大模型日报-20240110
AI解读视频张口就来?这种「幻觉」难题Vista-LLaMA给解决了
https://mp.weixin.qq.com/s/rsg1c4PnBp9PUEo1ROTkoQ
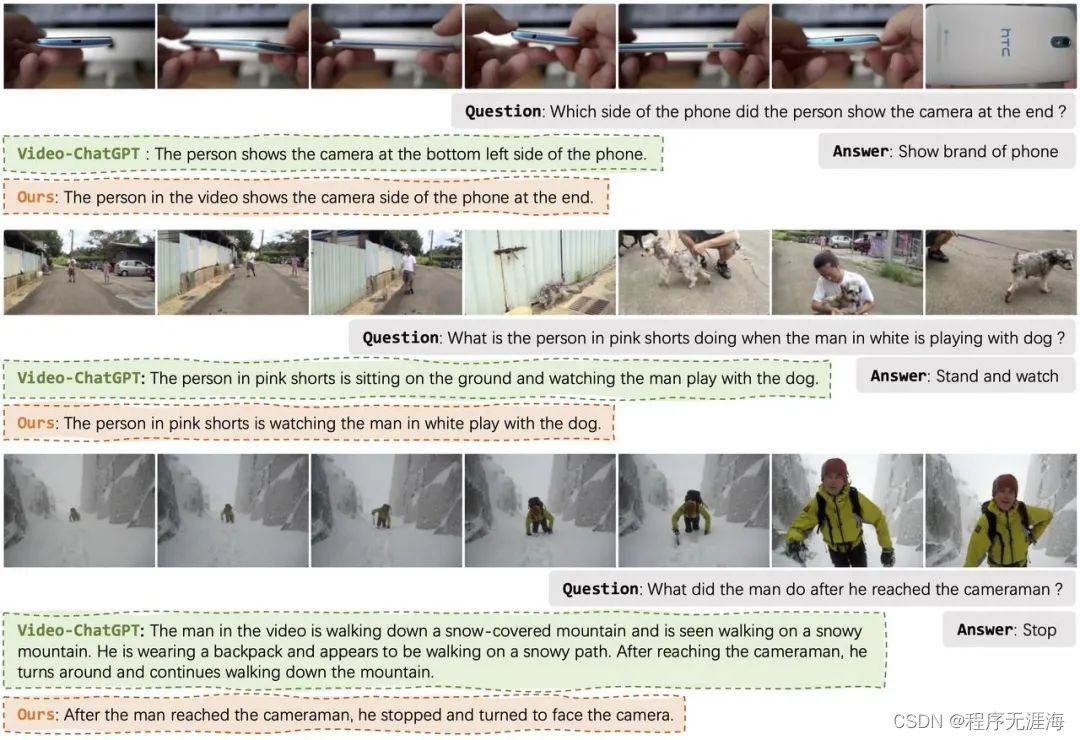
近年来,大型语言模型如 GPT、GLM 和 LLaMA 等在自然语言处理领域取得了显著进展,基于深度学习技术能够理解和生成复杂的文本内容。然而,将这些能力扩展到视频内容理解领域则是一个全新的挑战 —— 视频不仅包含丰富多变的视觉信息,还涉及时间序列的动态变化,这使得大语言模型从视频中提取信息变得更为复杂。面对这一挑战,字节跳动联合浙江大学提出了能够输出可靠视频描述的多模态大语言模型 Vista-LLaMA。Vista-LLaMA 专门针对视频内容的复杂性设计,能够有效地将视频帧转换为准确的语言描述,从而极大地提高了视频内容分析和生成的质量。
告别逐一标注,一个提示实现批量图片分割,高效又准确
https://mp.weixin.qq.com/s/TEqAeqdysPa2cB52J0a32g
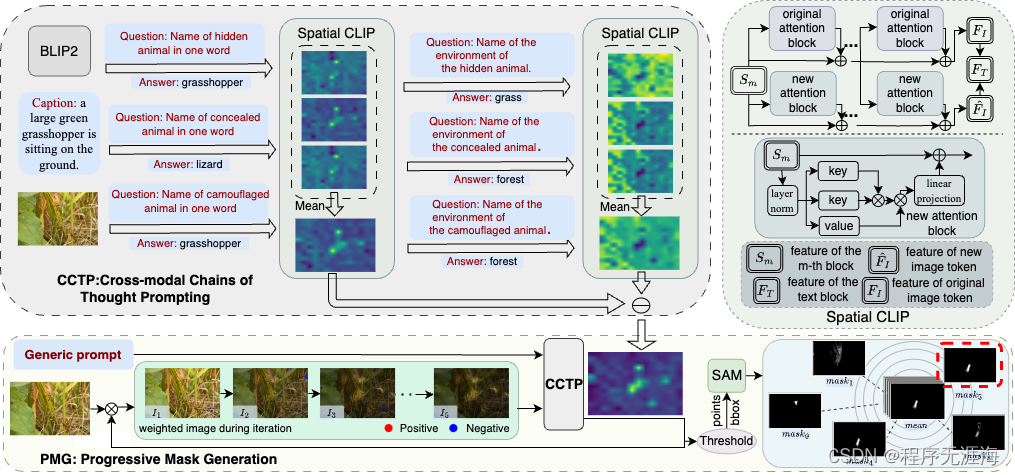
Segment Anything Model (SAM) 的提出在图像分割领域引起了巨大的关注,其卓越的泛化性能引发了广泛的兴趣。然而,尽管如此,SAM 仍然面临一个无法回避的问题:为了使 SAM 能够准确地分割出目标物体的位置,每张图片都需要手动提供一个独特的视觉提示。目前的一些方法,如 SEEM 和 AV-SAM,通过提供更多模态的输入信息来引导模型更好地理解要分割的物体是什么。来自伦敦大学玛丽女王学院的研究者们提出了一种无需训练的分割方法 GenSAM ,能够在只提供一个任务通用的文本提示的条件下,将任务下的所有无标注样本进行有效地分割。
四行代码让大模型上下文暴增3倍,羊驼Mistral都适用
https://mp.weixin.qq.com/s/1fFjy0kc8RcEqQWGFw4QTg
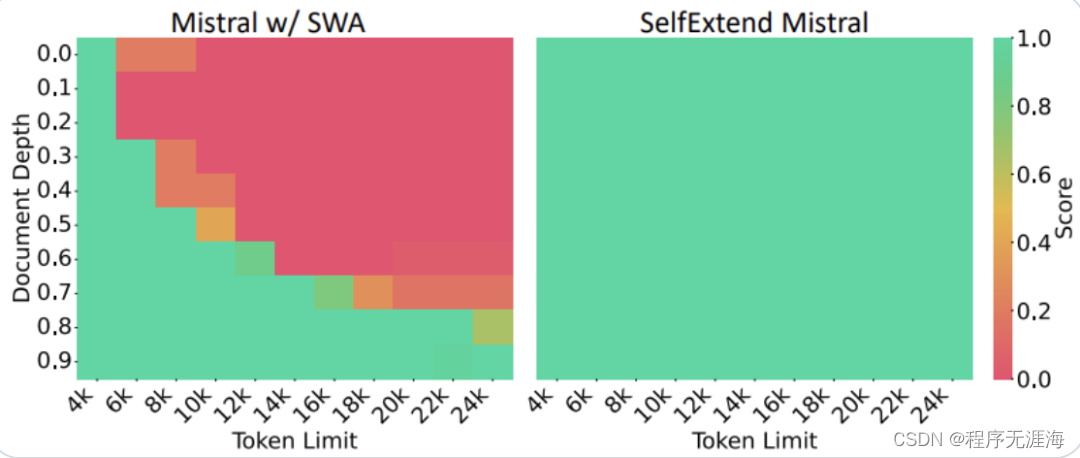
无需微调,只要四行代码就能让大模型窗口长度暴增,最高可增加3倍!而且是“即插即用”,理论上可以适配任意大模型,目前已在Mistral和Llama2上试验成功。有了这项技术,大模型(LargeLM)就能摇身一变,成为LongLM。近日,来自得克萨斯农工大学等机构的华人学者们发布了全新的大模型窗口扩展方法SelfExtended(简称SE)。在Mistral上,研究者在24k长度的文本中随机插入5位数字让模型搜索,结果经SE处理后,呈现出了全绿(通过)的测试结果。
多轮对话推理速度提升46%,开源方案打破LLM多轮对话的长度限制
 https://mp.weixin.qq.com/s/ngD97EaRD2pVqli_rsD76Q
https://mp.weixin.qq.com/s/ngD97EaRD2pVqli_rsD76Q
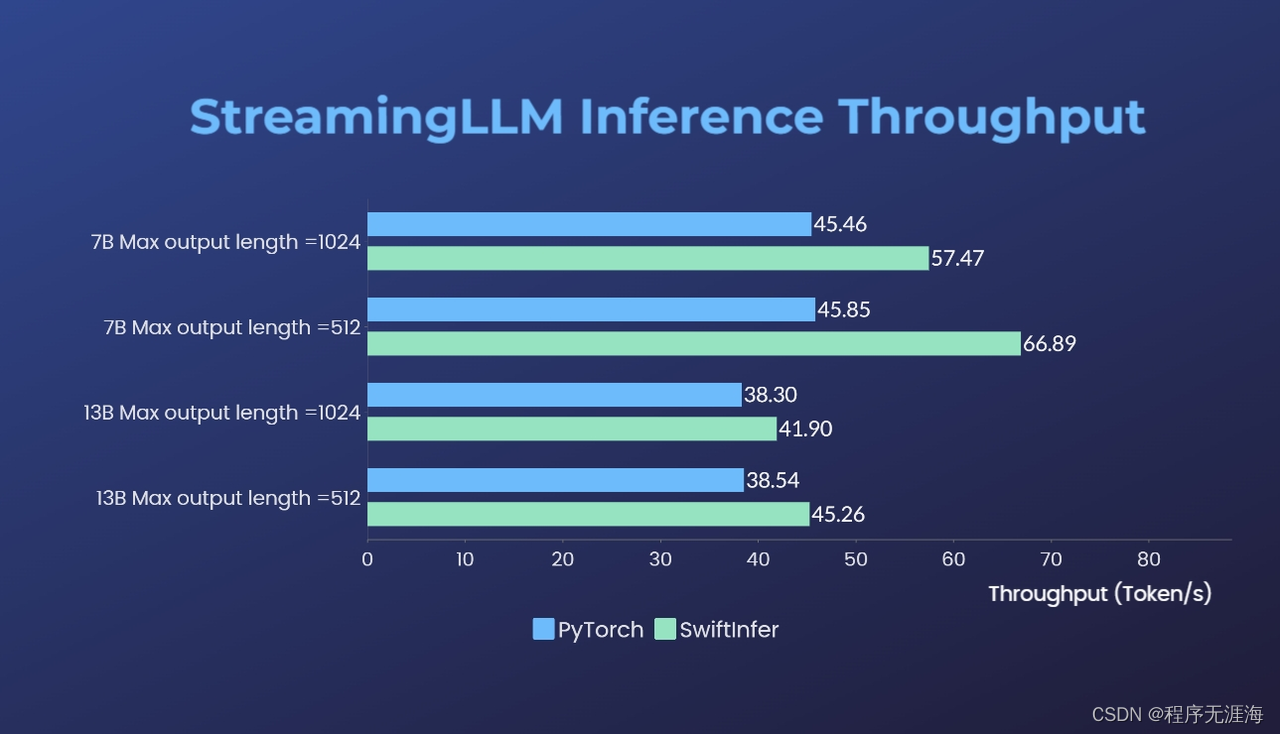
在大型语言模型(LLM)的世界中,处理多轮对话一直是一个挑战。前不久麻省理工 Guangxuan Xiao 等人推出的 StreamingLLM,能够在不牺牲推理速度和生成效果的前提下,可实现多轮对话总共 400 万个 token 的流式输入,22.2 倍的推理速度提升。但 StreamingLLM 使用原生 PyTorch 实现,对于多轮对话推理场景落地应用的低成本、低延迟、高吞吐等需求仍有优化空间。Colossal-AI 团队开源了 SwiftInfer,基于 TensorRT 实现了 StreamingLLM,可以进一步提升大模型推理性能 46%,为多轮对话推理提供了高效可靠的落地方案。
Figure-01学会制作咖啡:端到端人工智能
https://x.com/adcock_brett/status/1743987597301399852?s=20
Figure-01已经学会制作咖啡??
我们的人工智能在观察人类制作咖啡后学会了这一点
这是端到端的人工智能:我们的神经网络正在接收视频输入,输出轨迹
加入我们,来训练我们的机器人舰队:http://figure.ai/careers
MLLM-Protector: 确保大语言模型的安全性而不损害性能

链接:http://arxiv.org/abs/2401.02906v1
多模态大语言模型(MLLM)的部署带来了一种独特的弱点:对视觉输入的恶意攻击易受攻击。我们深入研究了保护MLLM免受此类攻击的新挑战。我们发现图像充当了一个在对齐过程中未被考虑的“外语”,这可能导致MLLM产生有害回应的倾向。不幸的是,与文本为基础的LLM中考虑的离散标记不同,图像信号的连续性质给对齐带来了重大挑战,这使得充分覆盖可能的情景变得困难。这种弱点加剧了一个事实,即开源MLLM主要是在有限的图文对示例上进行微调,远远少于广泛的基于文本的预训练语料库,这使得MLLM在显式对齐调优过程中更容易遗忘其原始能力。为了解决这些问题,我们引入了MLLM-Protector,一种插拔式策略,结合了轻量级的有害检测器和响应净化器。有害检测器的作用是识别MLLM中潜在的有害输出,而净化器将这些输出更正,以确保响应符合安全标准。这种方法有效地减轻了恶意视觉输入带来的风险,而不会损害模型的整体性能。我们的结果表明,MLLM-Protector为MLLM安全的一个以前未解决的方面提供了强大的解决方案。
上千位人工智能作者对人工智能的未来进行讨论

链接:http://arxiv.org/abs/2401.02843v1
在这项规模最大的调查中,有2,778位在顶级人工智能(AI)领域发表过论文的研究人员对AI进展的速度、高级AI系统的性质和影响进行了预测。总体预测显示,到2028年,AI系统实现多项里程碑的概率至少为50%,包括自主从零开始构建一个支付处理网站、创建一首与知名音乐家的新歌难以区分的歌曲,以及自主下载并微调一个大型语言模型。如果科学持续发展,到2027年,无人辅助的机器在每个可能的任务中超越人类的机会被估计为10%,到2047年为50%。后者的估计比我们仅一年前进行的类似调查提前了13年[Grace et al., 2022]。然而,预测人类所有职业成为完全可自动化的机会到2037年达到10%,最迟到2116年达到50%(与2022年调查中的2164年相比)。大多数受访者对AI进展的长期价值表达了相当大的不确定性38%至51%的受访者认为,高级AI可能导致与人类灭绝一样糟糕的结果的概率至少为10%。超过一半的人认为有关六种不同的AI相关情景应该“非常”或“极端”担心,包括错误信息、威权控制和不平等。关于更快还是更慢的AI进展对人类未来更好的争论存在。然而,人们普遍认为应该更加优先考虑旨在最小化AI系统潜在风险的研究。
大语言模型用于社交网络:应用、挑战和解决方案

链接:http://arxiv.org/abs/2401.02575v1
大语言模型(LLM)正在改变人们生成、探索和参与内容的方式。我们研究如何为在线社交网络开发LLM应用。尽管LLM在其他领域取得了成功,但出于多种原因,为社交网络开发基于LLM的产品具有挑战性,并且在研究界的报道相对较少。我们将社交网络的LLM应用分为三类。第一类是知识任务,用户希望找到新的知识和信息,例如搜索和问答。第二类是娱乐任务,用户希望消费有趣的内容,例如获取娱乐通知内容。第三类是基础任务,需要进行社交网络的内容注释和LLM监控。对于每个任务,我们分享了发现的挑战、开发的解决方案和吸取的教训。据我们所知,这是第一篇关于开发社交网络LLM应用的综合性论文。
CamoCopy 2.0
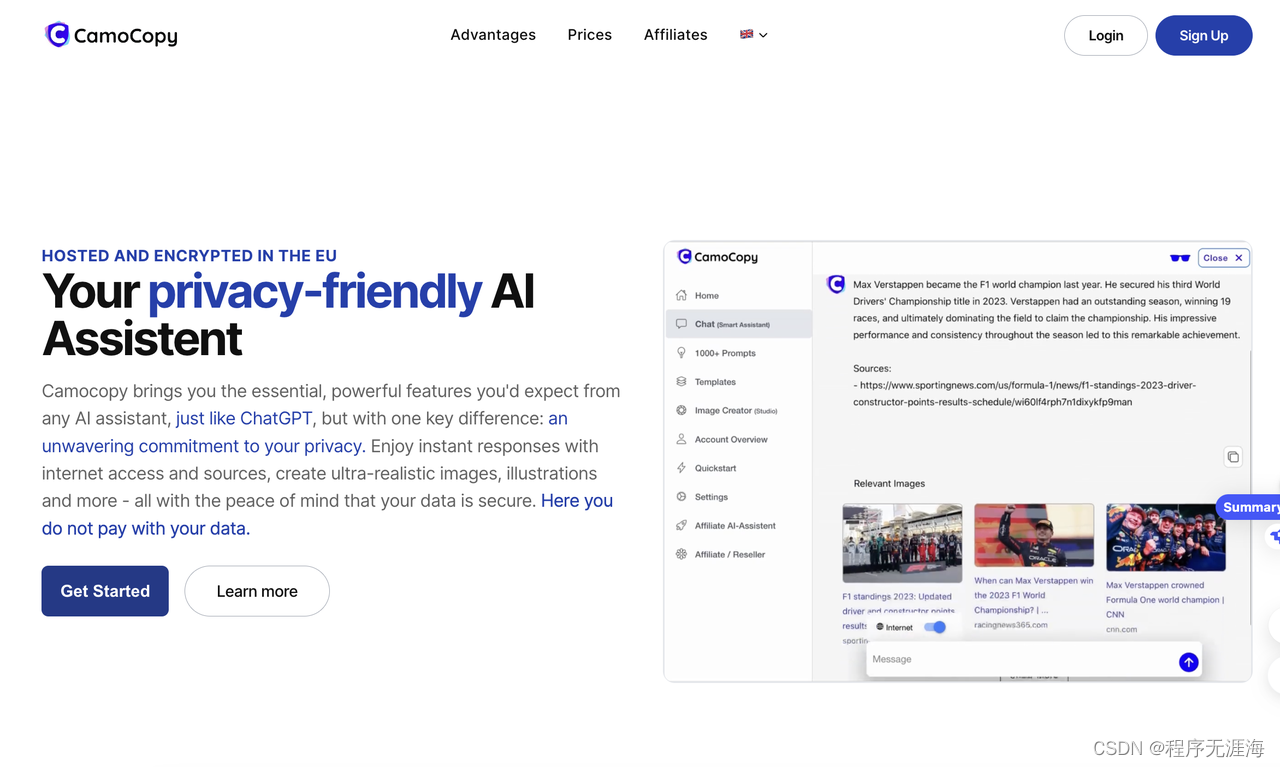
CamoCopy 2.0 是一个保护用户隐私的 AI 助手,而无需担心训练数据泄露。用户的任何数据都是加密或匿名的,用户通过购买积分的形式进行使用。
En3D:一种用于从 2D 合成数据中刻画 3D 形象的生成模型

https://github.com/menyifang/En3D
En3D 是一个大型 3D 人体生成模型,基于数百万个合成 2D 数据进行训练,独立于任何预先存在的 3D 或 2D 资产。该存储库包含 En3D 的实现,并提供了一系列基于它构建的应用程序。此外, repo 也是在打造一个有用的创意工具,从种子、文本提示或图像中生成逼真的 3D 头像,并支持自动角色动画 FBX 制作。所有输出都与现代图形工作流程兼容。
专访VideoPoet作者:LLM能带来真正的视觉智能
https://mp.weixin.qq.com/s/Hamz5XMT1tSZHKdPaCBTKg
VideoPoet是谷歌近期发布的一款专注于视频生成的大型语言模型(LLM),它能够生成视频和音频,支持更长的视频生成,并解决了现有视频生成中动作一致性的问题。与大多数视频领域模型不同,VideoPoet没有采用diffusion路线,而是沿着transformer架构开发,将多个视频生成功能集成到单个LLM中。VideoPoet的推出证明了transformer在视频生成任务上的潜力。研究者蒋路认为,视频生成领域的“ChatGPT时刻”预计将在2024年底或2025年中实现,届时视频生成将达到好莱坞样片级别的效果。长远来看,视频生成研究的终极目标是追求“视觉智能”,并在视频生成中实现人工通用智能。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【flink番外篇】9、Flink Table API 支持的操作示例(12)- Over Windows(有界和无界的over window)操作
- 探寻能源未来瞩目储能科技-2024武汉储能产业博览会定挡8月
- 对JAVA行业的深度思考职业规划
- Hive SQL判断一个字符串中是否包含字串的N种方式及其效率
- java设计模式实战【策略模式+观察者模式+命令模式+组合模式,混合模式在支付系统中的应用】
- 人大女王大学金融硕士项目——成功靠的不是豪言壮语,而是脚踏实地的努力
- 23种设计模式精讲,配套23道编程题目 ,支持 C++、Java、Python、Go
- vue3+vite+three加载glb模型文件
- volatile是什么?它有什么功能和特性?它值不值得我们去学习?我们该如何去学习呢?
- BSWM 模式管理(一) 基本规则