【时序预测】 1、prophet:Forecasting at Scale 论文
文章目录
https://otexts.com/fpp3/
https://facebook.github.io/prophet/ 是 meta 开源的时序预测框架,可用 python 和 R 实现
论文地址: https://peerj.com/preprints/3190/#

规模化预测
预测是一项常见的数据科学任务,可帮助组织进行容量规划、目标设置和异常检测。尽管它很重要,但在产生可靠和高质量的预测方面存在着严峻的挑战–特别是在存在各种时间序列的情况下,具有时间序列建模专业知识的分析师相对较少。为了应对这些挑战,我们描述了一种“大规模”预测的实用方法,该方法将可配置模型与环路分析人员的性能分析相结合。我们提出了一个带有可解释参数的模块回归模型,该模型可以被具有时间序列领域知识的分析师直观地调整。我们描述了性能分析,以比较和评估预测程序,并自动标记预测以供手动审查和调整。帮助分析师最有效地利用其专业知识的工具能够对业务时间序列进行可靠、实用的预测。
一、介绍
预测是一项数据科学任务,是组织内许多活动的核心。例如,行业所有部门的组织都必须参与能力规划,以便有效地分配稀缺资源和设定目标,以便衡量相对于基线的绩效。无论是对机器还是对大多数分析师来说,产生高质量的预测都不是一个容易的问题。
首先,完全自动的预测技术可能很难调整,而且往往过于僵化,无法纳入有用的假设或启发式方法。其次,整个组织中负责数据科学任务的分析师通常对他们支持的特定产品或服务拥有深厚的领域专业知识,但通常没有接受过时间序列预测方面的培训。因此,能够做出高质量预测的分析师相当罕见,因为预测是一项需要大量经验的专业技能。
其结果是,对高质量预测的需求往往远远超过了它们的制作速度。这一观察结果是我们在这里提出的研究的动机-我们打算为产生规模的预测提供一些有用的指导,针对几个规模概念。
在第3节中,我们介绍了一个时间序列模型,该模型对于广泛的业务时间序列足够灵活,但可以由非专家配置,他们可能对数据生成过程具有领域知识,但对时间序列模型和方法知之甚少。
我们解决的第三种类型的规模是,在最现实的设置中,将创建大量预测,这就需要高效、自动化的手段来评估和比较它们,以及检测它们可能表现不佳的时间。当做出成百上千个预测时,让机器完成模型评估和比较的繁重工作,同时高效地使用人工反馈来解决性能问题就变得很重要。
在第4节中,我们描述了一个预测评估系统,它使用模拟的历史预测来估计样本外的性能,并确定有问题的预测,以便人类分析师了解哪里出了问题,并进行必要的模型调整。
值得注意的是,我们并没有把重点放在规模方面的典型考虑:计算和存储。我们发现,预测大量时间序列的计算和基础设施问题相对简单-通常这些拟合过程很容易并行化,预测并不难存储在关系数据库中。
我们在图1中总结了我们的环路分析师方法来进行大规模的业务预测。然后,我们为该模型和一组跨越各种历史模拟预测日期的合理基线生成预测,并对预测性能进行评估。当预测的表现不佳或其他方面需要人工干预时,我们会按优先顺序将这些潜在问题标记给人类分析师。然后,分析师可以检查预测,并可能根据该反馈调整模型。

在Facebook上创建的事件数。每一天都有一个点,点按星期几用颜色编码,以显示每周的周期。这一时间序列的特征代表了许多商业时间序列:多重强烈的季节性、趋势变化、异常值和假日效应。
二、商业时序数据的特征
业务预测问题多种多样,但其中许多问题都有一些共同的特点。图2示出了Facebook事件的代表性Facebook时间序列。Facebook用户能够使用Events平台为活动创建页面,邀请他人,并以各种方式与活动互动。图2显示了Facebook上创建的事件数量的每日数据。在这个时间序列中,有几个明显的季节性影响:每周和每年的周期,以及圣诞节和新年前后的明显下降。这些类型的季节性影响是自然产生的,并且可以在人类行为产生的时间序列中预期。时间序列还显示了过去六个月的明显趋势变化,这种变化可能出现在受新产品或市场变化影响的时间序列中。最后,真实数据集通常具有异常值,此时间序列也不例外。
这一时间序列提供了一个有用的例子,说明了用全自动方法产生合理预测的困难。图3示出了使用来自R中的预报包的几个自动化程序的预报,预测是在历史上的三个时间点进行的,每个预测只使用该时间点之前的时间序列部分来模拟在该日期进行预测。图中的方法是:
- Auto.arima,它适合一系列 ARIMA 模型并自动选择最好的一个;
- ETS,它匹配一组指数平滑模型并选择最好的(Hyndman等人。2002年);
- Snaive,一种随机游走模型,根据每周季节性(季节性幼稚)进行持续预测;
- 以及Tbats,一种具有每周和年度季节性的TBATS模型(de Liva等人)。2011年)
图3中的方法通常很难产生符合这些时间序列特征的预测。
- 当趋势在接近截止期时发生变化,并且不能捕捉到任何季节性时,自动ARIMA预测容易出现较大的趋势误差。
- 指数平滑和季节性天真的预测捕捉到了每周的季节性,但错过了较长期的季节性。
- 所有的方法都对年终下降反应过度,因为它们没有对年度季节性进行充分的建模。
当预测不佳时,我们希望能够根据手头的问题调整方法的参数。调整这些方法需要彻底了解基本的时间序列模型是如何工作的。例如,自动ARIMA的第一个输入参数是差分、自回归分量和移动平均分量的最大阶数。。一个典型的分析师不知道如何调整这些订单以避免图3中的行为–这是一种很难衡量的专业知识类型。
三、Prophet 预测模型
我们现在描述一个时间序列预测模型,该模型旨在处理图2中所示的商业时间序列的常见特征。重要的是,它还被设计为具有直观的参数,可以在不知道底层模型的细节的情况下进行调整。这对于分析师有效地调整模型是必要的,如图1所示。
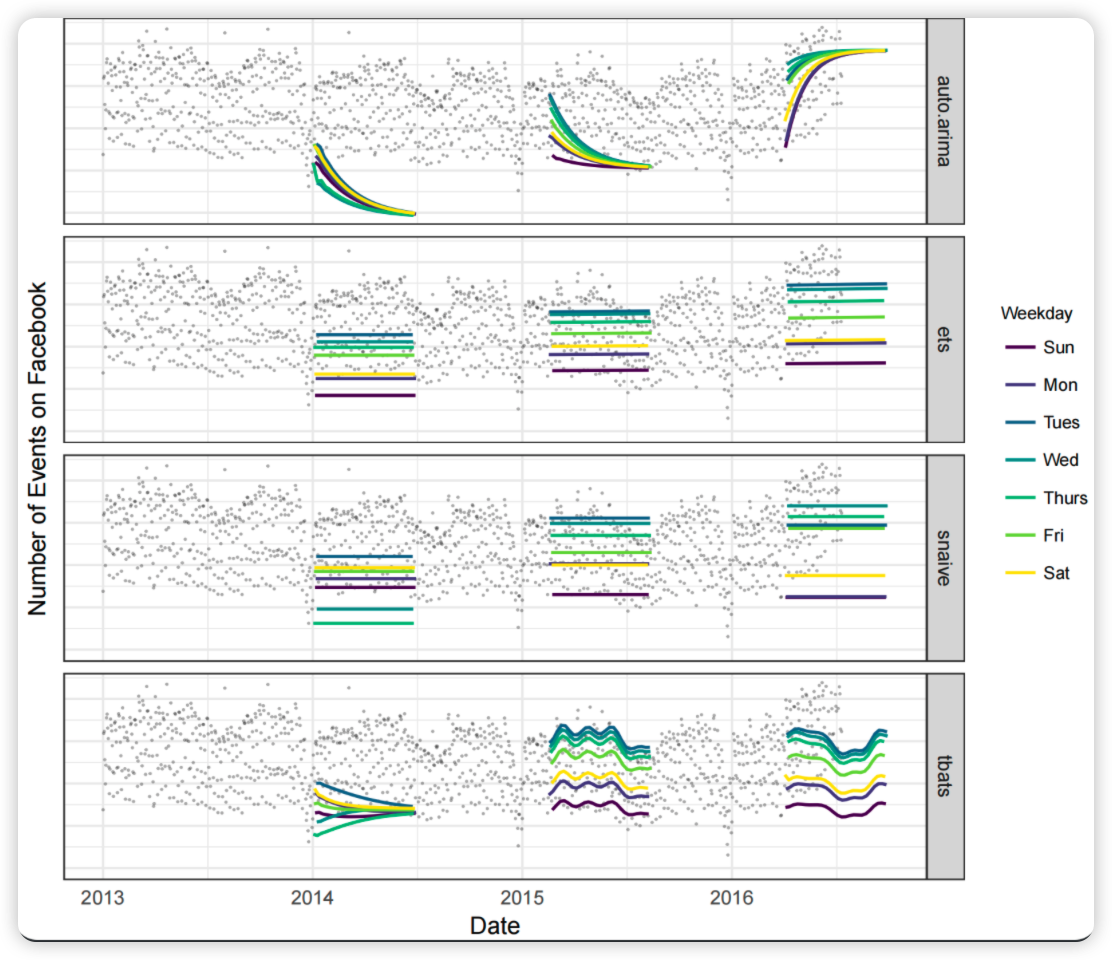
图3:使用一组自动预测程序对图2中的时间序列进行预测。预测是在历史上的三个说明性时间点做出的,每一个都只使用了到那时为止的时间序列的一部分。每一天的预报都按星期几分组和着色,以直观地显示每周的季节性。我们在绘图过程中删除了离群值,以便在图中留出更多垂直空间。
我们使用一个可分解的时间序列模型(Harvey & Peters 1990),该模型有三个主要组成部分:趋势,季节性和假期。它们在以下等式中组合:
y(t) = g(t) + s(t) + h(t) + t .
这里、g(T)是对时间序列的值的非周期性变化进行建模的趋势函数、S(T)表示周期性变化(例如,每周和每年的季节性),以及h(T)表示在一天或多天期间以潜在的不规则时间表发生的假期的影响.误差项t表示模型不能考虑的任何特殊变化;稍后我们将假设t是正态分布的.
这一规范类似于广义加性模型(GAM)(Hastie&Tibishani 1987),这是一类回归模型,对回归变量应用潜在的非线性光滑器。在这里,我们只使用时间作为回归变量,但可能使用时间的几个线性和非线性函数作为分量。将季节性作为一个附加成分建模与指数平滑的方法相同(Gardner,1985)。乘性季节性,其中季节效应是乘以g(T)的因子,可以通过对数变换来实现。
GAM配方的优点是,它很容易分解,并在必要时适应新的成分,例如在确定新的季节性来源时。GAM也可以非常快地适应,要么使用回溯,要么使用L-BFGS(Byrd等人)。1995)(我们更喜欢后者),以便用户可以交互地改变模型参数。
实际上,我们将预测问题框定为曲线拟合练习,这与明确说明数据中的时间相关性结构的时间序列模型有本质上的不同。虽然我们放弃了使用生成模型(如ARIMA)的一些重要推理优势,但此公式提供了许多实用优势:
- 灵活性:我们可以很容易地适应多个时期的季节性,让分析师对趋势做出不同的假设。
- 与ARIMA模型不同,测量值不需要规则地间隔,我们也不需要插入缺失值,例如通过去除异常值。
- 拟合速度非常快,允许分析师交互地探索许多模型规格,例如在应用程序中(Chang等人。2015年)
- 预测模型具有易于解释的参数,分析师可以更改这些参数以对预测施加假设。此外,分析师通常具有回归方面的经验,并且能够轻松地扩展模型以包括新的组件。
自动预测有很长的历史,有许多方法是为特定类型的时间序列量身定做的(Tashman&Leach 1991,de Gooijer&Hyndman 2006)。我们的方法既受到我们在Facebook预测的时间序列的性质(分段趋势、多个季节性、浮动假期)的推动,也受到大规模预测所涉及的挑战的推动。
3.1 趋势模型
我们已经实现了两个涵盖许多Facebook应用程序的趋势模型:饱和增长模型和分段线性模型。
3.1.1非线性饱和增长
对于增长预测,数据生成过程的核心部分是人口如何增长以及预计人口将如何继续增长的模型。Facebook的增长建模通常类似于自然生态系统中的人口增长。在承载能力饱和的情况下,存在非线性增长。例如,特定地区Facebook用户数量的承载能力可能是可以访问互联网的人数。这种增长通常使用逻辑增长模型建模,其最基本的形式是
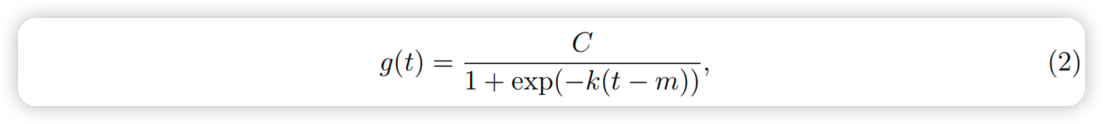
其中C是承载能力,k是增长率,m是偏移参数。
Facebook有两个重要的增长方面没有在(2)中得到体现。
- 首先,承载能力并不是一成不变的–随着世界上接入互联网的人数的增加,增长上限也在增加。因此,我们将固定容量C替换为时变容量C(T)。
- 其次,增长速度并不是恒定的。新产品可以深刻地改变一个地区的增长率,因此该模型必须能够纳入不同的增长率,以便与历史数据相吻合。
我们通过明确定义允许增长率变化的变化点,将趋势变化纳入增长模型。假设在 Sj 序列中有 S 个变化点 j = 1,…S。我们定义了一个增长率向量

每一项,Sj 序列的每一项都是一个增长率。任意时间点的增长率 = 基准增长率 k + 截止改点的变化值之和。

我们模型中的一组重要参数是C(T),即系统在任何时间点的预期容量。分析师通常对市场规模有洞察力,并可以相应地设定这些规模。也可能有外部数据来源可以提供承载能力,例如来自世界银行的人口预测。
这里提出的Logistic增长模型是广义Logistic增长曲线的一个特例,它只是单一类型的Sigmoid曲线。将这一趋势模型推广到其他曲线族是很简单的。
3.1.2 含变化点的线性趋势
对于没有呈现饱和增长的预测问题,分段恒定增长率提供了一个简明且往往有用的模型。这里的趋势模型是

3.1.3 自动选择变化点
变化点Sj可以由分析师使用已知的产品发布日期和其他改变增长的事件来指定,或者可以在给定一组候选者的情况下自动选择。使用(3)和(4)中的公式,通过将稀疏优先放在δ上,可以非常自然地完成自动选择。
我们经常指定大量的变化点(例如,对于几年的历史,每个月一个),并使用先前的~δ(0,τ)。参数τ直接控制模型在改变其速率时的灵活性。重要的是,调整δ的稀疏先验对主要增长率k没有影响,因此当τ变为0时,拟合降低到标准(非分段)逻辑增长或线性增长
3.1.4 趋势预测不确定性
当模型外推历史以进行预测时,趋势将具有恒定的速率。我们通过向前扩展生成模型来估计预测趋势中的不确定性。趋势的生成模型是在T个点的历史上有S个变点,每个变点都有一个变化率δj <$Laplace(0,τ)。我们模拟未来的利率变化,通过用从数据推断的方差代替τ来模拟过去的利率变化。在完全贝叶斯框架中,这可以通过τ的分层先验来获得其后验,否则我们可以使用速率尺度参数的最大似然估计。
未来变化点的随机采样方式是使变化点的平均频率与历史记录中的频率匹配:
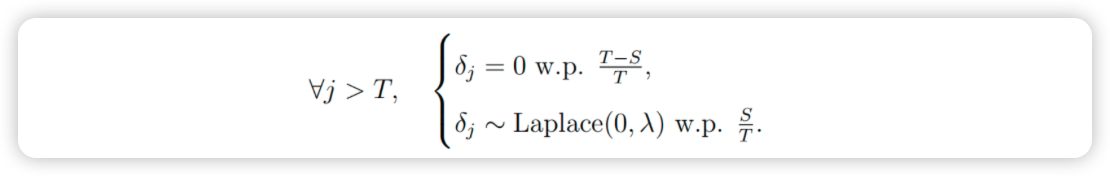
因此,我们通过假设未来利率变化的平均频率和幅度与历史上相同,来衡量预测趋势中的不确定性。一旦从数据中推断出λ,我们就使用这个生成性模型来模拟可能的未来趋势,并使用模拟的趋势来计算不确定区间。
假设趋势将继续以与历史上相同的频率和幅度变化,这一假设相当强烈,因此我们预计不确定性区间不会有确切的覆盖范围。然而,它们是不确定性水平的有用指标,尤其是过度匹配的指标。随着τ的增加,该模型在拟合历史方面具有更大的灵活性,因此训练误差将会下降。然而,当预测向前时,这种灵活性将产生较宽的不确定区间
3.2 季节性
由于所代表的人类行为,商业时间序列通常具有多时段季节性。例如,一周工作5天可能会对每周重复的时间序列产生影响,而假期安排和学校休息可能会产生每年重复的影响。为了拟合和预测这些影响,我们必须指定季节性模型,它们是t的周期函数。
我们依靠傅立叶级数来提供一个灵活的周期效应模型(Harvey & Shephard 1993)。设P是我们期望时间序列具有的规则周期(例如,当我们以天为单位缩放时间变量时,年数据的P = 365.25或周数据的P = 7)。我们可以近似任意平滑的季节效应,

在N处截断序列会对季节性应用低通滤波,因此增加N可以适应变化更快的季节模式,尽管过度拟合的风险会增加。对于每年和每周的季节性,我们发现N=10和N=3分别适用于大多数问题。这些参数的选择可以使用诸如AIC的模型选择过程自动进行。
3.3 节假日和事件
假日和事件对许多商业时间序列提供了较大的、在某种程度上可以预测的冲击,而且往往不遵循周期性模式,因此它们的影响不能很好地用平稳周期建模。例如,美国的感恩节在11月的第四个星期四。超级碗是美国最大的电视转播赛事之一,在1月或2月的一个周日举行,很难通过程序宣布。世界上许多国家的主要节日都在农历之后。特定假期对时间序列的影响往往年复一年地相似,因此将其纳入预测是很重要的。
我们允许分析师提供由事件或假日的唯一名称标识的过去和未来事件的自定义列表,如表1所示。我们包括针对国家/地区的列,以便在全球假日之外保留特定于国家/地区的假日列表。对于给定的预测问题,我们使用全球假日集和特定国家的假日集的联合。
通过假设假期的影响是独立的,将这个假期列表纳入模型变得简单明了。对于每个节日i,让Di成为该节日的过去和未来日期的集合。我们添加了一个指示器函数,表示时间

通常重要的是要包括特定节日前后某几天的影响,例如感恩节周末。为了说明这一点,我们包括了假日周围的其他参数,实质上是将假日周围窗口中的每一天都视为假日本身。
3.4 模型调参
当每个观测的季节性和节假日特征被组合成矩阵X和矩阵A中的变点指示器a(T)时,(1)中的整个模型可以用几行Stan代码来表示(Carpenter et al.对于模型拟合,我们使用斯坦的L-BFGS来找到最大后验估计,但也可以将模型参数不确定性包含在预测不确定性中的完全后验推断。
model {
// Priors
k ~ normal(0, 5);
m ~ normal(0, 5);
epsilon ~ normal(0, 0.5);
delta ~ double_exponential(0, tau);
beta ~ normal(0, sigma);
// Logistic likelihood
y ~ normal(C ./ (1 + exp(-(k + A * delta) .* (t - (m + A * gamma)))) +
X * beta, epsilon);
// Linear likelihood
y ~ normal((k + A * delta) .* t + (m + A * gamma) + X * beta, sigma);
}
图4显示了对图3的Facebook事件时间序列的预测模型。这些预测是在与图3相同的三个日期做出的,与之前一样,只使用该日期之前的数据进行预测。Prophet预测能够预测每周和每年的季节性,并且与图3中的基线不同,它不会对第一年的假期下降反应过度。在第一个预测中,由于只有一年的数据,Prophet模型略微超过了年度季节性。在第三次预测中,模型尚未了解到趋势发生了变化。图5显示包含最近三个月数据的预测显示趋势变化(虚线)。
可分解模型的一个重要好处是,它允许我们分别查看预测的每个组成部分。图6显示了与图4中最后一次预测相对应的趋势、每周季节性和年度季节性分量。这为分析师提供了一个有用的工具来洞察他们的预测问题,而不仅仅是生成预测。
清单1中的参数tau和sigma是正则化量的控制


图5:使用所有可用数据的先知预测,包括历史数据的内插。实线是样本内拟合,虚线是样本外预测。

对模型的变点和季节性分别进行分析。正则化对于这两种方法都很重要,以避免过度拟合,然而可能没有足够的历史数据来通过交叉验证来选择最佳正则化参数。我们设置了适用于大多数预测问题的缺省值,当需要优化这些参数时,分析师会参与其中
3.5 业务分析师在环(共同参与)建模
做出预测的分析师通常对他们预测的数量有广泛的领域知识,但统计知识有限。在Prophet模型规范中,分析师可以在几个地方更改模型,以应用他们的专业知识和外部知识,而不需要了解任何基本的统计数据。
- 能力上限:分析师可能有关于市场总规模的外部数据,并可以通过指定能力直接应用这些知识。
- 更改点:可以直接指定已知的更改点日期,如产品更改日期。
- 节假日和季节性:与我们合作的分析师了解哪些节假日会影响哪些地区的增长,他们可以直接输入相关的节假日日期和适用的季节性时标。
- 平滑参数:通过调整τ,分析师可以从更全局或更局部平滑的模型范围内进行选择。季节性和假日平滑参数(σ,ν)允许分析师告诉模型未来预期的历史季节性变化的程度
借助良好的可视化工具,分析师可以使用这些参数来改进模型拟合。当在历史数据上绘制模型拟合时,自动变点选择是否遗漏了变点,这一点很快就会显现出来。τ参数是一个单一的旋钮,可以转动它来增加或减少趋势的灵活性,σ是一个旋钮来增加或减少季节性分量的强度。可视化为富有成效的人工干预提供了许多其他机会:线性趋势或逻辑增长,识别季节性的时间尺度,以及识别应该从拟合中删除的外围时间段。所有这些干预都可以在没有统计专业知识的情况下进行,并且是分析师应用其见解或领域知识的重要方法。
预测文献通常区分统计预测和判断预测(也称为管理预测),统计预测是基于历史数据拟合的模型,而判断预测(也称为管理预测)是人类专家使用他们所学到的任何过程来产生的,这些过程往往适用于特定的时间序列。这些方法中的每一种都有其优点。统计预测需要较少的领域知识和人工预测的努力,并且可以很容易地扩展到许多预测。判断性预测可以包含更多的信息,并对不断变化的条件做出更好的反应,但可能需要分析师进行密集的工作(Sanders 2005)。
我们的分析师在环建模方法是一种替代方法,试图通过在必要时将分析师的努力集中在改进模型上,而不是通过一些未说明的程序直接产生预测,从而融合统计和判断预测的优势。我们发现,我们的方法非常类似于“变换可视化Wickham & Grolemund(2016)提出的“模型”循环,其中人类领域知识在一些迭代之后,边缘被编码在改进的模型中。
预测的典型规模将依赖于完全自动化的程序,但评判性预测已被证明在许多应用程序中高度准确(Lawrence等人)。2006)。我们建议的方法允许分析师通过一小部分直观的模型参数和选项对预测进行判断,同时保留在必要时依靠全自动统计预测的能力。在撰写本文时,我们只有一些轶事般的经验证据,可以证明准确度可能有所提高,但我们期待着未来的研究,这些研究可以评估分析师在模型辅助环境下可以获得的改善。
在规模上拥有分析师的能力至关重要地依赖于对预测质量的自动评估和良好的可视化工具.我们现在描述如何自动进行预测评估,以确定与分析师输入最相关的预测.
4 预测评估的自动化
在本部分中,我们概述了通过比较各种方法并确定可能需要人工干预的预测来自动进行预测绩效评估的过程。本部分与所使用的预测方法无关,包含了我们在各种应用程序中发布生产业务预测时确定的一些最佳实践。
4.1基线预测的使用
在评估任何预测程序时,将其与一套基线方法进行比较是很重要的。我们更喜欢使用简单化的预测,对潜在的过程做出强有力的假设,但这在实践中可以产生合理的预测。我们发现比较简单化的模型(最后的值和样本平均值)以及第2节中描述的自动预测程序是有用的。
4.2建模预测精度
预测是在一定的范围内进行的,我们将其表示为H。范围是我们关心预测的未来天数-在我们的应用程序中,这通常是30天、90天、180天或365天。因此,对于任何有每日观测的预报,我们对未来状态的估计高达H个,每个估计都与一些误差有关。我们需要宣布一个预测目标,以比较方法和跟踪性能。此外,了解我们的预测程序有多容易出错,可以让业务环境中的预测消费者决定是否完全信任它。
设误差y(t|T)表示用到时间T历史信息作出的对时间t的预测,d(y,y0)是诸如平均绝对误差d(y,y0)=|y?y0|的距离度量。距离函数的选择应该是特定于问题的。De Gooijer和Hyndman(2006)回顾了几个这样的误差度量–在实践中,我们更喜欢平均绝对百分比误差(MAPE)作为其可解释性。我们将时间T之前的h∈(0,H]个周期的预测的经验精度定义为:
为了形成对这种精度及其随h变化的估计,通常为误差项指定参数模型并从数据中估计其参数。例如,如果我们使用的是AR(1)模型,y(T)=?y(t~1)+α+β(T),我们将假设ν(T)为ν(T)α+β(0,ν2),并集中于从数据估计方差项ν2。然后,我们可以通过模拟使用任何距离函数或通过使用误差总和的期望的解析表达式来形成期望。不幸的是,这些方法只有在为流程指定了正确的模型的条件下才能给出正确的误差估计–这一条件在实践中不太可能成立。
我们倾向于采用非参数方法来估计适用于所有模型的预期误差。这种方法类似于应用交叉验证来估计对I.I.D.进行预测的模型的样本外误差。数据。在给定一组历史预测的情况下,我们拟合出在不同预测水平h下的预期误差模型:

这个模型应该是灵活的,但可以强加一些简单的假设。首先,函数应该在h中局部光滑,因为我们希望在连续几天犯下的任何错误都相对相似。其次,我们可以强加这样的假设,即函数应该在h中弱递增,尽管不是所有预测模型都是这样。在实践中,我们使用局部回归(Cveland&Devlin 1988)或保序回归(Dykstra 1981)作为误差曲线的灵活的非参数模型。
为了生成历史预测误差来拟合这个模型,我们使用了一个我们称之为模拟历史预测的过程。
4.3 模拟历史预测
我们想要拟合(8)中的预期误差模型来进行模型选择和评估。不幸的是,很难使用像交叉验证这样的方法,因为观测数据是不可交换的-我们不能简单地随机划分数据。
我们使用模拟历史预报(SHF),通过在历史的不同截止点产生K个预报,选择这样的方法,即地平线位于历史范围内,并且可以评估总误差。这一程序基于经典的“滚动起源”预报评估程序(Tashman 2000),但只使用一小段截止日期,而不是对每个历史日期进行一次预报。使用较少模拟日期(滚动原点评估每个日期产生一个预报)的主要优点是,它节省了计算,同时提供相关性较小的精度测量。
如果我们在过去的那些时间点使用这种预测方法,SHF模拟了我们可能会犯的错误。图3和图4中的预测是SHF的例子。这种方法的优点是简单,很容易向分析师和决策者解释,在生成对预测误差的洞察方面相对没有争议。在使用SHF方法评估和比较预测方法时,需要注意两个主要问题。
首先,我们做出的模拟预测越多,它们对误差的估计就越相关。在历史上每一天的模拟预报的极端情况下,如果增加一天的信息,预报不太可能发生太大变化,而且每一天的误差几乎相同。另一方面,如果我们做出很少的模拟预测,那么我们作为模型选择基础的历史预测错误的观测值就会更少。作为启发式,对于一个预报时段H,我们通常每隔H/2周期进行一次模拟预报。尽管相关估计不会在我们对模型精度的估计中引入偏差,但它们确实产生的有用信息较少,并减缓了预测评估。
其次,随着数据的增多,预测方法的表现可能更好,也可能更差。当模型被错误指定时,较长的历史可能会导致较差的预测,而我们正在过度拟合过去,例如,使用样本平均值来预测具有趋势的时间序列。
图7显示了我们对于图3和图4的时间序列的函数ξ(H)的估计,即在使用黄土的整个预测期内的预期平均绝对百分比误差。该估计是使用九个模拟预测日期进行的,第一年之后每季度一个。在所有预测范围内,Prophet的预测误差都较低。Prophet预测是使用默认设置进行的,调整参数可能会进一步提高性能。
在可视化预测时,我们更喜欢使用点而不是线来表示历史数据,因为这些数据表示的是从未内插的精确测量。然后,我们用预报覆盖各行。对于SHF,将模型在不同水平上的误差可视化是有用的,既可以作为时间序列(如图3),也可以在SHF上聚合(如图7)。
即使对于单个时间序列,SHF也需要计算多个预测,并且在规模上,我们可能希望在许多不同的聚合级别预测许多不同的指标。只要这些计算机可以写入相同的数据存储,就可以在不同的计算机上独立计算SHF。我们将预测和相关误差存储在配置单元或MySQL中,具体取决于它们的预期用途。
4.4 识别较大的预测错误
当有太多的预测让分析师无法手动检查时,能够自动识别可能有问题的预测是很重要的。自动识别糟糕的预测使分析师能够最有效地利用他们有限的时间,并利用他们的专业知识来纠正任何问题。有几种方法可以使用SHF来识别预测中可能存在的问题。
- 当预测相对于基线有较大误差时,可能会错误指定模型。分析师可以根据需要调整趋势模型或季节性。
- 在某一特定日期,所有方法的大误差都暗示着异常值。分析师可以识别异常值并将其移除。
- 当方法的SHF误差从一个截止点到下一个截止点急剧增加时,可能表明数据生成过程发生了变化。添加变化点或分别对不同阶段建模可能会解决该问题。
有些病态是不容易纠正的,但我们遇到的大多数问题都可以通过指定变化点和移除离群值来纠正。一旦标记了预测以供查看和可视化,就很容易识别和纠正这些问题
5 结论
大规模预测的一个主要主题是,具有不同背景的分析师必须做出比手动预测更多的预测。我们预测系统的第一个组成部分是我们在Facebook通过多次迭代预测各种数据而开发的新模型。我们使用简单的模块化回归模型,该模型通常与默认参数配合良好,允许分析师选择与其预测问题相关的组件,并根据需要轻松进行调整。第二个组成部分是一个衡量和跟踪预测准确性的系统,并标记应该手动检查的预测,以帮助分析师进行渐进的改进。这是一个关键的组成部分,使分析师能够确定何时需要对模型进行调整,或者何时可能适合完全不同的模型。简单、可调整的模型和可扩展的性能监控相结合,使大量分析师能够预测大量和各种时间序列-我们认为这是大规模预测。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 深入学习《大学计算机》系列之第1章 1.4节——从二进制起源窥见的奥秘
- Java 线程池参数详解与实战
- Android Studio实现华容道小游戏
- 会议剪影 | 思腾合力受邀出席首届CCF数字医学学术年会
- java反射
- nodejs微信小程序+python+PHP的4s店客户管理系统-计算机毕业设计推荐
- Invalid GeoJSON data provided to function st_geomfromgeojson
- 5G RRU delay 测量(九)
- Vue学习计划-Vue3--核心语法(六)路由
- 【Unity】GPU骨骼动画 渲染性能开挂 动画合批渲染 支持武器挂载