Redis:原理速成+项目实战——Redis常见命令(数据结构、常见命令总结)
👨?🎓作者简介:一位大四、研0学生,正在努力准备大四暑假的实习
🌌上期文章:Redis:原理速成+项目实战——初识Redis、Redis的安装及启动、Redis客户端
📚订阅专栏:Redis速成
希望文章对你们有所帮助
Redis数据结构介绍
Redis是一个key-value数据库,key为String类型,而value类型有很多样。
Redis为方便学习,将操作不同数据类型的命令做了分组,在官网中可以查看到不同的命令:
Redis官网——常见命令commands
如下所示:
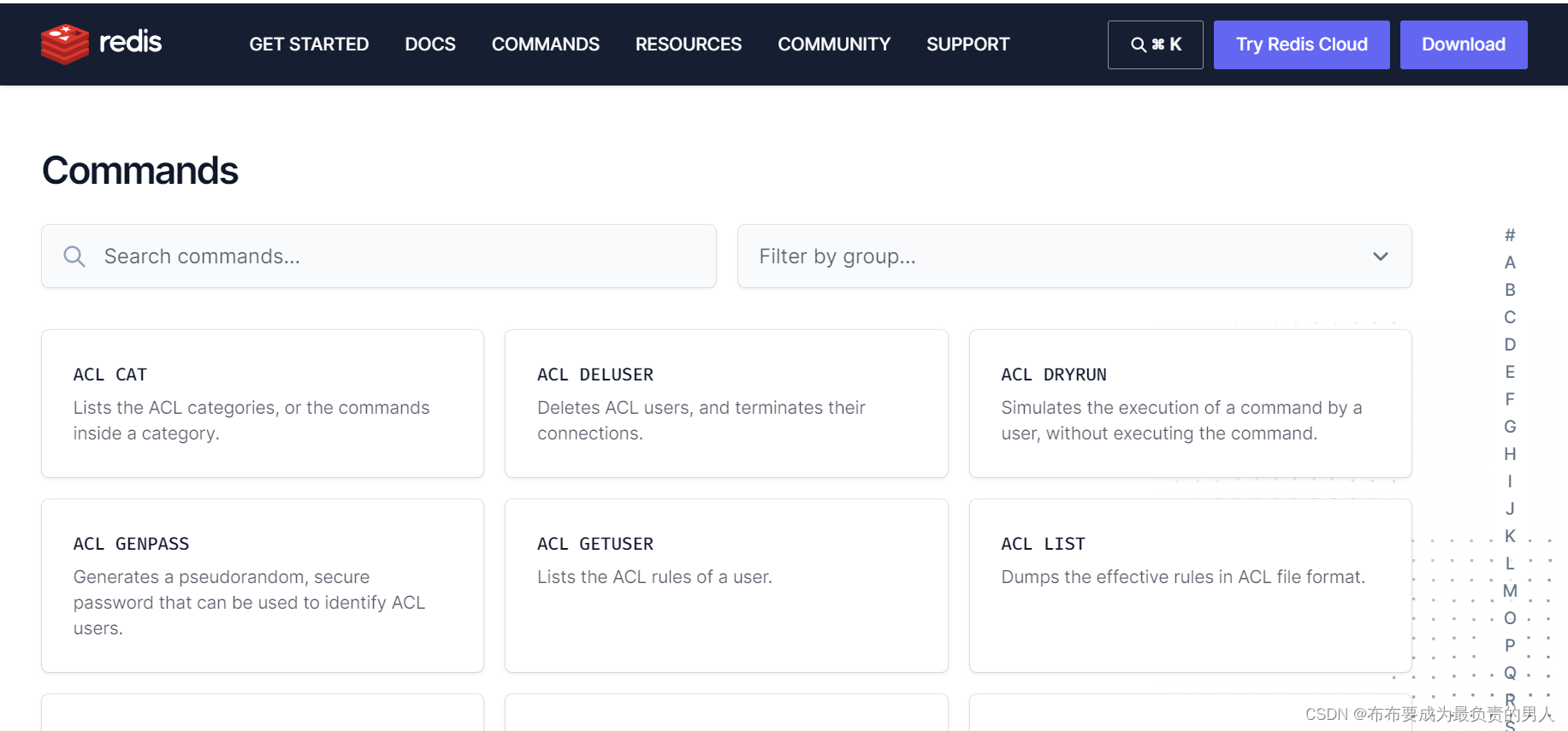
Redis通用命令
为方便演示,我们在Redis命令行中创建简单数据库:

通用命令是部分数据类型的都可以使用的指令,我们可以在官方文档中查看:
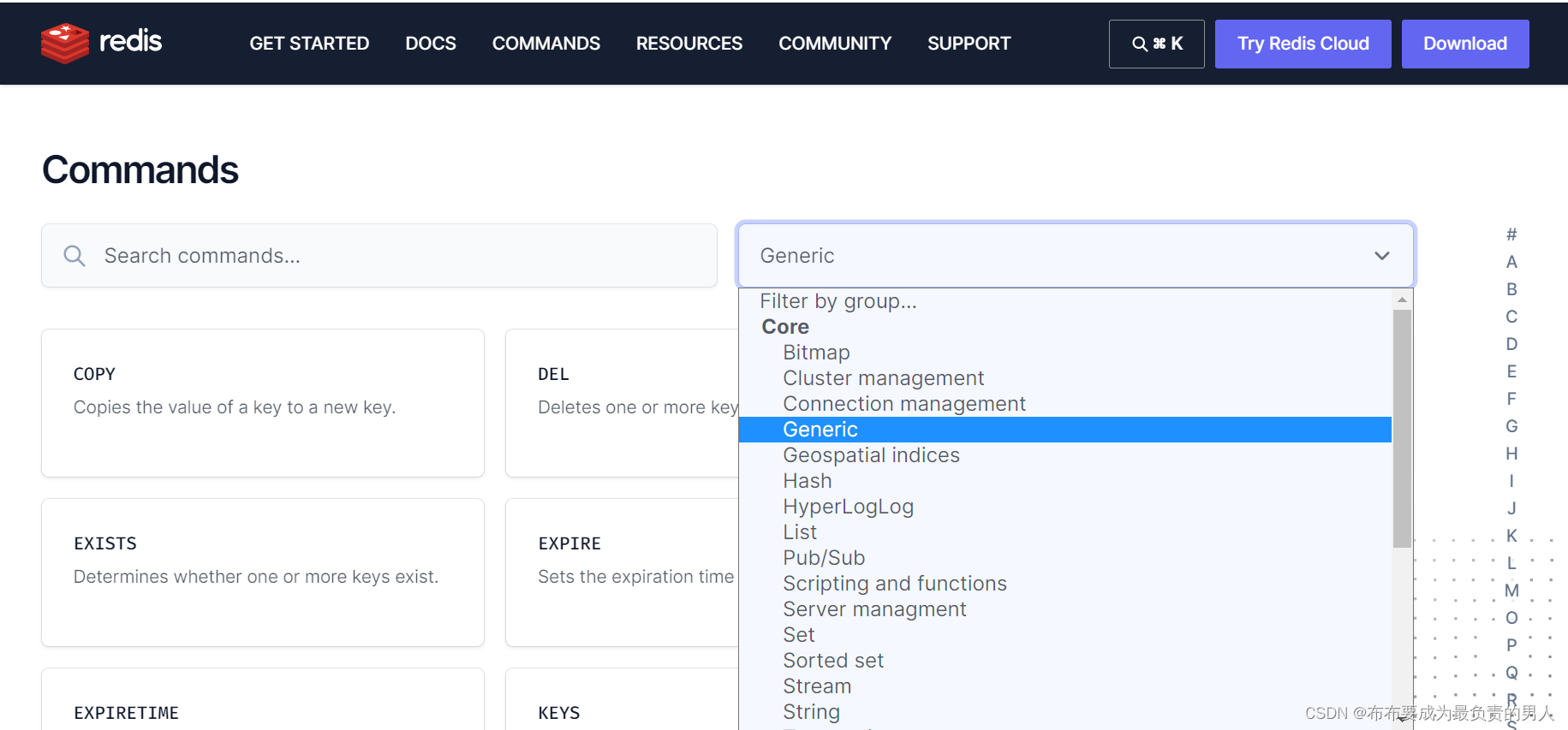
官方文档对命令的解释是比较详细的,如果大家经常使用命令的话,有点印象的时候,其实在命令行里面看也是很方便的:
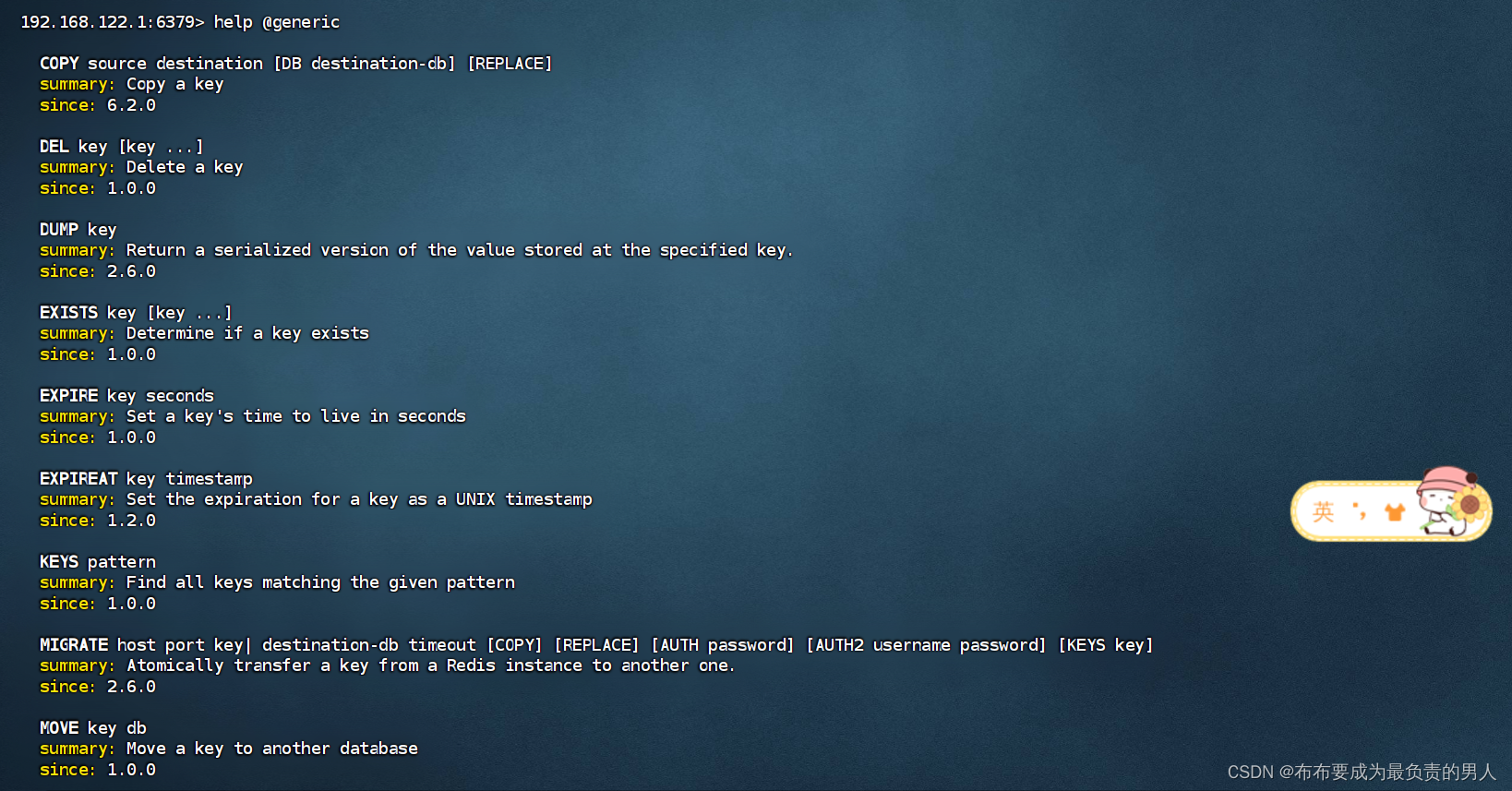
在这里,我就总结一下最常用的几个命令就好了:
1、KEYS:查看符合模板的所有key

其中,*表示多个字符,?表示单个字符,容易想到这种模糊搜索的方式肯定是效率不太高的。
2、DEL:删除一个指定的KEY
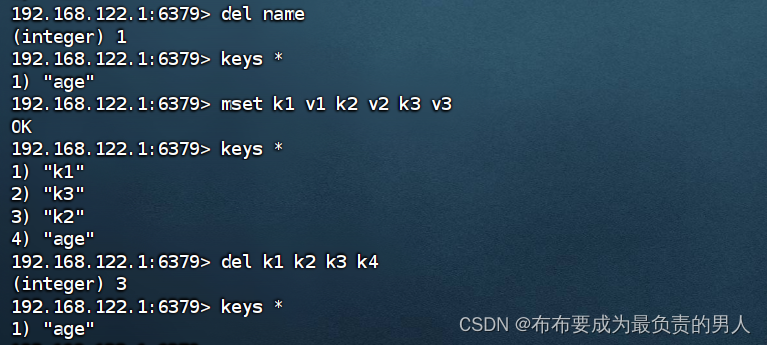
其中,mset是一种加入多种键值对的方式,在之后会介绍。
可以发现,del可以删除一个或多个key,要删除的某个key如果不存在也不会报错,命令运行的结果是成功删除的key的个数。
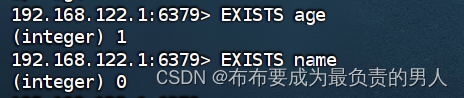
3、EXISTS:判断KEY是否存在,存在返回1,否则返回0
4、EXPIRE、TTL:
(1)EXPIRE:给一个key设置有效期,到期自动删除这个key
(2)TTL:查看一个KEY的剩余有效期

上面的命令定时为20s,利用TTL可以查看这个key还有多久到期,到-2就正式到期了,这时候这个key就会被自动删除。
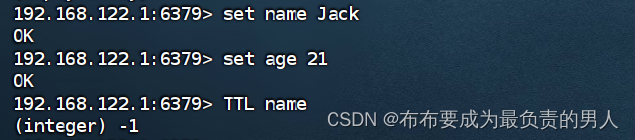
如果我们在增加key后没有设置失效时间,那么其TTL的返回值就是-1,表示永久有效。
为什么需要EXPIRE这个命令呢?因为Redis数据的存储是在内存中的,内存的空间相比磁盘珍贵的多的。
String类型
字符串类型是Redis中最简单的存储类型。
键值对中,根据字符串的格式不同,又可以分为3类:
string:普通字符串
int:整数,可以自增自减
float:浮点型,可以自增自减
| KEY | VALUE |
|---|---|
| msg | hello world |
| num | 10 |
| score | 92.5 |
无论哪种格式,其底层都是字节数组的形式来存储,只是编码方式不同,字符串类型的最大空间不能超过512M。
String常见命令如下:
| 命令 | 作用 |
|---|---|
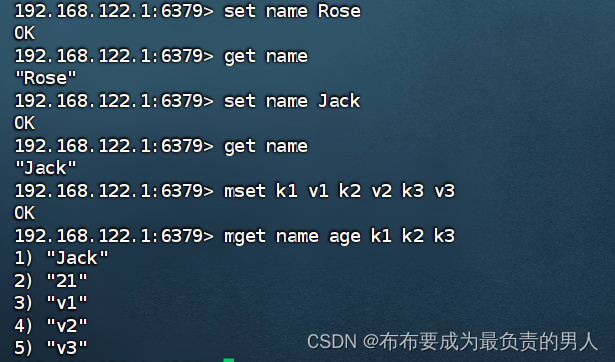
| SET | 添加或修改已经存在的一个String类型的键值对 |
| GET | 根据key获取String类型的value |
| MSET | 批量添加多个String类型的键值对 |
| MGET | 根据多个key获取多个String类型的value |
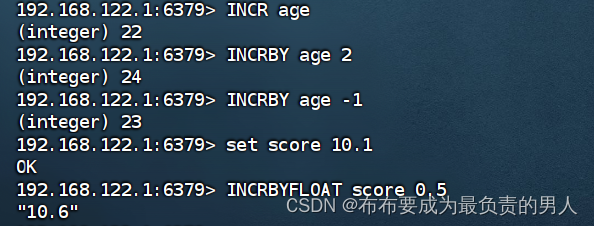
| INCR | 让一个整型的key自增1 |
| INCRBY | 让一个整型的key按指定步长自增 |
| INCRBYFLOAT | 让一个浮点类型的数字按指定步长自增 |
| SETNX | 添加一个String类型的键值对,前提是该key不存在 |
| SETEX | 添加一个String类型的键值对,且指定有效期 |
实验:
Key的层级格式
Redis没有类似MySQL中的table的概念,因此要想个办法来区分不同类型的key。
其实,Redis的key允许有多个单词来形成层级结构,多个单词之间用’:'隔开,格式类似:
项目名:业务名:类型:id
若value是一个Java对象,例如一个user对象,则可以将对象序列化成JSON字符串后存储:
| KEY | VALUE |
|---|---|
| wxj:user:1 | {“id”: 1, “name”: “Jack”, “age”: 21} |
| wxj:product:1 | {“id”:1, “name”: “库里10”, “price”: 1999} |
这种层级格式我们可以打开可视化工具去比较清晰的查看,便捷我们的开发。
Hash类型
Hash类型也叫做散列,其value是一个无序字典,类似于Java中的HashMap。
而String结构将对象序列化为json字符串后存储,当需要修改字段的时候就会很不方便,必须完全的覆盖字符串。
而Hash可以将对象的每个字段独立进行存储,这样就可以对单个字段来做CRUD了:
| KEY | VALUE-field | VALUE-value |
|---|---|---|
| wxj:user:1 | name | Jack |
| wxj:user:1 | age | 21 |
| wxj:user:2 | name | Rose |
| wxj:user:2 | age | 18 |
Hash常见命令:
| 命令 | 作用 |
|---|---|
| HSET key field value | 添加或修改hash类型key的field的值 |
| HGET key field | 获取一个hash类型key的field的值 |
| HMSET | 批量添加多个hash类型key的field的值 |
| HMGET | 批量获取多个hash类型key的field的值 |
| HGETALL | 获取一个hash类型的key中的所有的field和value |
| HKEYS | 获取一个hash类型的key中的所有的field |
| HVALS | 获取一个hash类型的key中的所有的value |
| HINCRBY | 让一个hash类型的key按指定步长自增 |
| HSETNX | 添加一个hash类型的key的field值,前提是该field不存在 |
实验部分就自行做实验,其实这无非就是个Map嵌套的Map而已。
List类型
Redis中的List与Java中的LinkedList类似(有序、元素可重复、插入删除快,查询慢),可以看成是一个双向链表。既支持正向检索也支持反向检索。
| 命令 | 作用 |
|---|---|
| LPUSH key element | 左侧插入一个或多个元素 |
| LPOP key | 左侧删除第一个元素 |
| RPUSH key element | 右侧插入一个或多个元素 |
| RPOP key | 右侧删除第一个元素 |
| LRANGE key star end | 返回一段角标范围内的所有元素 |
| BLPOP、BRPOP | 与LPOP、RPOP类似,但是在没有元素的时候会等待指定时间,而不是直接返回nil |

这就跟双向队列似的,先push进去的是1,那么从左边取出来的就是3。
Set类型
Redis的Set结构与Java中的HashSet类似(无序、元素不重复、查找快、支持集合的交并差),可以看成一个value为null的HashMap。
| 命令 | 作用 |
|---|---|
| SADD key member | 向set中添加一个或多个元素 |
| SREM key member | 移除set中的指定元素 |
| SCARD key | 返回set中元素的个数 |
| SISMEMBER key member | 判断一个元素是否存在于set中 |
| SMEMBERS | 获取set中的所有元素 |
SortedSet类型
Redis中的SortedSet是一个可排序的set集合,与Java中的TreeSet类似,但底层数据结构差别很大。SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加hash表。
SortedSet具备的特性:可排序、元素不重复、查询速度快。
所以SortedSet经常被拿来实现排行榜这样的功能。
| 命令 | 作用 |
|---|---|
| ZADD key score member | 添加一个或多个元素到sorted set ,如果已经存在则更新其score值 |
| ZREM key member | 删除sorted set中的一个指定元素 |
| ZSCORE key member | 获取sorted set中的指定元素的score值 |
| ZRANK key member | 获取sorted set 中的指定元素的排名 |
| ZCARD key | 获取sorted set中的元素个数 |
| ZCOUNT key min max | 统计score值在给定范围内的所有元素的个数 |
| ZINCRBY key increment member | 让sorted set中的指定元素自增,步长为指定的increment值 |
| ZRANGE key min max | 按照score排序后,获取指定排名范围内的元素 |
| ZRANGEBYSCORE key min max | 按照score排序后,获取指定score范围内的元素 |
| ZDIFF、ZINTER、ZUNION | 求差集、交集、并集 |
所有的排名都是升序的,要降序就需要在命令的Z后面添加REV。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 微信小程序vant安装使用过程中遇到无法构建npm的问题
- 软件测试全套教程,软件测试自学线路图
- 格局打开!前端未死,只是要求变高了
- 年度技术回顾总结与拓展
- 126.(leaflet篇)leaflet松散型arcgis缓存切片加载
- 什么是误差,什么是重构误差,误差与重构误差有什么区别?
- 内网渗透测试基础——Windows PowerShell篇
- CSS Day10
- 企业在什么情况下会需要ITSM?
- 备份方式和Linux基础