数据结构期末复习(六)查找算法
查找算法
查找算法通常有两种常见的实现方式:顺序查找和二分查找。
- 顺序查找
顺序查找也称为线性查找,是最简单的一种查找算法。它从数据集的起点开始逐个比较每个元素,直到找到目标元素或者搜索到数据集的末尾。
示例代码:
int sequential_search(int arr[], int n, int target) {
for (int i = 0; i < n; i++) {
if (arr[i] == target) {
return i;
}
}
return -1;
}
- 二分查找
二分查找也称为折半查找,是一种针对有序数据集合进行查找的算法。它利用了数据集的有序性,将数据集从中间分为两份,如果目标元素小于中间元素,则在左半部分继续查找,否则在右半部分继续查找,直到找到目标元素或者数据集缩小到只有一个元素为止。
示例代码:
int binary_search(int arr[], int n, int target) {
int left = 0, right = n - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (arr[mid] == target) {
return mid;
} else if (arr[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return -1;
}
其中,left 表示左边界,right 表示右边界,mid 表示中间位置。每次查找都将数据集缩小一半,时间复杂度为 O(log n)。
需要注意的是,二分查找算法只适用于有序的数据集合。




折半查找,也称为二分查找,是一种高效的查找算法,适用于有序数据集合。它通过将数据集从中间进行分割,并与目标元素进行比较,缩小查找范围,直到找到目标元素或者确定目标元素不存在。
折半查找的具体步骤如下:
- 定义左边界
left为数据集的起始位置,右边界right为数据集的末尾位置。 - 计算中间位置
mid,可以使用mid = left + (right - left) / 2或者mid = (left + right) / 2。 - 比较中间位置的元素与目标元素的大小关系:
- 如果中间元素等于目标元素,则返回中间位置作为结果。
- 如果中间元素大于目标元素,则在左半部分继续查找,更新右边界为
mid - 1。 - 如果中间元素小于目标元素,则在右半部分继续查找,更新左边界为
mid + 1。
- 重复步骤 2 和步骤 3,直到左边界大于右边界,表示没有找到目标元素,返回 -1。
以下是一个使用 C 语言实现的折半查找的示例代码:
int binary_search(int arr[], int n, int target) {
int left = 0;
int right = n - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (arr[mid] == target) {
return mid; // 找到目标元素,返回索引
} else if (arr[mid] < target) {
left = mid + 1; // 在右半部分继续查找
} else {
right = mid - 1; // 在左半部分继续查找
}
}
return -1; // 目标元素不存在,返回 -1
}
请注意,折半查找算法要求数据集已经按照升序或降序排列,否则不能保证正确性。此外,折半查找的时间复杂度为 O(log n),是一种高效的查找算法。
散列表
散列表(Hash Table),也被称为哈希表或哈希映射,是一种常见的数据结构,用于实现键值对的存储和查找。它通过将键映射到一个固定大小的数组中,以便快速访问和操作数据。
散列表的核心思想是使用散列函数(Hash Function)将键转换为数组索引。散列函数将键映射到数组中的特定位置,这个位置被称为散列桶(Hash Bucket)或槽位(Slot)。当需要插入、查找或删除元素时,只需通过散列函数计算键的散列值,然后在散列桶中进行操作。
散列函数应该具有以下特性:
- 一致性:对于相同的键,散列函数应该始终返回相同的散列值。
- 均匀性:散列函数应尽可能地将不同的键映射到不同的散列值,以避免冲突。
解决冲突:
由于散列函数的输出空间远远小于输入空间,不同的键可能会映射到相同的散列值,导致冲突。为了解决冲突,通常有以下两种常见的方法:
- 链接法(Chaining):每个散列桶维护一个链表,冲突的元素都存储在链表中。当需要查找时,先通过散列函数计算散列值,然后在对应的链表中顺序查找目标元素。
- 开放地址法(Open Addressing):尝试将冲突的元素存储到其他空闲的散列桶中,而不是使用链表。常见的开放地址法有线性探测、二次探测和双重散列等。
散列表的优点是可以在平均情况下实现快速的插入、查找和删除操作。但是,散列表的性能可能会受到冲突的影响,如果冲突过多,会导致性能下降。因此,在设计散列表时,选择合适的散列函数和解决冲突的方法很重要。
总结一下,散列表是一种基于散列函数的数据结构,用于实现键值对的高效存储和查找。它通过将键映射到数组中的位置来快速定位数据。
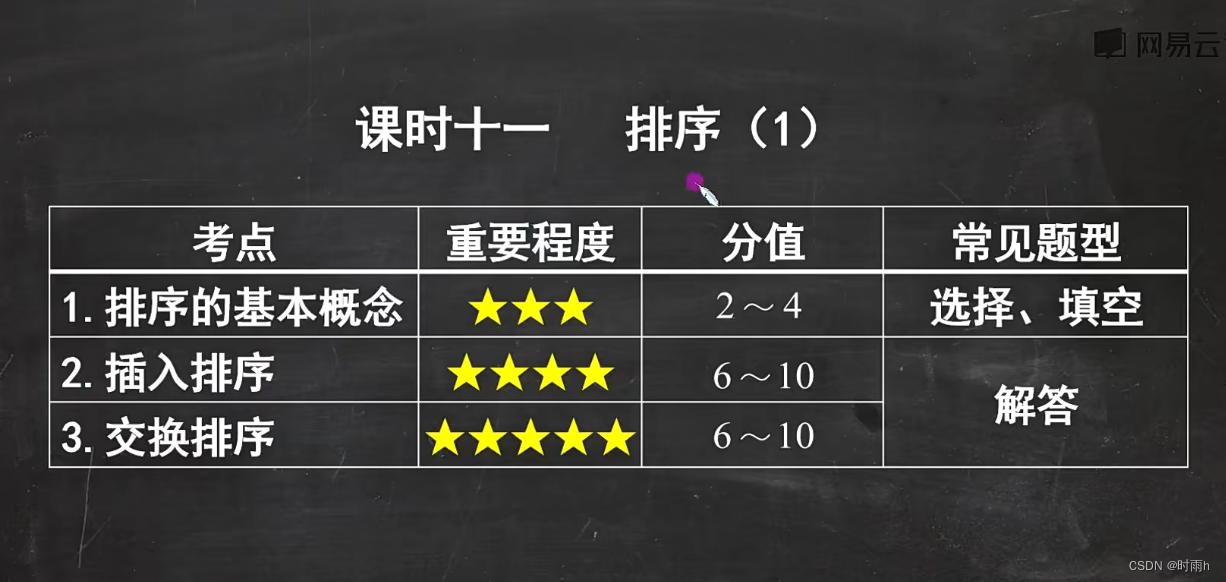
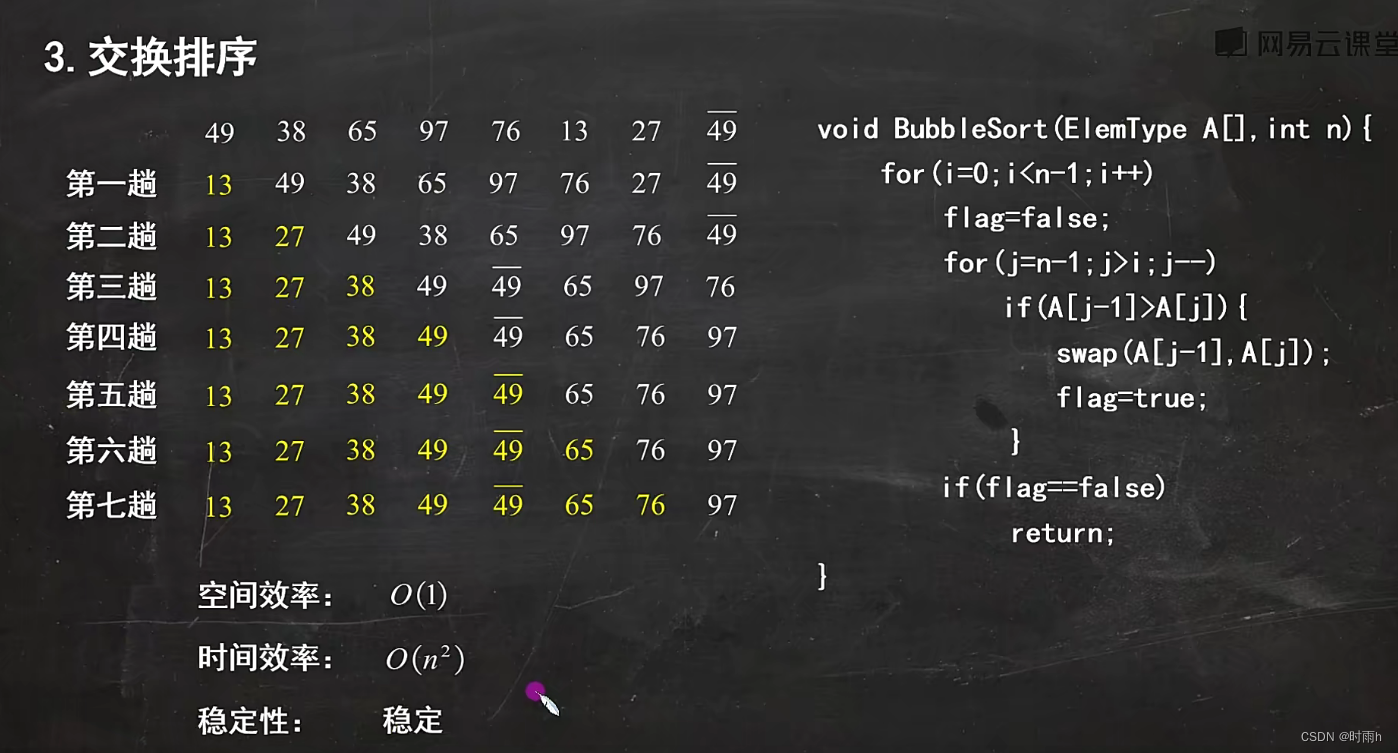
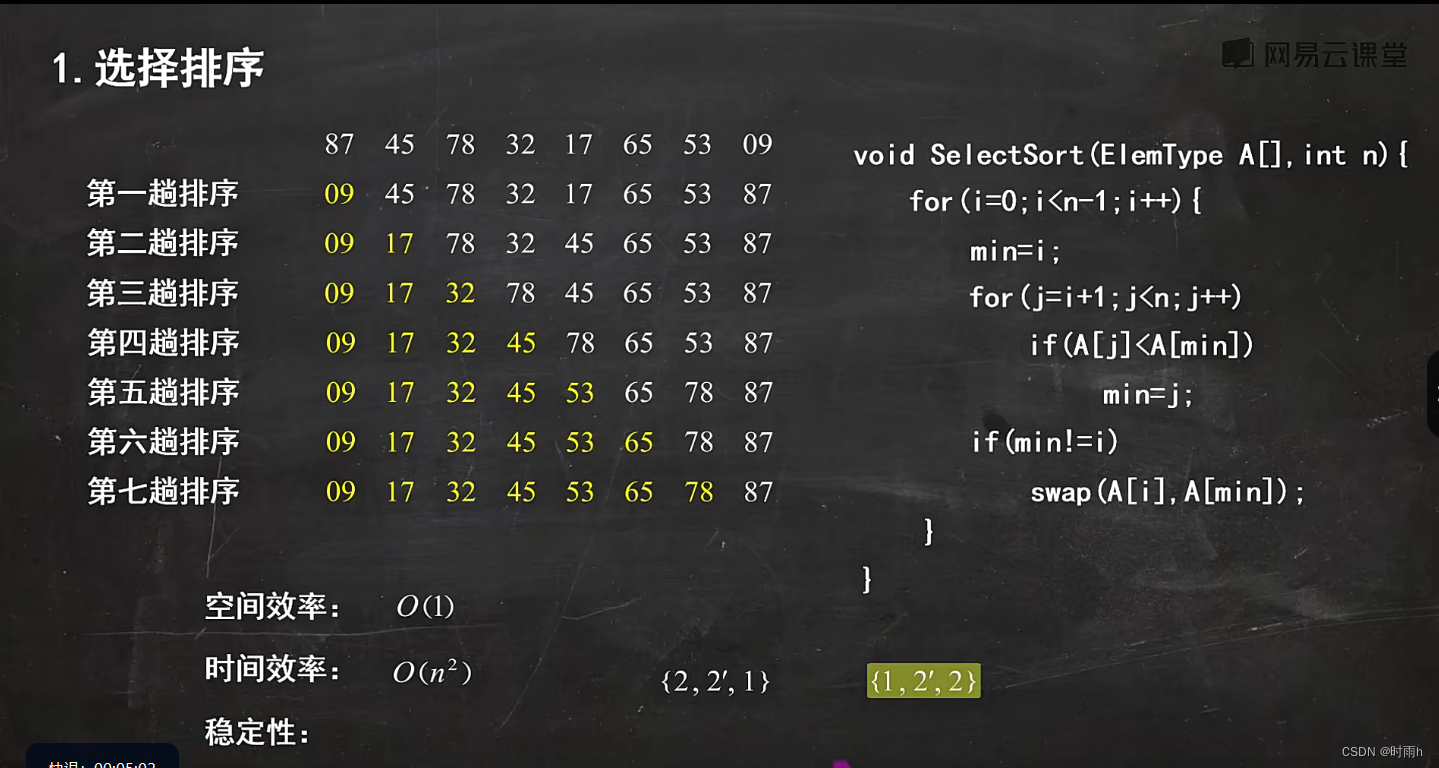
排序


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【C初阶——指针4】鹏哥C语言系列文章,基本语法知识全面讲解——指针(4)
- Find My对讲机|苹果Find My技术与对讲机结合,智能防丢,全球定位
- JVM的内存分区以及垃圾收集
- 吾爱破解置顶的“太极”,太好用了吧!
- Python文件命名规则:批量重命名与规则匹配的文件
- 基于ExoPlayer的缓存方案实现
- 商业印刷市场分析:预计2029年将达到53004亿元
- python3GUI--仿win11风格天气小工具By:PyQt5
- VS2017 搭建opencv工程
- 扩展坞 接两个显示器