【书生·浦语】大模型实战营——第六课作业
视频链接:https://www.bilibili.com/video/BV1Gg4y1U7uc
教程文档:https://github.com/InternLM/tutorial/blob/main/opencompass/opencompass_tutorial.md
作业要求如下:

基础作业
数据准备
这里使用上次作业lmdeploy的环境。因为超云盘空间了,在lmdeploy环境中下载opencompass的包。
git clone时,github可能会出现连接问题,现在把github改成gitee即可。

进入opencompass目录,执行pip install -e .来安装所需的程序包。
数据准备
cp /share/temp/datasets/OpenCompassData-core-20231110.zip /root/opencompass/
unzip OpenCompassData-core-20231110.zip
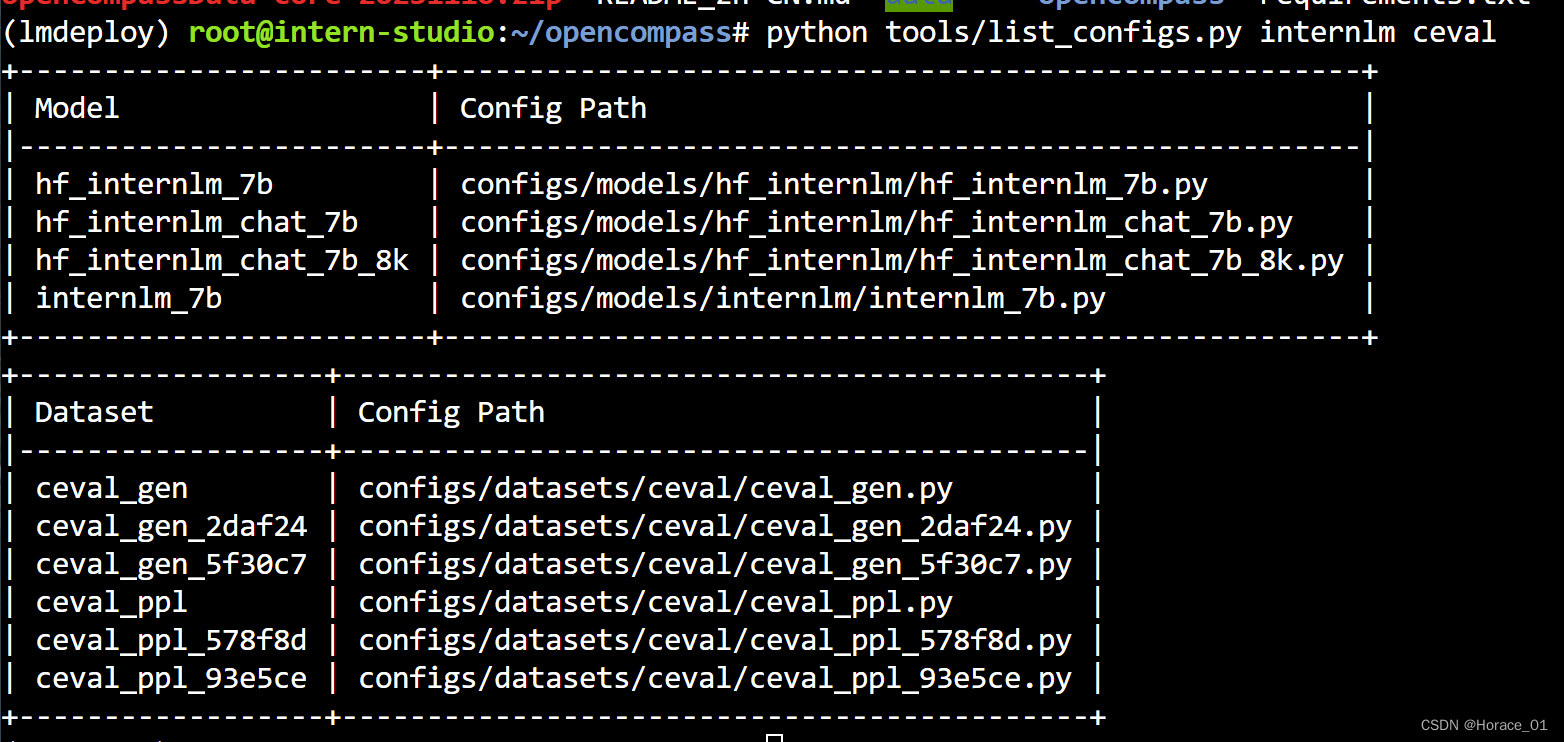
可以通过以下命令python tools/list_configs.py internlm ceval来查看与internlm评测相关的配置文件。
启动评测
通过下方命令启动评测
python run.py --datasets ceval_gen --hf-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 2048 --max-out-len 16 --batch-size 4 --num-gpus 1 --debug
datasets参数:评测使用的数据集
hf-path:要凭策的模型
max_seq_len:输入数据最大的长度
max_out_len:输出数据最大的长度
batch_size:推理时用的批量大小
执行命令后,可以看到模型的载入,然后进行推理
命令执行完毕后,会展示准确率。从左到右,分别是使用的数据集,数据集的版本,评判指标,评测模式,模型在各个数据子集上的评分。
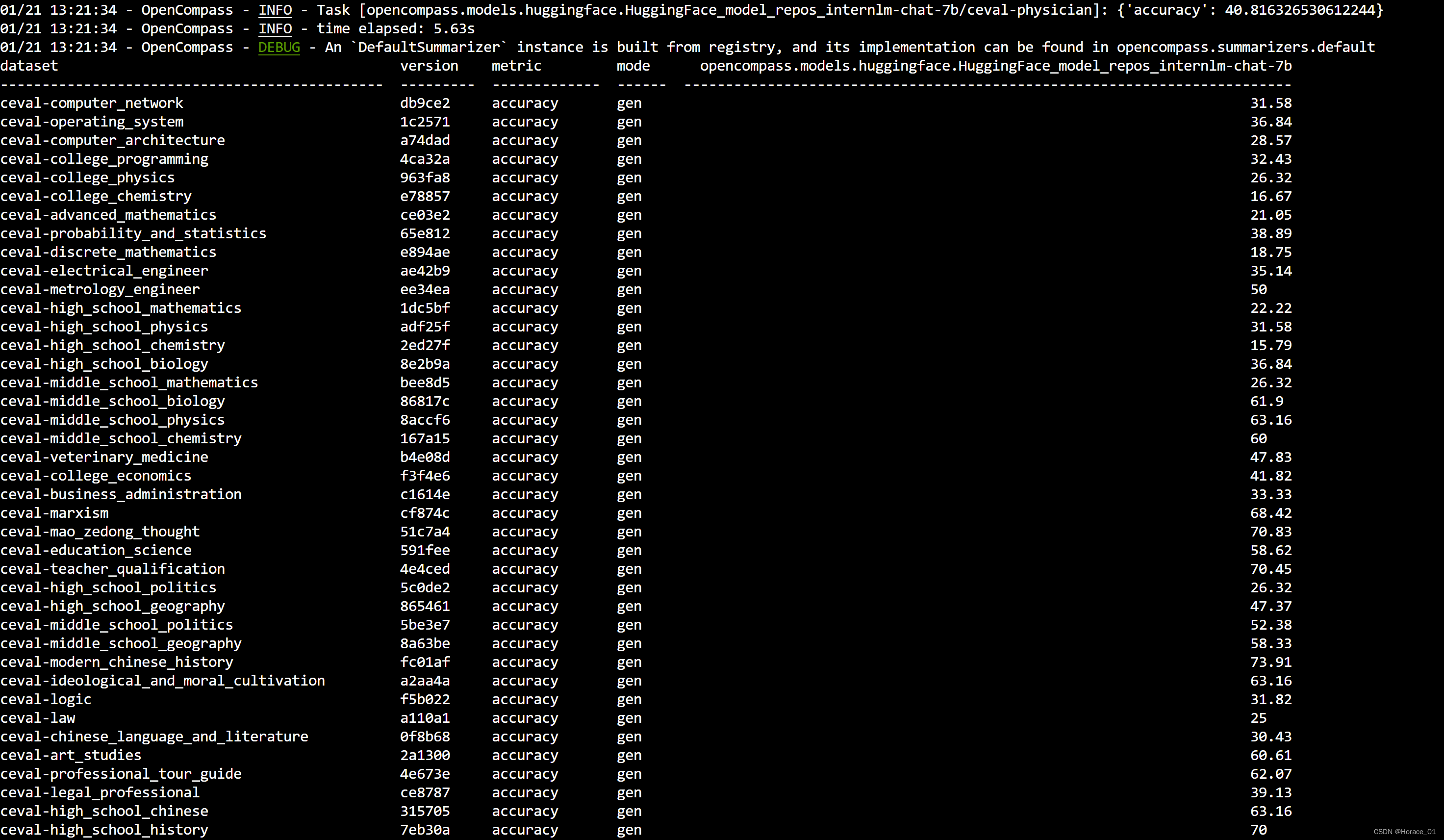
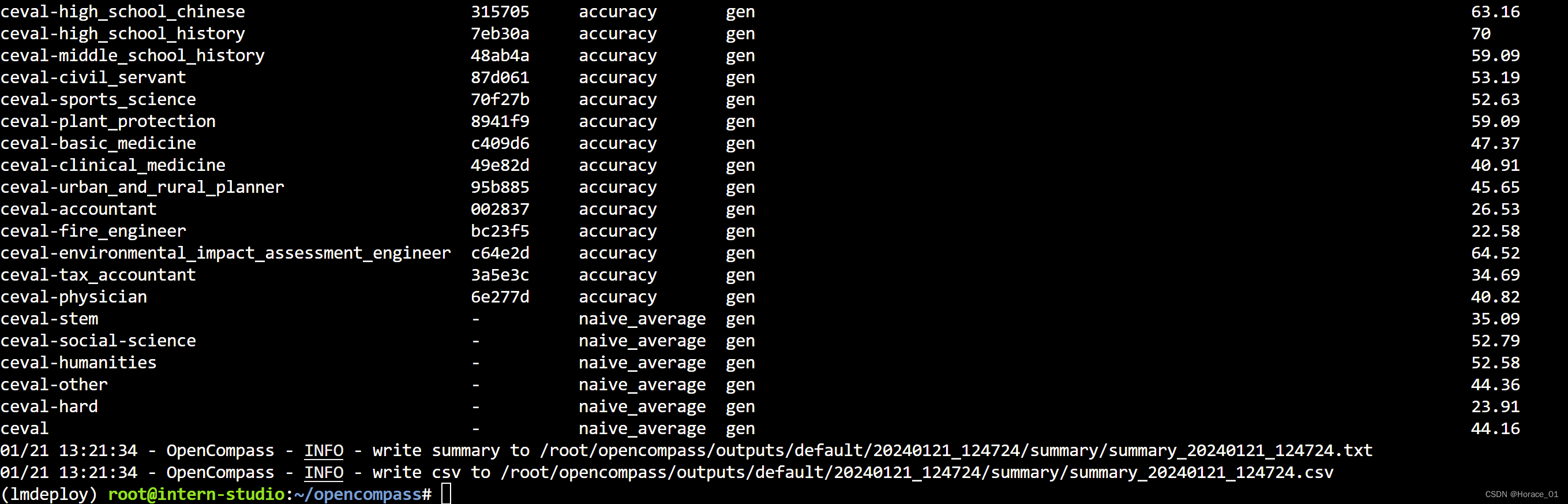
运行后,会在outputs目录下产生对应日志文件。
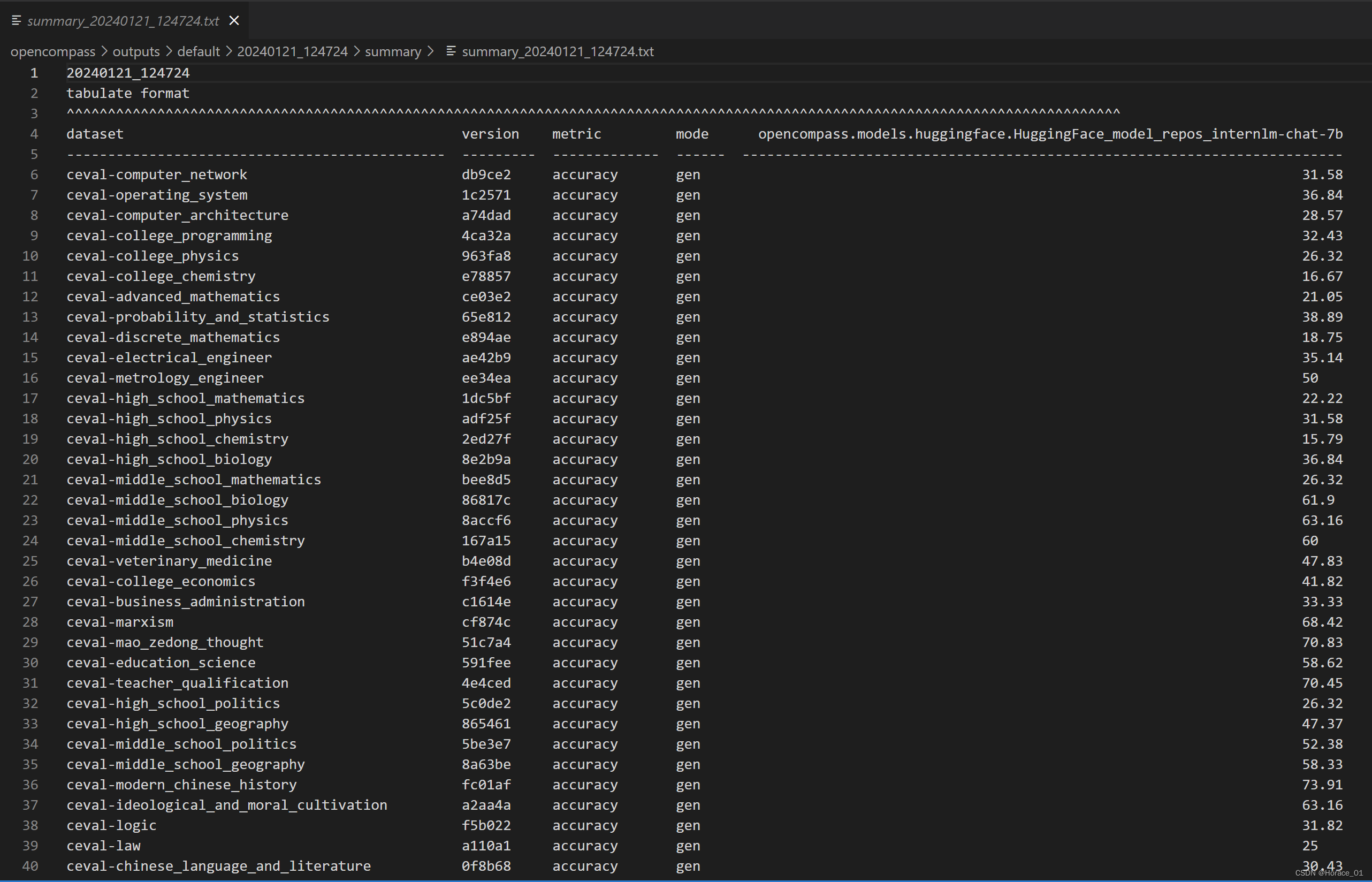
这里summary目录下存放了所有数据子集的准确率。
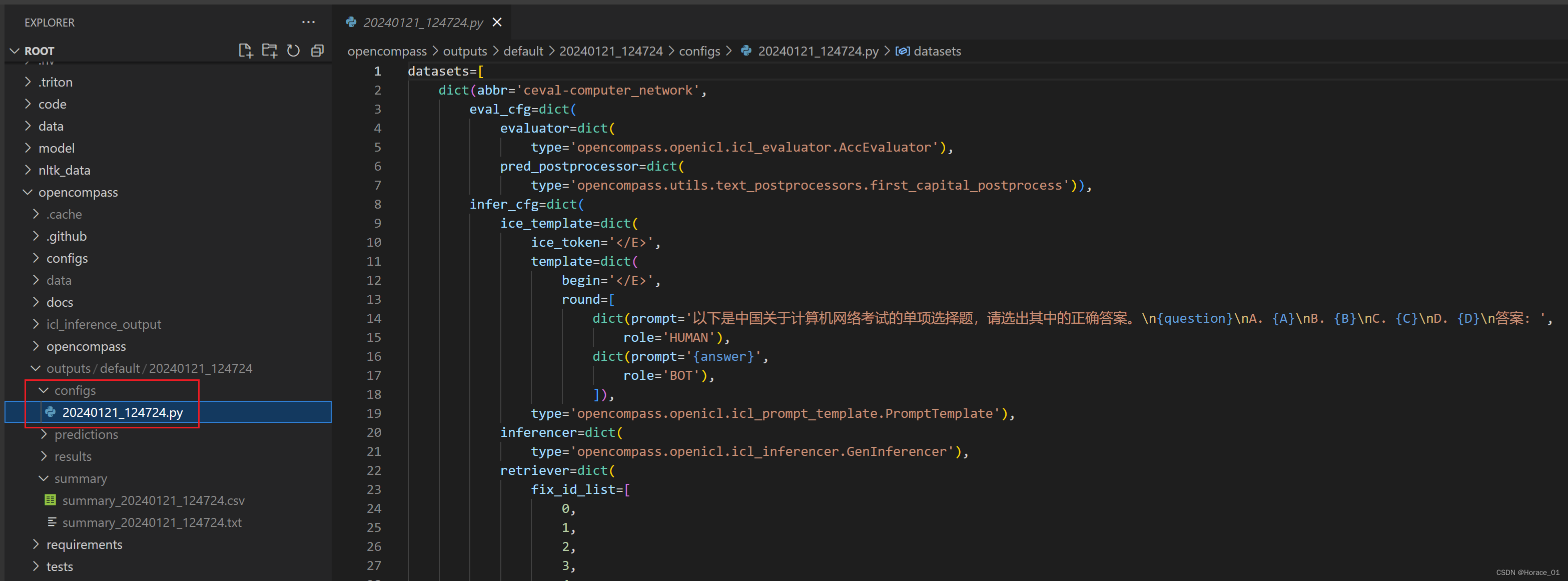
configs目录下有日期命名的py文件,可以看到此次配置形成的配置文件。
我们可以看eval_internLM.py这个文件夹
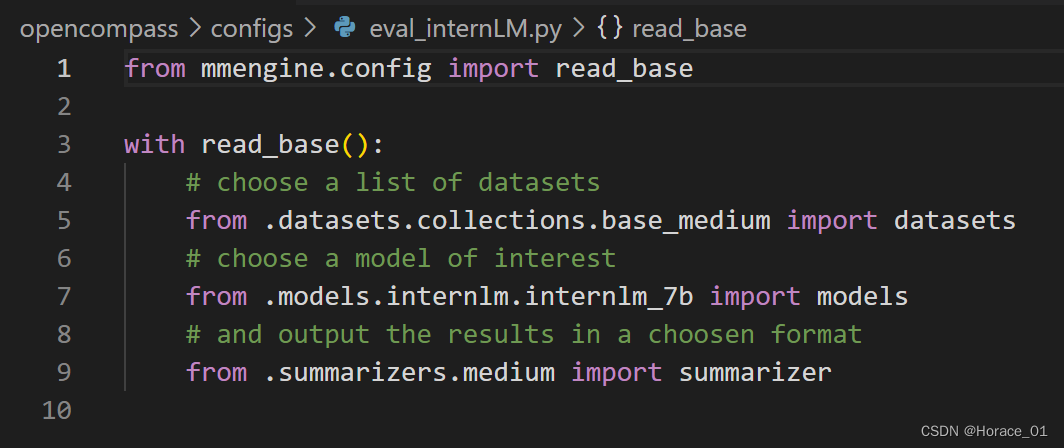
先读取数据集,然后再读取模型,最后读取一个输出配置,方便后续总结。
数据集py文件解读
命令中使用的数据集是ceval_gen.py,可以来看一下
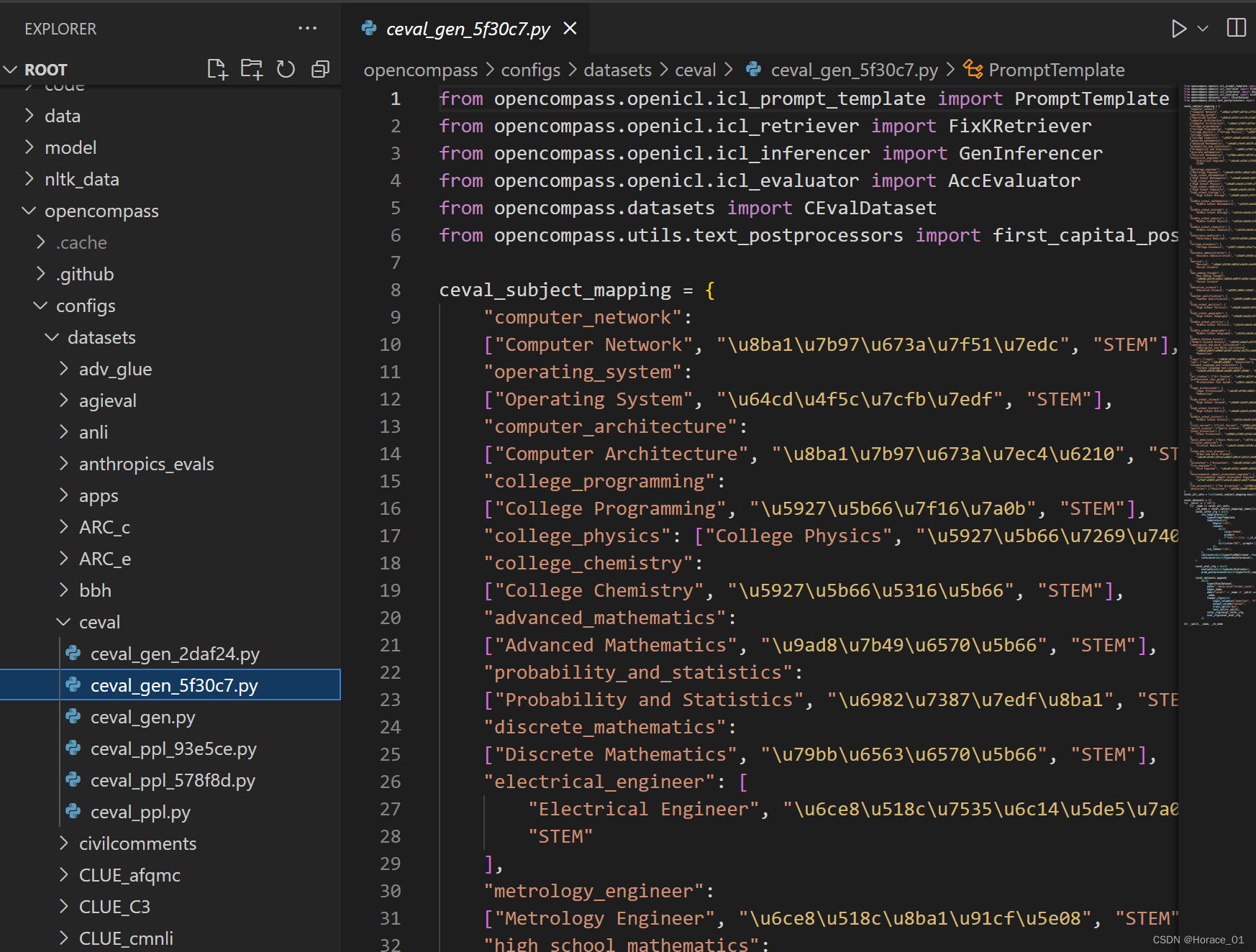
py文件中实际上是写了一个数据子集的映射,脚本文件会遍历子集进行推理来进行评测。比如operating_system操作系统相关的知识。

因为ceval中做的是选择题,所以评判要用准确率,也就是AccEvaluator。
如果要做别的数据集评测,那么就要换不同的evaluator
如果我只想要一个选项A,但是模型输出了A.巴拉巴拉很多东西,模型实际上是答对的。我们需要进行处理。所以此处使用了first_capital_postprocess这个后处理方法。
模型py文件解读
命令中使用的是internlm-7b
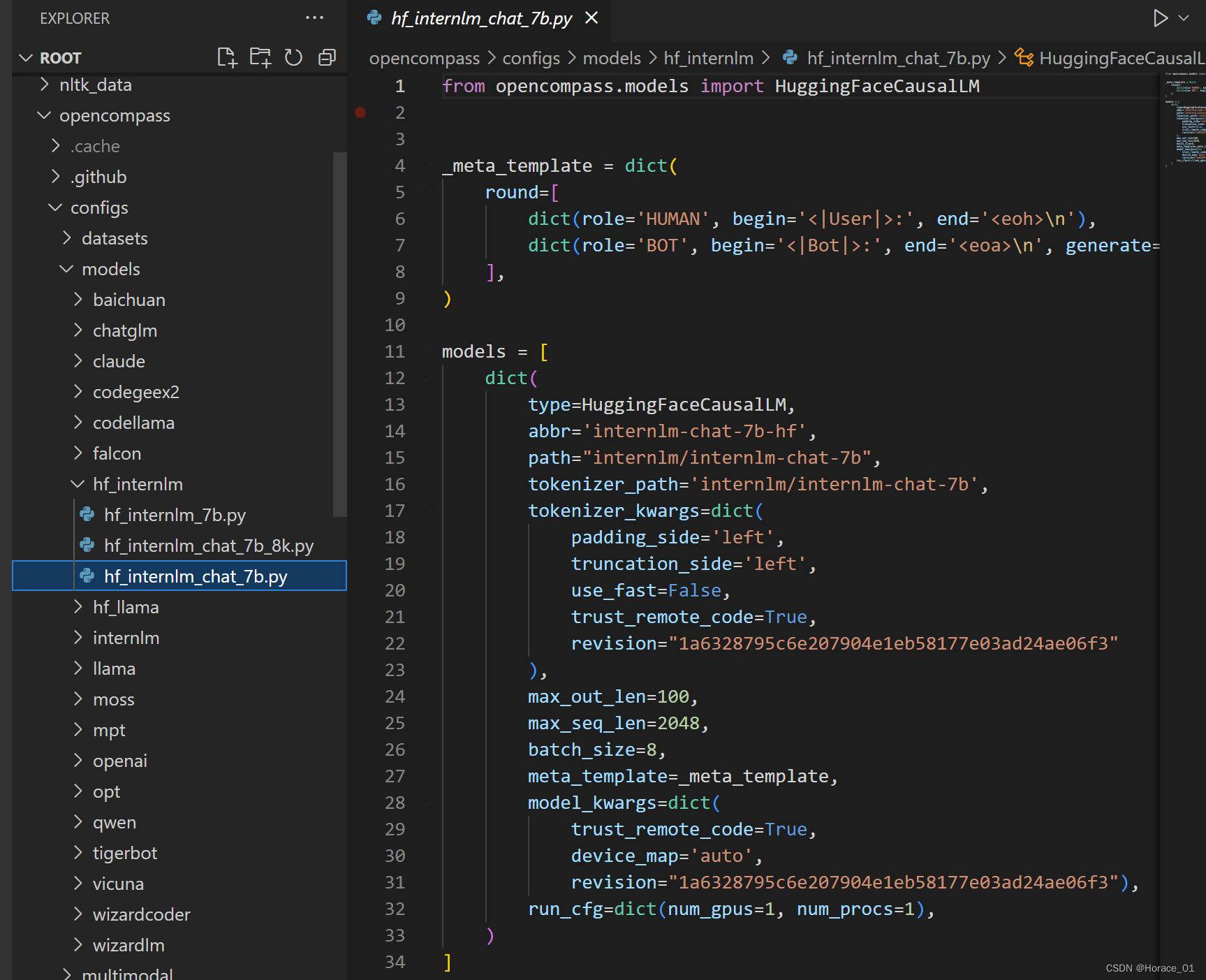
meta_template就是定制的一些元模板。用户开始说,模型开始说。
models中的dict字典存放模型的路径,词表路径,然后最大输入句子长度,最大输出句子长度。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024最新最全ChatGPT角色Prompt预设词教程
- 随笔-我在帝都住过的房子
- MBTI+大模型=甜甜的恋爱?美国新年AI裁员潮;中国大模型人才分布图;20分钟览尽NLP百年;Transformer新手入门教程 | ShowMeAI日报
- 数据驱动与数据安全,自动驾驶看得见的门槛和看不见的天花板
- [EFI]Thinkpad L380 Yoga电脑 Hackintosh 黑苹果efi引导文件
- scalpel一款命令行漏洞扫描工具,支持深度参数注入,拥有一个强大的数据解析和变异算法
- 高级分布式系统-第15讲 分布式机器学习--联邦学习
- 模型库创建-使用flask-sqlacodegen
- SQL注入检测工具及方法,黑客零基础入门
- Linux系统文件类型简介