大数据学习之Flink算子、了解(Transformation)转换算子(基础篇三)
Transformation转换算子(基础篇三)
目录
3.2?富函数类(Rich Function Classes)
三、转换算子(Transformation)

数据源读入数据之后,我们就可以使用各种转换算子,将一个或多个 DataStream 转换为新的 DataStream,如图所示。一个Flink程序的核心,其实就是所有的转换操作,它们决定了处理的业务逻辑。
1.基本转换算子
1.1 映射(Map)
map算子接收一个函数作为参数,并把这个函数应用于DataStream的每个元素,最后将函数的返回结果作为结果DataStream中对应元素的值,即将DataStream的每个元素转换成新的元素。

1.2 过滤(filter)
filter转换操作,顾名思义是对数据流执行一个过滤,通过一个布尔条件表达式设置过滤条件,对于每一个流内元素进行判断,若为 true 则元素正常输出,若为 false 则元素被过滤掉。

1.3 扁平映射(flatmap)
flatMap 操作又称为扁平映射,主要是将数据流中的整体(一般是集合类型)拆分成一个一个的个体使用。消费一个元素,可以产生 0 到多个元素。flatMap 可以认为是“扁平化”(flatten)和“映射”(map)两步操作的结合,也就是先按照某种规则对数据进行打散拆分,再对拆分后的元素做转换处理

1.4基本转换算子的例子
代码如下:
import org.apache.flink.streaming.api.scala._
object Practice_of_Simple_Operators {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1) //设置并行度为1
//常见的简单算子 有:map、flatmap、filter
//map
//从集合中获取不同数据类型数据
val dataStream1 = env.fromCollection(List(1,2,3))
//对每一个数 都乘以2
val resultStream1 = dataStream1.map(data => data * 2)
resultStream1.print("resultStream1")
//flatmap
val dataStream2 = env.fromCollection(List("hello word","hello flink","hello spark"))
val resultStream2 = dataStream2.flatMap(_.split(" "))
resultStream2.print("resultStream2")
//filter
val resultStream3 = dataStream1.filter(_%2==0)
resultStream3.print("resultStream3")
env.execute("Stream Transform")//启动flink作业
}
}运行结果:

2.聚合算子(Aggregation)
-
直观上看,基本转换算子确实是在“转换”——因为它们都是基于当前数据,去做了处理和输出。
-
而在实际应用中,我们往往需要对大量的数据进行统计或整合,从而提炼出更有用的信息。比如之前 word count 程序中,要对每个词出现的频次进行叠加统计。这种操作,计算的结果不仅依赖当前数据,还跟之前的数据有关,相当于要把所有数据聚在一起进行汇总合并——这就是所谓的“聚合”(Aggregation),也对应着 MapReduce 中的 reduce 操作。
2.1 按键分区(keyBy)
对于 Flink 而言,DataStream是没有直接进行聚合的API 的。因为我们对海量数据做聚合肯定要进行分区并行处理,这样才能提高效率。所以在 Flink 中,要做聚合,需要先进行分区; 这个操作就是通过keyBy来完成的。
keyBy 是聚合前必须要用到的一个算子。keyBy 通过指定键(key),可以将一条流从逻辑上划分成不同的分区(partitions)。这里所说的分区,其实就是并行处理的子任务,也就对应着任务槽(task slot)。
基于不同的key,流中的数据将被分配到不同的分区中去;这样一来,所有具有相同的key 的数据,都将被发往同一个分区,那么下一步算子操作就将会在同一个 slot 中进行处理了。
keyBy算子主要作用于元素类型是元组或数组的DataStream上。使用该算子可以将DataStream中的元素按照指定的key(字段)进行分组,具有相同key的元素将进入同一个分区中(不进行聚合),并且不改变原来元素的数据结构。在逻辑上将流划分为不相交的分区,在内部是通过哈希分区实现的。

//配置执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//fromElements --> 给一个固定的元素集合 创建一个数据流(DataStream)
//数据流是以键值对的形式存在的
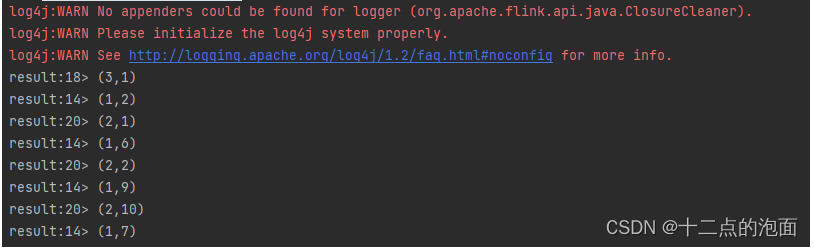
val source = env.fromElements((1, 2), (2, 1),(1, 6), (1, 9), (1, 7), (2, 2), (2, 10), (3, 1))
//keyby算子
source.keyBy(temp => temp._1).print("result")
// 执行 Flink 作业
env.execute("Flink FromElements Example")运行结果:
2.2 简单聚合
-
有了按键分区的数据流 KeyedStream,我们就可以基于它进行聚合操作了。Flink 为我们 内置实现了一些最基本、最简单的聚合 API,主要有以下几种:
-
sum():在输入流上,对指定的字段做叠加求和的操作。
-
min():在输入流上,对指定的字段求最小值。
-
max():在输入流上,对指定的字段求最大值。
-
minBy():与 min()类似,在输入流上针对指定字段求最小值。
不同的是,min()只计算指定字段的最小值,其他字段会保留最初第一个数据的值;
而 minBy()则会返回包含字段最小值的整条数据。
-
maxBy():与 max()类似,在输入流上针对指定字段求最大值。
不同的是,max()只计算指定字段的最大值,其他字段会保留最初第一个数据的值;
而 maxBy()则会返回包含字段最大值的整条数据。
-
-
简单聚合算子使用非常方便,语义也非常明确。这些聚合方法调用时,也需要传入参数; 但并不像基本转换算子那样需要实现自定义函数,只要说明聚合指定的字段就可以了。指定字 段的方式有两种:指定位置,和指定名称。 对于元组类型的数据,同样也可以使用这两种方式来指定字段。需要注意的是,元组中字 段的名称,是以1、2、_3、…来命名的。 例如,下面就是对元组数据流进行聚合的测试:
-
对于元组类型的数据,同样也可以使用这两种方式来指定字段。需要注意的是,元组中字 段的名称,是以1、2、_3、…来命名的。
测试:
import org.apache.flink.streaming.api.scala._
object TransTupleAggregation {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env
.fromElements(
("a", 1), ("a", 3), ("b", 3), ("b", 4)
)
stream.print("原数据")
stream.keyBy(_._1).sum(1).print() //对元组的索引 1 位置数据求和
stream.keyBy(_._1).sum("_2").print() //对元组的第 2 个位置数据求和
stream.keyBy(_._1).max(1).print() //对元组的索引 1 位置求最大值
stream.keyBy(_._1).max("_2").print() //对元组的第 2 个位置数据求最大值
stream.keyBy(_._1).min(1).print() //对元组的索引 1 位置求最小值
stream.keyBy(_._1).min("_2").print() //对元组的第 2 个位置数据求最小值
stream.keyBy(_._1).maxBy(1).print() //对元组的索引 1 位置求最大值
stream.keyBy(_._1).maxBy("_2").print() //对元组的第 2 个位置数据求最大值
stream.keyBy(_._1).minBy(1).print() //对元组的索引 1 位置求最小值
stream.keyBy(_._1).minBy("_2").print() //对元组的第 2 个位置数据求最小值
env.execute()
}
}而如果数据流的类型是样例类,那么就只能通过字段名称来指定,不能通过位置来指定了。
import org.apache.flink.streaming.api.scala._
object TransAggregationCaseClass {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.fromElements(
Event("Mary", "./home", 1000L),
Event("Bob", "./cart", 2000L)
)
// 使用 user 作为分组的字段,并计算最大的时间戳
stream.keyBy(_.user).max("timestamp").print()
env.execute()
}
}一个聚合算子,会为每一个key保存一个聚合的值,在Flink中我们把它叫作“状态”(state)。 所以每当有一个新的数据输入,算子就会更新保存的聚合结果,并发送一个带有更新后聚合值 的事件到下游算子。对于无界流来说,这些状态是永远不会被清除的,所以我们使用聚合算子, 应该只用在含有有限个 key 的数据流上。
2.3 归约聚合(reduce)
-
与简单聚合类似,reduce()操作也会将 KeyedStream 转换为 DataStream。它不会改变流的 元素数据类型,所以输出类型和输入类型是一样的。
-
调用 KeyedStream 的 reduce()方法时,需要传入一个参数,实现 ReduceFunction 接口。接 口在源码中的定义如下:
public interface ReduceFunction<T> extends Function, Serializable {
T reduce(T value1, T value2) throws Exception;
}ReduceFunction 接口里需要实现 reduce()方法,这个方法接收两个输入事件,经过转换处 理之后输出一个相同类型的事件;所以,对于一组数据,我们可以先取两个进行合并,然后再 将合并的结果看作一个数据、再跟后面的数据合并,最终会将它“简化”成唯一的一个数据, 这也就是 reduce“归约”的含义。在流处理的底层实现过程中,实际上是将中间“合并的结果” 作为任务的一个状态保存起来的;之后每来一个新的数据,就和之前的聚合状态进一步做归约。
下面我们来看一个稍复杂的例子。
我们将数据流按照用户 id 进行分区,然后用一个 reduce()算子实现 sum()的功能,统计每 个用户访问的频次;进而将所有统计结果分到一组,用另一个 reduce()算子实现 maxBy()的功 能,记录所有用户中访问频次最高的那个,也就是当前访问量最大的用户是谁。
import org.apache.flink.streaming.api.scala._
object TransReduce {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env
.addSource(new ClickSource)
.map(r => (r.user, 1L))
//按照用户名进行分组
.keyBy(_._1)
//计算每个用户的访问频次
.reduce((r1, r2) => (r1._1, r1._2 + r2._2))
//将所有数据都分到同一个分区
.keyBy(_ => true)
//通过 reduce 实现 max 功能,计算访问频次最高的用户
.reduce((r1, r2) => if (r1._2 > r2._2) r1 else r2)
.print()
env.execute()
}
}reduce()同简单聚合算子一样,也要针对每一个 key 保存状态。因为状态不会清空,所以 我们需要将 reduce()算子作用在一个有限 key 的流上。
3.用户自定义函数(UDF)
3.1?函数类(Function Classes)
3.2?富函数类(Rich Function Classes)
4.物理分区(Physical Partitioning)
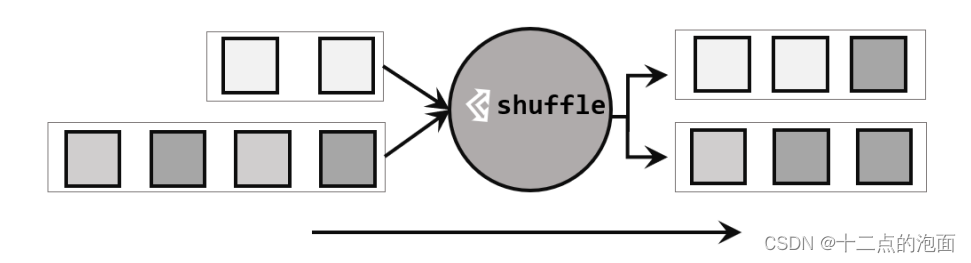
4.1?随机分区(shuffle)
4.2?轮询分区(Round-Robin)

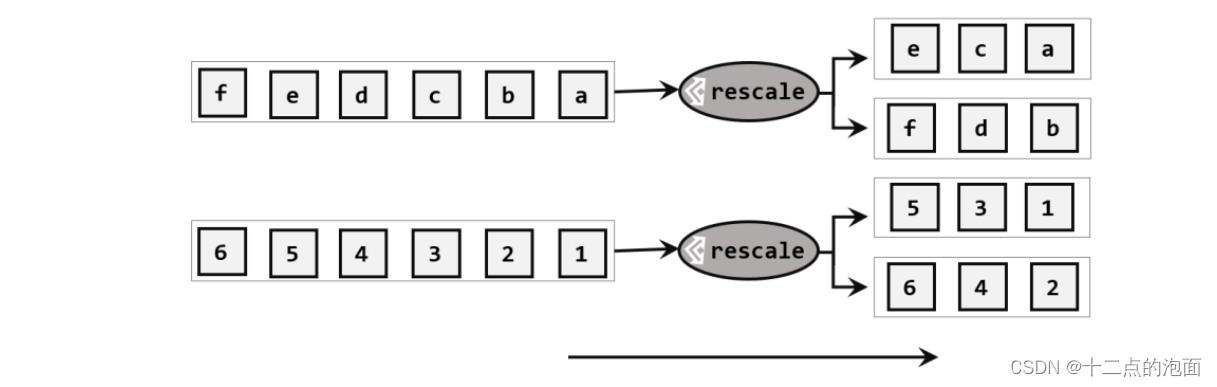
4.3?重缩放分区(rescale)
4.4?广播(broadcast)
4.5 全局分区(global)
4.6?自定义分区(Custom)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- uni-app如何生成骨架屏
- NR HARQ-RTT-Timer和DRX RetransmissionTimer
- 中国社科院与新加坡社科大联合培养博士——单证还是双证?
- 【检索稳定|火爆征稿中】2024年生物医药与医学影像国际会议(IACBMI 2024)
- 二分算法
- Java 数据结构集合
- 【INTEL(ALTERA)】错误 (19021):相同的文件名 xx 用于不同的 IP 文件。同一个名称不能用于多个 IP 文件。
- Python教程38:使用turtle画动态粒子爱心+文字爱心
- Python数据分析(1)Matrix Manipulation
- 跬智信息(Kyligence)与光环云(Sinnet Cloud)达成战略合作