内存问题(三)——生成内存问题案例
一、系统非堆内存溢出问题排查
以下例子出自其他人案例,拿过来是为了学习排查问题思路,与解决思路。
1.1 现象描述
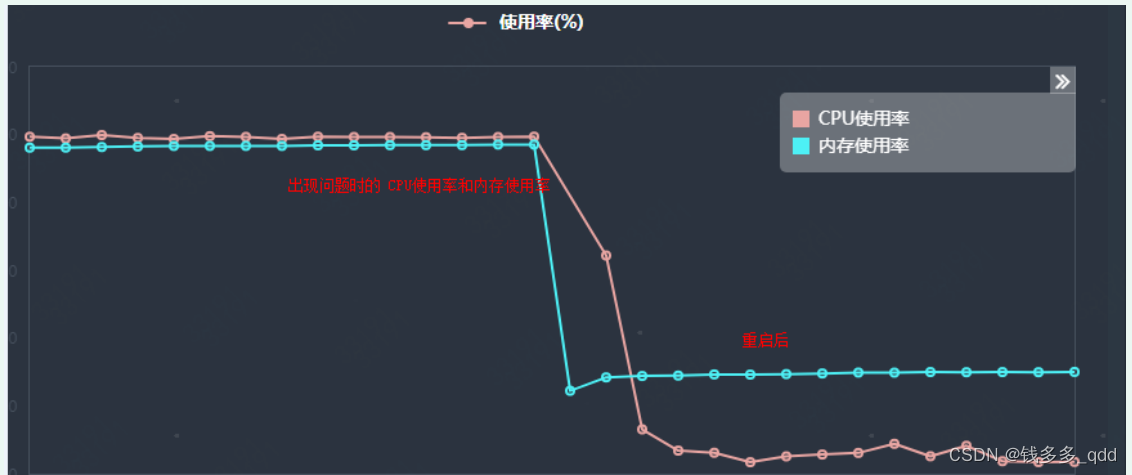
运单系统每隔一段时间,内存使用和CPU报警超出阈值85%,通过监控平台可以看到非堆内存持 续增加不回收
。导致频繁FullGC,引起CPU100%
1.2 操作系统监控图
1.3 JVM内存监控
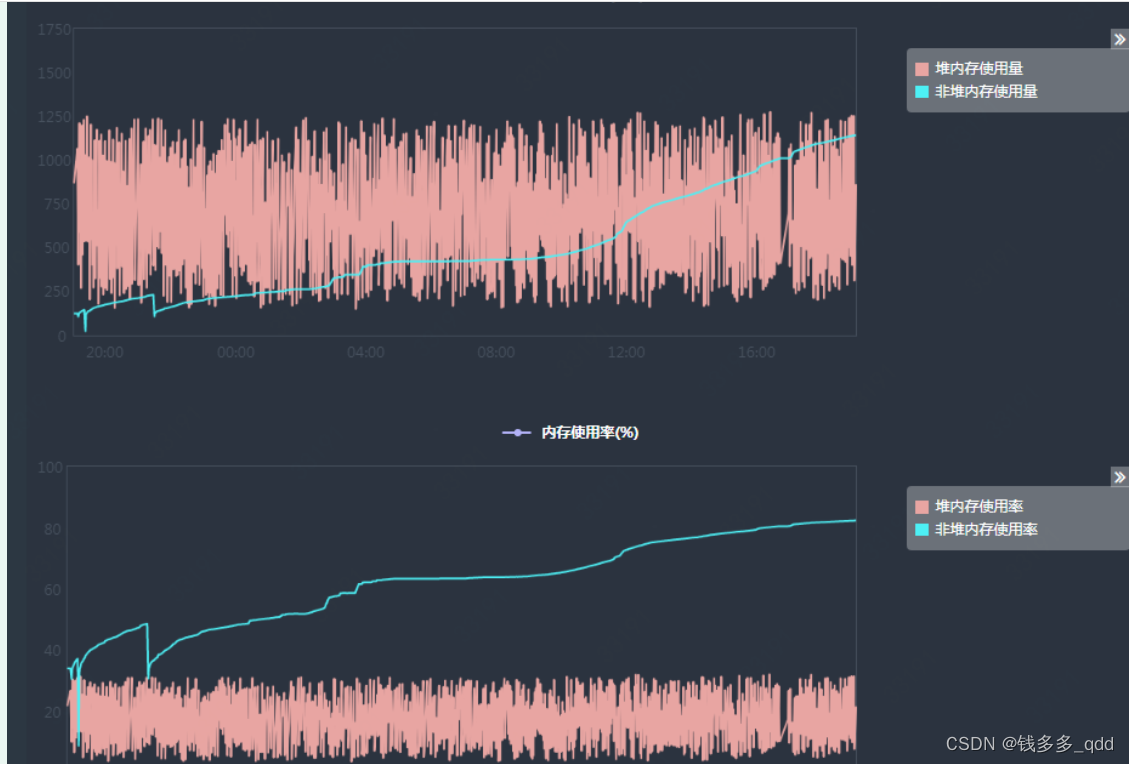
??从监控上看非堆内存永久代(JDK8 HotSpot JVM将移除永久区,使用本地内存来存储类元数据信息并称之为:元空间(Metaspace))一直增加且无法回收。这部分内存主要用于存储类的信息、方法数据、方法代码等,正常情况下元空间不会占用很大内存,所以对于动态生成类的情况 比较容易出现永久代的内存溢出。开始怀疑应该是使用反射、代理等技术生成了大量的类加载到元 空间无法回收。
1.4 问题排查
1.4.1 使用jstat 查看内存及GC情况

各列含义: jstat (oracle.com)
- S0C:第一个幸存区的大小
- S1C:第二个幸存区的大小
- S0U:第一个幸存区的使用大小
- S1U:第二个幸存区的使用大小
- EC:伊甸园区的大小
- EU:伊甸园区的使用大小
- OC:老年代大小
- OU:老年代使用大小
- MC:方法区大小
- MU:方法区使用大小
- CCSC:压缩类空间大小
- CCSU:压缩类空间使用大小
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
??可以看到发生了FullGC, MU 和 CCSU 都很大,FullGC并没有回收掉,再次确认了元空间内存溢出的可能。
1.4.2 打印类加载信息 分析代码
在JAVA_OPION 中添加 -verbose:class 打印类加载信息。重启后观察日志输出
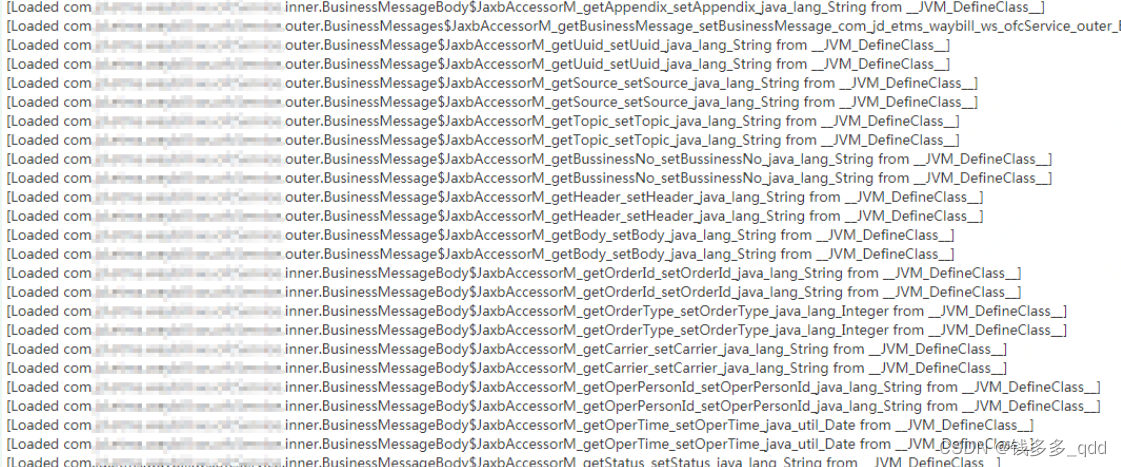 ??发现以上输出信息,并且一直不停的Loaded。 打印出了相关的业务类.BusinessMessageBody、BusinessMessage ,看样子是使用Jaxb 序列化成XML时产生的问题。在项目中搜索相关代码。
??发现以上输出信息,并且一直不停的Loaded。 打印出了相关的业务类.BusinessMessageBody、BusinessMessage ,看样子是使用Jaxb 序列化成XML时产生的问题。在项目中搜索相关代码。
总之,不是自己的案例,s省略中间的源码分析过程…,直接给结论:
因为框架这一行,会重复执行类的定义,一定重复定义,重复定义,在jvm内部会有一次约束检查出LinkageError,但临时创建的结构,等待GC去回收。
1.4.3 思考,并分析dump文件
??那么回过来想,为什么 injectors 被回收后,对应的Class实例未被回收卸载掉呢? 此现象产生的环境差异是因为升级了JDK版本,由JDK7升级到JDK8, 那么JDK8对垃圾回收做了哪些改变,是否这些改变导致了此问题的产生。带着这个疑问检索 google,得到了答案。
??在JDK 7中,对Permgen中对象的回收会进行存活性检查,因此重复定义时产生的数据会在GC时被清理。然而在JDK 8中,Metaspace的回收只依赖classloader的存活,当classloader还活着时,它所产生的对象无论存活与否都不会被回收,由此引发了OOM。
从生产环境dump出来的内存文件分析后验证了这一点:
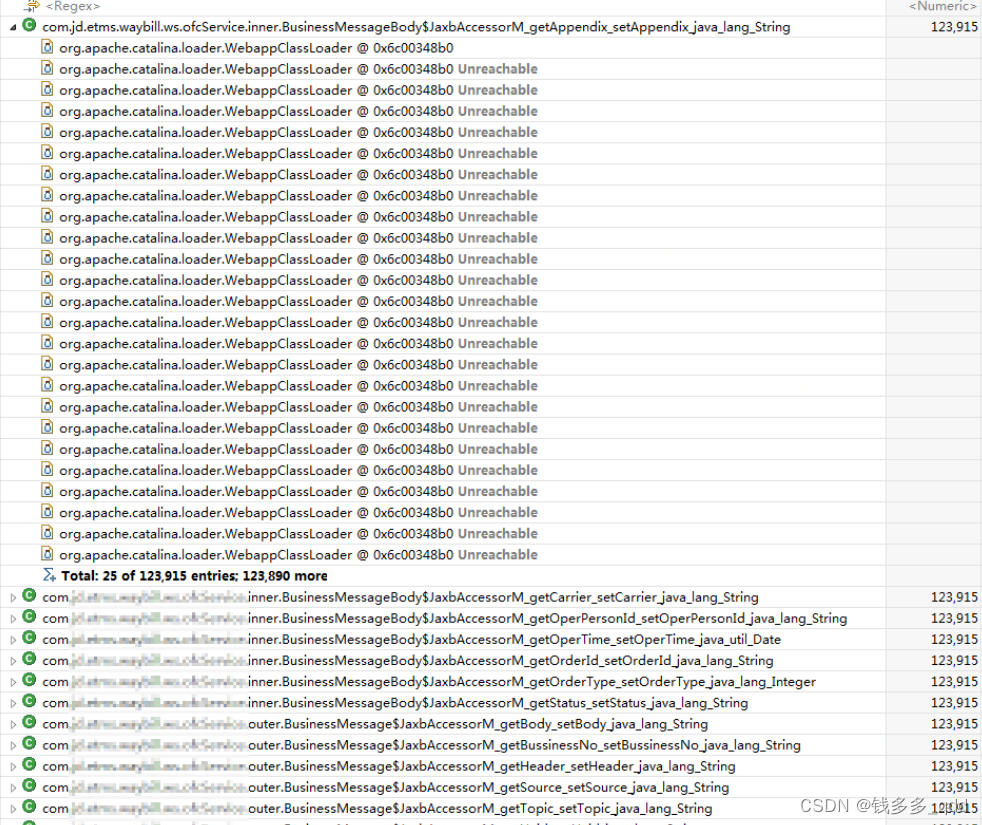
参见 :
假笨说-谨防JDK8重复类定义造成的内存泄漏
JVM源码分析之JDK8下的僵尸(无法回收)类加载器
JAXB导致的Metaspace OOM问题分析
??JAXB-impl 2.2.11 版本 inject 版本种增加了一段 findLoadedClass`` 逻辑,按名称查找是否已有加载的类,避免重复定义加载。
二、入库内存泄露总结
??由于条件问题,一个查询语句把一个表里所有的记录都查询出来了,数据量很大,把内存打爆,
造成现场验收卡,卡,卡…
2.1 用jmap -dump命令导出JVM的整个内存信息。
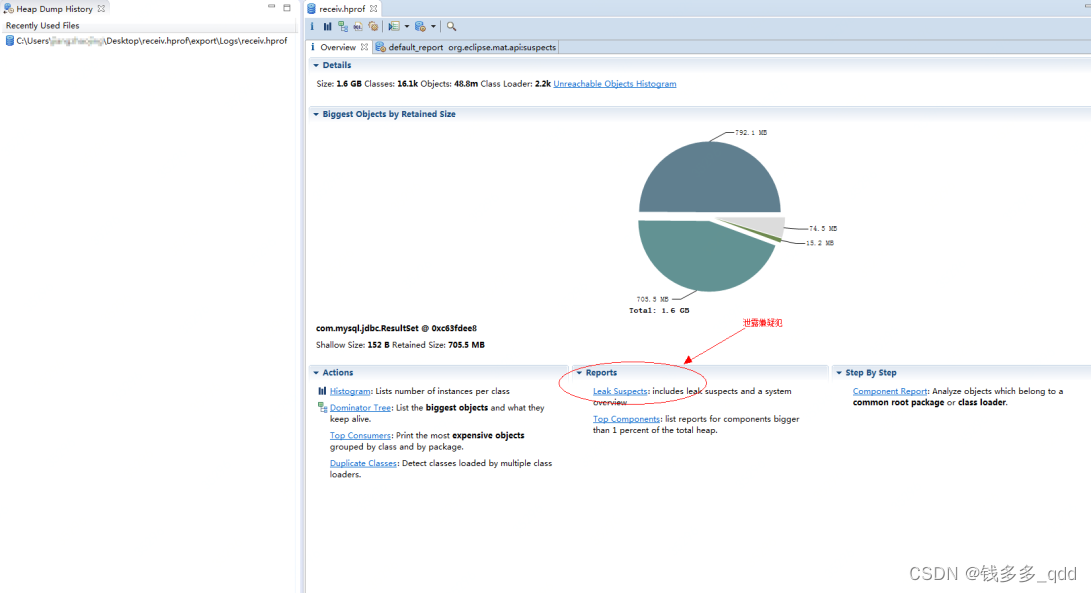
快速定位报表里的泄露嫌疑犯,点击进去,如图,发现这两个嫌疑犯占用了
49.90%+44.45%=94,35%的内存,还让其他功能咋用呢??
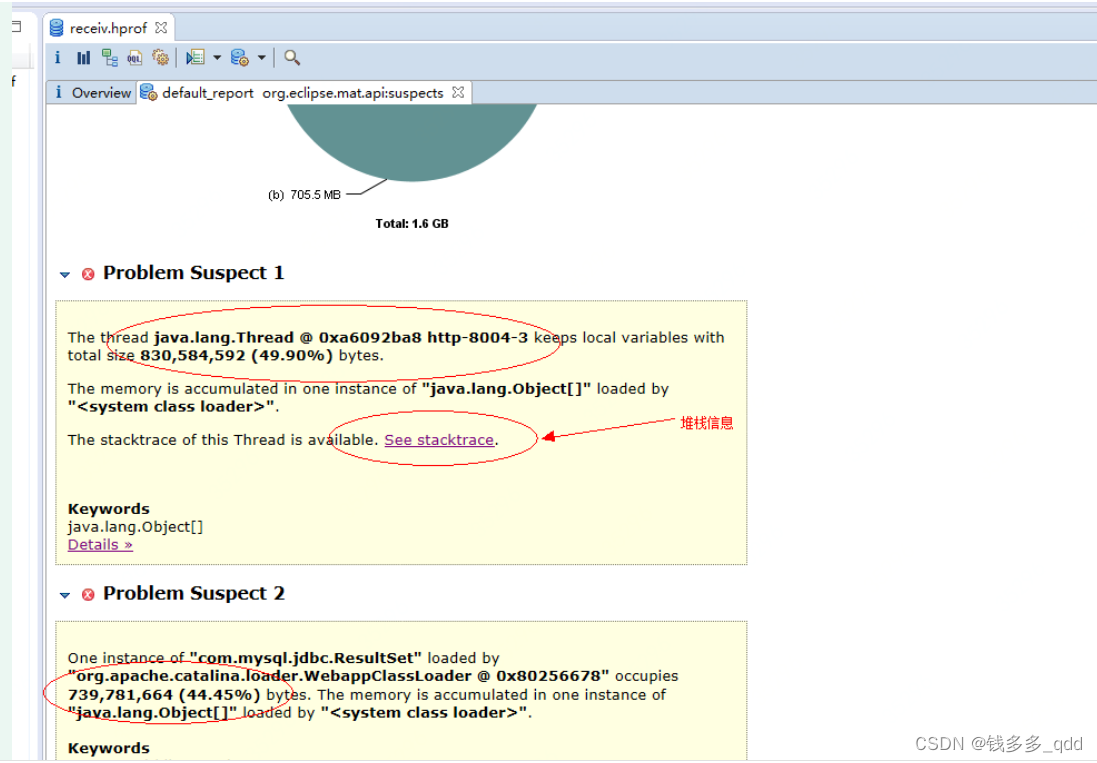
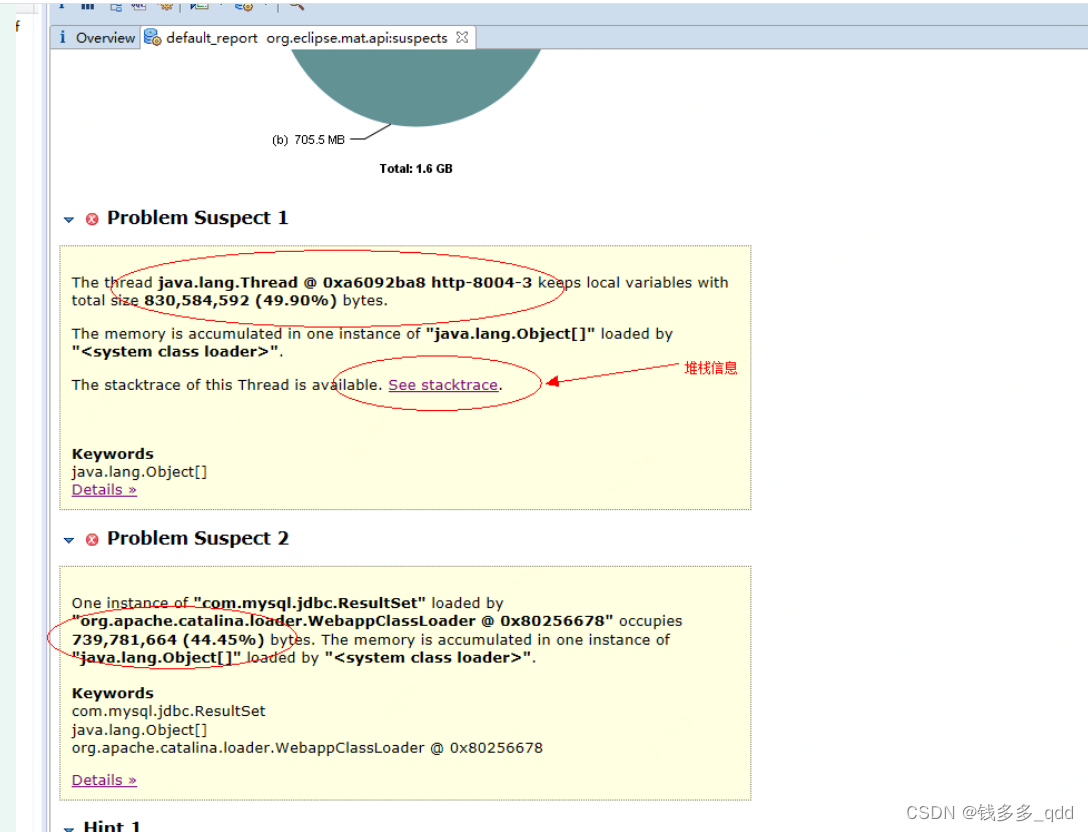
点击第一个嫌疑犯的堆栈信息链接,仔细看就能发现该嫌疑犯是如何行凶的,如下图:
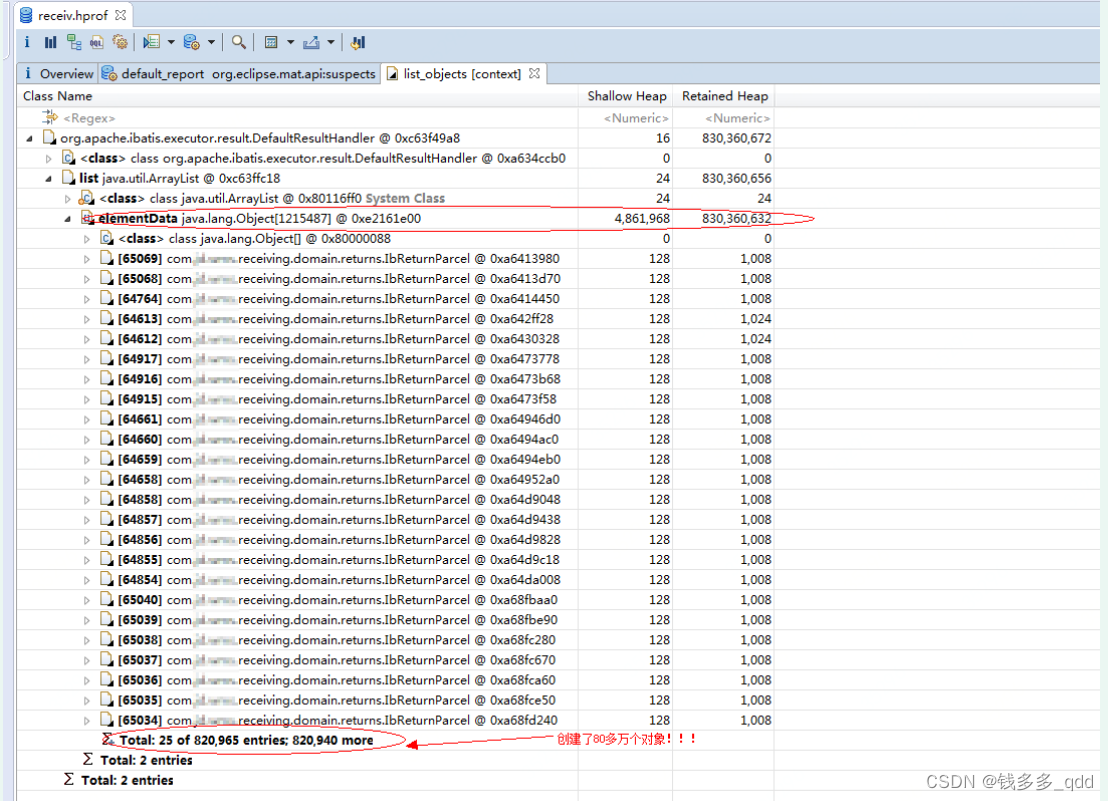
总结:内存分析工具有很多,使用MAT是其中的一种方法。另外,除了手动导出JVM内存信息外,还可以通过设置JVM参数,在JVM发生内存泄露的时候自动导出文件。
三、ArrayList递归调用addAll方法导致内存溢出
过程略,直接给结论:
??本段递归原思想以ids(ArrayList)为容器,循环添加每个子节点包含的全部分组id,并加上自身节点,进行返回。
??但是,由于ids为引用传递,每次addAll操作都会将容器中已有的ids重复添加到容器中,造成每次添加容器中的数据都会发生倍增。
??子分组数小时,不会发生异常现象。ArrayList 的每次扩容包括分配1.5倍的新数组空间,和老数组历史数据的拷贝。
??当子分组数超过27个时,数组长度达到了134217726,当长度超过Integer.MAX_VALUE-8或系统无法给ArrayList分配足够长的连续内存空间时,就会抛OOM异常。
??ArrayList的频繁扩容与拷贝操作,也导致了在执行递归方法开始到抛出OOM异常这段过程中,Cpu一直处于100%的状态,无法处理其它请求。
3.1 经验总结
- 在写完递归方法后,自测一定要认真测试到递归方法层的输入与返回,功能通过不能代表代码没有问题。
- 在使用ArrayList的时候,如果可以预知数组的大小范围,尽量对其进行容量大小的初始化,避
免其频繁扩容。
四、读取excel引发的内存泄露
4.1 现象
- 业务反馈****.com打开显示502,去查logbook日志发现应用出现内存溢出;

- 去ump中jvm监控查dump文件输入路径“-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/export/Instances/las-im-manager-new/server1/logs”,登录运维自主平台下载dump文件;
- 使用MAT工具打开dump文件,查看大对象的具体堆栈信息;

- 去程序中查代码,excel导入读取是使用WorkBook的方式,经测试几兆的excel文件导入就占用大量的内存(超1g);
- 去查poi文档 http://poi.apache.org/spreadsheet/how-to.html ,发现POI提供了2中读取Excel的模式,分别是:
- 用户模式:也就是poi下的usermodel有关包,它对用户友好,有统一的接口在ss包下,但是它是
把整个文件读取到内存中的,对于大量数据很容易内存溢出,所以只能用来处理相对较小量的数据; - 事件模式:在poi下的eventusermodel包下,相对来说实现比较复杂,但是它处理速度快,占用内存少,可以用来处理海量的Excel数据;
- 参考了poi官方example( http://svn.apache.org/repos/asf/poi/trunk/src/examples/src/org/apache/poi/xssf/eventusermodel/examples/FromHowTo.java ),使用事件模式读取excel,解决了问题;
五、通用sql查询条件全if导致的内存溢出
5.1 现象:
??目前JVM启动日志中都配置了 内存打满前自动dump,前往对应的机器dump日志进行分析,使用工具为jprofiler,经过分析 发现byte类型占用了435MB的数据,并且调用来源为ibatis.executor.resultset.ResultWrapper,经过jprofiler分析,怀疑有全表查询语句 返回了大对象
导致的内存溢出。
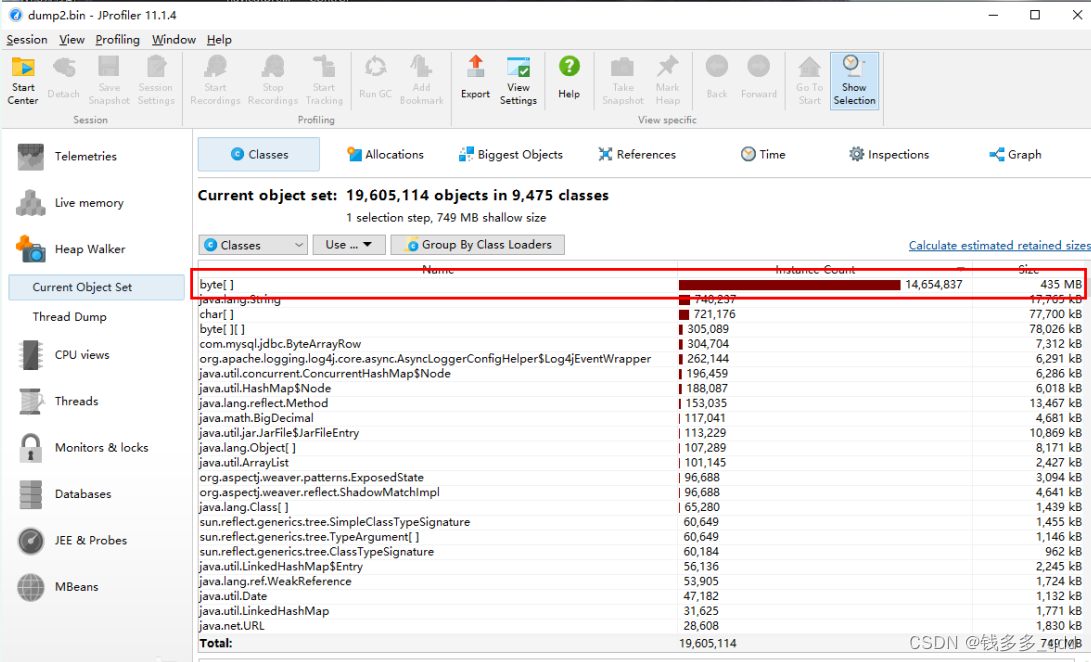
5.2 查询对应数据库是否存在慢sql全表查询
问题sql:
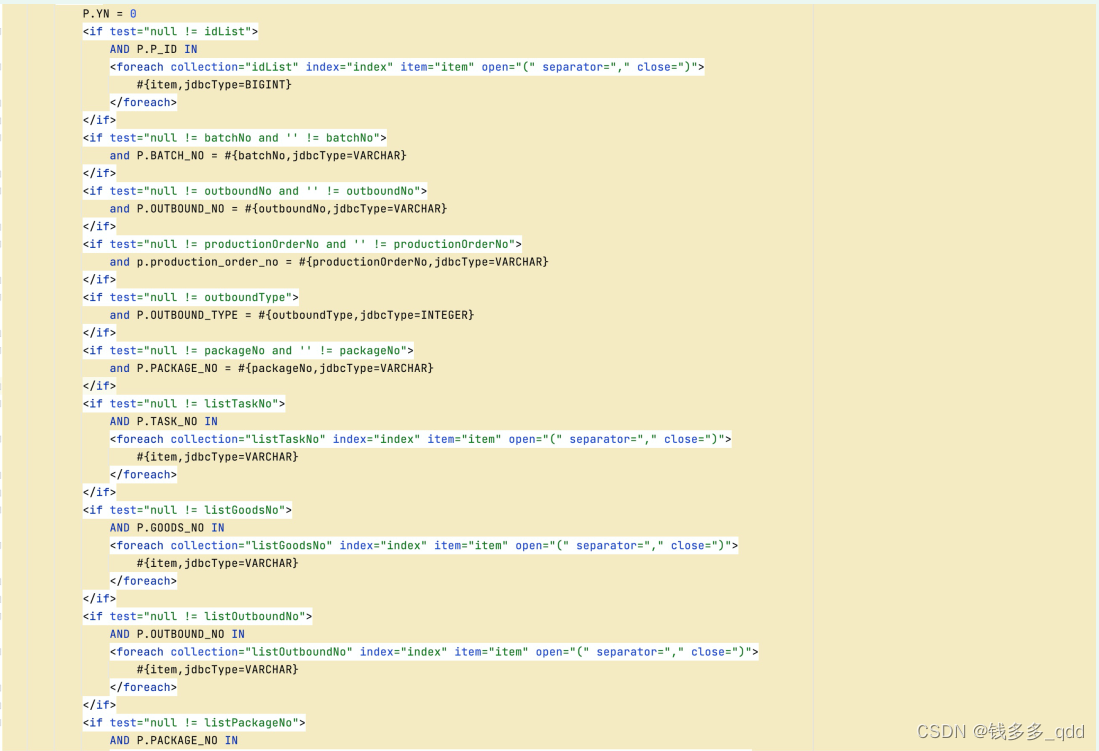
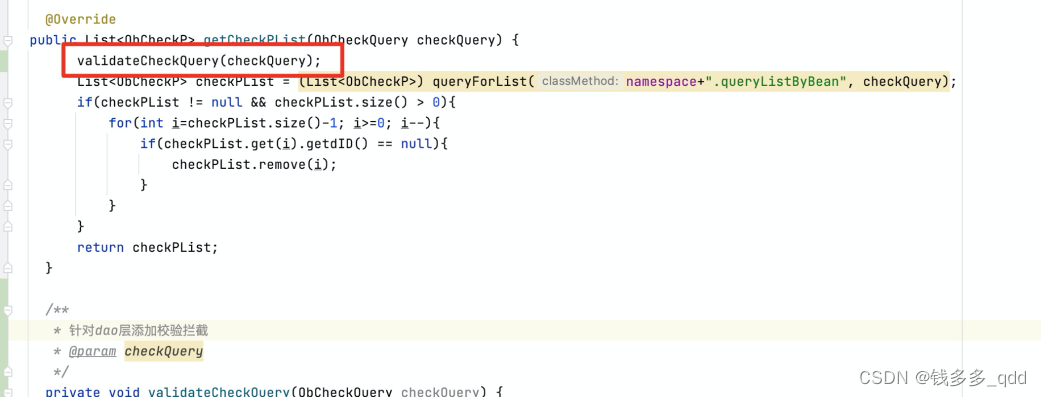
5.3 修改方案: 针对Dao层对一些基础参数进行强制校验(三要素)
六、JVM堆栈内存溢出问题分析
6.1 分析JVM内存溢出时生成的hprof
关键数据:
JVM堆栈报告中:大对象:
大对象中的占用内存最大的属性:
未来得及释放的XML解析数据: 该数据已经导出,在后面:
线程调用的HTTP响应方法:
用户上传文件:
6.2 原因分析:
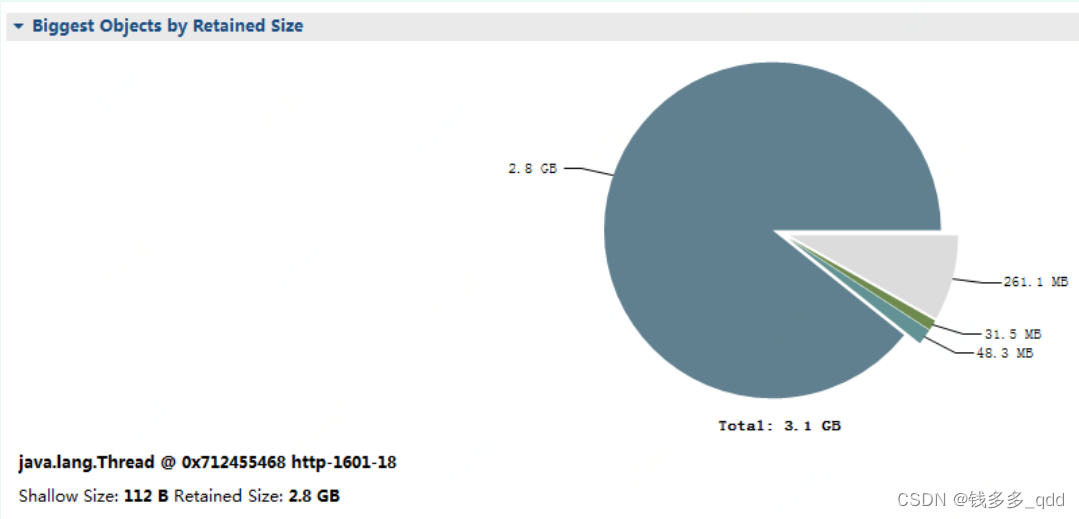
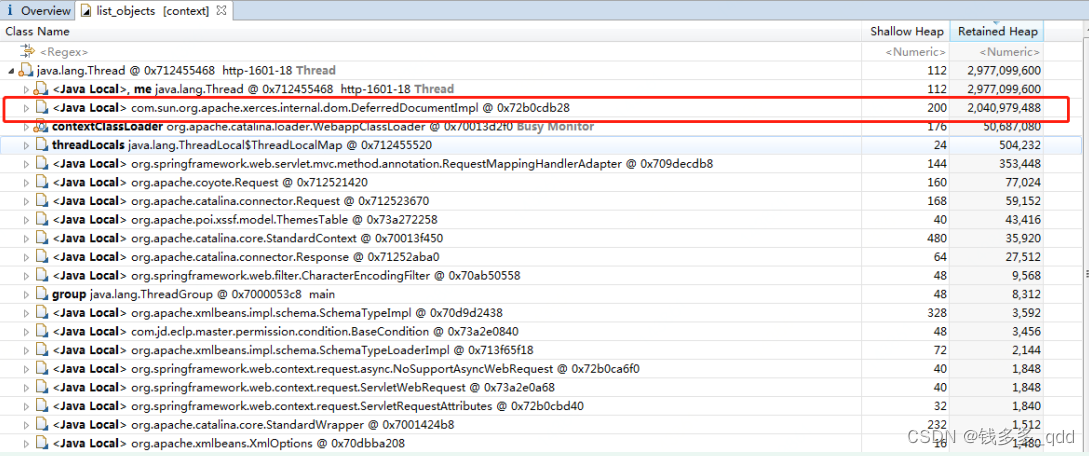
??在查看JVM内存堆栈信息分析报告的,Orverview的大对象图表中,说名称为"http-1601-18"的线程事例时占用内存超过2G;继而查看该线程实例包含属性实例明细列表;
??发现线程中占用内存最大的实例类为:
com.sun.org.apache.xerces.internal.dom.DeferredDocumentImpl ,占用内存 2G 左右;初步可以确定此实例的创建造成了JVM内存溢出;
??而该实例是POI工具包用于解析xlsx格式文件中的XML文件用的,也就是说是因为该线程执行过程中需要有xlsx文件解析逻辑。
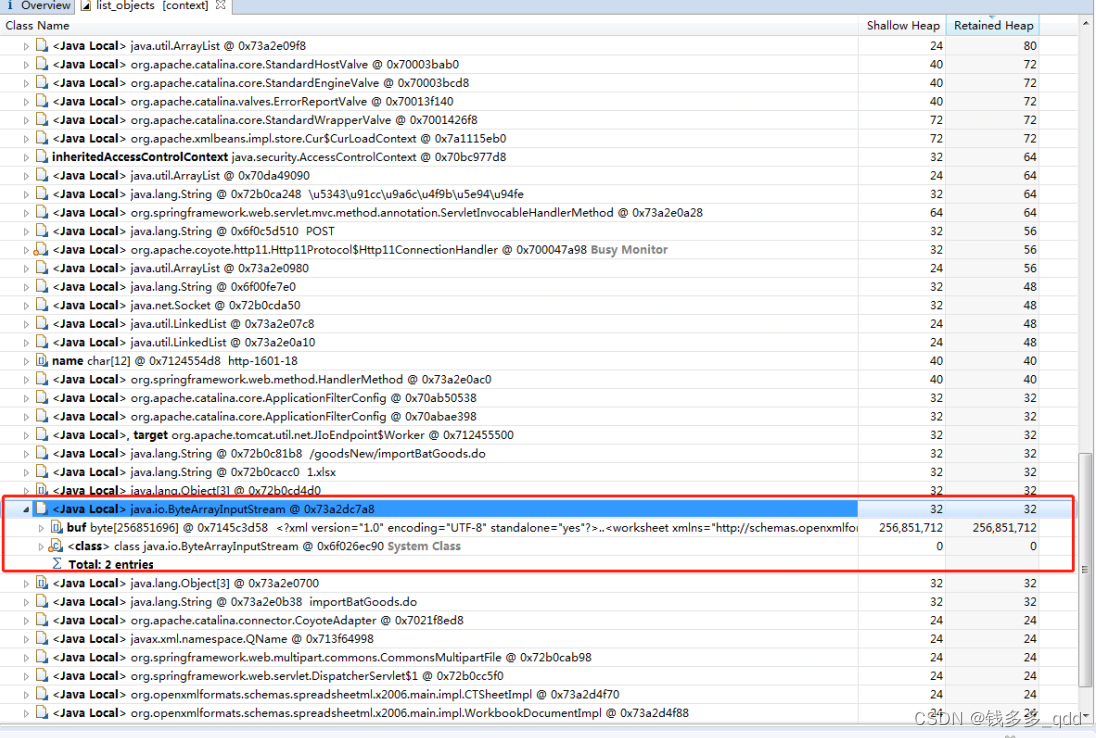
进而查询该线程的调用HTTP业务接口,是:
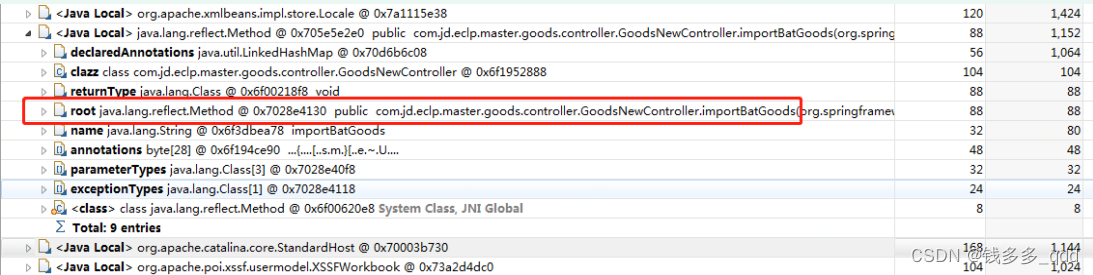
com…master.goods.controller.GoodsNewController#importBatGoods ;
结合代码,获知此方法是用于批量导入事业部商品数据的,其大致逻辑是:
- 接收用户导入的xlsx文件
- 使用POI包对文件进行解析
- 循环遍历解析后的数据,对他们进行数据验证、数据入库(及创建商品)操作
- 返回导入结果
??结合的代码逻辑,堆栈信息分析,初步结论为某一用户在执行改操作时,导入了过大文件,导致此次的JVM 内存溢出事故;
然后查询四台主机操作日志:果然发现同一个用户在每次告警前的几分钟,都在商家工作台执行了商品导入操作;
??因而得出本次JVM内存溢出的最终原因为:系统并未对导入文件大小做限制或限制太宽松; 从而导致用户导入较大的文件时在解析过程中出现 JVM内存溢出问题;
??因而得出本次JVM内存溢出的最终原因为:系统并未对导入文件大小做限制或限制太宽松; 从而导致用户导入较大的文件时在解析过程中出现 JVM内存溢出问题;
6.3 问题修复方案
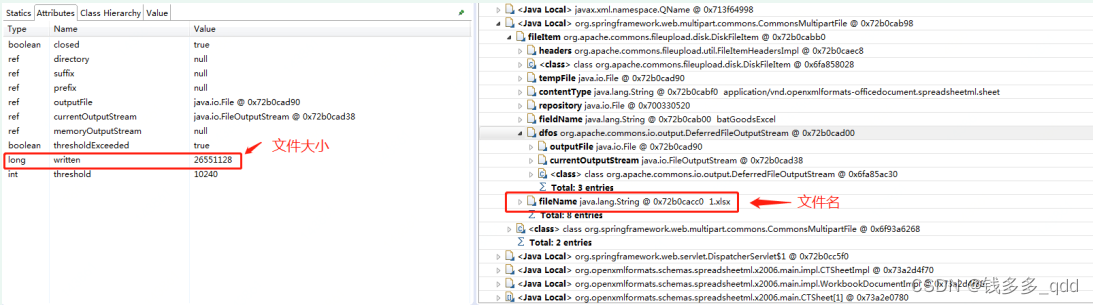
- 对上传得文件进行大小限制;限制的原则就是根据模板和数据条目上限,计算出一个合理的数值;根据实践:1000条的数据文件大小约在135K,5000条的文件大小在619K;也就是说文件大小不应该超过1M;而本案例中,用户上传的文件大小在26M左右;
- 解析数据时,要先进行数据行数验证,在对行数据进行解析;尽量减少数据转换次数;
七、生产环境部分机器内存溢出问题处理
7.1 现象
??部分请求出现502的情况。经查看发现5台服务器中的一台宕机,Tomcat进程已经不存在了。
??对该服务器及负载下的其他服务器的运行状态进行观察发现:该服务器的jvm已经没有数据,其他服务器jvm内存均接近100%,看来其他服务器也岌岌可危啊。
??查看了下宕机的那台服务器日志,关键信息如下:

??为了查看该日志文件,和jdos同事,申请开通了 该服务器 和 另外一台濒临崩溃的服务器的 终端连接信息;
??该文件信息基本上全是当时崩溃是的内存的一些大小参数(忘记截图),参考意义不大;
7.2 分析
??紧接着为了查看内存中到底是什么对象导致了内存的崩溃,由于jvm崩溃了,获取不到现在的一些信息了,于是连接到另外一台“濒危”的服务器上,去查看jvm内存的一些状况,具体情况如下:
- 首先使用查看了下 jvm进程ID为 139;
- 使用该命令 :sudo -u admin ./jmap -histo 139|more 查看到的情况如下:
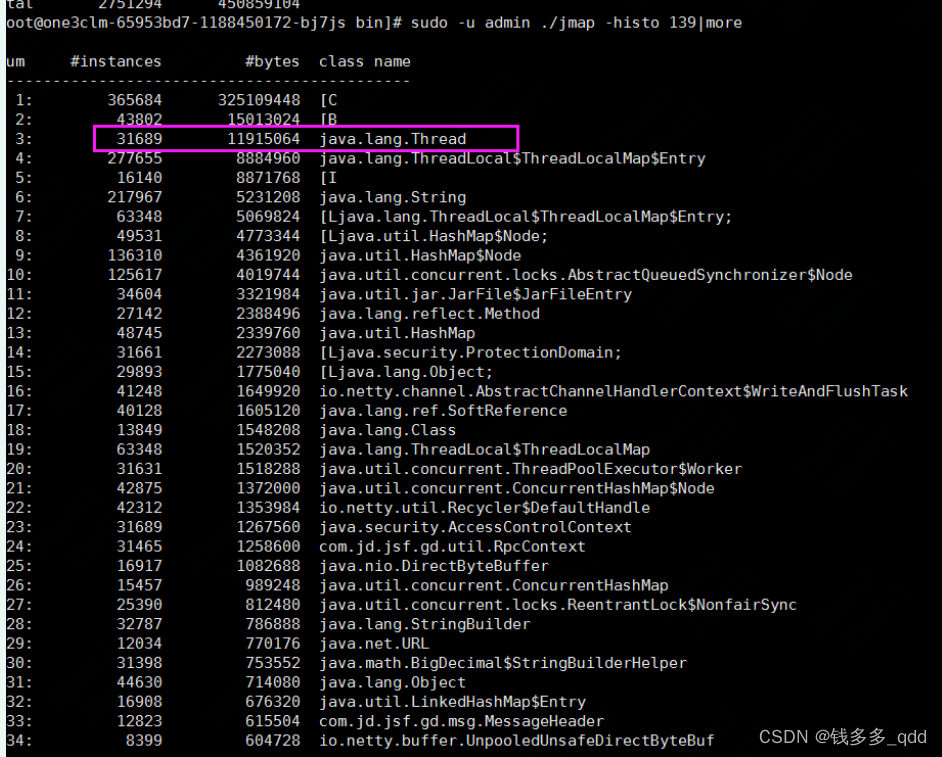
?如图:有31889个“Thread”事例导致,初步分析,某个地方在疯狂创建线程。但是,在哪个地方创建呢?我和几个相关同事沟通,确定没人在这个项目里边创建过线程。
?其实这个时候离成功仅有一步之遥了。
-
正在兴奋的解决中,杨xx同学也参与进来建议用sudo -u admin ./jstack -l -F 139 > stack.txt 打印堆栈信息,如图:
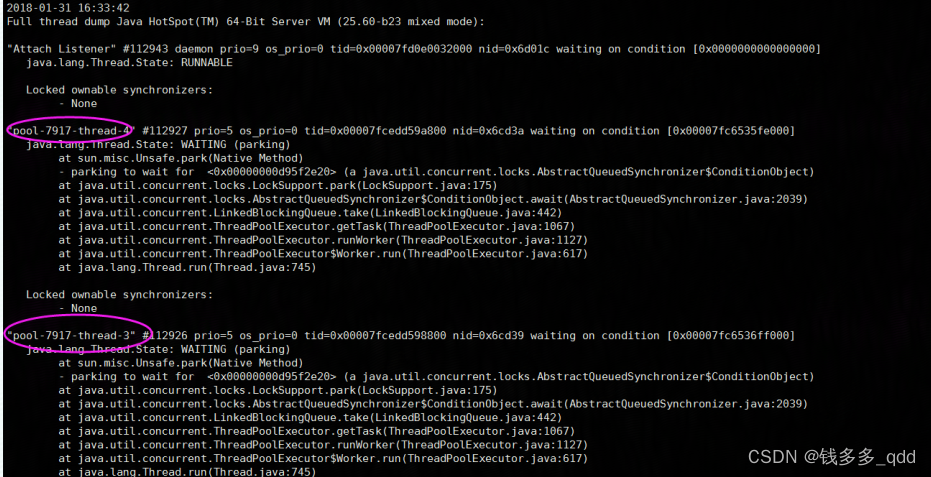
查到有7000多个线程池,可以定位某个地方在疯狂创建线程池,肯定了第一步的判断。 -
然后全文搜 Executors,发现之前的同事有两处创建线程池,并且是每次该请求接口基本上都会创建一个固定4个大小的线程池!原因终于找到了;此处列举一处:
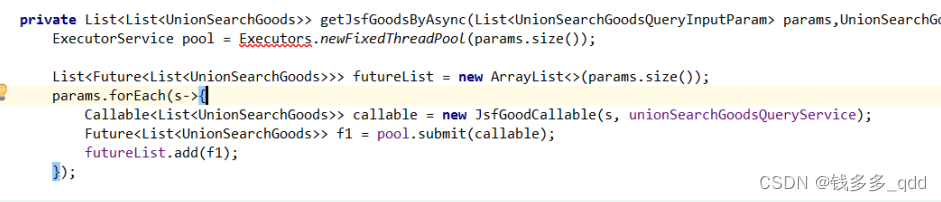
-
于是,将宕掉的机子重启,然后频繁的去请求该接口,复现了异常情况,由此可以肯定了判断。此处修改为启动的时候创建一个线程池,请求的时候创建一个Callable实现即可。
续:补上此次服务器的jvm参数,以及dump文件大小

使用命令 sudo -u admin ./jmap -dump:format=b,file=a.hprof 139。
7.3 事故反思总结
- 将服务器监控预警做到位,此次疏于预警,导致服务器异常,没有及时发现,而是由业务方通知发现的,以后应避免此类事情再次发生。
- 多人合作项目,项目时间长一些细节东西已经记的不清晰了,以后重要的设计点最好有设计问题,方便后人解决问题。
- 有必要进行codeReview,来相互学习,相互进步。
- 应继续加强深入学习jvm相关知识,此处的事故算是一个在学习jvm道路上的一个成功解决案例。
八、JVM异常终止问题排查
8.1 现象
jdos两台机器JVM突然挂掉(11.26.78.xx、10.190.183.xx),查看MDC监控,发现jvm挂掉的时间点 机器内存占用很高(99%);
内存很平稳,每次yong gc,都能降下来;至JVM挂掉之前,未触发过full gc;CPU和线程数也都很正常。
8.2 问题初步分析定位-尝试Google
8.3 linux的OOM killer
?Linux 内核有个机制叫OOM killer(Out-Of-Memory killer),该机制会监控那些占用内存过大,尤其是瞬间很快消耗大量内存的进程,为了防止内存耗尽而内核会把该进程杀掉。 因此,你发现java进程突然没了,首先要怀疑是不是被linux的OOM killer给干掉了!
OK,顺着这个思路,确定到底是不是被oom killer干掉的。
查看系统报错日志: /var/log/messages,发现此文件是空的(后来咨询jdos运维同事得知,docker实例写此日志被禁用)
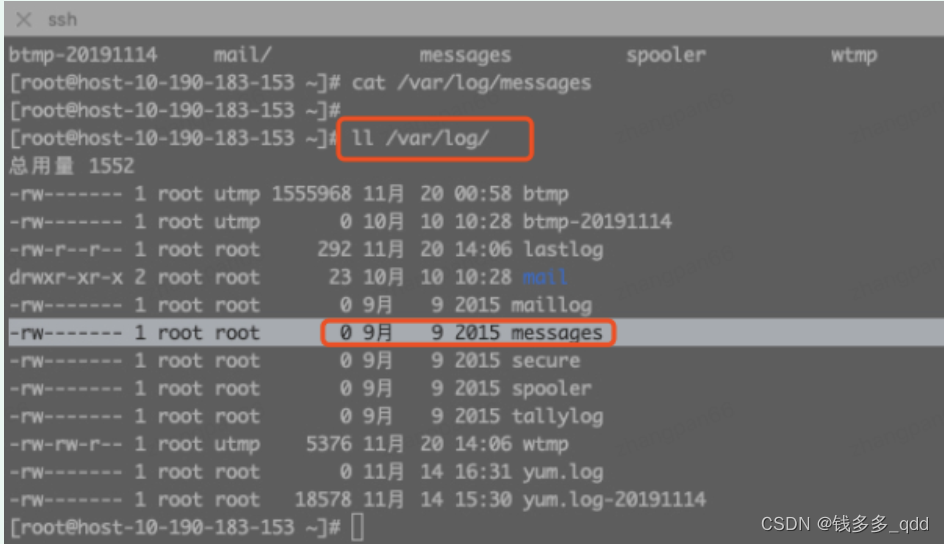
查看内核日志:
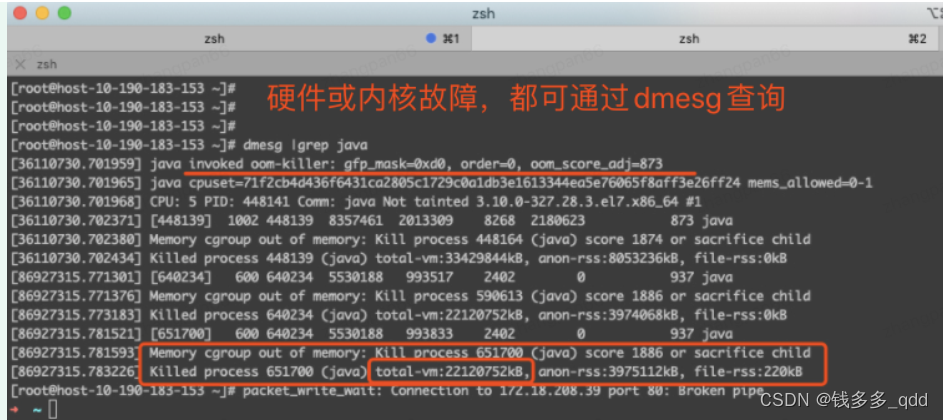
dmesg输出信息有调用oom-killer,但是从内存来看貌似是宿主机的(totalvm:22120752kB),时间点无法确定;
联系运维查询:
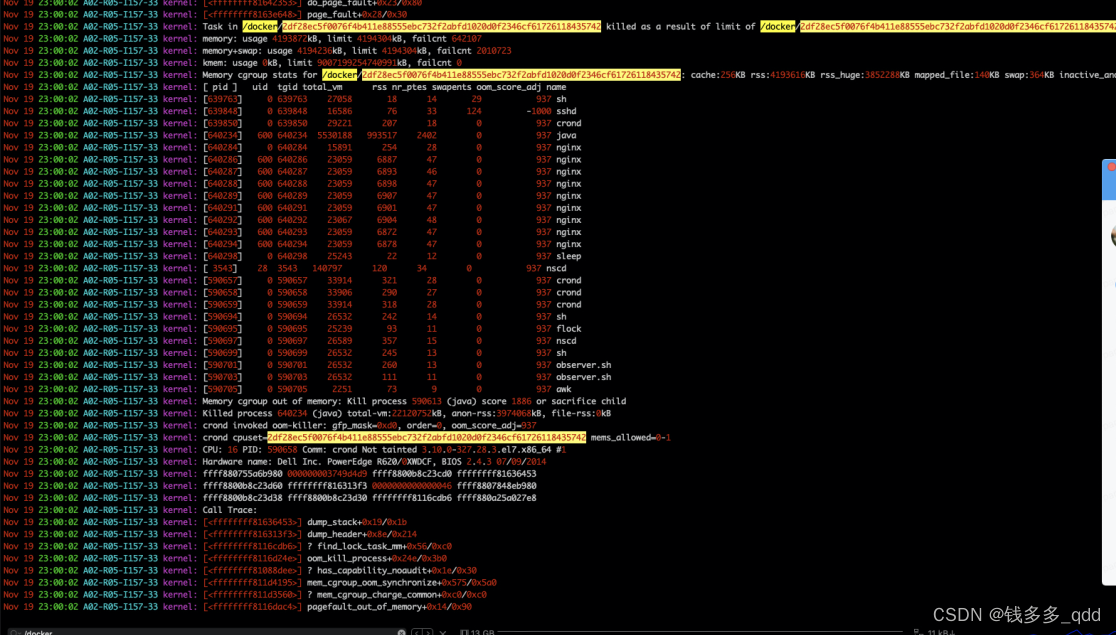
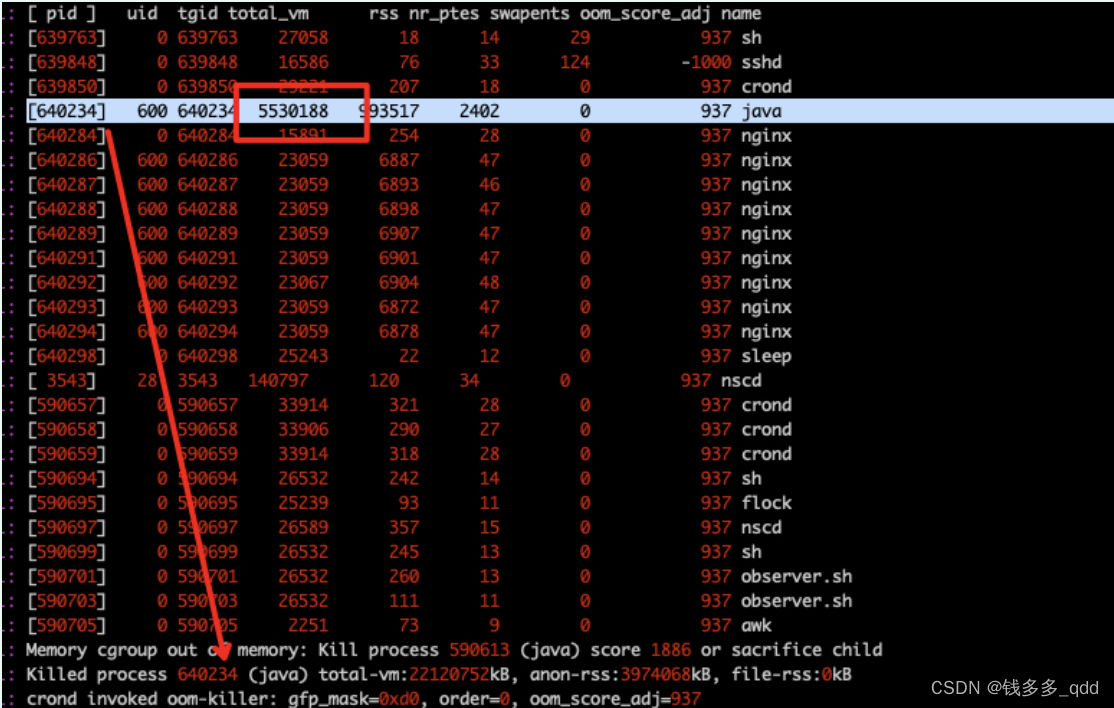
可以确定JVM是被操作系统oom killer干掉了。
问题:docker规格4c4g,为何java进程会占用5.2g?
jdk1.8及之前,JVM是感知不到容器的存在的,所以会使用宿主机的信息来计算,docker -m参数一般用来限制应用内存大小,跟镜像版本也有很大关系,有的版本限制的差不多相当于物理内存的 百分之50。
模拟:OOMKilled
九、其他
上面两个案例说明一个问题:遇见jvm异常退出,先找dump文件,dump如果没有,找hs_err_pid.log日志。如果还没有,翻内核日志。
jvm建议配置:
以8G内存为例:
1-垃圾回收器的参数
2-元空间需要配?512,350
3-堆内存最大最小?4G
4-栈大小?512k
5-直接物理内存?
6-GC日志
不建议配置的: 各个区域的比例,默认值。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- frp内网穿透
- 2024苹果手机iOS管理软软件iMazing2.17永久免费版下载教程
- Spring Boot 2.6 以上整合 Swagger + Knife4j 报错
- 调整几行代码,接口吞吐提升 10 倍,性能调优妙啊!
- docker-compose cadvisor
- ES安全重启
- python中元组应用场景
- visual studio 2022在查找和替换使用正则表达式查找if()
- ubuntu opengl安装使用
- chapter5-使用网页爬虫取利器—Requests