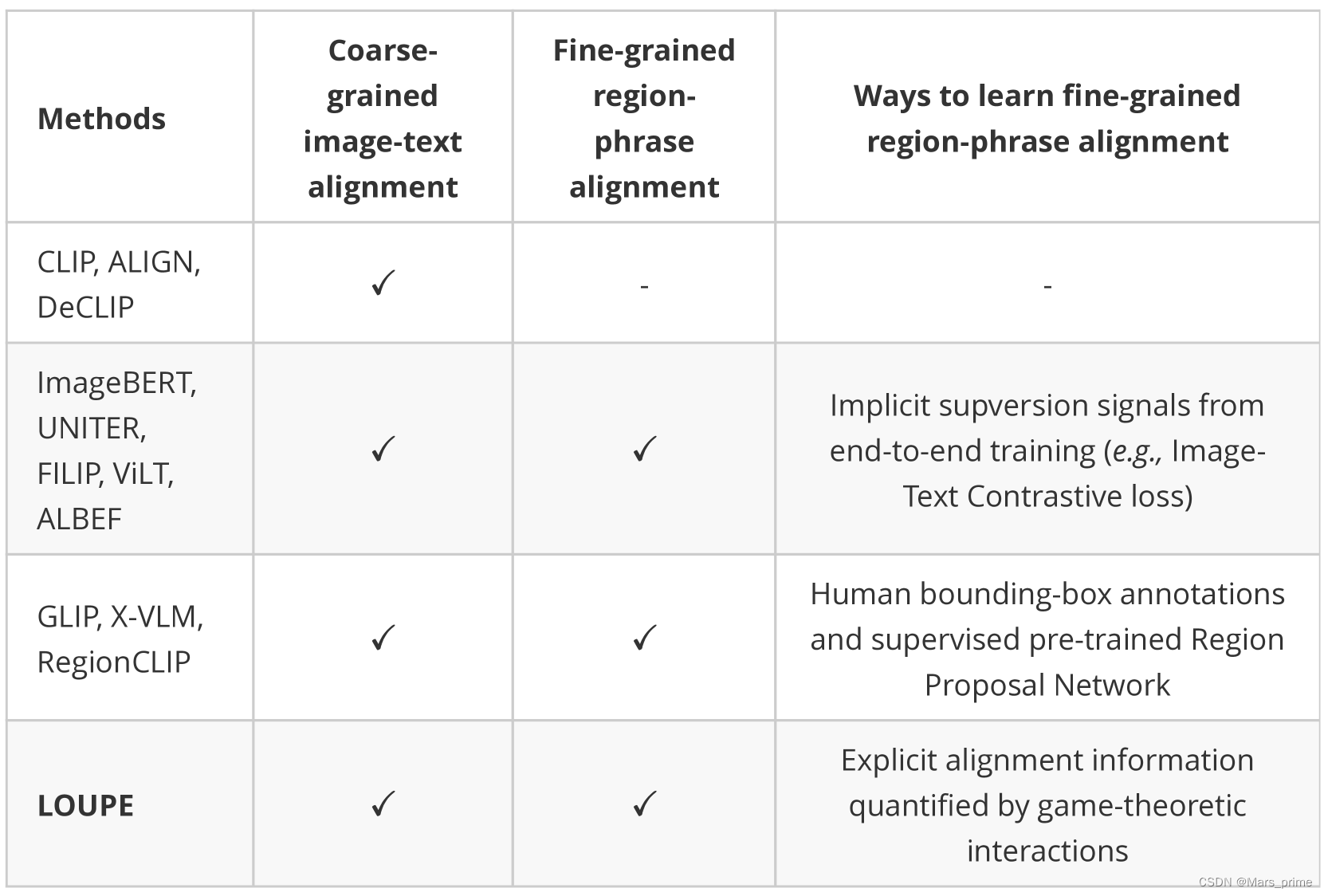
图 10:LOUPE与现有方法的比较。
附录K与一些相关作品的详细讨论
在本节中,我们首先提供比较表,以突出我们的 LOUPE 与各种方法的主要区别。然后,我们详细讨论了三部近期作品(即?FILIP姚2021菲利普、区域CLIP钟2022区域剪辑、X-VLM系列曾2021多),这也研究了细粒度语义对齐。 我们在图?10?中重点介绍了主要区别。我们的 LOUPE 不同之处在于,它从博弈论交互的新角度显式学习细粒度的区域短语对齐,而无需诉诸任何对象级人工注释和预训练的区域建议网络 (RPN)。值得注意的是,人类边界框注解通常仅限于预定义的对象类别,并且 RPN 只能检测属于预训练目标检测数据集的预定义类别的区域。因此,使用人工边界框注释或预训练 RPN 的方法通常会受到检测预定义类别之外的新对象的影响,而 LOUPE 则从大规模原始图像文本对中学习,这些图像文本对更具可扩展性并包含更广泛的视觉概念集。 与FILIP相比,使用Shapley交互建模的优势主要有三点:1)我们假设直接计算每个补丁标记和单词令牌之间的标记对齐是没有效率和有意义的,因为单个单词标记或补丁标记可能不包含完整的语义。语义丰富的短语(例如,“一个穿蓝色外套的女孩”)通常由多个单词组成,其对应的视觉区域由多个补丁组成。此外,一些单词(例如,“是”、“the”)和补丁(例如,背景像素)没有意义。基于这一见解,我们的 LOUPE 有所不同,因为我们首先提出了标记级 Shapley 交互建模,将补丁聚合到语义有意义的区域,然后引入语义级 Shapley 交互建模来显式建模语义有意义的区域和短语之间的细粒度语义对齐。2)尽管FILIP通过计算标记相似度来模拟细粒度对齐,但它只能从图像-文本对比损失的监督中学习隐式对齐,缺乏训练信号来明确鼓励视觉区域和文本短语之间的语义对齐。相比之下,我们的 Shapley 交互建模提供了显式的监督信号(例如,图 4 中可视化的对齐矩阵)来学习细粒度对齐。我们的 LOUPE 在所有指标上始终优于 FILIP,这也证明了显式细粒度对齐学习的好处。3)FILIP不能通过隐式标记对齐学习直接应用于目标检测和视觉接地,而我们的LOUPE可以立即转移到这些任务中,而无需任何微调。这是因为所提出的Shapley交互建模使我们的模型能够识别语义区域并将这些区域与语言对齐。如表 2 所示,在没有任何边界框注释和微调的情况下,我们的 LOUPE 在四个目标检测和视觉接地基准测试中实现了具有竞争力的性能。 我们的 LOUPE 与 RegionCLIP 在以下几个方面不同:1) RegionCLIP 使用预先训练的区域建议网络 (RPN)?来检测图像中的区域。然而,RPN 通常是在预定义的对象类别(例如,MSCOCO 的 80 个类)上进行预训练的,这无法涵盖大规模预训练数据集中广泛的对象类别。此外,由于 RPN 对内存和计算量的需求过高,现有方法(即 RegionCLIP)通常会固定 RPN 的参数,并将区域检测视为预处理步骤,与视觉语言预训练断开连接。因此,RegionCLIP 的性能也受到 RPN 质量的限制。相比之下,我们的 LOUPE 通过标记级 Shapley 交互建模来学习识别图像的语义区域,这更具可扩展性,使我们的 LOUPE 能够从大规模预训练数据集中学习更广泛的视觉概念。2)RegionCLIP从图像文本语料库中构建了一个对象概念池,并将视觉区域与这些概念对齐。这些概念通常是单个名词(例如,boy、风筝、公共汽车)。相比之下,我们的 LOUPE 侧重于涉及丰富上下文的短语(例如,“一个在草地上奔跑的男孩”)。通过将视觉区域与包含丰富语义上下文的短语对齐,我们的 LOUPE 可以从大规模预训练数据集中学习一组视觉概念(例如,对象、动作、关系)。 至于 X-VLM,主要区别在于三个方面:1)?X-VLM 是在注释良好的数据集上训练的,其中提供了带有边界框注释的区域,并且每个区域都与描述文本相关联。这种方式非常耗时,并且很难从网络扩展到更大的原始图像文本数据。我们的 LOUPE 不同,因为我们是在 Internet 上接受嘈杂的图像文本对的训练。2)X-VLM以地面实况区域为输入,并经过训练,以预测由地面实况坐标上的回归损失监督的边界框。相比之下,我们的 LOUPE 在没有来自人类注释的如此强烈的监督信号的情况下学习识别图像的语义区域。3)X-VLM具有区域与对应描述文本之间的真值对齐信息,为区域文本匹配提供了较强的监督信号。相比之下,我们的 LOUPE 从博弈论交互中学习细粒度的区域短语对齐。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 106、Text-Image Conditioned Diffusion for Consistent Text-to-3D Generation
- k8s - container
- Python线程池实现的进阶知识
- 2023感怀而立的岁月,感恩美好的时光,感谢身边的朋友
- 钡铼技术有限公司S281网关Lora参数应用介绍
- C++基础语法——数组、函数、指针和结构体
- 【图像融合】多分辨率奇异值分解图像融合(含融合评价指标)【含Matlab源码 2374期】
- git切换到另一分支更改也会随之过去
- 电子学会2023年12月青少年软件编程(图形化)等级考试试卷(三级)真题,含答案解析
- TypeScript中的Declare关键字的作用