模式识别与机器学习(十二):Stacking
发布时间:2023年12月28日
原理
在本次实验中以决策树、svm和随机森林为基学习器,以决策树为元学习器。
Stacking的做法是首先构建多个不同类型的一级学习器,并使用他们来得到一级预测结果,然后基于这些一级预测结果,构建一个二级学习器,来得到最终的预测结果。Stacking的动机可以描述为:如果某个一级学习器错误地学习了特征空间的某个区域,那么二级学习器通过结合其他一级学习器的学习行为,可以适当纠正这种错误。具体步骤如下图所示:

过程1-3 是训练出来个体学习器,也就是初级学习器。
过程5-9 是 使用训练出来的个体学习器来得预测的结果,这个预测的结果当做次级学习器的训练集。
过程11 是用初级学习器预测的结果训练出次级学习器,得到我们最后训练的模型。
但是这样的实现是有很大的缺陷的。在原始数据集D上面训练的模型,然后用这些模型再D上面再进行预测得到的次级训练集肯定是非常好的。会出现过拟合的现象。因此一般通过使用交叉验证法或留一法这样的方式,用训练初级学习器未使用的样本来产生次级学习器的训练样本。以K折交叉为例,具体情况如下图:
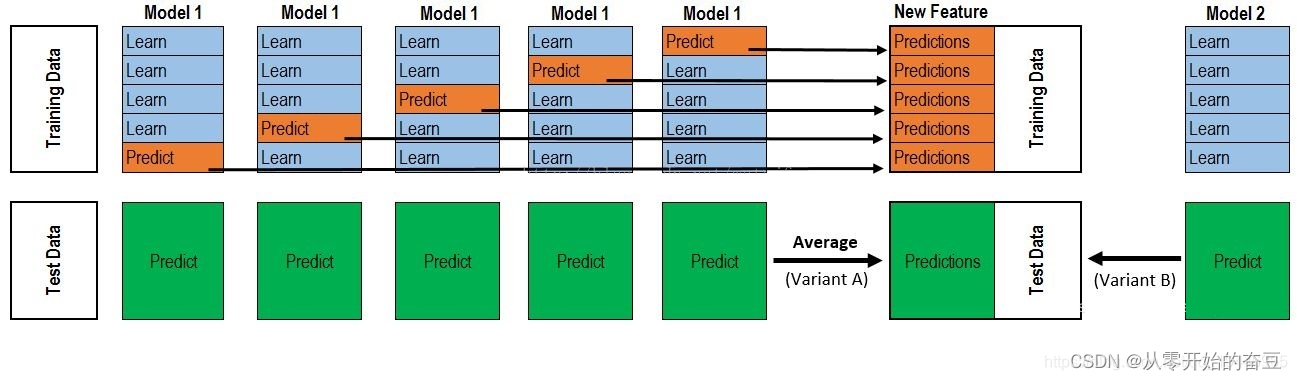
2.代码实现
from sklearn import datasets
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.ensemble import StackingClassifier
# 加载鸢尾花数据集
iris = datasets.load_iris()
X, y = iris.data, iris.target
# 定义基学习器
base_learners = [
('rf', RandomForestClassifier(n_estimators=10, random_state=42)),
('svc', SVC()),
('dt', DecisionTreeClassifier())
]
# 定义元学习器
meta_learner = DecisionTreeClassifier()
# 定义Stacking模型
stacking_model = StackingClassifier(estimators=base_learners, final_estimator=meta_learner, cv=5)
# 训练模型
stacking_model.fit(X, y)
# 预测
y_pred = stacking_model.predict(X)
# 打印预测结果
print(y_pred)
在这个例子中,我们首先加载了鸢尾花数据集,然后定义了三个基学习器:随机森林、SVM和决策树。然后,我们定义了一个决策树作为元学习器。然后,我们使用这些学习器创建了一个Stacking模型,并设置了5折交叉验证。最后,我们训练了模型,并进行了预测。
文章来源:https://blog.csdn.net/m0_68926749/article/details/135255105
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 深度学习(1)--基础概念
- 现代建筑 Modern Design 展示前端界面html推荐
- 线性代数的艺术
- 腾讯云2核2G轻量应用服务器300GB月流量够用吗?
- LangChain 71 字符串评估器String Evaluation衡量在多样化数据上的性能和完整性
- vector
- nodejs学习计划--(一)初始nodejs
- 一起学docker(六)| Dockerfile自定义镜像 + 微服务模块实战
- Leetcode—128.最长连续序列【中等】
- 基于SSM在线协同过滤汽车推荐销售系统