机器学习笔记 - 从2D数据合成3D数据
发布时间:2024年01月03日
一、3D 数据简介
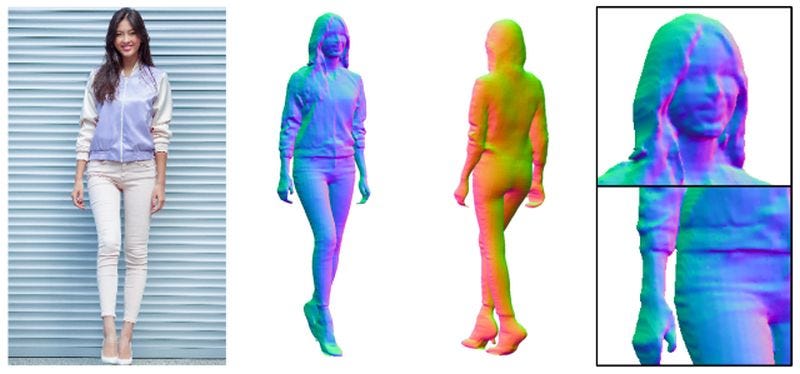
人们一致认为,从单一角度合成 3D 数据是人类视觉的一项基本功能,这对计算机视觉算法来说极具挑战性。但随着 LiDAR、RGB-D 相机(RealSense、Kinect)和 3D 扫描仪等 3D 传感器的可用性和价格的提高,3D 采集技术的最新进展取得了巨大飞跃。
与广泛使用的 2D 数据不同,3D 数据具有丰富的尺度和几何信息,从而为机器更好地理解环境提供了机会。然而,与 2D 数据相比,3D 数据的可用性相对较低,且获取成本较高。因此,最近提出了许多深度学习方法来从可用的 2D 数据合成 3D 数据,而不依赖于任何 3D 传感器。但在深入研究这些方法之前,我们应该了解处理 3D 数据的格式。
文章来源:https://blog.csdn.net/bashendixie5/article/details/134674235
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- windows 部署zlm
- 【精选】Spring思维导图分享,全是干货,思维导图带代码你们见过吗?
- Spirng MVC见解1
- 基于合宙Air700E的4G环境监测节点(温湿度、气压等数据),通过MQTT上传阿里云物联网平台
- Elasticsearch可视化平台Kibana [ES系列] - 第498篇
- ImageJ脚本初步:宏录制
- MySQL中MVCC的流程
- Android亮度调节的几种实现方法
- 阿里云 ACK One Serverless Argo 助力深势科技构建高效任务平台
- 还在用if-else? 用策略模式干掉它